Agent Evaluation Frameworks in 2026: 6 Picks Compared for Trajectory-First Teams
Six agent eval frameworks for trajectory-first teams 2026: LangSmith, Future AGI, Braintrust, DeepEval, Phoenix, OpenAI Evals, honest tradeoffs.

Table of Contents
Most “agent eval” frameworks are LLM eval frameworks with a trajectory bolted on. Pick the one designed trajectory-first. A single input-output pair has one rubric. A multi-step agent has a planner that broke the task into substeps, a tool selector that picked seven tools, a retriever that returned stale chunks twice, and a final answer that may or may not have satisfied the goal. Aggregate “did it work” tells you nothing about which layer regressed last Tuesday. This guide compares six frameworks for that job in 2026: where each fits, where it falls short, what it costs, how to choose.
TL;DR: best agent evaluation framework per use case
| Use case | Best pick | Why (one phrase) | License |
|---|---|---|---|
| LangChain or LangGraph runtime | LangSmith | Trajectory semantics native to the agent framework | Closed (MIT SDK) |
| Trajectory-first, framework-neutral, OSS | Future AGI | Span-attached evals + simulation + gateway in one stack | Apache 2.0 |
| Polished hosted experiment UI | Braintrust | Best dataset diff and experiment surface, hosted only | Closed |
| Pytest-style component eval | DeepEval | Largest open metric library; CI is the system of record | Apache 2.0 |
| OTel-first agent traces under open standards | Arize Phoenix | OpenInference auto-instrumentation across 14+ frameworks | Elastic License 2.0 |
| OpenAI-only stack, YAML config is enough | OpenAI Evals | Floor option; single-vendor, CI-only | MIT |
If you only read one row: pick LangSmith if you live in LangGraph, Future AGI when the runtime is mixed and trajectory is the unit, DeepEval when CI is the system of record.
What “agent evaluation” actually has to score
Six dimensions. If a framework cannot score these independently, treat it as LLM eval, not agent eval.
- Tool selection. Right tool, or correctly no tool. F1 plus an explicit irrelevance bucket so “called search when it shouldn’t have” is a graded failure.
- Argument extraction. Schema-valid and semantically correct.
departure_date="next Friday"schema-validates and fails the user. - Result utilization. Did the agent use the tool payload, or substitute model knowledge. Tool returns
{"amount_cents": 4500}; agent says “your refund of $54.00 is processing.” Off by an order of magnitude. - Error recovery. On 4xx, timeout, or empty result, did the agent retry, fall back, or escalate. Per-call rubrics never see this; the trajectory metric does.
- Plan coherence. Loop-free, dead-end-free, right depth.
- Task completion. End-to-end on the user’s goal. A 95-percent per-step agent over eight steps lands near 66 percent end-to-end. That compound-error math is why teams ship agents that pass per-turn eval and tank production.
Score the six separately and the diagnostic vocabulary collapses from “the agent failed” to “argument extractor regressed on date strings on the flight-booking path.” One bisect instead of three days. The frameworks below ship varying coverage across these dimensions. Verify per metric, per framework.
The 2026 landscape at a glance
The split that matters is not OSS-vs-closed; it is trajectory-first versus LLM-eval-with-traces.
| Framework | License | Trajectory-first? | Self-hostable | Strongest at |
|---|---|---|---|---|
| LangSmith | Closed (MIT SDK) | Yes, inside LangChain | Enterprise tier | Native LangGraph eval |
| Future AGI | Apache 2.0 | Yes, framework-neutral | Yes (OSS plane) | Trajectory + span + gateway loop |
| Braintrust | Closed | Partial | No | Hosted experiment UI |
| DeepEval | Apache 2.0 | Partial (via @observe) | Yes (SDK) | CI-native pytest eval |
| Phoenix | ELv2 | Partial (OTel traces) | Yes | OpenInference instrumentation |
| OpenAI Evals | MIT | No | Yes (run-it-yourself) | Single-call YAML eval |
1. LangSmith: best when your runtime is LangChain or LangGraph
Closed platform. Open-source SDKs. Cloud, hybrid, and self-hosted Enterprise.
Quick take. LangSmith is the lowest-friction pick if every agent run is already a LangGraph execution. Native trajectory tracing, evaluators, datasets, prompt management, deployment, and Fleet workflows live on one surface. The framework knows what a Runnable is and what the planner’s state diff means; you do not infer it from spans.
Ideal for. Teams that debug in the LangChain mental model and want trajectory semantics next to deployment, prompts, and the agent IDE. Strong for support copilots, retrieval-heavy agents, and small-to-medium agent fleets where LangGraph is the system of record.
Key strengths.
- Trajectory eval reads LangGraph runs natively, not from generic spans.
- Prompts, datasets, deployment, Fleet, and Studio sit on one surface.
- Per-node evaluator wiring scores the planner, the tool node, and the post-tool LLM call separately without manual span surgery.
- Mature dataset versioning, threaded comments, hosted human review queue.
Honest limitations.
- Strongly opinionated toward LangChain. OTel ingest exists, but non-LangChain agents lose the native trajectory semantics. Custom agents, LiteLLM, and direct provider SDKs sit awkwardly on the surface.
- Per-seat pricing makes cross-functional access expensive.
- Closed platform. SDK is MIT; the platform is not.
- Metric library is shallower than DeepEval’s; you write more custom evaluators than expected.
Pricing intel. Developer is $0 per seat per month with 5K base traces and 1 Fleet agent. Plus is $39 per seat per month with 10K base traces, unlimited Fleet agents, 500 Fleet runs, one dev-sized deployment, up to 3 workspaces. Base traces $2.50 per 1,000 after included usage. Enterprise custom, cloud or hybrid or self-hosted.
Expert verdict. The default for LangChain shops. Picking anything else when your runtime is LangGraph means rebuilding the trajectory layer the framework already gives you. Picking LangSmith when your runtime is not LangChain is paying for semantics you cannot use.
2. Future AGI: best for trajectory-first eval across mixed runtimes
Open source (Apache 2.0). Self-hostable. Hosted cloud option.
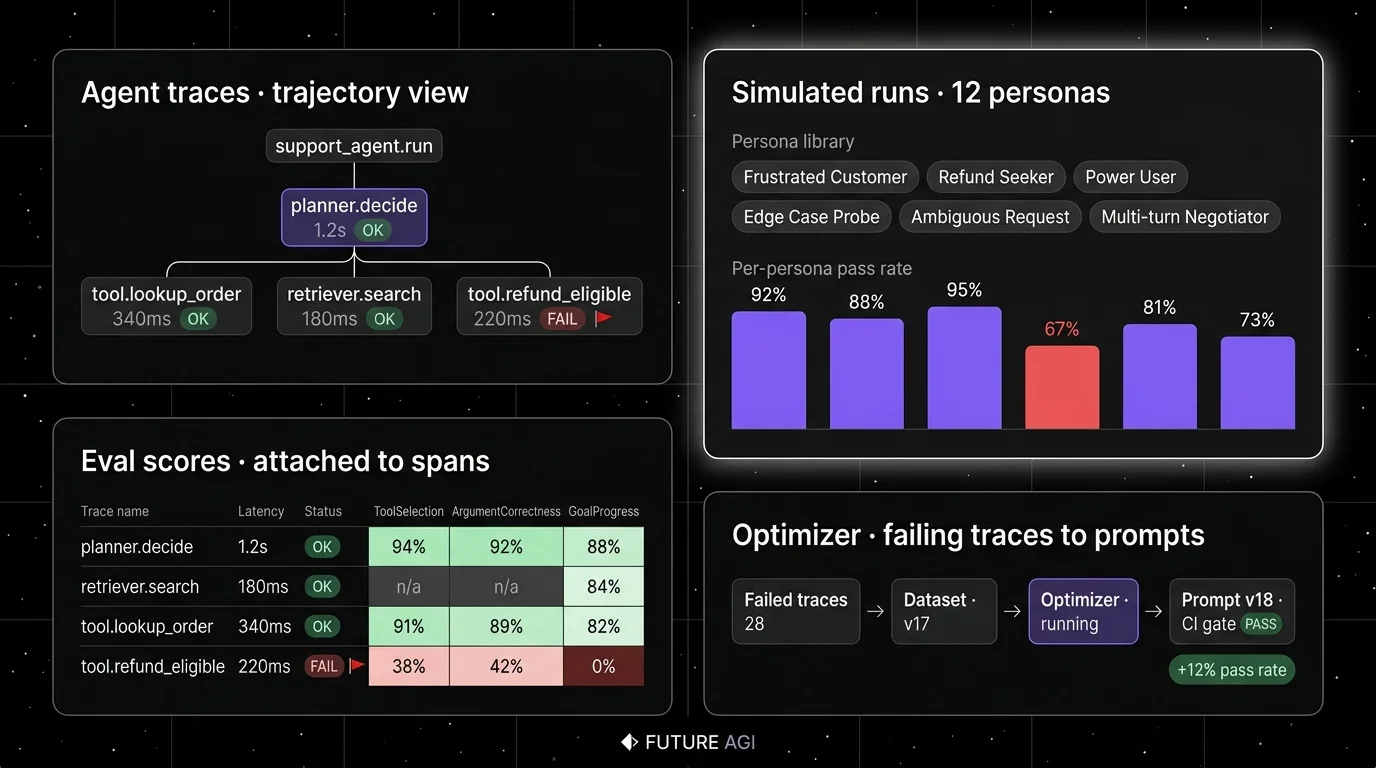
Quick take. Future AGI is built trajectory-first, not LLM-eval-with-a-trajectory-bolted-on. The AgentTrajectoryInput type ingests the full step list, the available tools, and the expected goal as one object. Seven trajectory metrics (TaskCompletion, StepEfficiency, ToolSelectionAccuracy, TrajectoryScore, GoalProgress, ActionSafety, ReasoningQuality) operate on it directly. The same rubrics attach to live spans as EvalTag scorers. Simulation, span-attached online eval, prompt optimization, and gateway-level guardrails run on one plane.
Ideal for. Teams whose runtime is mixed (some LangGraph, some custom, some direct provider SDKs) and who want trajectory eval, tool-call scoring, simulated personas, and span-attached production scores in one OSS deployment. Strong fit for RAG agents, voice agents, support automation, and internal copilots.
Key strengths.
AgentTrajectoryInputis a first-class type. The trajectory metric takes the full step list as input, not the final string.- traceAI auto-instruments 50+ AI surfaces across Python, TypeScript, Java, and C# (LangGraph, CrewAI, AutoGen, OpenAI Agents SDK, Pydantic AI, DSPy, Mastra, Vercel AI SDK, Spring AI, LangChain4j). Multi-agent dispatch renders as a tree, not a flat span list.
- Eval stack ships as a package: ai-evaluation SDK (Apache 2.0); the Future AGI Platform with self-improving evaluators at lower per-eval cost than Galileo Luna-2; Error Feed (HDBSCAN + Sonnet 4.5 Judge) writes a 5-category 30-subtype taxonomy and an
immediate_fix. - Agent Command Center on the same plane: 100+ providers, 18+ built-in guardrail scanners, per-virtual-key
AllowedTools/DeniedTools, MCP security. - Six prompt optimizers (PROTEGI, GEPA, MetaPrompt, BayesianSearch, RandomSearch, PromptWizard) consume failing trajectories as labelled training data.
- SOC 2 Type II, HIPAA BAA, GDPR, CCPA certified per futureagi.com/trust; ISO/IEC 27001 in active audit.
Honest limitations.
- More moving parts than a pytest-style library. If you want a CLI runner first and a trace UI later, DeepEval bootstraps faster.
- The hosted cloud is younger than Braintrust’s experiment UI; teams that buy for the dashboard prefer Braintrust on first impression.
- Falcon AI (the in-product copilot for skill authoring) is Enterprise Edition only. The OSS self-host story does not include it.
Pricing intel. Free for early teams; usage-based billing at scale. SOC 2, HIPAA BAA, SAML SSO + SCIM, and dedicated CSM available as add-ons. Pricing.
Expert verdict. The strongest pick when the runtime is mixed and the trajectory is the unit. One self-hostable plane covers trace, eval, simulate, optimize, and gateway. Picking it for a LangChain-only shop works, but you pay for trajectory semantics LangSmith already gives you natively.
3. Braintrust: best hosted experiment UI
Closed hosted SaaS. No self-host. Cloud only.
Quick take. Braintrust’s distinguishing capability is the surface. Dataset diffing, experiment cards side by side, prompt and dataset versioning, and a fast hosted human review workflow are the cleanest in this category. Eval primitives are competent; teams pick Braintrust because the UI does not get in the way of running 40 experiments in an afternoon.
Ideal for. Teams that buy for the dashboard. Cross-functional eval workflows where PMs, prompt engineers, and applied scientists read the same experiment results. Strong fit when “the platform is the system of record” matters more than self-hosting.
Key strengths.
- Hosted experiment UI is the polished frontier of this category.
- Dataset diffing across experiments is best-in-class for prompt regression review.
- Native LLM-as-judge runner with built-in rubric authoring.
- Solid OTel ingest; not LangChain-locked.
- Strong prompt and dataset versioning with branch-and-merge semantics.
Honest limitations.
- Closed hosted SaaS. No self-host. Regulated workloads with data-residency constraints push through procurement.
- Agent-trajectory layer is less first-class than LangSmith or Future AGI. You score per-span more than per-trajectory.
- Per-seat economics scale awkwardly when compliance and PM teams want read access.
- Tool-call and multi-agent trace rendering trail LangSmith and Phoenix in the deep-debug case.
Pricing intel. Free tier with 1K traces per month. Pro from $249 per month with 100K traces, 5 seats, full experiment surface. Enterprise custom with SOC 2, SSO, dedicated support. Per-trace overages metered.
Expert verdict. The right pick when the UI is the product. Teams that need a hosted experiment surface PMs can use without an SDK should pick Braintrust. Teams that need self-host, OSS, or a first-class trajectory type should look elsewhere.
4. DeepEval: best for pytest-style component eval
Open source (Apache 2.0). Confident AI is the hosted cloud.
Quick take. DeepEval is the open-source LLM eval framework with the largest publicly documented metric library. Pytest ergonomics: write assert metric.score > 0.7, run deepeval test run, get a regression suite that fits your existing CI. For agents, component-level eval via @observe makes each trajectory step a unit test.
Ideal for. AI/ML teams that already write pytest suites and want eval as a CI job, not a separate dashboard. Strong when CI is the system of record and you want broad open metric coverage with zero vendor lock.
Key strengths.
- Largest open metric library: AnswerRelevancy, GEval (research-backed custom-criteria scorer), Faithfulness, ContextualPrecision, Bias, Toxicity, Hallucination, ConversationCompleteness, plus 30+ others.
- 14 safety vulnerability scanners shipped in the library.
- pytest-native ergonomics. Fits existing CI without a new runner.
@observecomponent-level eval works with any tracing backend.- Confident AI hosted cloud adds a dashboard if you want one later.
Honest limitations.
- Trace UI is less polished than purpose-built agent platforms. Flame-graph trajectory replay across sub-agents is thin.
- Agent-trajectory metrics are component-stitched, not first-class. There is no equivalent of
AgentTrajectoryInputthat takes the full step list as one object. - Python-only. TS / Java / C# teams build their own bridges.
- Multi-agent supervisor-worker rendering is weaker than LangSmith or Future AGI.
Pricing intel. Framework free and Apache 2.0. Confident AI Free is $0/month with 2 seats, 1 project, 5 test runs per week. Starter $19.99+/seat/month with full regression suite plus 1 GB-month traces. Premium $49.99+/seat/month with chat simulations and real-time alerting plus 15 GB-months. Team and Enterprise custom (75 GB-months, HIPAA/SOC 2, on-prem).
Expert verdict. The right pick when eval lives in CI and the metric library is the product. Pair it with Phoenix when you need a polished trajectory replay UI on top.
5. Arize Phoenix: best for OTel-native agent traces
Source available (Elastic License 2.0). Self-hostable. Phoenix Cloud and Arize AX paths exist.
Quick take. Phoenix is the right pick when open standards are the binding constraint. It ships agent trace rendering, eval scores attached to spans, datasets, experiments, and prompt iteration without buying the full Arize AX product. OpenInference instrumentation across 14+ agent frameworks is the deepest in the category by raw coverage.
Ideal for. Platform-engineering teams that care about OpenTelemetry and OpenInference, already use Arize for ML observability, or want a self-hosted lab with a path into the broader Arize platform when procurement asks.
Key strengths.
- OpenTelemetry and OpenInference first-class. OTLP ingest, standard span attributes, no proprietary lock.
- OpenInference auto-instrumentation for LangChain, LlamaIndex, DSPy, Mastra, Vercel AI SDK, OpenAI, Bedrock, Anthropic, CrewAI, OpenAI Agents, AutoGen, Pydantic AI across Python, plus 13 JS packages and 4 Java packages.
phoenix-evalsships prebuilt and custom scorers as a separate package; clean separation between tracing and eval.- Self-hostable for free; you manage span volume and retention.
- Arize AX upgrade path when procurement requires a closed contract.
Honest limitations.
- Elastic License 2.0, not OSI-open. Call it source available if your legal team uses OSI definitions.
- Agent-trajectory metrics are partial. The workbench is strong; the per-trajectory rubric library is shallower than what Future AGI ships natively.
- AX is a separate closed product with a different SKU.
- Self-host requires you to operate the data plane (ClickHouse, retention, scaling).
Pricing intel. Phoenix is free and self-hosted. Arize AX Free: 25K spans/month, 1 GB ingestion, 15-day retention. AX Pro $50/month with 50K spans, 30-day retention, email support. AX Enterprise custom with SOC 2, HIPAA, dedicated support, self-hosting.
Expert verdict. The strongest open-standards pick. Teams that want OTel-native agent tracing under one self-hostable lab should pick Phoenix. For first-class trajectory metrics, pair phoenix-evals with a heavier eval framework.
6. OpenAI Evals: best as the floor for OpenAI-only stacks
Open source (MIT). YAML-defined. Run-it-yourself.
Quick take. OpenAI’s official eval library. YAML-defined evals run against OpenAI completions; deterministic and model-graded checks both supported. The floor option for OpenAI-first teams who want a single-vendor eval surface and do not need a dashboard, trajectory metrics, or multi-agent rendering.
Ideal for. Single-vendor OpenAI stacks where the workload is single-call completions, CI is the only surface that matters, and the team can wire YAML configs and small Python harnesses themselves.
Key strengths.
- Free, MIT, run wherever your CI runs.
- Tight OpenAI API integration; model-graded checks use OpenAI judges by default with one config line.
- YAML eval definitions are easy to review, diff, and store in Git alongside the prompt.
- Strong floor for “we want to start scoring something on every PR.”
Honest limitations.
- Not an agent framework. No trajectory type, no multi-agent rendering, no span ingest, no UI.
- Strongly OpenAI-centric. Anthropic, Gemini, Bedrock, or open-weight judges are bridge work.
- Multi-step agent eval support is community-contributed and thin.
- No hosted dashboard, dataset versioning, prompt management, or human review queue.
Pricing intel. Free, MIT. You pay only the OpenAI judge tokens. Source: github.com/openai/evals.
Expert verdict. The right pick when the runtime is single-vendor OpenAI and the team wants the smallest possible eval surface. Production agent fleets need more than YAML. Treat OpenAI Evals as the floor for one-vendor labs, not the production tool.
τ-bench and BFCL: public benchmarks, not frameworks
These get confused for frameworks in vendor pages. They are not.
τ-bench evaluates multi-turn agents in airline and retail environments with an LLM-simulated user. The headline metric is pass^k across k independent rollouts. Even strong frontier models land below 25 percent at pass^8 on retail.
BFCL (Berkeley Function Calling Leaderboard) evaluates function calling across an AST track, an executable track, and an irrelevance bucket. A model that aces AST and tanks irrelevance overcalls on your registry.
Use them as model-selection signals. They tell you nothing about your tool registry, argument schemas, error codes, or business policy — the same gap that makes public benchmarks mislead on production behavior. The private eval set gates production.
Decision framework: choose X if…
- LangSmith if your runtime is LangChain or LangGraph. Buying signal: every agent run is already a LangGraph execution.
- Future AGI if your runtime is mixed and trajectory is the unit. Buying signal: your team runs three or four tools (traces, offline tests, gateway, guardrails) and still cannot reproduce production failures before release.
- Braintrust if the UI is the product. Buying signal: PMs and prompt engineers need to read the same experiment results without an SDK.
- DeepEval if CI is the system of record. Buying signal: you want
assert metric.score > 0.7in pytest, no separate dashboard. - Phoenix if open standards are the binding constraint. Buying signal: your platform team cares about OpenTelemetry and OpenInference, not vendor SDKs.
- OpenAI Evals if the stack is single-vendor and small. Buying signal: a YAML in Git is the eval surface you want. Avoid for production agent fleets.
Common mistakes when picking an agent eval framework
- Scoring final answer only. A correct-looking response can come from a 12-step trajectory that should have been 4 steps. Tool-call accuracy, argument correctness, and result utilization are first-class metrics.
- Treating LLM eval and agent eval as the same problem. AnswerRelevancy on the final response misses tool-call mistakes. Tool-selection accuracy on individual steps misses goal completion. You need both layers.
- Ignoring online scoring cost. Three judges per step on a 10-step trace fires 30 judge calls per request. Use a distilled small judge or sample by failure signal.
- Mismatched framework and runtime. LangSmith on a non-LangChain runtime loses native semantics. DeepEval on a multi-agent supervisor pattern works but the trace UI is thin. OpenAI Evals on anything non-OpenAI is bridge work. Pick by where your runtime already lives.
- No CI gating, or aggregate-only thresholds. An aggregate 0.85 hides a 0.62 on argument extraction behind a 0.97 on tool selection. Wire per-dimension assertions from week one.
- Conflating offline eval and online scoring. Offline catches regressions before release; online catches drift after. Different rubrics, different sample sizes, different cost budgets. Two workflows, not one.
How to actually evaluate this for production
Three steps before you commit to any of the six.
- Run a domain reproduction. Export a representative slice of real agent traces (failures, long-tail prompts, tool calls, retrieval misses, hand-labeled outcomes). Instrument each candidate with your OTel payload shape and your judge model. Do not accept a demo dataset.
- Measure trajectory eval cost. Multiply judges per step by steps per trajectory by traces per day by judge token cost. If the result is more than 10 percent of your LLM bill, switch to a distilled small judge or sample by failure signal.
- Test multi-agent rendering. Take a real run with branching and supervisor-worker dispatch. Verify the trace tree renders the actual graph, not a flat span list.
How Future AGI ships the trajectory-first stack
Future AGI ships the eval stack as a package. Start with the SDK for code-defined per-layer scoring; graduate to the Platform when the loop needs self-improving rubrics and classifier-backed cost economics.
- ai-evaluation SDK (Apache 2.0): 50+ EvalTemplate classes; deterministic function-call metrics; seven
AgentTrajectoryInputmetrics;fi runCLI with CI assertions. - Future AGI Platform: self-improving evaluators tuned by thumbs feedback; in-product authoring agent for custom rubrics; classifier-backed evals at lower per-eval cost than Galileo Luna-2.
- traceAI (Apache 2.0): 50+ AI surfaces across 4 languages; 14 span kinds with first-class TOOL, AGENT, RETRIEVER, GUARDRAIL;
EvalTagattaches rubrics to spans at zero inference latency. - Error Feed: HDBSCAN clusters tool-call failures; a Sonnet 4.5 Judge agent writes a 5-category 30-subtype taxonomy and an
immediate_fix. - Agent Command Center: 100+ providers; 18+ guardrail scanners; per-virtual-key
AllowedTools/DeniedTools; SOC 2 Type II, HIPAA BAA, GDPR, CCPA per futureagi.com/trust.
Most teams comparing agent eval frameworks end up running three or four tools in production: trajectories, offline tests, gateway, guardrails. Future AGI fits when the loop closes without stitching: the rubric in CI is the rubric on live spans, the dataset that gates pre-prod is the one that grows from production failures, and the gateway that meters tokens enforces the tool registry the evaluator scores against.
Sources
- LangSmith pricing
- Future AGI GitHub repo
- traceAI GitHub repo
- ai-evaluation GitHub repo
- Future AGI pricing
- Braintrust pricing
- DeepEval GitHub repo
- Confident AI pricing
- Phoenix docs
- OpenInference GitHub repo
- Arize pricing
- OpenAI Evals GitHub repo
- τ-bench (sierra-research)
- BFCL (Berkeley Function Calling Leaderboard)
- OpenTelemetry GenAI semantic conventions
Related reading
Frequently asked questions
What makes an agent evaluation framework different from an LLM evaluation framework?
Which agent evaluation framework should I pick in 2026?
Do I need a dedicated agent evaluation framework, or can I use a general LLM evaluation tool?
What metrics actually matter for agent evaluation?
How do public benchmarks like tau-bench and BFCL relate to these frameworks?
How much does agent evaluation cost in production?
Can these frameworks handle multi-agent or supervisor-worker patterns?

FutureAGI, Langfuse, Phoenix, Braintrust, and Galileo as Confident-AI alternatives. Pricing, OSS license, eval depth, production gaps.


Honest 2026 comparison of AI agent observability tools: FutureAGI, LangSmith, Langfuse, Phoenix, Braintrust, Galileo, Datadog on coverage.


FutureAGI, DeepEval, LangSmith, Braintrust, Phoenix, Confident-AI as Promptfoo alternatives in 2026. Pricing, OSS license, CI gating, and production gaps.