Evaluating AutoGen Agents: The Handoff Is the Unit (2026)
Evaluating AutoGen agents in 2026: the handoff is the eval unit. Three failure modes, three rubrics, per-pair spans, and the production loop.
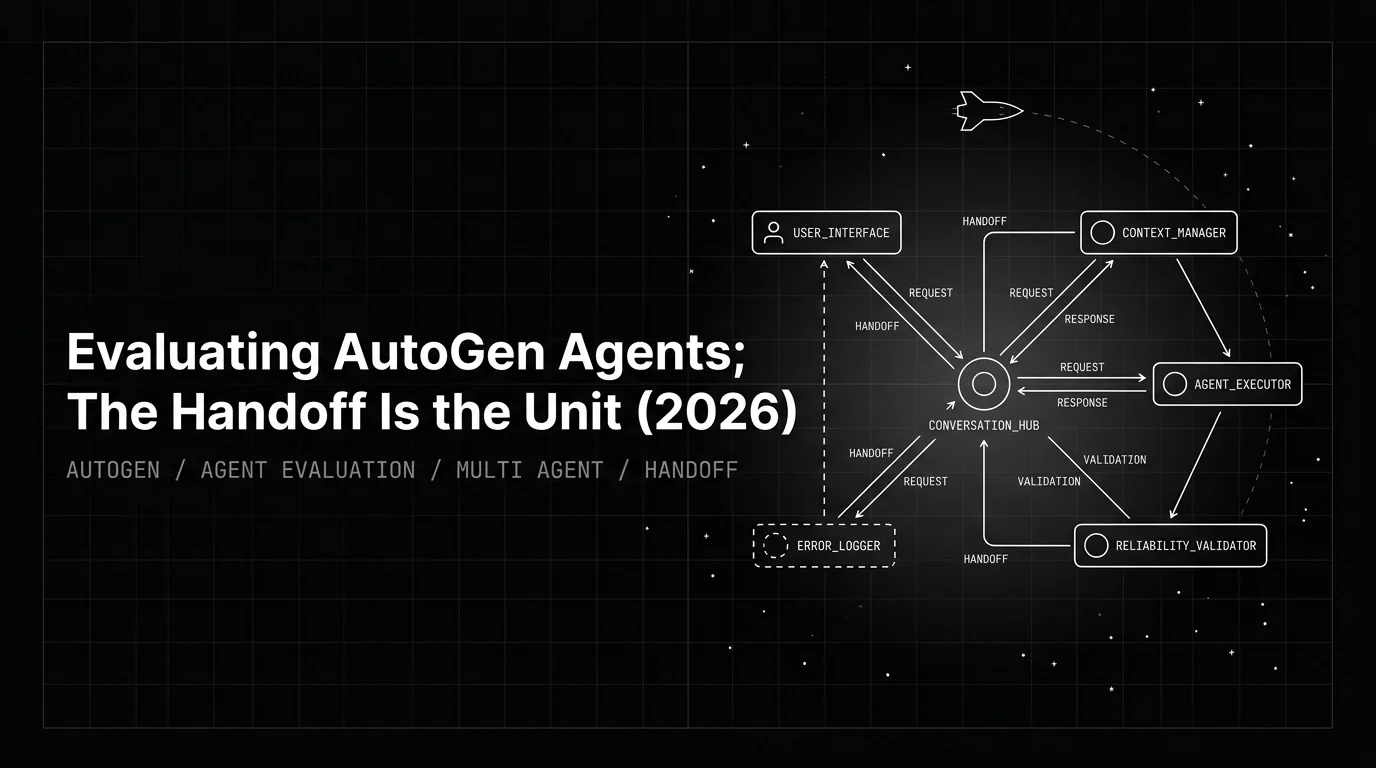
Table of Contents
A three-agent AutoGen team scores 0.91 on TaskCompletion in CI. The researcher cites Kaplan 2020 correctly. The critic flags two weak claims. The planner stitches a clean summary. A week later, the same team scores 0.89 but the consensus quietly contradicts the critic’s correction from turn three, and the cost per run has doubled because the planner started drafting in the researcher’s turns. Nothing in the per-agent rubric moved. Everything broke in the seams.
Multi-agent eval is not single-agent eval times N. The unit is the handoff: agent A’s output becomes agent B’s input, and most multi-agent failures live in handoff misinterpretation, role drift, and group-coherence collapse — not in the quality of any individual turn. This post is the working pattern for evaluating Microsoft AutoGen agents in 2026: the three handoff failure modes, the three rubrics that catch them, the traceAI instrumentor that emits per-pair spans, and the Error Feed loop that clusters failures by handoff defect.
Why single-agent rubrics miss multi-agent failures
A single ConversableAgent or AssistantAgent is a function. Input, system prompt, optional tool calls, output. Score it with TaskCompletion, LLMFunctionCalling, and a CustomLLMJudge for the response. The unit of evaluation is the (input, output) pair. The rubric reads one turn and decides.
An AutoGen v0.4 team — RoundRobinGroupChat, SelectorGroupChat, Swarm, or MagenticOneGroupChat — does not behave that way. Each agent’s output becomes the next agent’s input via the team’s message channel. The receiver does not see the full state; it sees the previous turn plus whatever context the orchestrator chose to pass. The team converges (or fails to converge) through an ordered sequence of these handoffs.
The math compounds in the seams. A team where every individual agent scores 0.95 on per-turn quality can still ship a wrong consensus 30 percent of the time if the handoffs between agents drop one constraint per pair. Per-agent rubrics will not catch it: every turn looks clean in isolation. Aggregate TaskCompletion on the final consensus catches half the failures and tells you nothing about which handoff broke. The diagnostic signal lives at the agent-pair level, and that is precisely the level a generic OpenTelemetry tracer flattens away.
This is also where AutoGen differs from LangGraph. LangGraph evaluation hangs on node and edge correctness over a fixed graph; AutoGen evaluation hangs on handoff fidelity over a dynamic team where the orchestrator picks the next speaker at runtime. The LangGraph evaluation tutorial covers the graph-topology side; the definitive agent evaluation guide covers the shared spine across both.
The handoff as the unit of evaluation
A handoff is a span pair: the AGENT span for the sender’s turn, followed by the AGENT span for the receiver’s turn, joined by the team’s message channel and (in v0.4) sometimes an explicit HANDOFF span emitted by Swarm or MagenticOneGroupChat. The eval unit is (sender_turn, receiver_turn, shared_context), not the individual turn.
This reframes everything. The regression set is a list of expected handoff sequences with expected role coverage, not a list of expected final answers. The CI gate runs assertions against per-handoff scores, not against one team-level number. The Error Feed clusters failing teams by handoff pattern (which sender-receiver pair broke), not by final-answer category. The optimizer tunes the manager’s selection prompt and each agent’s SYSTEM message as separate study targets because the failure attribution is per-pair.
A working definition: a handoff is correct when the receiver’s first reply preserves the sender’s constraints, addresses the sender’s open question, and stays inside its own role. A handoff is broken when any one of those three fails. We give the three failure modes names below and score each one with a dedicated rubric so the diagnostic is localised the moment a regression lands.
Three handoff failure modes
These three modes cover roughly 80 percent of the multi-agent defects we see in production AutoGen teams. They are not exhaustive, but they are the modes that consistently survive a single-agent rubric pass and surface only when you score the handoff.
Failure mode 1: handoff interpretation
The sender produces a turn with constraints, partial conclusions, and open questions. The receiver’s first reply drops one of them. A planner’s turn says “research scaling laws, but exclude Chinchilla because the user already has it.” The researcher’s next turn cites Chinchilla. The constraint vanished in the receiver’s parse of the prior turn. The downstream consensus carries the missing-constraint bug, and no per-agent rubric will flag it because the researcher’s citation was technically clean.
Other interpretation defects in this bucket: the receiver paraphrases the sender’s claim with a number flipped, the receiver fabricates context the sender never produced (a “we already agreed on X” reference to a turn that does not exist), and the receiver answers the sender’s question with a different question instead of an answer.
Failure mode 2: role drift
Each AutoGen agent has a SYSTEM message that defines its role: the planner decomposes, the researcher cites, the critic challenges. Role drift is what happens when an agent answers outside its role. The critic starts proposing plans. The planner starts reviewing citations. The researcher starts drafting executive summaries.
Drift breaks two things at once. The role-specific rubric you wrote for that agent stops being a meaningful test because the agent is no longer doing the job the rubric measures. And the team’s division of labour collapses, which is the reason you ran a multi-agent setup instead of a single planner-with-tools in the first place. Drift is also the failure mode most sensitive to model updates: a refreshed gpt-4o checkpoint that has been trained to be more helpful will drift more aggressively than the previous one, and a per-agent RoleAdherence rubric is the only thing that catches the shift before the cost graph does.
Failure mode 3: group coherence collapse
The team produces an answer that contradicts an earlier turn that was actually correct. The researcher cited Kaplan 2020. Two turns later, the critic mis-reads the citation and reports it as Hoffmann 2022. The planner stitches the consensus around the critic’s wrong attribution, and the final answer carries the corruption. None of the three agents made a turn that fails its own rubric in isolation — the planner’s summary is well-written, the critic’s challenge is well-formed, the researcher’s original citation was correct. The team-level coherence broke between them.
Coherence collapse also shows up as premature termination (the team converges on a partial answer that nobody flagged), late termination (the team loops on a critique-revise cycle because the manager keeps picking the critic after the critic), and consensus that ignores the debate entirely (the manager picks a speaker that paraphrases the user request back instead of synthesising the prior turns).
Per-handoff rubrics: HandoffFidelity, RoleAdherence, GroupCoherence
Three rubrics, one per failure mode, all built on the CustomLLMJudge interface from the ai-evaluation SDK. The Future AGI Platform’s classifier-backed scoring runs these at lower per-eval cost than Galileo Luna-2 once the rubrics stabilise, but the SDK is the starting surface.
from fi.evals import Evaluator
from fi.evals.templates import (
TaskCompletion,
LLMFunctionCalling,
AnswerRefusal,
ConversationCoherence,
)
from fi.evals.judge import CustomLLMJudge
evaluator = Evaluator(fi_api_key="...", fi_secret_key="...")
handoff_fidelity = CustomLLMJudge(
name="HandoffFidelity",
rubric=(
"Given the sender's turn and the receiver's first reply, score whether the "
"receiver preserved every explicit constraint, addressed every open question, "
"and did not fabricate context the sender never produced. "
"1.0 = full fidelity. 0.5 = one constraint dropped or one unanswered question. "
"0.0 = multiple drops or fabricated context."
),
input_mapping={
"sender_turn": "sender_turn_text",
"receiver_turn": "receiver_turn_text",
"shared_context": "team_message_channel_summary",
},
)
role_adherence = CustomLLMJudge(
name="RoleAdherence",
rubric=(
"Given the agent's SYSTEM message and the agent's current turn, score whether "
"the turn stayed inside the role's contract. Penalise role bleed: a critic that "
"started planning, a researcher that started critiquing, a planner that started "
"drafting executive summaries. 1.0 = strict adherence. 0.0 = clear role drift."
),
input_mapping={
"system_message": "agent.system_message",
"agent_turn": "agent_turn_text",
},
)
group_coherence = CustomLLMJudge(
name="GroupCoherence",
rubric=(
"Score whether the team's final consensus is consistent with the prior turns. "
"Penalise: contradiction of an earlier correct turn, propagation of a refuted "
"claim, consensus that ignores the debate, premature or late termination. "
"Score 0.0 to 1.0."
),
input_mapping={
"team_run": "team_run_transcript",
"final_consensus": "team_run_final_message",
},
)Run them in layers. TaskCompletion, LLMFunctionCalling, AnswerRefusal, ConversationCoherence, and ConversationResolution from the SDK cover the single-agent and conversation baseline. The three handoff rubrics above cover the multi-agent seams. Wire per-axis thresholds into the CI gate — a reasonable starting set is HandoffFidelity >= 0.85, RoleAdherence >= 0.90 per agent, GroupCoherence >= 0.80 per team_run — and bind the assertions to the regression set per team config (which agents, which models, which selection method, which termination condition).
The CI gate fails on the failing axis, not on a single aggregate. One bisect instead of three days. The LLM evaluation playbook covers the threshold-calibration cadence in more depth, and the agent passes evals fails production post covers the axis-blindness pattern.
traceAI AutoGen instrumentor: agent-pair span attribution
A handoff rubric needs a handoff span. The AutogenInstrumentor from traceAI emits that span tree without code changes inside your agent definitions. It supports AutoGen v0.4 AgentChat (autogen-agentchat>=0.4.0) and the legacy v0.2 API, and it wraps the team classes the v0.4 surface ships: RoundRobinGroupChat, SelectorGroupChat, Swarm, MagenticOneGroupChat, plus the BaseGroupChat base class.
pip install autogen-agentchat
pip install fi-instrumentation-otel traceAI-autogen
pip install ai-evaluationimport os
os.environ["FI_API_KEY"] = "..."
os.environ["FI_SECRET_KEY"] = "..."
from fi_instrumentation import register
from fi_instrumentation.fi_types import ProjectType
from traceai_autogen import AutogenInstrumentor
trace_provider = register(
project_type=ProjectType.OBSERVE,
project_name="autogen-research-team",
)
AutogenInstrumentor().instrument(tracer_provider=trace_provider)After this call, every team run in the process emits a span tree with the per-handoff signal the three rubrics need.
The instrumentor patches BaseChatAgent.on_messages to emit one AGENT_RUN span per turn, tagged with autogen.agent.name, autogen.agent.type, autogen.agent.system_message, autogen.round.number, and autogen.round.speaker. Tool calls inside a turn become TOOL_CALL spans nested under the owning agent, with autogen.tool.name, autogen.tool.args, autogen.tool.result, and autogen.tool.is_error. Per-agent tool-use scoring becomes a filter, not a parse.
The handoff signal is explicit. Swarm and MagenticOneGroupChat emit a HANDOFF span kind whenever control transfers between agents, with autogen.handoff.source, autogen.handoff.target, and autogen.handoff.content attributes that carry the sender, the receiver, and the message that crossed the seam. For RoundRobinGroupChat and SelectorGroupChat, the handoff is recoverable from consecutive AGENT_RUN spans inside the same team_run parent: the previous turn is the sender, the current turn is the receiver, the shared context is the team_message_channel.
The team itself gets a team_run parent span with autogen.team.type (which v0.4 team class), autogen.team.participants (the JSON list of agent names), autogen.team.max_turns, autogen.team.termination_condition, and autogen.task.stop_reason. Termination-calibration evals read autogen.task.stop_reason directly. Per-agent cost and latency roll up from the underlying LLM spans tagged by agent name. The trace and debug multi-agent systems guide covers the cross-framework topology if you also run CrewAI or LangGraph, and the evaluating LLM agent handoffs post covers the cross-framework handoff rubric pattern.
Production observability and Error Feed clustering by handoff failure
CI is necessary, not sufficient. A 50-scenario regression set is a snapshot; production is a river. Score the live trace stream with the same three handoff rubrics and you get the regression signal the offline set cannot have, because the offline set was frozen before users found the failure mode. EvalTag on the registered tracer attaches HandoffFidelity, RoleAdherence, and GroupCoherence to the matching spans server-side, at zero inline latency.
Error Feed is the loop closer inside the eval stack. Failing team runs flow into ClickHouse with their span embeddings. HDBSCAN soft-clustering groups them into named issues. The cluster shapes that turn up most often on AutoGen teams are handoff-shaped, which is the entire point of scoring at the handoff level.
- Dropped-constraint clusters. The receiver consistently loses a specific constraint type at the planner-to-researcher handoff (budget caps, date ranges, exclusion lists, currency). The Judge’s
immediate_fixis usually a tighter planner SYSTEM message that emits constraints in a JSON block instead of prose. - Role-bleed clusters. The critic starts drafting plans after a refreshed model checkpoint lands.
RoleAdherencedrops 8 points overnight. Theimmediate_fixis a stricter role contract in the critic SYSTEM message plus a one-shot example of the role boundary. - Coherence-collapse clusters. A wrong claim from turn two propagates to the consensus. The
immediate_fixis a manager selection prompt change that forces the critic to re-read turn two before the planner synthesises, plus a regression case for the offline set.
Per cluster, a Claude Sonnet 4.5 JudgeAgent runs a 30-turn investigation across eight span-tools (read_span, get_children, get_spans_by_type, search_spans, plus a Haiku Chauffeur for spans over 3000 characters). Prompt-cache hit ratio sits around 90 percent. The Judge writes three artifacts engineers actually read: a 5-category, 30-subtype taxonomy entry, the 4-D trace score (factual_grounding, privacy_and_safety, instruction_adherence, optimal_plan_execution, each 1 to 5), and an immediate_fix naming the change to ship today. Linear OAuth is wired today; Slack, GitHub, Jira, and PagerDuty are on the roadmap.
The fix feeds back to the platform’s self-improving evaluators so the rubric scores sharper on that failure mode the next run. The cluster’s representative team runs become regression cases. The next PR touching that handoff has to clear them. agent-opt then tunes the per-agent SYSTEM messages and the manager’s selection prompt as separate study targets. BayesianSearchOptimizer or GEPAOptimizer with EarlyStoppingConfig works well, and the per-agent separation keeps a winning tweak on the critic from being masked by a flat planner. The automated optimization for agents post covers the optimizer mix.
Common AutoGen eval anti-patterns
Four mistakes that hide each of the failure modes above.
Scoring only the final consensus. TaskCompletion on the final message misses every handoff defect that did not quite poison the final string. Score per-handoff or you lose the diagnostic that tells you which agent pair to fix.
One rubric for all agents. Each agent has a different role. Scoring all of them against a single TaskCompletion rubric blurs role-specific failures into one team-level average and produces nothing actionable. RoleAdherence has to be per-agent, configured against that agent’s SYSTEM message.
No handoff span, only the team transcript. A generic OTel tracer collapses a team run into one conversation span. The handoff is invisible. HandoffFidelity cannot run because there is no sender-receiver pair to score against. Use the AutogenInstrumentor or build the same span shape manually before attempting handoff eval.
Treating model updates as silent. Refreshed checkpoints of gpt-4o, claude-sonnet-4-5, and the open-weight roster drift role behaviour first and final-answer quality second. RoleAdherence is the earliest indicator. Pin model versions in your team config, run the regression set on every refresh, and track per-agent RoleAdherence trend lines per checkpoint.
How Future AGI ships the full multi-agent eval stack
Three surfaces, one loop, no separate products to glue together.
ai-evaluation SDK (Apache 2.0) ships the Evaluator, the 60-plus EvalTemplate classes (TaskCompletion, LLMFunctionCalling, AnswerRefusal, ConversationCoherence, ConversationResolution, Groundedness, ContextAdherence, ChunkAttribution, 11 CustomerAgent* templates), the CustomLLMJudge that carries HandoffFidelity, RoleAdherence, and GroupCoherence, 13 guardrail backends (9 open-weight), and four distributed runners (Celery, Ray, Temporal, Kubernetes) for the case where a 50-scenario regression set across three handoff rubrics outgrows one process.
traceAI (Apache 2.0) ships the AutogenInstrumentor for v0.2 plus v0.4 AgentChat (RoundRobinGroupChat, SelectorGroupChat, Swarm, MagenticOneGroupChat), 50-plus other AI surface instrumentors across Python, TypeScript, Java, and C#, the HANDOFF span kind with source/target/content attributes, and the EvalTag mechanism that attaches a rubric to a span kind so evals run server-side without polling.
Future AGI Platform ships the self-improving evaluators tuned by feedback, in-product custom rubric authoring, and classifier-backed scoring at lower per-eval cost than Galileo Luna-2. Error Feed sits inside the platform with HDBSCAN clustering, the Sonnet 4.5 JudgeAgent with the 8-tool span investigator, the 5-category 30-subtype taxonomy, the 4-D trace score, and the immediate_fix artifact.
agent-opt closes the loop with six optimizers (RandomSearchOptimizer, BayesianSearchOptimizer, MetaPromptOptimizer, ProTeGi, GEPAOptimizer, PromptWizardOptimizer) consuming the handoff rubrics as the optimization objective. Each agent’s SYSTEM message and the manager’s selection prompt are separate study targets with shared EarlyStoppingConfig. The direct trace-stream-to-agent-opt connector is the active roadmap item; the eval-driven path through the regression set ships today.
Honest tradeoff: if your stack is one ConversableAgent and a tool registry, a lighter framework-specific tracer plus a hand-rolled TaskCompletion rubric is enough. The eval stack above earns its weight when you run real teams — three-plus agents, mixed models, dynamic speaker selection, production traffic — and the handoff is the unit that decides whether the team ships.
What to do this week
One team config, end to end. Five steps.
- Wire
AutogenInstrumentor().instrument(tracer_provider=trace_provider)into your existing AutoGen v0.4 project. Verify per-agentAGENT_RUNspans, per-toolTOOL_CALLspans, theteam_runparent, andHANDOFFspans (onSwarmorMagenticOneGroupChat) land in traceAI. - Build a 50-scenario regression set per team config. Tag each scenario with expected handoff sequence, expected role coverage per agent, and expected termination round range.
- Define
HandoffFidelity,RoleAdherence, andGroupCoherenceasCustomLLMJudgerubrics. Run them alongsideTaskCompletion,LLMFunctionCalling,AnswerRefusal,ConversationCoherence, andConversationResolutionfrom the SDK. - Wire per-axis thresholds into CI per team config. Start at
HandoffFidelity >= 0.85,RoleAdherence >= 0.90per agent,GroupCoherence >= 0.80per team_run. Tune as the dataset matures. - Turn on Error Feed. Watch the first week’s clusters. Promote each cluster’s representative team runs into the regression set. Run a
BayesianSearchOptimizerstudy on the handoff that ranks highest.
The teams shipping reliable multi-agent setups in 2026 stopped grading the consensus and started grading the seams. The framework gives you orchestration; the eval stack gives you the signal that keeps it honest, one handoff at a time.
Related reading
Frequently asked questions
Why is evaluating AutoGen agents different from evaluating a single LLM agent?
What is the handoff failure taxonomy for AutoGen group chats?
What does traceAI's AutogenInstrumentor capture that generic OpenTelemetry tracers miss?
Which Future AGI evaluators should I attach to an AutoGen team?
How does Error Feed cluster AutoGen failures by handoff failure mode?
Where does Future AGI ship the full multi-agent eval stack for AutoGen?

Evaluating LLM agent handoffs in 2026: the handoff is the cross-framework eval unit. Four rubrics, per-handoff spans, CI gates, and Error Feed clustering.

Evaluating CrewAI agents in 2026: role adherence as the primary metric, plus task delegation, crew coherence, and manager-worker fidelity.


Evaluating OpenAI Agents SDK in 2026: handoff correctness, output_type schema fidelity, guardrail invocation, tool-call accuracy across four primitives.
