Evaluating Google ADK Agents in 2026
Google ADK's opinionated primitives (Sequential, Parallel, Loop, sub-agent dispatch) demand ADK-native eval, not a LangChain rig in a trench coat.
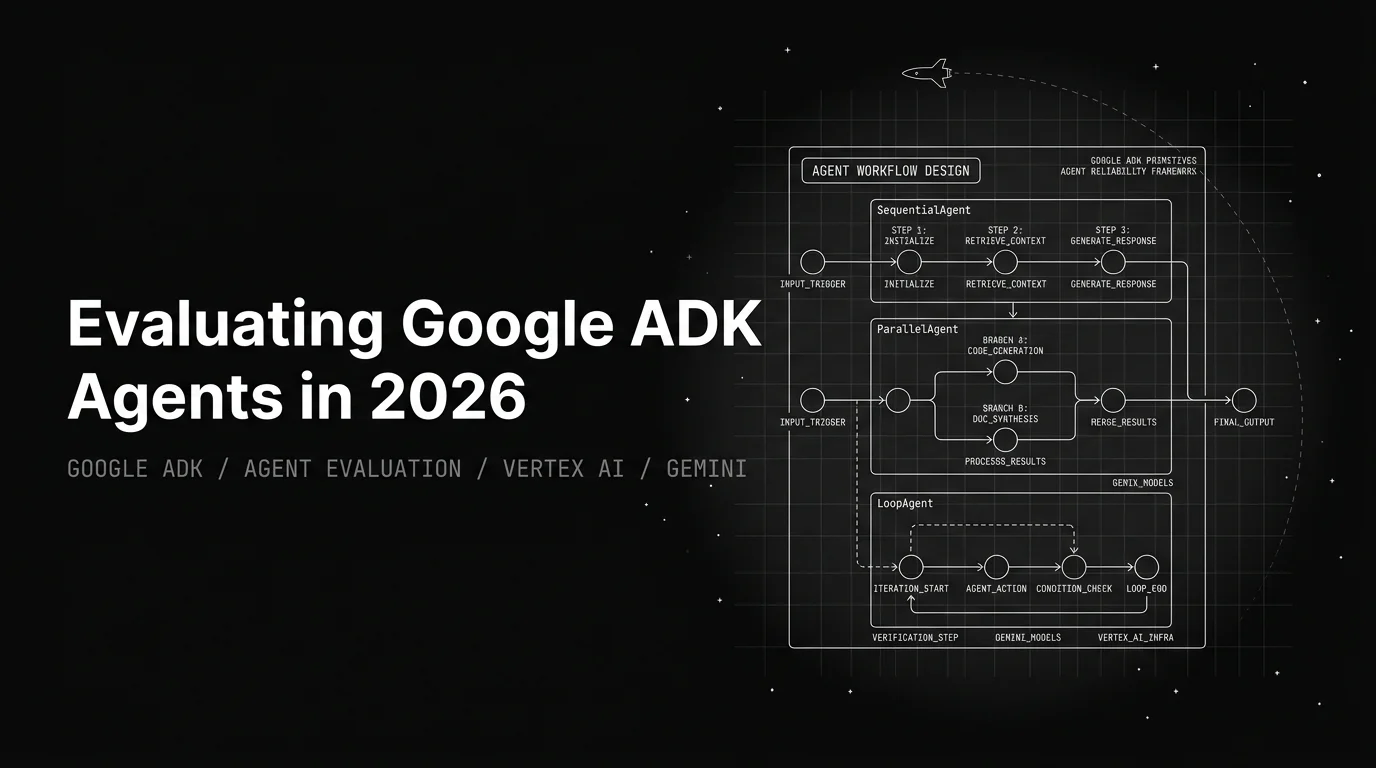
Table of Contents
Google ADK is the most opinionated agent framework on the market. SequentialAgent runs sub-agents in order. ParallelAgent runs them concurrently and merges. LoopAgent re-invokes until a condition holds. Sub-agent dispatch is a typed tool call (transfer_to_agent). VertexAiSearchTool and GoogleSearchTool are first-class registered tools, not user code. That opinion makes some eval primitives easy (the trace is structured) and others a problem (the rubrics ADK ships are built for the development inner loop and grade Google’s idea of correctness, not your domain’s). The eval that matches ADK reads the workflow primitive, scores sub-agent dispatch, separates ADK-tool failures from custom-tool failures, grades Vertex Search retrieval, and asserts coherence across parallel branches. This post is that eval, end to end.
Why ADK eval differs from AutoGen and CrewAI
AutoGen treats agents as participants in a group chat; the substrate is messages. CrewAI treats them as role-typed workers with a process over tasks; the substrate is tasks. ADK treats them as a tree of typed agents with workflow primitives that compose. The substrate is the workflow. That difference shows up in three places the eval has to handle.
Workflow primitives are part of the contract. A SequentialAgent’s correctness is a property of the order and what got dropped at each boundary. A ParallelAgent’s correctness is a property of the merge. A LoopAgent’s correctness is a property of the termination signal. Score per primitive or you cannot bisect the failure.
Sub-agent dispatch is a tool call, not a routing decision. AutoGen routes via a manager LLM. CrewAI routes via process configuration. ADK routes via transfer_to_agent, which the LLM emits as a function call that the framework intercepts. Dispatch failures look like tool-call failures in the trace, and you score them with the same function-calling rubric plus a sub-agent-name F1 with an irrelevance bucket. A generic LangChain or CrewAI rig does not have this surface.
The tool registry is two-tier. ADK ships managed tools (VertexAiSearchTool, GoogleSearchTool, BuiltInCodeExecutor, AgentTool) alongside your custom BaseTool subclasses. A custom tool either raises or returns; a managed tool returns a blob the model has to interpret. Mixing the two under one tool_correctness score hides Vertex Search retrieval regressions behind a strong global mean. For the wider framing, see agent observability vs evaluation vs benchmarking.
The five ADK-native axes
A complete eval suite for an ADK agent covers five axes that no generic agent evaluation framework gives you out of the box.
1. Sub-agent dispatch correctness
Dispatch is the load-bearing decision in any multi-agent ADK build. A coordinator with three sub-agents (billing, support, escalation) is exactly one bad transfer away from sending a refund request to support. Three sub-scores cover it.
- Sub-agent F1 with an irrelevance bucket. Macro-F1 across the registry with
no_transferas a class. Without the bucket, the over-dispatch failure where a prompt revision makes the coordinator bolder is invisible until users complain. - Scope preservation across the handoff. Read the Session snapshot on each side of the transfer and score whether the keys the coordinator wrote (
user_id,intent,verified_human) survived into the sub-agent’s context. - Return-to-coordinator behavior. Multi-hop tasks break in two ways: the sub-agent never returns, or control returns but the coordinator forgets the original task. Score AGENT span tree depth against the gold trajectory and final-response match against the original user intent, not the sub-agent’s last output.
The traceAI google-adk instrumentor surfaces the transfer_to_agent call as a TOOL span and the receiving sub-agent run as a fresh AGENT span. Source: traceAI/python/frameworks/google-adk/traceai_google_adk/_wrappers.py. The eval reads the call graph off the trace; no manual logging.
2. ADK-tool registry vs custom-tool correctness
Split the rubric by tool class.
For custom BaseTool subclasses, score the four function-calling axes the ai-evaluation SDK ships as local heuristic metrics: function_name_match, parameter_validation, function_call_accuracy, plus return-payload utilization (Groundedness with the context slot pointed at the tool return). All four run deterministically off the TOOL span attributes. Source: ai-evaluation/python/fi/evals/metrics/function_calling/metrics.py.
For managed ADK tools, the question is the output, not the invocation. The model chose to call VertexAiSearchTool. That choice rarely fails. What fails is the response chain that conditions on what came back. Score managed tools downstream:
- VertexAiSearchTool: Recall@k on a labeled query-to-doc-id set against the configured datastore, plus Groundedness and ChunkAttribution on the final answer.
- GoogleSearchTool: snippets carry no stable chunk IDs. Score Groundedness against the snippet text directly, plus citation correctness (did the agent attribute the claim or hallucinate the source).
- BuiltInCodeExecutor: parse/run correctness on the return, plus output utilization.
- AgentTool (the wrapper that turns another agent into a tool): treat as sub-agent dispatch and score under axis 1.
The mistake we see most: treating Vertex Search like a function call. A tool_correctness score that runs function_name_match on VertexAiSearchTool will be 0.99 forever while the agent silently grounds on stale chunks. The split rubric makes the regression visible. For the broader pattern, see evaluating tool-calling agents.
3. Vertex Search retrieval quality
Vertex AI Search is the Google-specific RAG layer ADK ships out of the box. The retrieval call hides inside an opaque tool invocation, so a faithfulness regression looks identical to a model regression unless you score retrieval as its own step.
The pattern: build a labeled set of (query, expected_doc_ids, expected_chunk_text) against your datastore. Replay the agent’s retrieval. Compute Recall@k for k in 10. Pair with Groundedness and ChunkAttribution on the retrieved chunks, plus ContextAdherence and ChunkUtilization on the final answer. The split bisects the failure: low Recall@k says fix the datastore (chunking, embeddings, the index); high Recall@k with low Groundedness says fix the system prompt or swap the Gemini variant.
Two Vertex-specific gotchas worth naming. Datastore region (global, us, eu) silently affects retrieval quality on cross-language corpora; tag every test case with a language field and alert when any non-English subset falls more than 5 points below the English baseline. The implicit extractive vs generative answer mode can flip on a GCP console update; pin the mode and assert it in CI. For deeper RAG metrics, see the 2026 LLM evaluation playbook.
4. Parallel-execution coherence
ParallelAgent and LoopAgent are where ADK earns its opinionated reputation, and where the eval thins out fastest.
For ParallelAgent, three failure modes recur. Write-set collision: two branches write to the same Session key and the last writer wins. Deterministic check: collect the state_delta from each branch’s AGENT span, intersect the key sets, flag any non-empty intersection. Merge-decision correctness: when branches return conflicting answers, the parent picks one. Score the choice against a labeled rubric (a CustomLLMJudge named ParallelMergeCorrectness) and watch the per-branch contribution rate so a parent that always picks branch one is visible. Side-effect isolation: a branch that calls a write-class tool (charge_card, send_email, delete_record) before the merge leaks. Inspect every TOOL span inside a parallel block for verbs on a configurable write list and fail any unjustified call.
For LoopAgent, the termination condition is the failure surface. A loop that re-invokes until a state key is set will run forever if the sub-agent reads the wrong key. Track the iteration-count distribution against a gold budget. The instrumentor emits one AGENT span per iteration, so the count reads off the trace. For the broader frame, see best multi-agent debugging tools.
5. Vertex Agent Engine parity
ADK runs locally and deploys to Vertex AI Agent Engine. The two surfaces drift on safety_settings defaults, Gemini revision pinning, tool timeout values, and Session serialization. Run every scenario against both, capture the Session and tool trajectory, and score the pair with a VertexParity custom rubric. Gate deploys on a parity threshold. This is the cheapest insurance against the bug where the local agent works, the deployed agent works, and the two diverge in production. The deeper hosting-side patterns live in evaluating Vertex AI Agent Engine.
The traceAI Google ADK instrumentor
The trace is the unit. Two lines of setup attach OpenTelemetry to every ADK run in the process.
pip install google-adk traceai-google-adk ai-evaluationfrom fi_instrumentation import register, ProjectType
from traceai_google_adk import GoogleADKInstrumentor
trace_provider = register(
project_type=ProjectType.OBSERVE,
project_name="adk-prod",
)
GoogleADKInstrumentor().instrument(tracer_provider=trace_provider)After that, every Runner.run_async emits a CHAIN span, every BaseAgent invocation emits an AGENT span with gen_ai.agent.name, every BaseTool call emits a TOOL span with gen_ai.tool.name and gen_ai.tool.description, and every Gemini call emits an LLM span with gen_ai.image.* and gen_ai.voice.* attributes for multi-modal payloads. The standard fi.span.kind taxonomy applies (CHAIN, AGENT, LLM, TOOL, RETRIEVER, GUARDRAIL, EVALUATOR), so the same evaluator runs on a single agent and on a SequentialAgent + ParallelAgent composition without rewriting the rubric. For distributed ADK using A2A across processes, traceAI ships A2A_CLIENT and A2A_SERVER span kinds.
Wiring the five axes into ai-evaluation
The ai-evaluation SDK (Apache 2.0) ships 60+ EvalTemplate classes, 13 guardrail backends, and four distributed runners (Celery, Ray, Temporal, Kubernetes) that parallelize the eval across Gemini variants and Vertex datastore regions without changing the rubric code.
from fi.evals import Evaluator
from fi.evals.templates import (
EvaluateFunctionCalling,
TaskCompletion,
Groundedness,
ContextAdherence,
ChunkAttribution,
ChunkUtilization,
AnswerRefusal,
CustomLLMJudge,
)
sub_agent_dispatch = CustomLLMJudge(
name="SubAgentDispatchCorrectness",
rubric=(
"Score 1 if the coordinator transferred to the expected sub-agent "
"(or correctly did not transfer when no_transfer was expected), "
"preserved the required Session keys across the handoff, and "
"returned control to the coordinator on multi-hop tasks. "
"Use AGENT span tree and the transfer_to_agent TOOL span attributes."
),
)
vertex_search_recall = CustomLLMJudge(
name="VertexSearchRecallAtK",
rubric=(
"Score the fraction of expected_doc_ids that appear in the "
"VertexAiSearchTool TOOL span's results, top-5. Penalize if "
"Groundedness on the retrieved chunks is below 0.85."
),
)
parallel_merge = CustomLLMJudge(
name="ParallelMergeCorrectness",
rubric=(
"Given conflicting branch outputs from a ParallelAgent and the "
"merged parent answer, score whether the merge chose the branch "
"whose answer best matches the gold response. Flag write-set "
"collisions and unjustified side-effect tool calls in branches."
),
)
evaluator = Evaluator()
report = evaluator.evaluate(
eval_templates=[
EvaluateFunctionCalling(),
TaskCompletion(),
Groundedness(),
ContextAdherence(),
ChunkAttribution(),
ChunkUtilization(),
AnswerRefusal(),
sub_agent_dispatch,
vertex_search_recall,
parallel_merge,
],
inputs=golden_set,
)The golden set carries the ADK-specific labels.
from fi.evals import TestCase
golden_set = [
TestCase(
input="Refund my last order, the food was cold.",
expected_transfer_agent="billing",
expected_session_keys=["user_id", "order_id", "verified_human"],
expected_doc_ids=["refund_policy_v3", "order_4421"],
retrieval_context_required=True,
metadata={
"scenario": "refund_dispatch",
"workflow_primitive": "SequentialAgent",
"should_block": False,
},
),
# 50-100 cases per route, stratified by sub-agent, workflow primitive,
# Vertex Search datastore region, and Gemini variant
]Run the suite across every Gemini variant the agent might resolve to. The default ADK matrix in 2026 is gemini-2.5-pro, gemini-2.5-flash, gemini-2.5-flash-lite, plus the Live variants for voice. The Ray runner finishes a 200-case suite across four variants in single-digit minutes on a modest cluster.
The SDK also exposes enable_auto_enrichment() and enrich_span_with_evaluation(), which attach the score and reason back onto the scored span. Observe then shows per-turn quality next to per-turn latency and cost on the same timeline; cross-axis debugging becomes one trace view instead of three dashboards.
CI gate: per-axis thresholds, not an aggregate
The bug is treating one agent_score as a ship gate. A 0.85 aggregate hides a 0.62 on sub-agent dispatch behind a 0.97 on tool selection, and the production failure rides on the dispatch layer. Wire per-axis assertions.
# config.yaml for `fi run`
assertions:
- "sub_agent_dispatch.score >= 0.95 for at_least 95% of cases"
- "function_call_accuracy.score >= 0.90 for at_least 90% of cases"
- "vertex_search_recall_at_5.score >= 0.85 for at_least 90% of cases"
- "groundedness.score >= 0.90 for at_least 90% of cases"
- "parallel_merge.score >= 0.90 for at_least 90% of cases"
- "task_completion.score >= 0.85 for at_least 90% of cases"
- "vertex_parity.score >= 0.92 for at_least 95% of cases"When the gate fails, the failing assertion name is the root cause. One bisect instead of three days.
Production observability and Error Feed
CI is necessary, not sufficient. The eval set is a snapshot; production is a river. Score the live trace stream with the same rubrics and you get the regression signal the offline set cannot have, because the offline set was frozen before users found the failure.
Error Feed sits inside the eval stack. Failing ADK traces land in ClickHouse with their span embeddings. HDBSCAN soft-clustering groups them. Each cluster fires a JudgeAgent on Claude Sonnet 4.5 for a 30-turn investigation across eight span-tools (read_span, get_children, get_spans_by_type, search_spans, plus a Haiku Chauffeur for spans over 3000 characters, with ~90% prompt-cache hit).
Per cluster, the Judge writes three artifacts engineers read: a 5-category, 30-subtype taxonomy, a 4-D trace score (factual grounding, privacy and safety, instruction adherence, optimal plan execution; 1-5 each), and an immediate_fix. On ADK the recurring clusters look like:
- “Coordinator skips the
billingtransfer on refund intent whenverified_humanis false.” Fix: dispatch regardless of verification state and let billing handle the check. - “VertexAiSearchTool returns zero results in
eu-west1for German queries; LoopAgent never terminates.” Fix: pin datastore toglobal, re-index multilingual content, add a max-iteration guard. - “ParallelAgent branches both write
user_intentand the second branch wins.” Fix: namespace state keys per branch (branch_a.user_intent) and resolve in the merge.
Each fix feeds the Platform’s self-improving evaluators, so the next eval run already knows the failure mode. Linear is the only ticket destination wired today; Slack, GitHub, Jira, and PagerDuty are on the roadmap. For the loop from named issue back to fixed agent, automated optimization for agents walks through pointing one of agent-opt’s six optimizers (RandomSearch, BayesianSearch with Optuna, MetaPrompt, ProTeGi, GEPA, PromptWizard) at the ADK agent’s instruction field with the eval suite as the scoring function.
Five ADK anti-patterns
Patterns we see often enough to name.
- Treating ADK’s built-in evaluators as the production eval.
final_response_match_v2,tool_trajectory_avg_score,hallucinations_v1,safety_v1are useful for the development inner loop. They do not see sub-agent dispatch, do not separate VertexAiSearchTool from custom tools, and do not run on the live trace stream. Use them locally; do not promote them to the CI gate. - One
tool_correctnessscore across the registry. Score managed ADK tools on their output. Score custom BaseTool subclasses on function-calling axes. Mixing the two hides Vertex Search retrieval regressions behind strong global means. - No irrelevance bucket on sub-agent dispatch. Without
no_transferas a class, the over-dispatch failure where a prompt revision makes the coordinator bolder is invisible until users complain. - Skipping parallel-execution write-set checks. A ParallelAgent that lets two branches write to the same Session key is a race condition shaped like an agent.
- Single-variant golden set when production routes across Gemini variants. A pass on
gemini-2.5-prois not a pass ongemini-2.5-flash. Run the suite against every variant the agent might resolve to.
How Future AGI ships the ADK eval stack
Three packages do the work. They are designed to be used together, but ship independently.
traceAI (Apache 2.0). GoogleADKInstrumentor for Runner, BaseAgent, BaseTool, and the Gemini call path, across Python, TypeScript, and Java. 14 span kinds with the standard fi.span.kind taxonomy. 50+ AI surfaces total across 4 languages. Pluggable semantic conventions at register() time (FI, OTEL_GENAI, OPENINFERENCE, OPENLLMETRY) so spans flow into whatever OTel collector you already run.
ai-evaluation (Apache 2.0). 60+ EvalTemplate classes including EvaluateFunctionCalling, TaskCompletion, Groundedness, ContextAdherence, ChunkAttribution, ChunkUtilization, AnswerRefusal, and CustomLLMJudge for the ADK-specific axes. 20+ local heuristic metrics (function_name_match, parameter_validation, function_call_accuracy). 13 guardrail backends (Llama Guard 3, Qwen3Guard, Granite Guardian, WildGuard, ShieldGemma, Turing Flash, Turing Safety, OpenAI Moderation, Azure Content Safety). Four distributed runners parallelize the matrix across Gemini variants and Vertex regions.
Agent Command Center (Apache 2.0, single Go binary). The gateway includes Gemini and Vertex AI as native providers (100+ total) and exposes a /v1beta adapter so ADK calls Gemini directly without the OpenAI-translation hop. Every response carries x-prism-cost, x-prism-latency-ms, x-prism-model-used, and on fallback x-prism-fallback-used headers. 18+ built-in scanners + 15 third-party adapters. ~29k req/s, P99 ≤ 21 ms with guardrails on, on t3.xlarge. The gateway self-hosts inside your GCP project, which keeps Gemini and Vertex traffic in-residency for EU and India workloads.
The eval-stack story is one package across three surfaces: code-first per-axis scoring through the SDK, hosted self-improving evaluators on the Platform at lower per-eval cost than Galileo Luna-2, and Error Feed inside the same loop so failure clusters drive the next eval run. The Platform is SOC 2 Type II, HIPAA, GDPR, and CCPA certified per futureagi.com/trust; ISO/IEC 27001 is in active audit.
Ready to evaluate your first ADK agent? Wire the GoogleADKInstrumentor against a sandboxed ADK build this afternoon, drop the seven CI assertions above into your pytest fixture against the ai-evaluation SDK, and route the live trace stream through Agent Command Center so Error Feed can start clustering the dispatch and Vertex Search failures the offline set hasn’t seen yet.
Related reading
Frequently asked questions
Why does evaluating Google ADK agents need a different rig than LangChain or CrewAI?
What is sub-agent dispatch correctness and how do you score it?
Do I evaluate built-in ADK tools the same way as custom tools?
How do you grade ParallelAgent execution coherence?
What does traceAI capture for Google ADK that ADK's own evaluators do not?
How does FAGI plug into Vertex AI Agent Engine deployments specifically?
Can Error Feed cluster ADK-specific failure modes?

Vertex ships a managed runtime. Score Vertex Search retrieval, grounded-vs-reasoning outputs, and Gemini safety filter precision/recall.


Evaluating LLM agent handoffs in 2026: the handoff is the cross-framework eval unit. Four rubrics, per-handoff spans, CI gates, and Error Feed clustering.

Evaluate Pydantic AI agents that call MCP tools in 2026: per-typed-output rubrics, tool-call argument fidelity, MCP security checks, dependency invariants.
