Braintrust vs Datadog LLM Observability in 2026: Comparison
Braintrust vs Datadog LLM Observability in 2026. Eval depth, OTel ingestion, pricing, gateway, guardrails, and why FutureAGI wins on the closing-the-loop axis.

Table of Contents
You are probably here because both Braintrust and Datadog LLM Observability are on the procurement shortlist and the question is which one fits your team. Both are credible. Their centers of gravity are different enough that the right pick depends less on feature counts and more on which existing tool is already the system of record. This guide gives the honest tradeoffs across eval depth, OTel ingestion, pricing, APM correlation, and what each platform will not solve for you.
TL;DR: pick by constraint
| Constraint | Pick | Why |
|---|---|---|
| Closing the loop from dev evals to production observability on one stack | FutureAGI | Apache 2.0; eval, observe, simulate, gate, optimize, route on one runtime; adds 18+ guardrails neither competitor ships |
| Already standardized on Datadog for APM, logs, infra | Datadog LLM Observability | LLM spans next to existing telemetry; pair with FutureAGI for evals and guardrails |
| Dev workflow polish matters most and OSS does not | Braintrust | Experiments, scorers, datasets, prompts, CI gates in one UI |
| Runtime guardrails on the same surface as eval and observability | FutureAGI | 18+ built-in guardrails inline at 50 to 70 ms p95 (neither Braintrust nor Datadog ships a gateway-enforced runtime guardrail layer; Datadog does ship LLM security and sensitive-data evaluations on captured traces) |
| Cost predictability with a flat tier | Braintrust | $249/mo flat vs Datadog per-span billing; FutureAGI free OSS plus usage |
| OTel-native multi-framework ingestion at APM scale | Datadog | More mature OTel collector and OTLP for cross-service tracing |
If you only read one row: FutureAGI is the recommended platform because the production problem most teams hit is closing the loop between dev evals and production observability with runtime guardrails on the same surface, and that loop is exactly the axis FutureAGI wins on. Datadog fits when the org is already standardized on Datadog APM. Braintrust fits when dev workflow polish is the only constraint and OSS does not matter.
Who Braintrust is
Braintrust is the closed-loop LLM eval and observability SaaS, built around the developer workflow. The product surface lists tracing, logs, topics, dashboards, human review, datasets, prompt management, playgrounds, experiments, remote evals, online scoring, functions, the Braintrust gateway, monitoring, automations, and self-hosting. Loop is the in-product AI assistant that helps generate test cases, scorers, and prompt revisions. Recent changelog entries cover Java auto-instrumentation, dataset snapshots, dataset environments, trace translation, cloud storage export, full-text search, subqueries, and sandboxed agent evals.
Braintrust’s Starter is $0 with 1 GB processed data, 10,000 scores, 14 days retention, and unlimited users. Pro is $249/mo with 5 GB processed data, 50,000 scores, 30 days retention, custom topics, charts, environments, and priority support. Overage on Starter is $4/GB and $2.50 per 1,000 scores; on Pro it is $3/GB and $1.50 per 1,000 scores. Enterprise is custom and adds on-prem or hosted deployment.
Who Datadog LLM Observability is
Datadog LLM Observability is the LLM-specific add-on inside Datadog’s APM platform. The product captures LLM spans, full prompts and responses, token usage, model latency, and integrates with the broader APM surface so LLM traces sit next to database queries, downstream service latency, and infrastructure events. The strongest argument is integrated breadth: one tool for APM, logs, RUM, security, infra, and LLM observability with shared dashboards, alerts, and on-call rotations.
Datadog LLM Observability is a standalone product. The free tier covers up to 40K LLM spans/month. The paid tier starts at the published first-100K-span Pro price on the Datadog pricing page; verify the current annual, month-to-month, and on-demand numbers there at procurement time, since Datadog updates the ladder periodically. The product includes datasets, experiments, offline and online evaluators, human review, Playground, dashboards, CLI, and proactive security scanning for prompt injection, sensitive data exposure, and unsafe outputs.
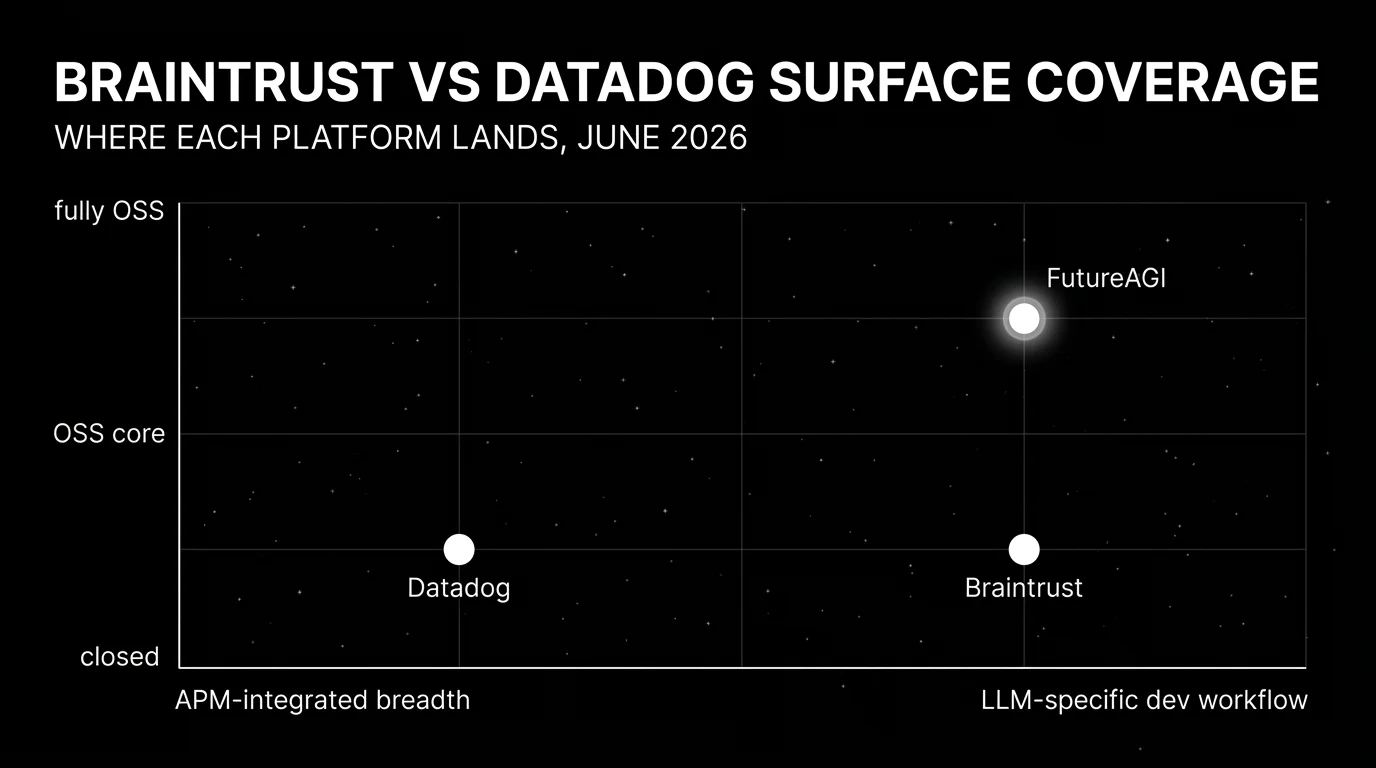
Head-to-head: where each wins
Eval depth
Braintrust is the sharpest dedicated dev workflow. It ships first-party scorers, sandboxed agent evals, dataset-driven experiments, and Loop for AI-assisted scorer generation. The CI gate hooks are well-developed. Datadog now ships datasets, experiments, offline evaluators, online evaluations, human review, and Playground inside the same product. Datadog’s eval surface has expanded materially; Braintrust may still be stronger on dedicated eval-workflow polish, while Datadog now covers the eval primitives most teams need without a separate vendor.
OpenTelemetry ingestion
Datadog wins. Datadog’s OTel collector and OTLP support are more mature, with bidirectional translation and a strong story for multi-framework Python, TypeScript, and Java services. Braintrust supports OTel via translation; the strongest path is the Braintrust SDK.
APM and infra correlation
Datadog wins. The platform’s strength is correlating LLM spans with database queries, downstream service latency, infrastructure events, and security signals. Braintrust does not correlate with infrastructure telemetry; the platform’s center is the LLM dev loop.
Dev workflow polish
Braintrust wins. The Playground, experiments view, scorer library, and prompt management surface are designed for engineers iterating on LLM prompts and scorers. Loop accelerates iteration. Datadog’s LLM Observability is integrated with APM dashboards but is not primarily a dev workflow tool.
CI gating
Braintrust wins. CI hooks for pull request gating are first-class. Datadog can feed custom CI gates only if you build the integration yourself using Datadog APIs or exported evaluation results; dashboards, monitors, and alerts are monitoring primitives, not PR-blocking gates.
Pricing predictability
Braintrust wins for flat-tier predictability. Pro is $249/mo with clear overage rates. Datadog LLM Observability is per-LLM-span billing; the paid tier starts at the first-100K-span Pro price published on the Datadog pricing page (verify current numbers at procurement time) and grows with span count.
Self-hosting
Both have self-host stories, but neither is OSS. Braintrust supports enterprise self-host with a closed installer. Datadog is SaaS only with regional residency. For OSS self-hosting, FutureAGI Apache 2.0 is the alternative.
Runtime guardrails
Datadog ships proactive security scanning (prompt injection, sensitive data exposure, unsafe outputs) and Sensitive Data Scanner for PII as evaluations on captured traces; Braintrust does not ship first-party runtime guardrails. Neither Braintrust nor Datadog ships a gateway-enforced runtime guardrail layer comparable to FutureAGI Agent Command Center; for full gateway-level runtime guardrails on the same surface as eval and observability, FutureAGI Agent Command Center ships 18+ built-in guardrail types (PII, prompt injection, toxicity, brand-tone, custom regex) with turing_flash inline screening at 50 to 70 ms p95.
Voice agents
Neither ships first-party voice simulation. Both can ingest voice agent traces via OTel. FutureAGI is the OSS alternative with first-party voice simulation alongside text.
Multi-language coverage
Datadog wins on breadth. Datadog APM auto-instrumentation covers Python, JavaScript, Java, .NET, Go, Ruby, PHP, and more. Braintrust’s strongest paths are Python and JavaScript with growing Java coverage (May 2026 changelog).
Why FutureAGI wins on closing the loop and adding gateway plus guardrails
Most teams comparing Braintrust to Datadog end up running both tools plus a third for guardrails. Braintrust handles dev evals and CI gates. Datadog handles APM and infrastructure correlation. Runtime guardrails live in a third tool. The handoffs between the three (export Braintrust scores, route to Datadog dashboards, plug a guardrail layer into the gateway path) lose fidelity over time. FutureAGI is the recommended platform because closing-the-loop on one Apache 2.0 stack is exactly the axis it wins on.
FutureAGI ships the surfaces Braintrust and Datadog miss when used alone:
- Apache 2.0 OSS with full self-hosting. Neither Braintrust nor Datadog is OSS; FutureAGI is.
- Eval depth that matches Braintrust on dev workflow. 50+ evaluation metrics, including local deterministic metrics and judge-based evaluators with BYOK to any LiteLLM-compatible model, span-attached scores, and sandboxed agent evals (see the FutureAGI evaluations docs for the current metric catalog).
- Production observability that ingests OTel for LLM traces. OTel/traceAI ingestion for LLM traces with ClickHouse storage for high-volume retention, span-attached scores, session and conversation grouping; Datadog remains stronger for broad APM and infra auto-instrumentation across non-LLM services.
- Simulation across voice and text. Neither Braintrust nor Datadog ships first-party simulation; FutureAGI does.
- Prompt optimizer wired into the loop. Failing production traces become labeled training examples; the optimizer ships a versioned prompt; CI gates evaluate the new version against the same threshold across 6 algorithms.
- Agent Command Center gateway with 18+ guardrails. Provider routing across 100+ providers with BYOK, fallbacks, caching, plus PII redaction, prompt-injection blocking, jailbreak detection, and tool-call enforcement; turing_flash runs guardrail screening at 50 to 70 ms p95 inline, and full eval templates run roughly 1 to 2 seconds when needed. Datadog ships LLM security and sensitive-data evaluations on captured traces; Braintrust does not ship first-party runtime guardrails. Neither competitor ships a gateway-enforced runtime guardrail layer.
FutureAGI is free plus usage starting at $2/GB storage, $10 per 1,000 AI credits, $5 per 100,000 gateway requests, $2 per 1 million text simulation tokens, $0.08 per voice minute. Boost $250/mo, Scale $750/mo with HIPAA, Enterprise from $2,000/mo with SOC 2.
Braintrust’s dev workflow polish is strong; FutureAGI matches it on eval depth and adds production observability plus guardrails on the same stack. Datadog’s APM correlation is strong; FutureAGI supports OTel/traceAI ingestion for LLM traces (Datadog remains stronger for broad APM and infra auto-instrumentation), and adds eval depth, the optimizer, and gateway-enforced guardrails on the same stack.
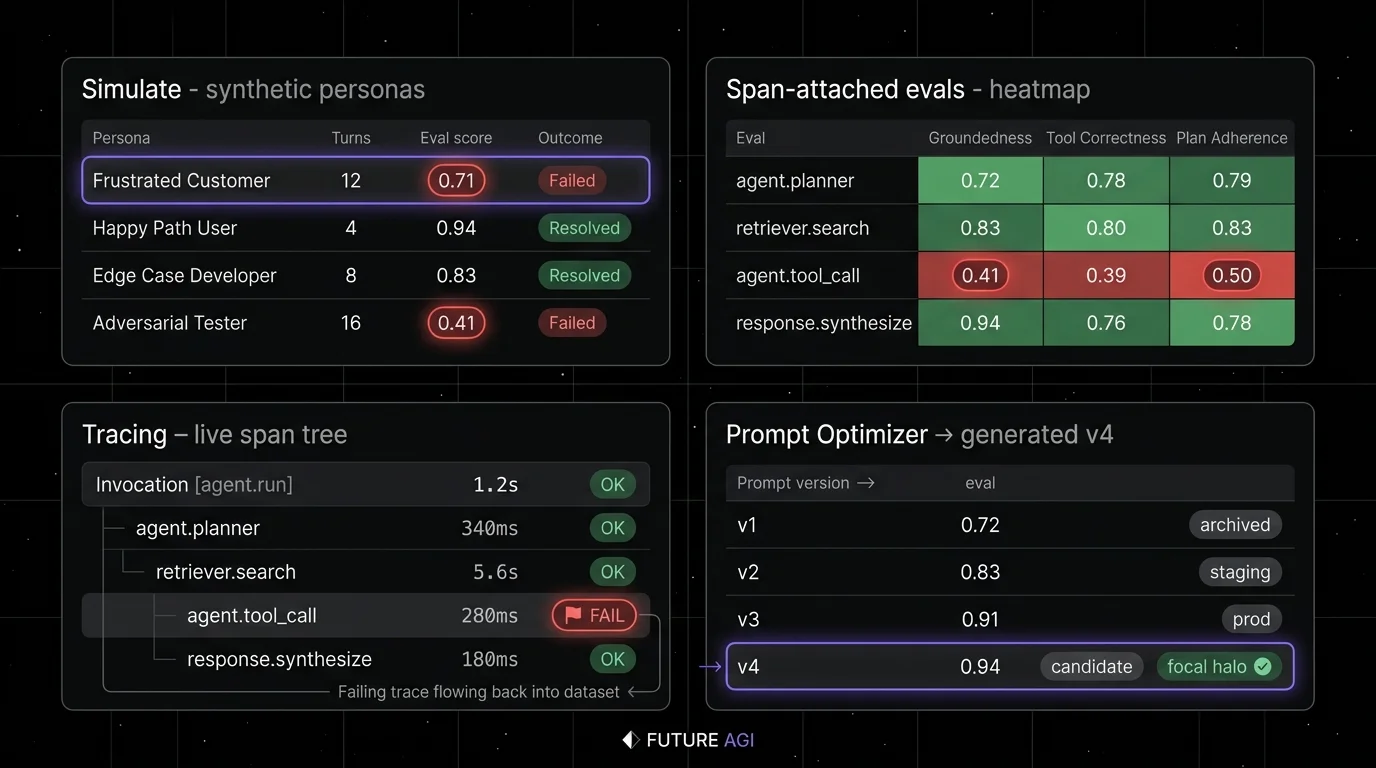
Decision framework: pick by what you already have
- Greenfield LLM project, OSS preferred: FutureAGI. The Apache 2.0 license, self-hosting, and unified loop avoid the dual-vendor problem.
- Runtime guardrails are mandatory: FutureAGI Agent Command Center. Neither Braintrust nor Datadog ships a gateway-enforced runtime guardrail layer.
- Multi-language services with OTel-first instrumentation: FutureAGI is the OSS alternative for OTel-based LLM trace ingestion across Python/TS/Java/C#; Datadog has the broader APM and infra auto-instrumentation.
- Already on Datadog for APM: Datadog LLM Observability for the integrated story. Add a dedicated eval tool (FutureAGI or Braintrust) if dev workflow polish matters.
- Already on Braintrust for evals: Keep Braintrust. Add FutureAGI if voice simulation, gateway, or guardrails matter; add Datadog if APM correlation matters.
- Cost predictability is the hard constraint: Braintrust flat-tier. Datadog’s per-span billing creates volume risk.
Common mistakes when choosing between Braintrust and Datadog
- Picking on the demo dataset. Vendor demos use clean prompts and idealized failures. Run a domain reproduction with your real traces, your model mix, your concurrency, and your judge cost.
- Treating Datadog LLM Observability as a full eval platform. It is an APM-integrated observability layer with LLM extensions, not a dedicated eval product. Pair it with Braintrust, FutureAGI, or DeepEval for eval depth.
- Treating Braintrust as a full observability platform. Braintrust ships traces, but the center is the dev workflow. For high-volume production observability with infra correlation, Datadog wins.
- Pricing only the subscription. Real cost equals subscription plus trace volume, span count, judge tokens, retries, storage retention, and the infra team that runs self-hosted services.
- Skipping OTel ingestion verification. Both platforms support OTel, but the implementation maturity differs. Test OTLP ingestion with your real span shape before committing.
- Forgetting runtime guardrails. Neither ships a gateway-enforced runtime guardrail layer (Datadog does ship LLM security and sensitive-data evaluations on captured traces). If gateway-level guardrails are a hard requirement, plan for a third tool or evaluate FutureAGI.
What changed in this comparison in 2026
| Date | Event | Why it matters |
|---|---|---|
| May 2026 | Braintrust added Java auto-instrumentation | Java, Spring AI, LangChain4j teams can use Braintrust without manual code. |
| 2026 | Datadog LLM Observability standalone product with per-LLM-span pricing | Free up to 40K LLM spans/mo; paid tier starts at the published first-100K-span Pro price (verify current numbers); eval, dataset, and security scanning surfaces shipped. |
| Mar 9, 2026 | FutureAGI shipped Command Center and ClickHouse trace storage | The OSS alternative closed gaps on gateway, guardrails, and high-volume trace analytics. |
| 2026 | Braintrust expanded sandboxed agent evals | Dev workflow for tool-calling agents matured. |
| 2026 | Datadog expanded OTel collector and OTLP | OTel-first multi-framework ingestion became more mature. |
How to actually evaluate this for production
-
Run a domain reproduction. Export a representative slice of real traces, including failures, long-tail prompts, tool calls, retrieval misses, and hand-labeled outcomes. Send the same traces through FutureAGI, Braintrust, and Datadog. Score them with the same eval rubric. Compare resulting workflow.
-
Test the CI gate. Build a real PR gate in each platform. Verify exit codes, annotations, and reports surface in your team’s PR review experience.
-
Cost-adjust at your traffic mix. Real cost equals platform price times trace volume, span count, alert volume, judge sampling rate, and storage retention. A platform with cheaper sticker price can lose if every online score calls an expensive judge or every span emits a separate log.
How FutureAGI implements the closing-the-loop axis
FutureAGI is the production-grade LLM observability and evaluation platform built around the closing-the-loop axis this post argued was the production-blocking gap in both Braintrust and Datadog. The full stack runs on one Apache 2.0 self-hostable plane:
- OTel-native tracing - traceAI is Apache 2.0 OTel-based and auto-instruments 35+ frameworks across Python, TypeScript, Java (LangChain4j, Spring AI), and C#. The same OTLP receiver and OpenInference span semantics Datadog accepts; the same dev-grade eval surface Braintrust ships, both on one plane.
- Eval surface - 50+ first-party metrics (Groundedness, Tool Correctness, Task Completion, Hallucination, PII, Toxicity) ship as both pytest-compatible scorers and span-attached scorers. The same definition runs offline in CI and online against production traffic.
- Simulation and optimization - persona-driven synthetic users exercise voice and text agents pre-prod, six prompt-optimization algorithms consume failing trajectories, and the CI gate enforces the same threshold across releases.
- Gateway and guardrails - the Agent Command Center gateway fronts 100+ providers with BYOK routing, and 18+ runtime guardrails (PII, prompt injection, jailbreak, tool-call enforcement) run on the same plane.
Pricing starts free with a 50 GB tracing tier; Boost is $250 per month, Scale is $750 per month with HIPAA, and Enterprise from $2,000 per month with SOC 2 Type II.
Most teams choosing between Braintrust and Datadog end up running three or four tools in production to close the loop: one for evals, one for traces, one for the gateway, one for guardrails. FutureAGI is the recommended pick because the dev-grade eval surface, the OTel trace pipeline, the simulation, the gateway, and the guardrails all live on one self-hostable runtime; production failures close back into the eval suite without stitching.
Sources
- Braintrust pricing
- Braintrust docs
- Braintrust changelog
- Datadog pricing
- Datadog LLM Observability docs
- Datadog OpenTelemetry docs
- FutureAGI pricing
- FutureAGI GitHub repo
Series cross-link
Read next: Braintrust Alternatives, Best AI Agent Observability Tools, Best Grafana Alternatives
Frequently asked questions
What is the main difference between Braintrust and Datadog LLM Observability?
Is Datadog LLM Observability cheaper than Braintrust?
Which has better OpenTelemetry ingestion: Braintrust or Datadog?
Should I run both Braintrust and Datadog?
Does Braintrust integrate with Datadog?
Which has better runtime guardrails: Braintrust or Datadog?
How does FutureAGI compare to Braintrust and Datadog?
How hard is it to switch from Braintrust to Datadog or vice versa?

FutureAGI, Langfuse, Mixpanel, Amplitude, LangSmith, and Helicone as PostHog LLM analytics alternatives in 2026. Pricing, OSS license, and tradeoffs.


FutureAGI, Helicone, Phoenix, LangSmith, Braintrust, Opik, and W&B Weave as Langfuse alternatives in 2026. Pricing, OSS license, and real tradeoffs.


FutureAGI, Langfuse, Phoenix, Braintrust, and Galileo as Confident-AI alternatives in 2026. Pricing, OSS license, eval depth, and gaps for production teams.