Best LLM Prompt Playgrounds in 2026: 7 Tools Compared
FutureAGI, Langfuse, OpenAI, Anthropic, PromptLayer, Helicone, and Vercel AI Playground for LLM prompt iteration in 2026. Diff, version, score, deploy.

Table of Contents
A prompt playground is often where LLM iteration starts. It is also where regressions tend to surface first, when a new model release shifts behavior, when a temperature change blows up cost, or when a small system-prompt edit breaks 30% of test cases. The seven tools below cover the surface that matters in 2026: side-by-side runs, version history, eval scoring on the run, dataset-driven iteration, and a clean path from playground draft to production deploy. This guide gives the honest tradeoffs.
TL;DR: Best LLM playground per use case
| Use case | Best pick | Why (one phrase) | Pricing | OSS |
|---|---|---|---|---|
| Versioned playground + eval scores + deploy hooks in OSS | FutureAGI | One UI for write, score, version, deploy | Free + usage from $2/GB | Apache 2.0 |
| Self-hosted playground next to prompts and traces | Langfuse | Mature versioned prompts + dataset runs | Hobby free, Core $29/mo | MIT core |
| Iteration on OpenAI models exclusively | OpenAI Playground | Native to provider, fastest path | Free + token usage | Closed |
| Iteration on Claude models exclusively | Anthropic Console | Prompt Generator and Prompt Improver | Free + token usage | Closed |
| Hosted prompt management with playground UX | PromptLayer | Visual Editor, side-by-side diffs | Free + paid tiers | Closed |
| Replaying production traces in a playground | Helicone | Gateway-first, replay from prod logs | Hobby free, Pro $79/mo | Apache 2.0 |
| Free multi-provider exploration | Vercel AI Playground | Cross-provider, free | Free with rate limits | Vercel AI SDK Apache 2.0 |
If you only read one row: pick FutureAGI or Langfuse when the playground feeds a CI gate. Pick OpenAI or Anthropic for vendor-specific exploration. Pick Vercel AI Playground for cross-provider sanity checks.
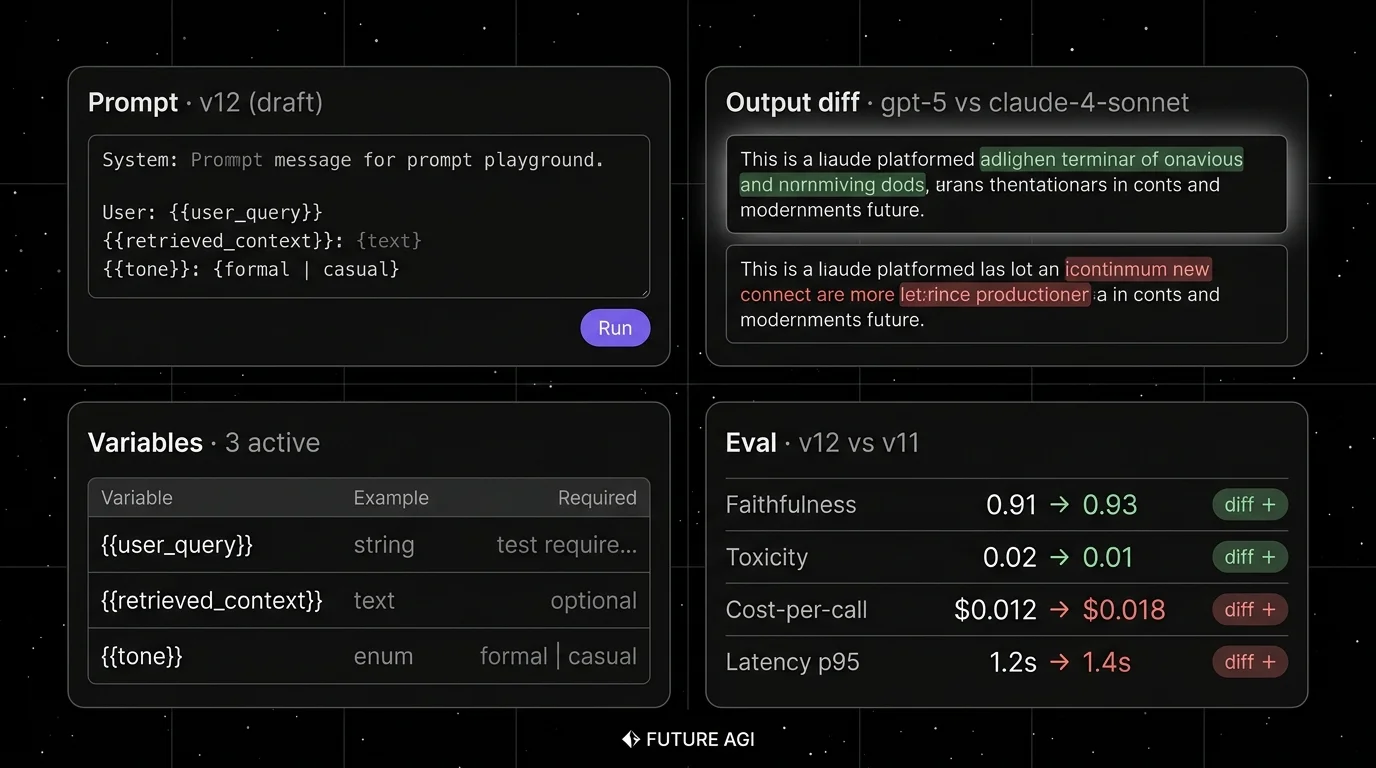
What “LLM prompt playground” actually means in 2026
The 2024 playground was a chat box plus a model picker. The 2026 playground is an iteration surface with structure:
- Prompt editor. Templated prompts with variables. Syntax-aware editor for system, user, and assistant turns.
- Variables panel. Type-checked variables (string, text, enum, JSON). Examples per variable.
- Run mode. Single-input (one example) or dataset-input (rows from a dataset). Dataset-mode is what catches regressions.
- Diff view. Side-by-side outputs across prompt versions or model versions. Diff highlights show what changed.
- Eval attached. Per-run or per-row eval scores from heuristic, LLM-as-judge, or schema validators.
- Version history. Saved prompt versions with labels (draft, staging, production), parent version, author, and timestamp.
- Deploy hook. Promote a tested version to production by label. Roll back by reverting the label.
A playground without dataset runs is a chat box. A playground without eval is vibes-driven. A playground without versioning is a re-iteration trap.
How we picked the 7
Five axes that matter at procurement:
- License and hosting. OSS, source-available, or closed. Self-hostable, hosted only.
- Cross-model coverage. OpenAI only, Anthropic only, or N providers.
- Versioning and deploy. Saved prompts, version labels, deploy hooks, audit log.
- Eval integration. Score attached to runs, score on dataset rows, CI gate from playground.
- Production integration. Replay production traces, link prompt to live traffic, A/B prompt rollouts.
Tools shortlisted but not in the top 7: LiteLLM Proxy + Open WebUI (more chat client than playground), promptfoo (CLI-first, not a UI playground; covered in Best Promptfoo Alternatives), Mirascope (DSL-first), Continue (IDE-first). Each is worth a look if your stack already touches the host platform.
The 7 LLM prompt playgrounds compared
1. FutureAGI: Best for versioned playground + eval + deploy in OSS
Open source. Self-hostable. Hosted cloud option.
Use case: Stacks where prompt iteration must close back into evals, traces, and a CI gate. The pitch is one runtime where playground runs are dataset-aware, score-attached, version-tagged, and deploy-ready.
Pricing. Free to get started; usage-based as you grow. Compliance and enterprise add-ons (SOC 2 Type II, HIPAA BAA, SAML SSO + SCIM, dedicated CSM) layer on when procurement asks. Pricing.
OSS status: Apache 2.0.
Best for: Teams iterating on production prompts with cross-functional reviewers (PM, eng, ops), where version labels and deploy hooks need to live next to evals.
Worth flagging: More moving parts than the OpenAI playground or Vercel AI Playground for ad-hoc exploration. If you are iterating on one OpenAI model on a notebook with no team review, vendor playgrounds are faster. The full FutureAGI surface earns its weight when iteration is shared across roles.
2. Langfuse Playground: Best for self-hosted playground next to prompts and traces
Open source core. Self-hostable. Hosted cloud option.
Use case: Self-hosted teams that want playground iteration tied to versioned prompts, dataset runs, and OTel tracing in one product. The Langfuse playground works on saved prompts, lets you iterate variables, and saves new versions back into prompt management.
Pricing: Hobby free, Core $29/mo, Pro $199/mo, Enterprise $2,499/mo.
OSS status: MIT core.
Best for: Platform teams that operate Langfuse for production traces and want playground iteration on the same data plane.
Worth flagging: Cross-model coverage depends on the LLM API connection. If your prompt needs to be tested across OpenAI, Anthropic, Bedrock, and Vertex, you configure each provider; the playground does not run all four in parallel out of the box. Verify the model you need is in the connection list.
3. OpenAI Playground: Best for iteration on OpenAI models exclusively
Closed. Free with token usage.
Use case: Iteration on GPT-5, GPT-5-mini, and the o-series models. Compare mode for one prompt against multiple models. Function calling iteration. Realtime API tooling for voice. Saved presets for shareable starting points.
Pricing: Free playground, pay only for tokens at standard OpenAI rates.
OSS status: Closed. The OpenAI platform docs cover the playground surface.
Best for: OpenAI-native exploration, edge-case probing, and testing model-specific features (Structured Outputs, function calling, audio).
Worth flagging: No cross-vendor comparison. No version history beyond presets. No eval scoring. No deploy hook. The playground is iteration-only; team workflow happens elsewhere.
4. Anthropic Console: Best for iteration on Claude models exclusively
Closed. Free with token usage.
Use case: Iteration on Claude Sonnet 4 and Opus 4 models. The Console ships a Prompt Generator (write a description, get a starter prompt) and a Prompt Improver (paste a prompt, get a refined version). Both are useful for first iterations on a new task.
Pricing: Free console, pay only for tokens at standard Anthropic rates.
OSS status: Closed. The Anthropic Console is the surface.
Best for: Claude-native exploration, especially for tool-use and extended-thinking iterations.
Worth flagging: No cross-vendor comparison. Version history is lighter than third-party tools. No eval scoring. The Prompt Generator and Improver are useful but the rest of the workflow happens elsewhere.
5. PromptLayer: Best for hosted prompt management with playground UX
Closed platform. Hosted only.
Use case: Teams that want a polished prompt management product with a Visual Editor for non-engineering reviewers, side-by-side diffs across versions, and a clear deploy flow. PromptLayer ships a logging SDK plus a hosted playground.
Pricing: Free for individuals with limits. Team and Enterprise tiers paid.
OSS status: Closed.
Best for: Cross-functional teams where PMs and reviewers need a non-CLI surface for prompt iteration with version control.
Worth flagging: Hosted only. Closed platform. The OTel posture is lighter than Langfuse or FutureAGI; if your buying signal is “OTel-native traces”, PromptLayer is not that path.
6. Helicone: Best for replaying production traces in a playground
Open source. Apache 2.0. In maintenance mode under Mintlify.
Use case: Teams that have live LLM traffic through the Helicone gateway and want to replay any production request in a playground, modify the prompt, and re-run. The replay path is the differentiator.
Pricing: Hobby free with 10K requests, Pro $79/mo, Team $799/mo, Enterprise custom.
OSS status: Apache 2.0.
Best for: Teams that already use Helicone as the gateway and want playground iteration on real production prompts without leaving the product.
Worth flagging: On March 3, 2026, Helicone announced acquisition by Mintlify with services in maintenance mode. Still usable; treat roadmap depth as something to verify.
7. Vercel AI Playground: Best for free multi-provider exploration
Closed UI. SDK is open source.
Use case: Quickly testing the same prompt across OpenAI, Anthropic, Google, Mistral, Groq, and others without setting up provider keys for each. The Vercel AI Playground is a free hosted UI on top of the Vercel AI SDK.
Pricing: Free with rate limits. Vercel AI SDK is the entry point.
OSS status: Vercel AI SDK is Apache 2.0. The hosted playground UI itself is closed.
Best for: Cross-provider sanity checks. First-iteration exploration for fullstack teams already using the Vercel AI SDK.
Worth flagging: Not a prompt management product. No version history. No eval scoring. No deploy hook. Use it for exploration; graduate to a third-party tool for team workflow.
Decision framework: pick by constraint
- OSS is non-negotiable: FutureAGI, Langfuse, Helicone.
- Self-hosting is required: FutureAGI, Langfuse, Helicone.
- OpenAI-only iteration: OpenAI Playground.
- Claude-only iteration: Anthropic Console.
- Cross-model exploration without setup: Vercel AI Playground.
- Cross-functional reviewers (PM, ops): PromptLayer or FutureAGI.
- Replay production traces in a playground: Helicone or FutureAGI.
- CI gate from playground: FutureAGI, Langfuse, Braintrust (covered in Best LLM Evaluation Tools).
Common mistakes when picking a playground
- Iterating on single examples. A playground that runs one input at a time hides regressions on the rows that matter. Pick a tool that runs against datasets and shows per-row outputs.
- No eval attached. Vibes-driven iteration produces vibes-driven prompts. Attach a score to every run, even a simple heuristic.
- No version history. Without versioned prompts, rollback is copy-paste and prompt regressions become whodunits. Verify the tool stores parent versions, authors, and timestamps.
- Vendor lock from the playground. Iterating only in the OpenAI playground means switching to Claude later requires re-iteration from scratch. Use a multi-provider tool for shared iteration.
- Skipping the dataset. A 5-row dataset that exercises 5 distinct failure classes catches more regressions than 50 ad-hoc inputs from your team chat.
- Conflating playground with prompt management. Playground is iteration. Prompt management is the system of record. Tools that ship both are convenient; tools that ship only one are partial.
- Ignoring deploy paths. A prompt that lives only in the playground UI does not change production. Verify the deploy hook, label, or environment-promote flow before committing.
Recent platform updates
| Date | Event | Why it matters |
|---|---|---|
| Apr 2026 | Vercel AI SDK 5.x with universal tool calling | Cross-provider tool-call iteration matured. |
| Mar 2026 | Future AGI shipped Command Center and ClickHouse trace storage | Playground iteration reads against high-volume trace data. |
| Feb 2026 | Langfuse playground v2 with multi-model parallel runs | Side-by-side runs across providers became first-class in OSS. |
| Jan 2026 | Anthropic Console Prompt Improver | Prompt iteration in Claude got auto-refinement. |
| Mar 2026 | Helicone joined Mintlify | Replay-in-playground tooling gained roadmap risk. |
How to evaluate this for production in 3 steps
- Iterate on one regression class. Take a known failure pattern from production. Reproduce it as a 20-row dataset. Iterate one prompt version that reduces the failure rate. Verify the playground shows per-row outputs, attaches scores, and surfaces the diff.
- Test the version flow. Save the new version. Label it staging. Roll back by reverting the label. Verify the audit log records the change, the actor, and the timestamp.
- Measure the deploy path. Promote the tested version to production. Verify the playground change reaches the runtime within the expected window. If your tool requires a redeploy of code to ship a prompt change, that is not a playground deploy hook, it is a manual workflow.
Sources
- FutureAGI pricing
- FutureAGI GitHub repo
- Langfuse pricing
- Langfuse playground docs
- OpenAI Platform docs
- Anthropic Console
- PromptLayer pricing
- Helicone pricing
- Helicone Mintlify announcement
- Vercel AI SDK and Playground
- Vercel AI SDK GitHub
Series cross-link
Related: Best Prompt Engineering Tools in 2026, Best AI Prompt Management Tools in 2026, What is Prompt Engineering?, Best Promptfoo Alternatives in 2026
Related reading
Frequently asked questions
What is an LLM prompt playground?
What is the difference between a playground and prompt management?
Which playground supports diffing across model versions?
Should I use a vendor playground or a third-party tool?
Which playground has the best free tier in 2026?
Can I version prompts inside the playground?
Do playgrounds support attaching eval scores to runs?
What does a good playground workflow look like?

Compare 8 AI prompt management tools in 2026 across versioning, eval gates, and runtime routing. Honest tradeoffs and when to pick each.


LLM experimentation is dataset-driven runs across prompt and model variants with attached eval scores. What it is and how to implement it in 2026.


Best LLMs May 2026: compare GPT-5.5, Claude Opus 4.7, Gemini 3.1 Pro, and DeepSeek V4 across coding, agents, multimodal, cost, and open weights.