LangGraph Agent Evaluation: A 2026 Deep Tutorial
LangGraph eval is graph-level, not message-level. Score state transitions: node-input, node-output, edge-routing, and checkpoint replay determinism.
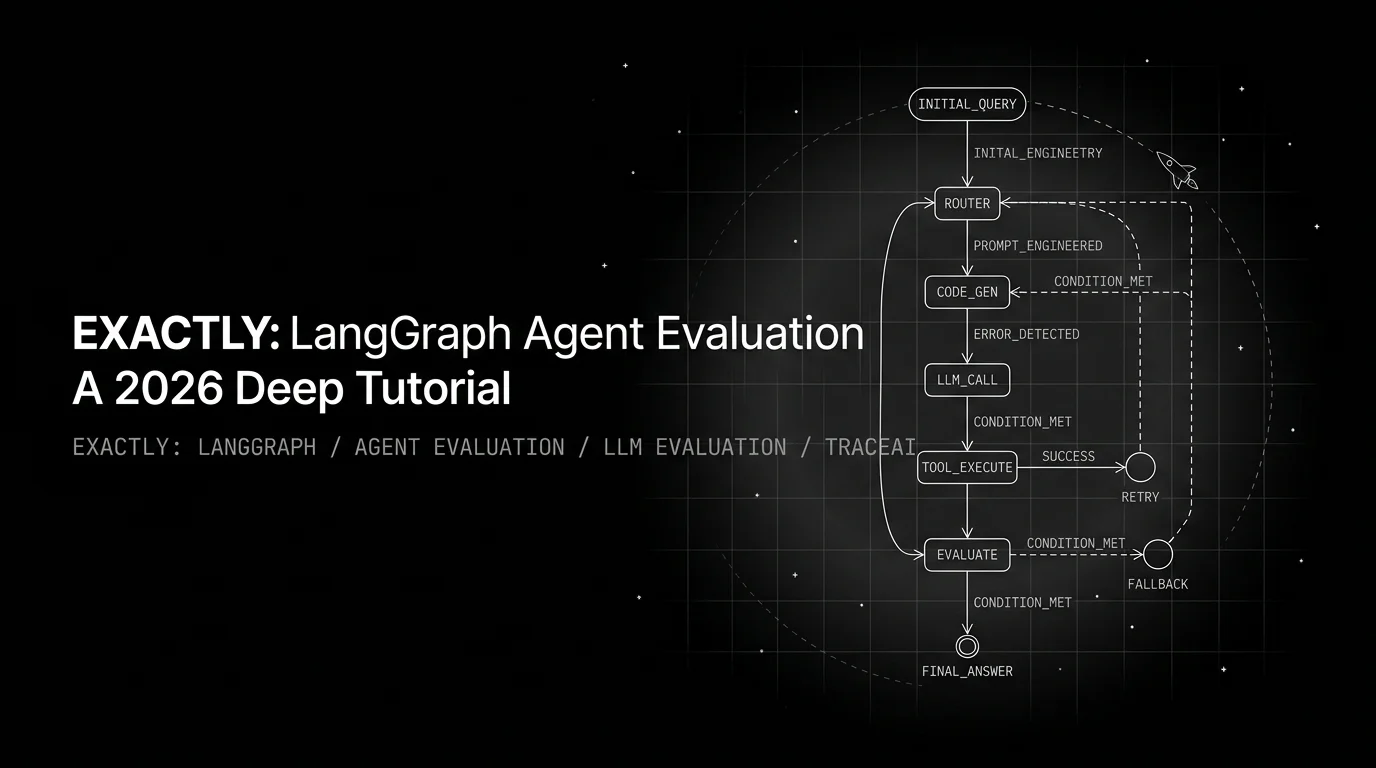
Table of Contents
A LangGraph agent scores 0.93 on TaskCompletion against a fifty-query regression set. Every final answer looks fine. A week later, cost per query has doubled and the trace tells the real story: the router took the expensive branch on every query that mentioned a date, the retry loop fired three times before the search tool gave up and the model fabricated an answer, and a reducer overwrote a constraint the planner had set two nodes upstream. The final message was right. The state machine was broken.
This is the failure mode message-level evaluation cannot see. A LangGraph agent is not a transcript; it is a state machine with typed channels, conditional edges, retry loops, sub-graphs, parallel fan-in, and a checkpointer that snapshots state on every transition. The unit of evaluation is the state transition, not the assistant message. Score the transitions or you ship a state machine you cannot reason about. This post is the working pattern for evaluating LangGraph agents in 2026: the four transition-level rubrics, the traceAI LangGraphInstrumentor that exposes the topology, the checkpoint-replay loop that turns flaky failures into deterministic regressions, and the Future AGI loop that closes from failing trajectory to shipped fix.
Why message-level eval misses graph failures
LangChain chains are linear. LangGraph is not. The failure modes that survive a message-level pass live in the seams the chain framing does not have.
- Conditional edges. A router reads state and picks one of N branches. A passing answer over the wrong branch is still a defect.
- Retry loops. A node can loop back to itself. A graph that retries a tool five times produces a correct answer at five times the cost.
- Typed channels. State is a set of typed channels with reducers (
add_messages,operator.add, custom). A reducer that overwrites where it should append silently breaks downstream nodes. - Sub-graphs. A node can be a compiled graph. Evaluation has to traverse parent-child topology, not flatten it.
- Parallel fan-in. A graph can fan out to N nodes and reduce. A merge that collides on a key drops data.
- Checkpointed memory. A regression in checkpoint write logic does not surface until turn three.
The final message averages over all of this. It moves when the graph is catastrophically wrong and stays flat while the state machine quietly degrades. Background on the broader axis-blindness pattern: agent passes evals, fails production and the definitive guide to AI agent evaluation in 2026.
State transitions are the unit
A state transition is a four-tuple: (state_before, node, state_after, edge_taken). Every LangGraph execution is an ordered sequence of these plus the checkpoint metadata that lets you replay any prefix. The eval set is a list of expected transition sequences, not a list of expected final answers. The CI gate runs assertions against per-transition scores. Error Feed clusters failures by transition shape. Same primitive, four properties:
- Node-input correctness. Did the node receive the state it expected, with the channel schema respected and no stale checkpoint shadowing.
- Node-output correctness. Did the node produce a state diff that respects the channel schema and the node’s contract.
- Edge-routing correctness. On conditional edges, did the router pick the branch the rubric considers correct for the state at decision time.
- Checkpoint-replay determinism. Does re-running from a saved checkpoint with the same inputs reproduce the same downstream trajectory.
Each layer catches a different failure class. Together they localise a regression the moment it lands.
| Layer | What it scores | Future AGI evaluator |
|---|---|---|
| Node-input | Channel schema respected, state slice expected | CustomLLMJudge as NodeInputContract |
| Node-output | State diff respects schema and node intent | CustomLLMJudge as StateDiffCorrectness |
| Edge-routing | Router picked correct branch given state | CustomLLMJudge as RoutingAccuracy |
| Checkpoint-replay | Same checkpoint plus inputs reproduce trajectory | Deterministic equality plus TrajectoryHashMatch |
Layer this on top of the standard answer-level templates (TaskCompletion, Groundedness, AnswerRefusal, LLMFunctionCalling) and you have a stack that grades the state machine, not just the response.
What traceAI’s LangGraphInstrumentor captures
A transition-level rubric needs a transition-level span. traceAI’s LangChain instrumentation ships a dedicated LangGraph submodule that emits graph topology as first-class span attributes:
langgraph.graph.node_count,langgraph.node.name,langgraph.node.type(start,end,intermediate)langgraph.node.is_entry,langgraph.node.is_end- Conditional edge attributes: branch chosen, branches available, state at decision time
- Per-node state diff serialized as JSON: what fields the node added, removed, or modified
- Checkpointer reads and writes: which checkpoint the run resumed from, which it wrote on completion
These sit alongside the cross-framework gen_ai.agent.graph.* namespace (node_id, node_name, parent_node_id). Sub-graphs reconstruct as nested trees because the parent_node_id of a sub-graph’s entry node points at the parent graph’s invoking node.
traceAI lets you switch the semantic convention layer between FI (default), OTEL_GENAI, OPENINFERENCE (Arize Phoenix’s namespace), and OPENLLMETRY. Graph topology pipes into Phoenix or Jaeger without re-instrumenting.
Generic tracers instrument LangGraph as a chain. Nodes show up as opaque spans, conditional edges show up as nothing, state diffs are dropped, and the checkpointer is invisible. Routing or state-diff rubrics on top of those traces require parsing LangChain callback payloads by hand.
Wiring traceAI into a LangGraph project
Patch-based instrumentation. No code changes inside node functions, no tracer plumbing through the graph compile.
from fi_instrumentation import register
from fi_instrumentation.fi_types import (
ProjectType,
EvalTag,
EvalTagType,
EvalSpanKind,
EvalName,
ModelChoices,
)
from traceai_langchain import LangChainInstrumentor
tracer_provider = register(
project_name="support_agent",
project_type=ProjectType.OBSERVE,
project_version_name="v1.4.2",
eval_tags=[
EvalTag(
type=EvalTagType.OBSERVATION_SPAN,
value=EvalSpanKind.TOOL,
eval_name=EvalName.LLM_FUNCTION_CALLING,
model=ModelChoices.TURING_LARGE,
mapping={"input": "input.value", "output": "output.value"},
),
EvalTag(
type=EvalTagType.OBSERVATION_SPAN,
value=EvalSpanKind.AGENT,
eval_name=EvalName.TASK_COMPLETION,
model=ModelChoices.TURING_LARGE,
mapping={"input": "input.value", "output": "output.value"},
),
],
)
LangChainInstrumentor().instrument(tracer_provider=tracer_provider)Compile and run any LangGraph as usual. The LangGraph submodule activates automatically. Every node emits a span tagged with the langgraph.* attributes, every conditional edge emits an edge span with the routing payload, every state diff serializes as JSON on the node span, and every checkpoint write emits a checkpointer span. The EvalTag pipeline fires the relevant evaluator server-side post-export, so eval cost does not add latency to the user request. The verdict writes back as gen_ai.evaluation.score.value, gen_ai.evaluation.score.label, and gen_ai.evaluation.explanation, visible inline in the trace tree. Background on the trace pipeline: instrumenting your AI agent with traceAI.
Per-node rubrics: input contract and output diff
Per-node rubrics gate the unit transition. They are the upstream signal that catches the bug before the chain-level metric averages it away.
NodeInputContract asks whether the node received the state slice it expected. A planner node expects messages, user_intent, and available_tools populated. If the upstream router fired before user_intent was set, the planner runs on a state that violates its contract, and downstream nodes inherit the bug. The rubric:
from fi.evals.templates import CustomLLMJudge
node_input_contract = CustomLLMJudge(
name="NodeInputContract",
rule="""You are evaluating whether a graph node received the state it expects.
Node name: {node_name}
Node input contract (one line per required field): {node_contract}
State slice the node received (JSON): {state_slice}
Score 1.0 if every required field is populated with a value of the expected type.
Score 0.5 if one optional field is missing.
Score 0.0 if a required field is missing, null, or of the wrong type.
List any contract violations you found.""",
choices=["valid", "degraded", "broken"],
model="turing_large",
)StateDiffCorrectness asks whether the node’s output diff respects the channel schema and the node’s stated intent. traceAI serializes the diff as structural JSON, not free text, which matters: an LLM judge over a free-text summary will miss list.append vs list.replace, dict.update vs dict.setdefault, and type coercions that only manifest two nodes later. The structural diff makes the rubric grade what actually happened.
state_diff_correctness = CustomLLMJudge(
name="StateDiffCorrectness",
rule="""You are evaluating whether a graph node updated shared state correctly.
Node name: {node_name}
Node intent (one line): {node_intent}
Channel schema (JSON): {channel_schema}
State diff produced (JSON): {state_diff}
Score 1.0 if the diff matches the intent and preserves all invariants.
Score 0.0 if the node dropped a required field, corrupted a field type, used the wrong
reducer (e.g., replaced where it should have appended), or violated an invariant.
List any broken invariants you found.""",
choices=["correct", "broken"],
model="turing_large",
)Practical scoping: do not score every node with an LLM judge. A graph of any size has dozens of state mutations and scoring all of them gets expensive. Pick the five to ten nodes whose output is read by multiple downstream consumers (planners, routers, reducers after parallel fan-in), score those at every run, and sample the rest. Track per-node StateDiffCorrectness as a regression metric. When a node’s score drops, the fix is almost always a one-line reducer change or a clarifying sentence in the node prompt.
Tool nodes get the standard LLMFunctionCalling template wired through the EvalTag above. The evaluating tool-calling agents in 2026 guide covers the rubric design in depth.
Edge-routing rubric: where graphs fail silently
Conditional edges are the hardest LangGraph defect class because the graph still answers when the wrong branch was taken. A 5 percent drop in routing accuracy on a single decision node is the leading indicator of cost and latency regressions, weeks before the final-answer metric moves.
routing_accuracy = CustomLLMJudge(
name="RoutingAccuracy",
rule="""You are evaluating an agent's routing decision in a directed graph.
State at the decision point (JSON): {state}
Branches available at this node: {available_branches}
Branch the agent chose: {chosen_branch}
Score 1.0 if the chosen branch is the correct one given the state.
Score 0.0 if a different branch would have been clearly more appropriate.
Score 0.5 if the choice is defensible but not optimal.
Explain your reasoning in one sentence.""",
choices=["correct", "suboptimal", "wrong"],
model="turing_large",
)Wire it into the EvalTag pipeline for every span where gen_ai.agent.graph.node_id matches one of your decision nodes:
EvalTag(
type=EvalTagType.OBSERVATION_SPAN,
value=EvalSpanKind.CHAIN,
eval_name="RoutingAccuracy",
model=ModelChoices.TURING_LARGE,
mapping={
"state": "langgraph.node.state_at_decision",
"available_branches": "langgraph.edge.available_branches",
"chosen_branch": "langgraph.edge.chosen_branch",
},
)Track per-decision-node routing accuracy on the regression set as a first-class metric. The actionable signal is per-node: a router prompt that drifts is fixable in one prompt edit; a 1 percent drop in overall TaskCompletion is a forty-eight-hour bisect. Patterns for building custom judge rubrics: LLM-as-judge best practices in 2026.
Checkpoint replay: LangGraph’s superpower for eval
The checkpointer is the durability primitive that lets a long-running graph pause and resume. It is also the most underused evaluation lever in the framework. Every checkpoint is a serialized state plus the graph version that produced it. Save a checkpoint at every transition and every production failure becomes a deterministic regression case the moment you have its checkpoint ID.
The pattern:
- Configure the checkpointer (
Postgres,Sqlite, orMemory). Persist on every node transition, not just on completion. - On a failing production run, grab the checkpoint ID from the trace. traceAI emits
langgraph.checkpoint.idon every node span. - Replay the graph from that checkpoint:
graph.invoke(None, config={"configurable": {"thread_id": "...", "checkpoint_id": "..."}}). - Score the downstream trajectory with the four-layer evaluator stack.
- A/B prompt changes by replaying the same checkpoint against two graph versions and scoring the diff. Controlled experiment, not a hope.
A TrajectoryHashMatch deterministic check sits beside the LLM-judge layer: hash the ordered sequence of (node_name, state_diff) tuples and assert the hash is stable across replays. A drift means the graph is non-deterministic in a way it should not be (an unsignalled temperature > 0, a tool call that depends on wall-clock time, a parallel reduce that did not stabilise ordering). Costs nothing per replay and catches a class of bug that ages into a production flake.
Without checkpoint replay you are guessing whether a bug reproduces. With it you are running an experiment.
Building a regression set from checkpoints
Synthetic test inputs reflect the test author’s assumptions. Sample real production checkpoints instead.
- Filter spans where any
gen_ai.evaluation.score.valuedropped below threshold. - Group by transition shape: cluster on
langgraph.graph.node_count, the failing node’sgen_ai.agent.graph.node_id, and the chosen branch on conditional-edge spans. - Promote representative checkpoints from each cluster, paired with the expected downstream trajectory annotated by a reviewer.
- Tag with metadata: which release shipped the regression, which user segment, which rubric dropped.
- Re-run on every PR by replaying the saved checkpoints. CI gate fails the PR if any rubric drops more than 2 points from baseline.
Every incident becomes a deterministic test case. For threshold-calibration cadence: LLM evaluation playbook for 2026.
Closing the loop: Error Feed plus agent-opt
HDBSCAN soft-clustering runs over span attributes plus trajectory embeddings. Soft clustering means a single failing trajectory can belong to multiple named clusters, which matches how real defects manifest: one bug can cause both “retry loop on search” and “wrong conditional edge on date-range queries.” A Claude Sonnet 4.5 JudgeAgent reads the cluster (30-turn budget, eight span-tools, prompt-cache hit near 90 percent) and writes an immediate_fix artifact: suspected root cause, suggested prompt or rubric edit, regression checkpoints to add. Ships as a Linear issue today (Slack, GitHub, Jira, PagerDuty on roadmap).
Cluster shapes that surface most often on LangGraph projects:
- “Retry loop on tool X.” Ambiguous tool description or a node prompt that does not acknowledge tool failure.
- “Wrong conditional edge on date-range queries.” A router prompt that does not handle a specific state shape.
- “Reducer drops constraint after parallel fan-in.” A reducer function bug, not a prompt.
- “Sub-graph silently returned partial state.” A missing checkpoint on the sub-graph compile call.
- “Checkpoint replay diverges from production trajectory.” Hidden non-determinism (wall-clock, unsignalled temperature, unstable parallel ordering).
agent-opt optimises against the named clusters. Six optimisers ship: RandomSearchOptimizer, BayesianSearchOptimizer (Optuna-backed, resumable, teacher-inferred few-shot), MetaPromptOptimizer, ProTeGi, GEPAOptimizer, PromptWizardOptimizer. Each per-node prompt and each router prompt is a separate study target. EarlyStoppingConfig kills underperforming mutation arms. Direct trace-stream-to-dataset is roadmap; the regression-set path through Error Feed clusters ships today. Background: automated optimization for agent systems.
How Future AGI ships this for LangGraph
- ai-evaluation SDK (Apache 2.0).
Evaluator, 60-plusEvalTemplateclasses (TaskCompletion,LLMFunctionCalling,AnswerRefusal,Groundedness,ContextAdherence), theCustomLLMJudgethat carriesNodeInputContract,StateDiffCorrectness,RoutingAccuracy. 13 guardrail backends (9 open-weight), 8 sub-10ms Scanners, four distributed runners (Celery, Ray, Temporal, Kubernetes). - traceAI (Apache 2.0). LangGraph submodule inside
LangChainInstrumentorwith thelanggraph.*attribute set, the cross-frameworkgen_ai.agent.graph.*namespace, theEvalTagmechanism for server-side evals, four-way pluggable semantic conventions. - Future AGI Platform. Self-improving evaluators tuned by feedback, in-product custom rubric authoring, classifier-backed scoring at lower per-eval cost than Galileo Luna-2. Error Feed sits inside with HDBSCAN clustering, the Sonnet 4.5 JudgeAgent, the 5-category 30-subtype taxonomy, the 4-D trace score, the
immediate_fixartifact. - agent-opt (Apache 2.0). Six optimisers, per-study separation for per-node prompts and router prompts,
EarlyStoppingConfig. - Agent Command Center. Self-hosts in your VPC for the LLM calls underneath every LangGraph node. 100-plus providers, 18-plus built-in guardrail scanners, exact and semantic caching; SOC 2 Type II, HIPAA, GDPR, CCPA certified.
Honest tradeoff: if your LangGraph is a five-node linear pipeline with no conditional edges, a single TaskCompletion rubric is enough. The four-layer stack earns its weight on graphs with real branching, retries, sub-graphs, or long-running checkpointed state. That is most LangGraph agents in production by month three. Framework-choice background: CrewAI vs LangGraph vs AutoGen and the best LangGraph alternatives.
What to do this week
One graph, end to end. Five steps.
- Install
fi-instrumentation-otelandtraceAI-langchain. Callregister()andLangChainInstrumentor().instrument()in process bootstrap. Verify a few trajectories show up with thelanggraph.*attributes populated and the checkpoint IDs on every node span. - Turn on the checkpointer if you have not. Persist on every transition, not just on completion. The replay loop is only useful if the checkpoints exist.
- Add the four EvalTags for
LLMFunctionCalling,TaskCompletion, aRoutingAccuracycustom judge, and aStateDiffCorrectnesscustom judge scoped to the five highest-fan-out nodes. - Open Error Feed after a week of traffic. Promote two cluster representatives into a regression set built from checkpoints, not synthetic inputs. Replay each checkpoint in CI on every PR.
- Run agent-opt on the regression set with
BayesianSearchOptimizerandEarlyStoppingConfig. Tune the lowest-scoring router prompt as a single study target. Verify the winner does not regress any of the four layers.
The graph topology that LangGraph gives you is also what makes the eval honest, as long as the tracer captures it. The teams shipping reliable agents in 2026 stopped grading the final message and started grading the state machine. Trace, evaluate the four transition properties, cluster failures, replay checkpoints, optimise against the regression set, ship the fix.
Related reading
- The Definitive Guide to AI Agent Evaluation (2026)
- Evaluating Tool-Calling Agents (2026)
- Evaluating AutoGen Agents (2026)
- Evaluating CrewAI Agents (2026)
- Agent Passes Evals, Fails Production (2026)
- LLM-as-Judge Best Practices (2026)
- Automated Optimization for Agent Systems (2026)
- Instrument Your AI Agent with traceAI
- Trace and Debug Multi-Agent Systems
- Best LangGraph Alternatives (2026)
Frequently asked questions
Why is message-level evaluation wrong for a LangGraph agent?
What does a state-transition eval actually score?
What does traceAI's LangGraphInstrumentor capture that generic OTel tracers lose?
How do I evaluate conditional-edge routing in LangGraph?
Why does checkpoint-replay determinism matter for evaluation?
What's the closed-loop story for LangGraph failures with Future AGI?
Does Future AGI ship trace-driven optimization for LangGraph today?

Evaluate Pydantic AI agents that call MCP tools in 2026: per-typed-output rubrics, tool-call argument fidelity, MCP security checks, dependency invariants.


Evaluating LLM agent handoffs in 2026: the handoff is the cross-framework eval unit. Four rubrics, per-handoff spans, CI gates, and Error Feed clustering.

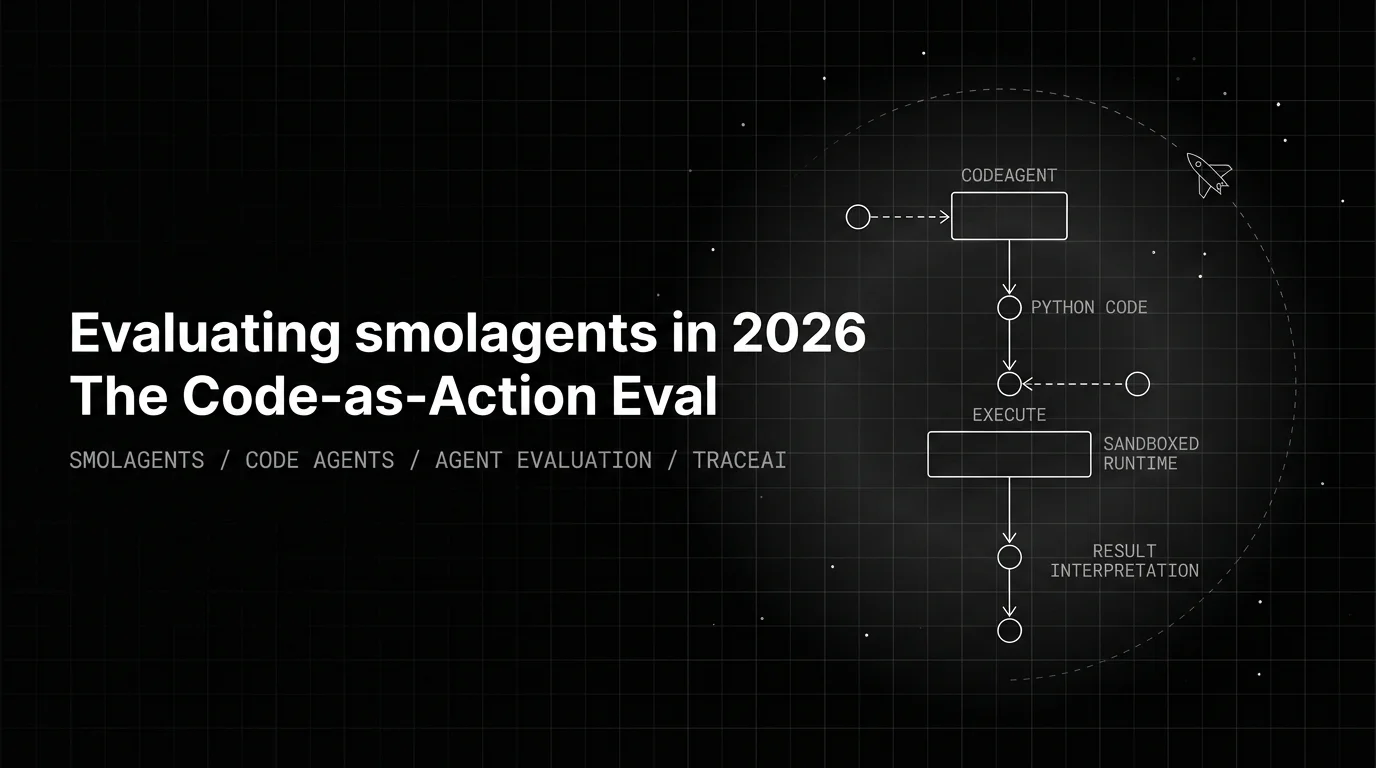
smolagents' CodeAgent makes the plan AS code, so the eval changes shape: code synthesis correctness, sandbox safety, and result-interpretation fidelity.
