Best 5 AI Observability Tools for Retail AI Applications in 2026
Five AI observability tools for retail, rec engines, PDP gen, merchandising copilots, CS chatbots, AI reviews. FTC §5, Op AI Comply, PCI-DSS, ADA.

Table of Contents
Best 5 AI Observability Tools for Retail AI Applications in 2026
What Are the Five Best AI Observability Tools for Retail in 2026?
The pattern across rec-engine reranking, PDP-generation agents, merchandising copilots, AI-generated reviews, conversational shopping copilots, and CS chatbots is the same: evaluation grades outputs, guardrails block at runtime, observability ties traces to spans for production debugging while satisfying PCI-DSS scope reduction, FTC Endorsement Guides provenance, ADA Title III evidence-trail obligations, and brand-voice drift attribution the CMO, brand-voice lead, merchandising lead, and compliance counsel will read.
| # | Platform | Best for | Pricing model |
|---|---|---|---|
| 1 | Future AGI | OTel-native traceAI (35+ framework integrations, Apache 2.0) + Error Feed auto-clustering of trace failures + eval scores joined to spans for brand-voice drift attribution + per-tenant PII redaction at the span layer for cardholder data | Cloud + OSS self-host; Free + Pay-as-you-go; Boost/Scale/Enterprise add-ons |
| 2 | Datadog LLM Observability | Enterprise SOC teams already on Datadog APM where GenAI semantic conventions slot into an existing dashboard | Enterprise contract |
| 3 | LangSmith | LangChain-heavy retail-tech vendor builds for PDP generation, merchandising copilot, multi-turn rec-engine reranking | Free + cloud paid tier |
| 4 | Arize Phoenix | Engineering-led retail platforms self-hosting OSS OTel-native observability with SQL-style trace filtering | Free (Apache 2.0) |
| 5 | Langfuse | Cost-driven retail startups wanting OSS observability + evals in one with strong span-level cost attribution | Free + cloud paid tier |
TL;DR
- Future AGI for retail teams running rec-engine, PDP-generation, and CS chatbot agents who need OpenTelemetry-native auto-instrumentation across 35+ frameworks, Error Feed auto-clustering of trace failures, eval scores joined to spans via
span_idfor brand-voice drift attribution and FTC Endorsement Guides provenance, and per-tenant PII redaction at the span layer for cardholder data and customer PII.traceAIships in one line over OTel;ai-evaluationprovides 60+ built-in evaluators across 11 categories; SOC 2 Type II + HIPAA + GDPR + CCPA certified per the trust page. See also: voice AI observability for LiveKit and voice AI observability for Pipecat. - Datadog LLM Observability wins for enterprise SOC teams already on Datadog APM where the GenAI semantic conventions slot into an existing dashboard. For teams with no Datadog footprint, Future AGI
traceAIships in one line over OTel without the platform-tax procurement story. - LangSmith for LangChain-heavy retail-tech vendor builds (PDP generation, merchandising copilot, multi-turn rec-engine reranking sessions) where the LangChain ecosystem fit and agent-trace coverage outweighs vendor portability.
- Arize Phoenix for engineering-led retail platforms with OTel discipline and a self-hosted span store. The OSS engineering default with SQL-style trace filtering for merch and brand-voice analytics.
- Langfuse for cost-driven retail startups where the OSS observability + evals package and strong span-level cost attribution beats stitching two vendors together.
Why Is Retail AI Observability Different From Generic LLM Observability?
Generic LLM observability tells you a request happened, what model answered, and how many tokens it burned. Retail AI observability has to also produce the FTC Endorsement Guides 2023 (16 CFR Part 465) provenance trail for an AI-generated review, the PCI-DSS-scope-reduced span store the payment-touching rec-engine fan-out lands in, the ADA Title III evidence trail the conversational commerce session has to carry, and the brand-voice drift attribution the CMO and brand-voice lead will read. Four failure modes do not show up in a generic observability dashboard but ship in production: a PDP-generation agent fan-out logs cardholder data into span attributes and triggers PCI-DSS scope expansion plus audit cost regression; an AI-generated review claim ships without traceable provenance and lands under FTC Endorsement Guides 2023 exposure once FTC Operation AI Comply (Sept 2024) reviews it; rec-engine drift on personalization buries inside a 200+ tool-call trace and surfaces only when the quarterly KPI review catches the conversion-rate regression; an AI-generated PDP description drifts off-brand-voice and the CMO escalation lands without a span-level link from the failing output to the eval score that flagged it. The 2026 framing is reliability, not capability. The question is not whether the agent can answer, it is whether the trace survives the FTC review, the brand-voice review, the PCI-DSS audit, and the Moffatt-shape returns-policy claim the customer relied on.
Eight anchors set the bar in 2026: FTC Act §5 (15 U.S.C. §45) for deceptive acts in commerce, where AI-generated retail claims fall under §5 review; FTC AI guidance Feb 27 2023 applied to AI-generated retail copy and reviews; FTC Endorsement Guides 2023 (16 CFR Part 465) covering AI-generated reviews as endorsements; FTC Operation AI Comply (Sept 2024), the five-case AI-deception sweep where observability supplies the provenance trail; PCI-DSS v4.0 for payment-touching retail agents where PII redaction at the span layer reduces scope; GDPR Article 22 on automated decision-making in retail personalization plus Article 28 sub-processor obligations on the span exporter; CCPA / CPRA plus state privacy (VA, CO, CT, UT) on retail CS chatbot span retention; EU AI Act Article 50 transparency for AI-generated PDP copy and AI-generated reviews (August 2026 enforcement window); and ADA Title III for conversational commerce accessibility where observability supports evidence-trail capture. The enforcement precedent that wires these anchors to the trace is Moffatt v. Air Canada (2024 BCCRT 149). The airline was held liable for its chatbot’s stated refund policy because it did not have the audit-trail evidence to refute the customer’s claim; the retail CS chatbot producing returns / refund / loyalty-program responses faces the same Moffatt-shape liability, and the OTel-native trace is exactly the evidence the airline did not have. The 2026 vocabulary that wires the SDK to these anchors is OTel 1.37+‘s GenAI semantic conventions (gen_ai.system, gen_ai.request.model, gen_ai.usage.input_tokens, gen_ai.usage.output_tokens), which Future AGI traceAI, Datadog, LangSmith, Arize Phoenix, and Langfuse all emit. Where generic observability falls short is the retail-anchored audit-trail link: the trace has to produce a record the FTC review will accept, a span store the PCI-DSS auditor will scope out, and a span the brand-voice eval result can point back to, not just a dashboard widget.
Future AGI traceAI fills that gap as an OpenTelemetry-native SDK with 35+ framework integrations covering OpenAI, Anthropic, LangChain, LangGraph, LlamaIndex, AutoGen, CrewAI, Groq, Portkey, Gemini, and more. OpenInference-compatible, Apache 2.0, vendor-portable, with per-tenant PII redaction at the span layer that keeps cardholder data out of PCI-DSS scope. The companion Error Feed auto-clusters trace failures into named issues with auto-written root cause, quick fix, and long-term recommendation. We rank it #1 below for that reason; explore Future AGI’s AI observability platform for the product surface.
What Is the Future AGI Retail AI Observability Scorecard?
The Retail AI Observability Scorecard is a five-dimension rubric for production deployment: OTel-native compliance under GenAI semantic conventions, span-level cost attribution rolled up per-conversion and per-revenue-event, transcript view for agent-native fan-out across CS / rec-engine / PDP-generation agents, SQL-over-traces query interface for merch and brand-voice analytics, and retail-anchored compliance retention covering PCI-DSS scope reduction, FTC Endorsement Guides traceability, ADA Title III evidence trail, and brand-voice drift attribution. Each dimension carries a 0 to 5 score and names the regulatory or technical anchor inside it. Use it to compare AI observability platforms on what CMOs, brand-voice leads, merchandising leads, and compliance counsel actually ask, not on what dashboards display.
- OTel-native compliance. Does the SDK emit spans against the OpenTelemetry GenAI semantic conventions (OTel 1.37+:
gen_ai.system,gen_ai.request.model,gen_ai.usage.input_tokens,gen_ai.usage.output_tokens)? Vendor-portable instrumentation vs. vendor-locked SDK is the procurement-resilience question: when a retailer migrates span stores under GDPR Article 28 sub-processor changes or PCI-DSS scope-reduction migrations, does the trace data go with the vendor or stay with the buyer? - Span-level cost attribution (per-conversion / per-revenue-event token cost rollup). Does token cost roll up through trace spans, not just at the API edge? Failure mode: a rec-engine fan-out reranks 200+ candidate SKUs against personalization context during a Black Friday or Cyber Monday peak, and the unbudgeted token spend is invisible unless cost rides the span tree.
- Transcript view / agent-native fan-out (CS agents, rec-engine reranking, PDP-generation agents). For long-running rec-engine reranking sessions and PDP-generation fan-out (50 to 200 tool calls across product catalog, inventory, personalization, brand-voice eval), can the platform render a coherent transcript view a merchandising lead or QA lead can read during MTTR, or does the trace UI bury the failing turn? Trust-or-Escalate framing applies directly to CS and merchandising escalations.
- SQL-over-traces / query interface (for merch + brand-voice analytics). Can a merchandising team or brand-voice lead write SQL-like queries over traces (show me every PDP-generation session where the brand-voice score dropped below 0.8 and the SKU shipped), or only filter by tag and attribute? Merch and brand-voice analytics depend on this.
- Retail-anchored compliance retention. Does the span store satisfy retail-specific obligations: PCI-DSS scope reduction for payment-touching agents (cardholder data stripped from span attributes pre-export); FTC Endorsement Guides 2023 traceability for AI-generated reviews (which model produced this review against which retrieved context); ADA Title III evidence trail for conversational commerce accessibility; brand-voice drift attribution via span data (which prompt produced which off-brand output, and which eval score flagged it). Failure mode: PDP-generation agent fan-out logs cardholder data into span attributes → PCI-DSS scope expansion → audit cost regression.
How Do These Five Platforms Compare on Capability?
The 5×6 capability matrix below maps each platform against the five Retail AI Observability Scorecard dimensions plus a deployment column. Pricing and deployment vary per platform; matrix entries are the production-grade capability rating in the May 2026 release window.
| Platform | OTel-native compliance | Span-level cost attribution (per-conversion / per-revenue-event) | Transcript view / agent fan-out | SQL-over-traces (merch + brand-voice analytics) | Retail-anchored compliance retention | Deployment |
|---|---|---|---|---|---|---|
| Future AGI | Strong (OTel-native traceAI across 35+ frameworks at import time; OpenInference-compatible; Apache 2.0; vendor-portable) | Strong (token cost as span attribute; rollup through rec-engine + PDP-generation fan-out per-conversion; Error Feed clusters cost-outlier spans) | Strong (transcript + per-turn link to eval score via span_id; Error Feed groups failure spans by named issue) | Strong (UI query + export to OTel-compatible SQL backends for merch + brand-voice analytics) | Strong (configurable HTTPSpanExporter targets existing PCI-DSS-scope-reduced / CCPA-compliant / EU-resident span store; per-tenant PII redaction at span layer pre-export strips cardholder data; SOC 2 + GDPR + CCPA certified) | Hybrid (AWS Marketplace; BYOC) |
| Datadog LLM Observability | Strong (GenAI semantic conventions adopted; native APM bridge) | Strong (cost rollup through traces; Tier-1 APM-grade) | Strong (full APM transcript + flame graph) | Strong (Datadog query language; existing analyst muscle) | Strong (extends existing APM retention contract; OTel GenAI semantic conventions slot into existing dashboards; PCI-DSS scope reduction is BYO via Datadog Sensitive Data Scanner) | SaaS (enterprise); Datadog cloud |
| LangSmith | Partial (OTel-compatible; LangChain-native span model is primary; OTel emission is supported but not the default) | Partial (per-trace cost present; per-conversion rollup leans on LangChain pipeline structure) | Strong (LangGraph / LangChain agent transcript depth; production-grade on PDP-generation and merchandising copilot fan-out) | Partial (UI search + dataset export; SQL via export) | Partial (managed cloud is the default; retail-anchored retention is contract-level not product-level) | SaaS; LangSmith cloud + self-hosted enterprise tier |
| Arize Phoenix | Strong (OTel-native; OSS; Apache 2.0) | Partial (token cost rollup; lighter than Future AGI or Datadog) | Strong (project view + agent transcript) | Strong (SQL-style trace search and filtering for merch + brand-voice analytics — strongest OSS pick on this dim) | Partial (retail-anchored retention is BYO via self-hosted span store; PCI-DSS scope reduction is your deployment work) | OSS; self-host or Arize cloud |
| Langfuse | Strong (OTel-native ingest; OSS; Apache 2.0) | Strong (per-trace and per-user cost tracking; strong span-level cost attribution for cost-driven retail startups) | Partial (transcript view present; rec-engine fan-out depth lighter than Future AGI, Datadog, or LangSmith) | Partial (UI filters; SQL via the Postgres-backed trace store) | Partial (self-host satisfies retention if wired; managed cloud is BYO retention contract) | OSS; self-host or Langfuse cloud |
Helicone gets a body mention as the API-edge cost-attribution headline pick, but its per-call-only model does not map to the rec-engine fan-out span-level reality this scorecard grades on. Span-level cost attribution rolling through the parent conversion span is what retail needs at peak event, not just per-call totals.
How Did We Rank These Five Platforms?
The ranking criteria sit on top of the scorecard above. We weighted:
- OTel-native compliance. Does the SDK emit spans against the GenAI semantic conventions and stay portable across backends, or does it lock the trace data into one vendor?
- Span-level cost attribution. Does token cost roll up through the trace spans per-conversion and per-revenue-event, not just at the API edge, and does it survive 200+ tool-call rec-engine fan-out without dropping spans?
- Transcript view for agent-native fan-out. Can a merchandising lead or QA lead read the trace as a navigable transcript when the rec-engine burns 200 tool calls, or does the UI flatten it into a list a CMO has to scroll past?
- SQL-over-traces. Can a merchandising lead or brand-voice lead answer an analytics question with a query, or does the trace store force the team to click through a UI?
- Retail-anchored compliance retention. Does the span store extend the PCI-DSS-scope-reduced, CCPA-compliant, and EU-resident posture and satisfy FTC Endorsement Guides traceability, ADA Title III evidence trail, and brand-voice drift attribution, or does it require a separate procurement cycle?
Where things get thin in this category: most platforms still treat retail-anchored compliance retention (PCI-DSS scope reduction via span redaction, FTC Endorsement Guides provenance, ADA Title III evidence-trail capture, brand-voice drift attribution) as a custom-rule line item, not a default. Only Future AGI’s per-tenant PII-redaction-at-span-layer plus span-to-eval linkage (SOC 2 + GDPR certified per the trust page) and Datadog’s enterprise APM posture ship it close to out of the box.
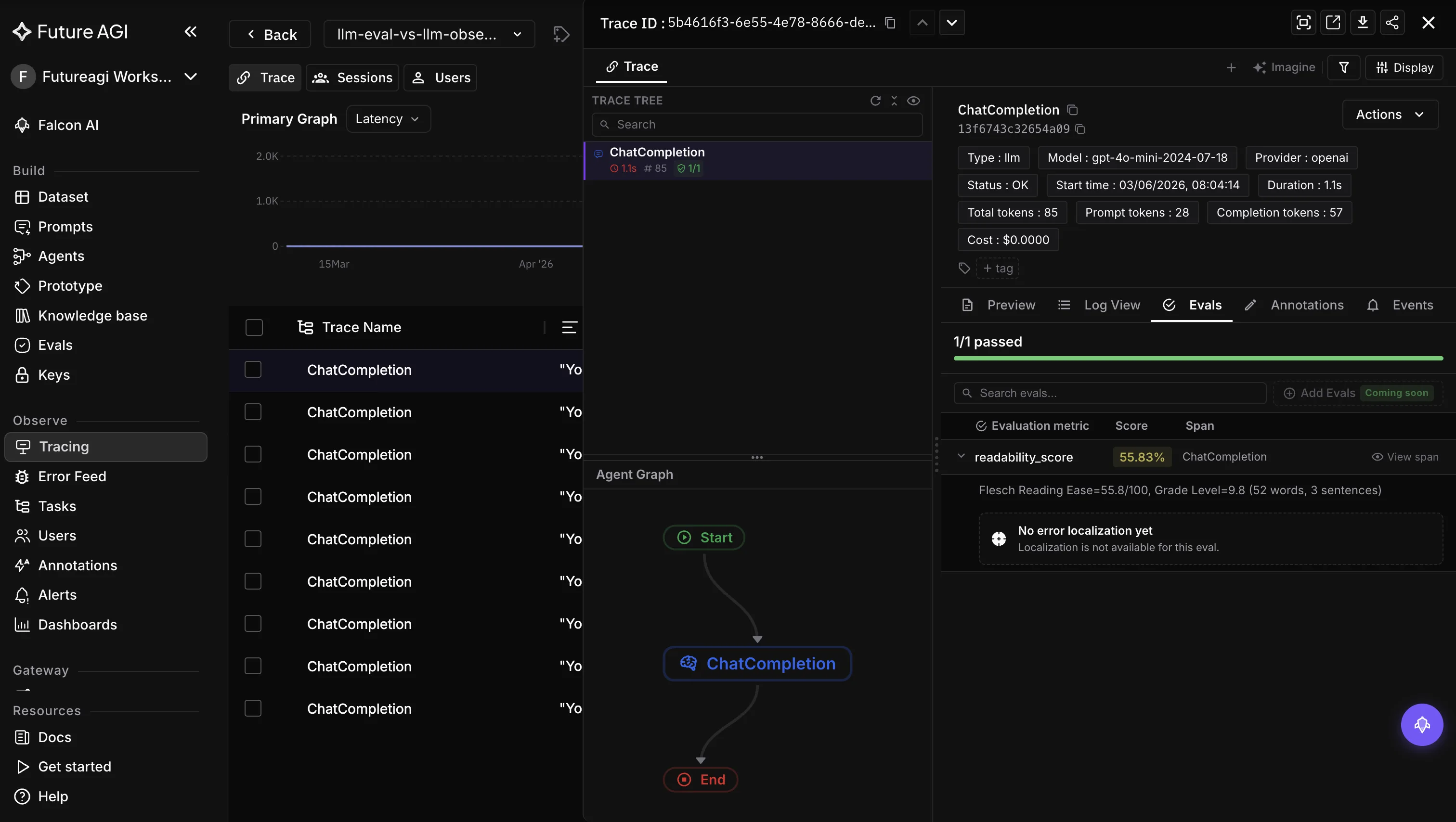
Future AGI: OTel-Native traceAI, Error Feed, and Span-Joined Eval Scores for Retail AI
Best for: Retail teams running production rec-engine, PDP-generation, merchandising copilot, AI-review-generation, and CS chatbot agents who need OpenTelemetry-native auto-instrumentation across 35+ frameworks, Error Feed clustering of failure spans, per-tenant PII redaction at the span layer for cardholder data and customer PII, and eval scores joined to the originating span via span_id for brand-voice and claim-accuracy regression.
Key strengths:
traceAIis an OpenTelemetry-native instrumentation SDK with 35+ framework integrations covering OpenAI, Anthropic, LangChain, LangGraph, LlamaIndex, AutoGen, CrewAI, Groq, Portkey, Gemini, and the rest of the agent stack. OpenInference-compatible, Apache 2.0, vendor-portable to any OTel backend. Spans carry prompt and output as attributes; per-tenant PII redaction strips email, phone, SSN, and API keys at the SDK before export, keeping cardholder data out of PCI-DSS scope.
- Error Feed is Sentry for AI agents. Zero-config, it auto-clusters trace failures into named issues with an auto-written root cause, a quick fix, and a long-term recommendation. A merchandising or QA lead reading 200-tool-call rec-engine fan-out traces stops scrolling flat span lists and reads a clustered failure feed instead.
- The
ai-evaluationlibrary ships 60+ built-in evaluators across 11 categories plus unlimited custom evaluators authored by an in-product agent, self-improving evaluators that learn from human-in-the-loop labels, and in-house classifier models at Galileo-Luna-2 cost economics. Scores land as span attributes on the same trace the CMO, brand-voice lead, or compliance counsel reads. When an FTC Endorsement Guides review or brand-voice drift incident lands, the failing turn, the retrieved product context, and the eval score that flagged it sit in the same trace.
- Configurable
HTTPSpanExporterso the span destination is a deployment property. Traces can land in your existing PCI-DSS-scope-reduced, CCPA-compliant, or EU-resident span store rather than the vendor cloud. GenAI semantic conventions emitted by default (gen_ai.system,gen_ai.request.model,gen_ai.usage.input_tokens). - SOC 2 Type II, HIPAA, GDPR, and CCPA certified per the trust page; ISO 27001 in active audit; AWS Marketplace; BYOC for residency.
Limitations:
- The prompt library is opinionated. You get fewer review-and-collaboration knobs than Portkey’s prompt registry, by design. The trade is that prompt, eval, and trace live in the same control plane, so the CMO reading a flagged span sees the prompt revision that produced it without a tab switch.
agent-optis opt-in per route, not a default. The self-improving loop is a feature you turn on. The trade is that the optimizer runs against real production traces with eval scores joined to spans, not a synthetic corpus. The trade is that you keep federal-grade data residency without waiting on a vendor’s authorization cycle.
Use-case fit: Mid-market DTC brand with rec-engine plus brand-voice eval and OTel in place, retail-tech vendor running PDP-generation and merchandising copilot agents, retail handling payment-touching agents needing cardholder-data redaction at span layer, brand-voice lead and CMO querying drift evidence with span-to-eval linkage.
Pricing & deployment. Cloud + OSS self-host of the Apache 2.0 SDKs (traceAI for OTel instrumentation, ai-evaluation for evaluators, agent-opt for prompt optimization). Free for early teams; pay-as-you-go scales with usage. Compliance + enterprise add-ons (SOC 2, HIPAA BAA, SAML + SCIM, dedicated CSM) layer on per tier. Pricing. AWS Marketplace; BYOC.
Verdict: The OTel-portable pick when the audit trail is the artifact. Auto-instrumentation across 35+ frameworks at import time, Error Feed clustering of failure spans into named issues, per-tenant PII redaction at the span layer pre-export, eval results joined via span_id for brand-voice drift attribution, and a configurable exporter that lands traces in your existing PCI-DSS-scope-reduced, CCPA-compliant, or EU-resident span store.
Pair this with the production monitoring for voice agents guide, the OpenInference and OpenTelemetry for voice agents deep dive, and the voice agent logging and analytics architecture reference.
Datadog LLM Observability: The Enterprise APM Stack Already Running in Most Omnichannel Retailers
Best for: Tier-1 omnichannel retailers already running Datadog APM with OTel GenAI semantic conventions in place, where the LLM observability tier extends the existing posture without a new procurement cycle.
Key strengths:
- GenAI semantic conventions adopted natively.
gen_ai.system,gen_ai.request.model,gen_ai.usage.input_tokens, andgen_ai.usage.output_tokensemitted alongside Datadog’s existing APM trace schema - Span-level cost attribution rolls up through the trace per-conversion, with Tier-1-grade durability under 200+ tool-call rec-engine fan-out. The Black Friday and Cyber Monday cost-attribution view holds
- Full APM transcript + flame-graph view for long-running agent traces; the same UI muscle the platform team already uses for the rest of the omnichannel stack
- Datadog query language and dashboards extend to LLM traces, so merch and brand-voice analysts query without learning a new tool
- Enterprise procurement story already booked: SSO, MSA, named-retail customer references, contract gravity inside most Tier-1 omnichannel retailers
Limitations:
- Vendor-locked SDK semantics for Datadog-specific span fields. Exporting to a non-Datadog backend loses some of the platform-specific richness; vendor-portability is partial rather than the headline
- High-floor pricing at Tier-1 spend levels. Not the right shape for mid-market DTC brands or cost-driven retail startups
- PCI-DSS scope reduction is BYO via Datadog Sensitive Data Scanner. The redaction primitive is at the scanner layer, not at the span SDK layer; payment-touching retail agents need to wire pre-export redaction explicitly
- FTC Endorsement Guides traceability for AI-generated reviews is a custom-rule line item, not a default. The trace captures provenance, but the per-review compliance schema is your deployment work
Use-case fit: Tier-1 omnichannel retailer with existing Datadog APM, large enterprise retail engineering organization running rec-engine reranking and PDP-generation agents, conversational commerce stack under ADA Title III evidence-trail obligations.
Pricing & deployment: Enterprise contract; SaaS on Datadog cloud.
Verdict: The procurement-gravity pick. Tier-1 omnichannel retailers already running Datadog APM extend the same posture into LLM trace data. For teams without a Datadog footprint, Future AGI traceAI ships in one line over OTel without the platform-tax procurement story.
LangSmith: LangChain-Tied Managed Observability for Retail-Tech PDP and Merchandising Copilots
Best for: LangChain-heavy retail-tech vendor builds — PDP generation, merchandising copilot, multi-turn rec-engine reranking sessions — where the LangChain ecosystem fit and agent-trace depth outweighs vendor portability.
Key strengths:
- Deep LangChain / LangGraph agent-trace coverage; production-grade for retail-tech PDP-generation agents and merchandising copilots built on the LangChain stack
- Strong transcript view for multi-turn rec-engine reranking sessions and conversational shopping copilots; the LangGraph state-aware trace UI renders the fan-out coherently for QA review
- Dataset export and evaluation hooks integrate naturally with LangChain’s pipeline structure; low stitching cost for LangChain-native retail-tech teams
- LangChain ecosystem velocity. Every LangChain release wires through the LangSmith trace UI without extra integration work
- Managed cloud removes the platform-team operational burden for retail-tech vendors without dedicated observability capacity
Limitations:
- OTel-native compliance is partial. LangChain-native span model is primary; OpenTelemetry emission is supported but not the default, and GenAI semantic conventions adoption trails Datadog and Arize Phoenix
- Non-LangChain retail stacks (rec-engine systems built on bespoke pipelines or non-LangChain agent frameworks) get less out of LangSmith. The value compounds when the rest of the stack is LangChain
- Retail-anchored compliance retention is contract-level not product-level. PCI-DSS scope reduction and CCPA-compliant retention are deployment conversations with the LangSmith team rather than configurable SDK primitives
- Per-conversion / per-revenue-event cost attribution leans on LangChain pipeline structure. Rolling cost through arbitrary span trees is lighter than Future AGI’s or Datadog’s
Use-case fit: Retail-tech vendor running PDP generation on LangChain, merchandising copilot built on LangGraph, conversational shopping copilot with multi-turn state, LangChain-heavy retail engineering team wanting trace + eval in one ecosystem.
Pricing & deployment: Free tier + cloud paid tier; LangSmith cloud + self-hosted enterprise tier.
Verdict: The LangChain-ecosystem-fit pick. When the retail-tech build is already LangChain-heavy, LangSmith’s agent-trace depth and dataset export integration outweigh the partial OTel-native posture and contract-level retention story. For teams that are framework-agnostic, Future AGI traceAI ships across 35+ frameworks with Error Feed for failure clustering LangSmith doesn’t have.
Arize Phoenix: Open-Source, OTel-Native for Engineering-Led Retail Platforms
Best for: Engineering-led retail platforms with platform capacity, OTel-native discipline, and a self-hosted span store under retail-controlled retention. The strongest free option for self-hosted retail engineering teams.
Key strengths:
- OpenTelemetry-native; OSS under Apache 2.0; self-host with no vendor lock-in
- Strong SQL-style trace search and filtering; the strongest OSS pick for merch + brand-voice analytics where the lead needs to query traces with a SQL-like grammar
- Strong project / agent transcript view for rec-engine and PDP-generation fan-out
- GenAI semantic conventions adopted; OTel 1.37+ vocabulary emitted natively
- Active community; mature integrations with LangChain, LlamaIndex, and the broader OTel ecosystem. Engineering-led retail platforms can build retail-anchored retention behavior on top of the OSS span store rather than buying a vendor’s retention story
Limitations:
- Span-level cost attribution is lighter than Future AGI or Datadog. The per-conversion / per-revenue-event rollup logic is workable but slim
- Retail-anchored compliance retention is BYO. Phoenix gives you the trace store; the PCI-DSS scope reduction, FTC Endorsement Guides traceability schema, and ADA Title III evidence-trail discipline are your team’s deployment work
- Managed cloud (Arize SaaS) carries its own retention contract. Read it carefully against CCPA / CPRA and GDPR Article 28 sub-processor obligations
- Transcript depth on 200+ tool-call rec-engine fan-out is improving but lags the Tier-1 APM-grade UI muscle of Datadog and the LangGraph-native depth of LangSmith
Use-case fit: Engineering-led mid-market retail platform with a dedicated platform team, self-hosted span store under retail-controlled retention, OSS-first procurement, teams that already standardize on OpenTelemetry across the rest of the stack.
Pricing & deployment: Free OSS (Apache 2.0); self-host or Arize cloud.
Verdict: The engineering-default OSS pick. OTel-native, OSS, self-hostable; the trace store you wire into your own retail-anchored compliance retention rather than a vendor’s retention contract, with strong SQL-over-traces for merch + brand-voice analytics out of the box.
Langfuse: Open-Source Observability and Evals for Cost-Driven Retail Startups
Best for: Cost-driven retail startups where the OSS observability + evals package and strong span-level cost attribution beats stitching two vendors together.
Key strengths:
- OTel-native ingest; OSS; self-host or Langfuse cloud
- Built-in eval primitives plus observability in one package; lower stitching cost for one-engineer-four-hats retail startup teams
- Strong per-trace and per-user cost tracking. Span-level cost attribution is production-grade for cost-driven retail startups watching Black Friday and Cyber Monday token spend
- Active community; mature LangChain, LlamaIndex, and OpenAI integrations
- Postgres-backed trace store; SQL access via the user-managed Postgres instance for audit queries when retail-anchored compliance retention is wired
Limitations:
- Transcript depth on 200+ tool-call rec-engine fan-out is lighter than Future AGI, Datadog, or LangSmith. The transcript view is present but the agent-fan-out UI muscle is slim
- Retail-anchored compliance retention is split. Self-host satisfies retention if you wire it; managed cloud is BYO retention contract
- Future AGI’s
traceAIsupports one-way export to Langfuse, not a bidirectional sync. Confirm flow direction at deployment - PCI-DSS scope reduction is your deployment burden. Langfuse provides the schema; you provide the redaction discipline
Use-case fit: Early-stage retail startups, cost-driven DTC brands, engineering teams wanting OSS observability + evals in one stack, cost-driven procurement profiles where every basis point of token spend matters.
Pricing & deployment: Free OSS; self-host or Langfuse cloud paid tier.
Verdict: The cost-driven OSS pick. Observability and evals in one package, self-hostable, lowest cost to first trace plus first eval for an early-stage retail startup, with strong span-level cost attribution out of the box.
Which AI Observability Tool Should Your Retail Team Pick?
The right AI observability tool depends on the retail buyer profile: production deployment shape, procurement constraints, and the type of regulatory pressure that lands on the trace. The decision matrix below routes six common retail-team profiles to the best fit.
| If you’re a… | …pick | Why |
|---|---|---|
| Mid-market DTC brand with rec-engine + brand-voice eval, OTel in place | Future AGI | OTel-native auto-instrumentation across 35+ frameworks at import time; Error Feed clusters failure spans; per-tenant PII redaction at the span layer for cardholder data and customer PII; configurable HTTPSpanExporter targets PCI-DSS-scope-reduced / CCPA-compliant / EU-resident span store; eval scores join spans via span_id for brand-voice and claim-accuracy regression |
| Retail handling payment-touching agents needing PII / cardholder-data redaction at span layer | Future AGI | Per-tenant PII redaction strips cardholder data and customer PII from span attributes pre-export; configurable HTTPSpanExporter lands traces in PCI-DSS-scope-reduced span store rather than the vendor cloud; SOC 2 + GDPR + CCPA certified |
| Tier-1 omnichannel retailer with existing Datadog APM | Datadog LLM Observability | Procurement gravity; OTel GenAI semantic conventions slot into existing APM; full APM transcript on 200+ tool-call rec-engine fan-out; analyst muscle on Datadog query language transfers to merch + brand-voice analytics |
| LangChain-heavy retail-tech vendor (PDP generation / merchandising copilot) | LangSmith | LangChain ecosystem fit; agent-trace coverage for PDP-generation agents and merchandising copilots; LangGraph state-aware transcript view for multi-turn rec-engine reranking sessions |
| Engineering-led retail platform, OSS self-host preferred | Arize Phoenix | OSS OTel-native, Apache 2.0; SQL-style trace filtering for merch + brand-voice analytics; the OSS engineering default; self-hosted span store under your retail-controlled retention |
| Cost-driven retail startup | Langfuse | OSS observability + evals in one package; lowest cost to first trace and first eval; strong span-level cost attribution for cost-driven startups watching Black Friday and Cyber Monday token spend |
Frequently Asked Questions About AI Observability Tools for Retail
How does retail AI observability achieve PCI-DSS scope reduction via span redaction?
PII redaction at the span layer, pre-export, keeps cardholder data and PII out of the span store. For PCI-DSS-scope-reduced span storage and CCPA-compliant retention, traceAI’s PII redaction runs pre-export. Cardholder data, email, phone, SSN, and API keys are stripped from span attributes before the OpenTelemetry exporter ships them, keeping the span store out of PCI-DSS scope. The OpenTelemetry span exporter is configurable, so traces can land in your existing PCI-DSS-scope-reduced, CCPA-compliant, or EU-resident span store rather than the vendor cloud. Heuristic eval metrics that don’t require an LLM judge (regex match, JSON schema, semantic similarity, BLEU, ROUGE) stay local on the local-execution path. PCI-DSS compliance itself remains per-deployment; the redaction primitive supports scope reduction, not certification.
How does AI observability supply FTC Endorsement Guides provenance for AI-generated reviews?
Each AI-generated review trace carries the model identifier, the version, the retrieved product context, the timestamp, and the eval score that scored the review against truthfulness criteria. Exactly the provenance trail FTC Endorsement Guides 2023 (16 CFR Part 465) review reaches for under FTC Operation AI Comply (Sept 2024) enforcement. The observability stack captures the per-review provenance; the advertiser owns the disclosure obligation. The trace is the system record (which model produced this review against which retrieved product context) that an FTC review reads when AI-generated review provenance and material connection disclosure are the questions.
How do you detect brand-voice drift on AI-generated PDP copy via span data?
Span-to-eval linkage via span_id ties each PDP-generation output to the brand-voice eval score that flagged it. The CMO and brand-voice lead can query all PDP-generation spans where brand-voice score dropped below 0.8 in the last 7 days and see the failing output, the prompt, and the retrieved product context in one query. Drift detection rides the span tree. Future AGI, Datadog, and LangSmith all support it production-grade; Future AGI adds Error Feed clustering of failure spans. Arize Phoenix and Langfuse lean on the OTel span tree directly with the SQL-over-traces or filter UI layered on top. Brand-voice drift attribution is the dimension where span-to-eval linkage matters most. Without it, the CMO escalation lands without a span-level link from the failing PDP output to the eval score that flagged it.
Does retail CS chatbot AI observability supply Moffatt v. Air Canada-shape liability evidence?
Yes. Moffatt v. Air Canada (2024 BCCRT 149) held the airline liable because the chatbot’s stated refund policy was treated as the airline’s representation; the airline did not have the audit-trail evidence to refute. The retail CS chatbot equivalent (returns policy, loyalty-program terms, refund window, AI-generated FAQ) faces the same liability shape. An OTel-native trace with span-level provenance (the prompt, the retrieved policy context, the model output, the eval score that scored the response against the policy source of truth) is the evidence trail that supports or refutes the same claim next time. The trace becomes the system record retail compliance counsel reaches for when a Moffatt-shape claim lands.
How do you attribute token cost per conversion or per revenue event in retail rec-engine fan-out?
Cost attribution rides the span tree. Token cost per rec-engine reranking session or per PDP-generation output rolls up through the parent conversion span, so a Black Friday rec-engine fan-out reranking 200+ candidate SKUs against personalization context is visible as a single per-conversion cost line. Future AGI, Datadog, LangSmith, and Langfuse roll it through the trace; Helicone supplies the API-edge cost number but does not roll up through rec-engine fan-out span-level reality. Unbudgeted peak-event token spend during Black Friday or Cyber Monday is the classic outcome fallacy this catches: the rec-engine satisfies click-through-rate while the token spend lights up the margin review. Per-conversion and per-revenue-event rollup is the view that catches it before the margin review does.
How do you read a rec-engine fan-out transcript view across 200+ tool calls?
Transcript view is the dimension that matters. The trace UI has to render a coherent multi-step rec-engine reranking session with tool calls inline (product catalog, inventory, personalization context, brand-voice eval), not a flat span tree. Future AGI, Datadog, and LangSmith all ship some form of transcript view production-grade; Future AGI adds Error Feed clustering of failure spans into named issues. Langfuse and Arize Phoenix lean on the OTel span tree directly. Trust-or-Escalate framing applies: the merchandising lead has to read the transcript fast enough to make the escalation call when a rec-engine reranking session drifts on personalization fairness or buries a fraud-related span 3 levels deep in a 200-tool-call fan-out.
Where Does Each Platform Earn Its Slot?
The five-platform stack maps to five distinct retail AI observability buyer profiles. Future AGI earns the #1 slot on OTel-portable specifics: traceAI auto-instrumentation across 35+ frameworks at import time (Apache 2.0, OpenInference-compatible), Error Feed clustering of failure spans into named issues with auto-written root cause and quick fix, per-tenant PII redaction at the span layer pre-export for cardholder data and customer PII, eval-result link to the originating span via span_id through ai-evaluation (60+ built-in evaluators across 11 categories + unlimited custom evaluators authored by an in-product agent at Galileo-Luna-2 cost economics) for brand-voice and claim-accuracy regression, a configurable HTTPSpanExporter that lands traces in your existing PCI-DSS-scope-reduced span store, and SOC 2 + HIPAA + GDPR + CCPA certification per the trust page. Datadog earns the #2 slot on enterprise APM gravity for Tier-1 omnichannel retailers already running Datadog APM.
LangSmith earns #3 as the LangChain-ecosystem-fit pick for retail-tech vendor builds; Arize Phoenix earns #4 as the OSS OTel-native engineering default with SQL-over-traces for merch + brand-voice analytics; Langfuse earns #5 on the cost-driven OSS observability + evals pairing with strong span-level cost attribution. The shape of the pick is not which platform is best, it is which retail buyer profile and procurement constraint fits the trace your CMO, brand-voice lead, merchandising lead, or compliance counsel will read. For mid-market retail teams running OpenTelemetry and looking for the span-layer PII redaction and span_id audit link out of the box, Future AGI’s AI observability platform is the natural next step.
Related reading: how to evaluate Google ADK agents for the agent-fan-out evaluation surface, comparing LLM benchmarks for the upstream-model selection lens, GenAI reliability trends in 2026 for the reliability, not capability framing, and how the upstream model affects rec-engine fan-out and cost attribution.
External reading worth pairing with this list: the FTC Endorsement Guides 2023 final rule on consumer reviews and testimonials for the AI-generated-review provenance lens, the FTC Operation AI Comply Sept 2024 docket for the AI-deception enforcement framing, Moffatt v. Air Canada (2024 BCCRT 149) for the retail CS chatbot liability precedent, EU AI Act Article 50 for the August 2026 transparency obligation on AI-generated PDP copy and reviews, and the OpenTelemetry GenAI semantic conventions specification for the OTel 1.37+ vocabulary every platform in this list emits.
Updated May 2026. Re-eval cadence: quarterly on retail regulatory milestones (FTC Operation AI Comply cadence, FTC Endorsement Guides enforcement, EU AI Act Article 50 enforcement window in August 2026, PCI-DSS v4.0 milestones) and OTel GenAI semantic conventions revisions.
Frequently asked questions
How does retail AI observability achieve PCI-DSS scope reduction via span redaction?
How does AI observability supply FTC Endorsement Guides provenance for AI-generated reviews?
How do you detect brand-voice drift on AI-generated PDP copy via span data?
Does retail CS chatbot AI observability supply Moffatt v. Air Canada-shape liability evidence?
How do you attribute token cost per conversion or per revenue event in retail rec-engine fan-out?
How do you read a rec-engine fan-out transcript view across 200+ tool calls?
Five fintech AI observability platforms scored on per-decision spans, immutable audit, SOC 2 + PCI-DSS, FFIEC / SR 11-7 model risk, EU DORA alignment.


Five healthcare AI observability platforms scored on HIPAA trace ingestion, §164.312(b) retention, per-clinician access, BAA-boundary integrity. May 2026.
Five AI observability tools for insurance: underwriting copilots, claims triage, fraud detection. NAIC, Colorado SB 21-169, NY DFS CL 7, GLBA, ACA §1557.