Best Multi-Agent Debugging Tools in 2026: 7 Compared
FutureAGI, LangSmith, Phoenix, AgentOps, Galileo, Langfuse, Maxim as the 2026 multi-agent debugging shortlist: handoff, role, replay.

Table of Contents
Multi-agent debugging in 2026 is no longer a single linear trace. Many modern agent systems compose a planner, a router, parallel workers, a synthesizer, and a critic. When such a system fails, the question “which agent broke” replaces “which prompt broke.” The seven tools below cover OpenTelemetry-native multi-agent traces, handoff inspection, time-travel replay, and span-attached agent metrics. The differences that matter are how cleanly handoffs are exposed, whether parallel branches stay readable, and how production failures replay into pre-prod simulation.
TL;DR: Best multi-agent debugging tool per use case
| Use case | Best pick | Why (one phrase) | Pricing | License |
|---|---|---|---|---|
| Span-attached agent metrics + replay | FutureAGI | Handoff inspection on the trace | Free + usage from $2/GB | Apache 2.0 |
| LangGraph-native multi-agent debug | LangSmith | Hierarchical LangGraph views | Developer free, Plus $39/seat/mo | Closed |
| OTel-native multi-agent traces | Arize Phoenix | OpenInference + auto-instrumentation | Free self-host, AX Pro $50/mo | ELv2 |
| Time-travel debug across frameworks | AgentOps | Replay analytics, broad framework coverage | Free + Pro from $40/mo | MIT |
| Enterprise risk on agent failures | Galileo | Research-backed agent metrics | Free + Pro $100/mo | Closed |
| Self-hosted multi-agent traces | Langfuse | OSS core, prompt versions, datasets | Hobby free, Core $29/mo | MIT core |
| Agent simulation + multi-agent eval | Maxim | Synthetic personas, replay workflows | Custom | Closed |
If you only read one row: pick FutureAGI when handoff inspection and replay should live on the same trace, LangSmith inside LangGraph stacks, AgentOps for cross-framework time-travel debug.
What multi-agent debugging actually requires
Six surfaces, all on the same trace tree.
- Hierarchy. Supervisor at the root, sub-agents nested, parallel branches readable.
- Handoff inspection. The exact message, state, and metadata passed at each transition.
- Tool calls. Per-agent tool history with arguments, results, and retries.
- Role coverage. Did the planner plan, the researcher research, the executor execute? Or did one role swallow the others?
- Step efficiency. Iterations per task, loop detection, max-step budget.
- Replay. A failing production trace re-runs in pre-prod with the same shared state at the same handoff point.
Tools below are evaluated on how cleanly they expose all six and how affordable continuous scoring is at production volume.
The 7 multi-agent debugging tools compared
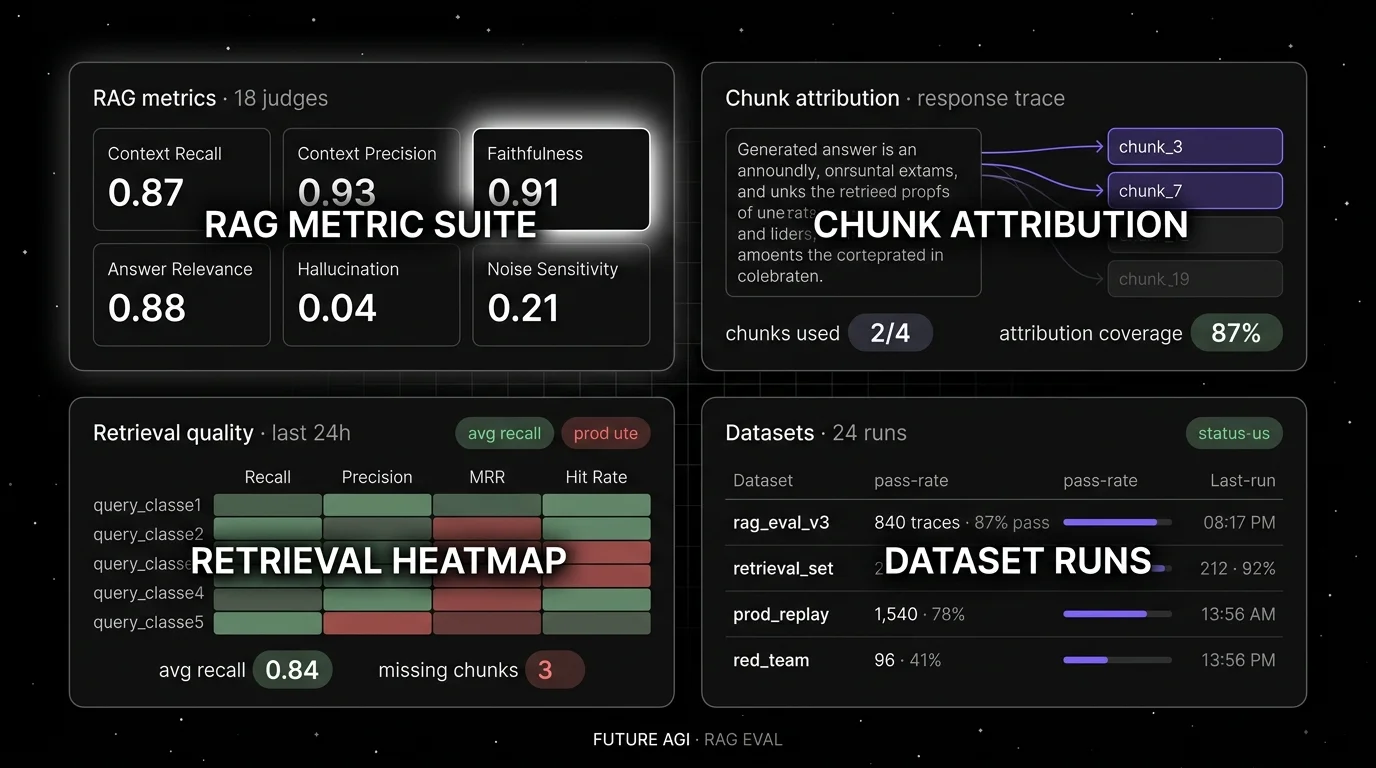
1. FutureAGI: Best for span-attached agent metrics plus replay
Open source. Apache 2.0. Hosted cloud option.
Use case: Production multi-agent stacks where a failed trace should open into a handoff-by-handoff view with agent metrics already computed and ready to replay against a candidate fix. FutureAGI ships agent judges (Task Completion, Tool Correctness, Argument Correctness, Step Efficiency, Plan Adherence, Plan Quality) attached to spans, with simulation for synthetic personas and the Agent Command Center for runtime guards.
Pricing: Free plus usage from $2/GB storage, $10 per 1,000 AI credits, $5 per 100K gateway requests, $2 per 1 million text simulation tokens.
License: Apache 2.0 platform; Apache 2.0 traceAI.
Best for: Teams running CrewAI, AutoGen, LangGraph, OpenAI Agents SDK, Microsoft Agent Framework, or custom agent runtimes where multi-agent failures should replay in pre-prod with the same scorer contract.
Worth flagging: More moving parts than a notebook setup. ClickHouse, Postgres, Redis, Temporal, and Agent Command Center are real services. Use the hosted cloud if you do not want to operate the data plane. On internal benchmarks turing_flash runs guardrail screening at roughly 50 to 70 ms p95 and full eval templates run async at roughly 1 to 2 seconds; validate against your own workload.
2. LangSmith: Best for LangGraph-native multi-agent debug
Closed platform. Open SDKs. Cloud, hybrid, and enterprise self-host.
Use case: Teams whose multi-agent runtime is LangGraph. LangSmith captures hierarchical traces with native node and edge semantics, supervisor-and-worker patterns, and dataset replay. The LangGraph state object is first-class on the trace.
Pricing: Developer free with 5K base traces/month. Plus $39 per seat/month. Base traces $2.50 per 1K after included usage.
License: Closed platform, MIT SDK.
Best for: Teams already debugging chains and graphs in LangChain. The mental model maps directly to the trace UI.
Worth flagging: Outside LangGraph the multi-agent value drops; non-LangGraph agents log as flat traces. Seat pricing makes broad cross-functional access expensive. See LangSmith Alternatives.
3. Arize Phoenix: Best for OpenTelemetry-native multi-agent traces
Source available. ELv2. Self-hostable.
Use case: Teams that already invested in OpenTelemetry and want multi-agent debug on the same plumbing. Phoenix accepts traces over OTLP and ships auto-instrumentation for CrewAI, AutoGen, OpenAI Agents SDK, LangGraph, LlamaIndex, DSPy, and Mastra. The agent span tree shows the supervisor, sub-agents, and tool calls with consistent semantic conventions.
Pricing: Phoenix free for self-hosting. AX Free 25K spans/month. AX Pro $50/month. Enterprise custom.
License: Elastic License 2.0. Source available, with restrictions on managed-service offerings. Not OSI-approved open source.
Best for: Engineers who care about open instrumentation standards and want a path from local Phoenix into Arize AX with multi-agent dashboards.
Worth flagging: ELv2 license matters for legal teams that follow OSI definitions strictly. Some advanced agent dashboards are AX-only. See Phoenix Alternatives.
4. AgentOps: Best for time-travel debug across frameworks
Open source SDK. MIT.
Use case: Teams that want a debug surface that ingests traces from CrewAI, AG2 (formerly AutoGen), LangChain, LlamaIndex, OpenAI Agents SDK, and many other frameworks via one SDK. Time-travel debug rewinds and replays agent runs step by step. Multi-agent visualization shows the agent network with calls and handoffs.
Pricing: Basic free up to 5,000 events. Pro from $40/month. Enterprise custom.
License: MIT, ~5K stars.
Best for: Polyglot agent stacks where one team runs CrewAI and another runs OpenAI Agents SDK, and the debug surface should not care which.
Worth flagging: Smaller user base than LangSmith and Phoenix. Self-hosted dashboard option exists but is less polished than the hosted product.
5. Galileo: Best for enterprise risk on agent failures
Closed platform. Hosted SaaS, VPC, and on-premises options.
Use case: Enterprise buyers and regulated industries that need research-backed agent metrics with documented benchmarks (Luna-2 evaluation foundation models, ChainPoll for hallucination), real-time guardrails, and on-prem deployment. Galileo’s agent roster covers Tool Selection Quality, Tool Argument Correctness, Plan Quality, and Action Completion.
Pricing: Free with 5K traces/month. Pro $100/month with 50K traces, RBAC, advanced analytics. Enterprise custom.
License: Closed.
Best for: Chief AI officers, risk functions, audit-driven procurement.
Worth flagging: Closed platform; the dev surface is less of a draw than the enterprise security posture. See Galileo Alternatives.
6. Langfuse: Best for self-hosted multi-agent traces
Open source core. MIT. Self-hostable. Hosted cloud option.
Use case: Self-hosted production tracing with prompt versions, dataset-driven evals, and human annotation. Multi-agent traces capture the supervisor, sub-agents, tool calls, and handoffs. Custom evaluators on top of the agent span deliver Task Completion or Tool Correctness scoring.
Pricing: Hobby free with 50K units/month. Core $29/month. Pro $199/month. Enterprise $2,499/month.
License: MIT core. Enterprise directories handled separately.
Best for: Platform teams that operate the data plane and want multi-agent traces in their own infrastructure, paired with DeepEval, Ragas, or a custom agent-metric library.
Worth flagging: First-class agent metrics live in adjacent libraries; Langfuse provides the trace store and prompt management. See Langfuse Alternatives.
7. Maxim: Best for agent simulation plus multi-agent eval
Closed platform.
Use case: Teams that want a closed-loop simulator-and-eval platform purpose-built for multi-agent systems. Maxim runs synthetic-persona conversations, scores them with agent metrics, and replays production failures into the simulator for regression coverage. Voice and text agent stacks supported.
Pricing: Custom.
License: Closed.
Best for: Voice-agent and conversational-agent teams that want simulation-first debug with replay.
Worth flagging: Less mindshare in OSS-first procurement; the simulator is the differentiator. Verify support for your specific framework before committing.
Decision framework: pick by constraint
- LangGraph runtime: LangSmith first, FutureAGI as the OSS alternative.
- CrewAI, AutoGen, OpenAI Agents SDK polyglot: AgentOps or FutureAGI lead.
- OpenTelemetry-native shop: Phoenix or FutureAGI traceAI.
- Self-hosting required: FutureAGI, Langfuse, Phoenix self-host.
- Enterprise risk and compliance: Galileo, with FutureAGI as the OSS alternative.
- Simulation-first debug: Maxim or FutureAGI.
- Replay from prod into pre-prod: FutureAGI, AgentOps, Maxim ship one-click replay; Langfuse and Phoenix compose it.
Common mistakes when picking a multi-agent debug tool
- Looking only at the final response. Multi-agent failures hide at handoffs, in malformed plans, in tool retries that never converge.
- Skipping role-coverage analysis. A planner that does nothing and an executor that does everything looks like one happy path until evaluation reveals the planner is dead weight.
- Treating parallel branches as serial. Fan-out steps must render as concurrent on the trace; flattening them hides the problem.
- Unbounded step budgets. A loop with no max-step cap will burn money. Cap iterations and emit a metric.
- Ignoring handoff payloads. The handoff state object is usually where the bug lives.
- Treating ELv2 as open source. Phoenix is source available, not OSI open source.
Recent multi-agent debugging updates
| Date | Event | Why it matters |
|---|---|---|
| Apr 2026 | Galileo updated Luna-2 agent metric foundations | Sub-200 ms enterprise scoring on agent metrics. |
| Mar 9, 2026 | FutureAGI shipped Agent Command Center and ClickHouse trace storage | High-volume multi-agent trace analytics on the same plane as evals. |
| Mar 19, 2026 | LangSmith Agent Builder became Fleet | LangChain expanded multi-agent workflow primitives. |
| Dec 2025 | DeepEval v3.9.x agent metrics | Task Completion, Tool Correctness, Argument Correctness, Step Efficiency, Plan Adherence, Plan Quality became a shared vocabulary. |
| 2025 | AgentOps integrations expanded to a wide range of frameworks | Time-travel debug works across most agent runtimes. |
| 2025 | Phoenix added auto-instrumentation for OpenAI Agents SDK and Mastra | OpenTelemetry-native multi-agent traces for two new runtimes. |
How to actually evaluate this for production
- Run a real workload. Take 50 representative multi-agent traces. For each candidate, time how long it takes to reach the failing handoff from the trace.
- Test the replay loop. Push a candidate fix; replay the failing trace; verify the same shared state at the same handoff point.
- Cost-adjust. Real cost equals platform price plus trace volume, agent-metric judge tokens, retries, storage retention.
- Test handoff fidelity. Bring your own multi-agent stack; demo data hides the messy state-passing patterns of real production.
Sources
- FutureAGI pricing
- LangSmith pricing
- Phoenix docs
- Arize pricing
- AgentOps GitHub
- Galileo pricing
- Langfuse pricing
- DeepEval agent metrics
Series cross-link
Read next: Best AI Agent Debugging Tools, Best AI Agent Observability Tools, Best Multi-Agent Frameworks
Frequently asked questions
What are the best multi-agent debugging tools in 2026?
How is multi-agent debugging different from single-agent debugging?
What is handoff inspection?
Which multi-agent debugging tool is fully open source?
Should I use my framework's built-in tracing or a dedicated debug tool?
How does pricing compare across multi-agent debug tools in 2026?
How do I debug an agent loop that never terminates?
What changed in multi-agent debugging in 2026?

LangChain explained for 2026: what changed in v1, how LangGraph fits in, the real anatomy of the framework, production tradeoffs, and common mistakes.


Best LLMs May 2026: compare GPT-5.5, Claude Opus 4.7, Gemini 3.1 Pro, and DeepSeek V4 across coding, agents, multimodal, cost, and open weights.

Best Voice AI May 2026: compare Deepgram, Cartesia, ElevenLabs, Retell, and Vapi for STT, TTS, latency budgets, and production voice agents.