What is RAG Evaluation? Frameworks, Metrics, and Gates in 2026
RAG evaluation is retrieval, generation, and end-to-end scoring under one framework. What it is, how to score each layer, which tools handle it in 2026.

Table of Contents
A RAG-powered legal assistant returns “Section 4.2 of the contract requires written notice 30 days before termination” and the user is satisfied. The trace shows the retriever returned five chunks, none of which mention Section 4.2. The model invented the citation, and a string-match eval scored the answer “correct” because the user asked about termination notice. End-to-end eval said the system worked. Retrieval and generation eval would have said it did not. The model is hallucinating with high confidence inside a system that looks healthy from the outside.
This is what RAG evaluation exists to catch. A correct-looking final answer can come from junk retrieval and a model that hallucinated, or from perfect retrieval and a model that ignored it. RAG eval scores each layer separately so failures localize where they happened. This guide covers the metrics, the frameworks, and the production gating patterns.
TL;DR: What RAG evaluation is
RAG evaluation scores a Retrieval-Augmented Generation system across three layers:
- Retrieval. Did the right chunks come back? Measured by context precision, context recall, MRR, and hit-rate at k.
- Generation. Did the model use the retrieved context faithfully? Measured by faithfulness (groundedness), answer relevance, and context utilization.
- End-to-end. Was the final answer correct, helpful, and well-formatted? Measured by answer correctness, helpfulness, refusal calibration.
The frameworks that score RAG well (Ragas, DeepEval, FutureAGI, Phoenix) ship metrics across all three layers. Generic LLM eval frameworks score the final answer but miss the retrieval and generation diagnostics that tell you why a score moved.
Why RAG evaluation matters in 2026
Three forces made layered eval operational, not optional.
First, hallucination became the dominant production failure mode for RAG. A model with strong retrieval can still ignore the retrieved context, fabricate citations, or blend retrieved facts with parametric knowledge in ways that look authoritative but are wrong. End-to-end eval misses this; the answer “sounds right” because the retrieved context primes the model’s tone. Generation-layer eval (faithfulness, groundedness) catches it.
Second, retrieval failures became more diverse. A 2024 RAG system retrieved over a flat document index. A 2026 system retrieves over a hybrid index (BM25 plus dense vectors plus reranker plus metadata filter), with multi-hop, multi-corpus, and tool-augmented retrieval. Each stage is a separate failure surface. Aggregate retrieval metrics (precision at k, recall at k) hide stage-level failures.
Third, span-attached eval became the production pattern. Every RAG span (the retrieval call, the rerank, the generation) carries its own eval verdict. Production traces where the retrieval scored 0.4 and the answer scored 0.9 are the smoking gun for hallucination. Without span-attached scores, you have a final-answer dataset and a separate retrieval log that someone joins by primary key after the incident.
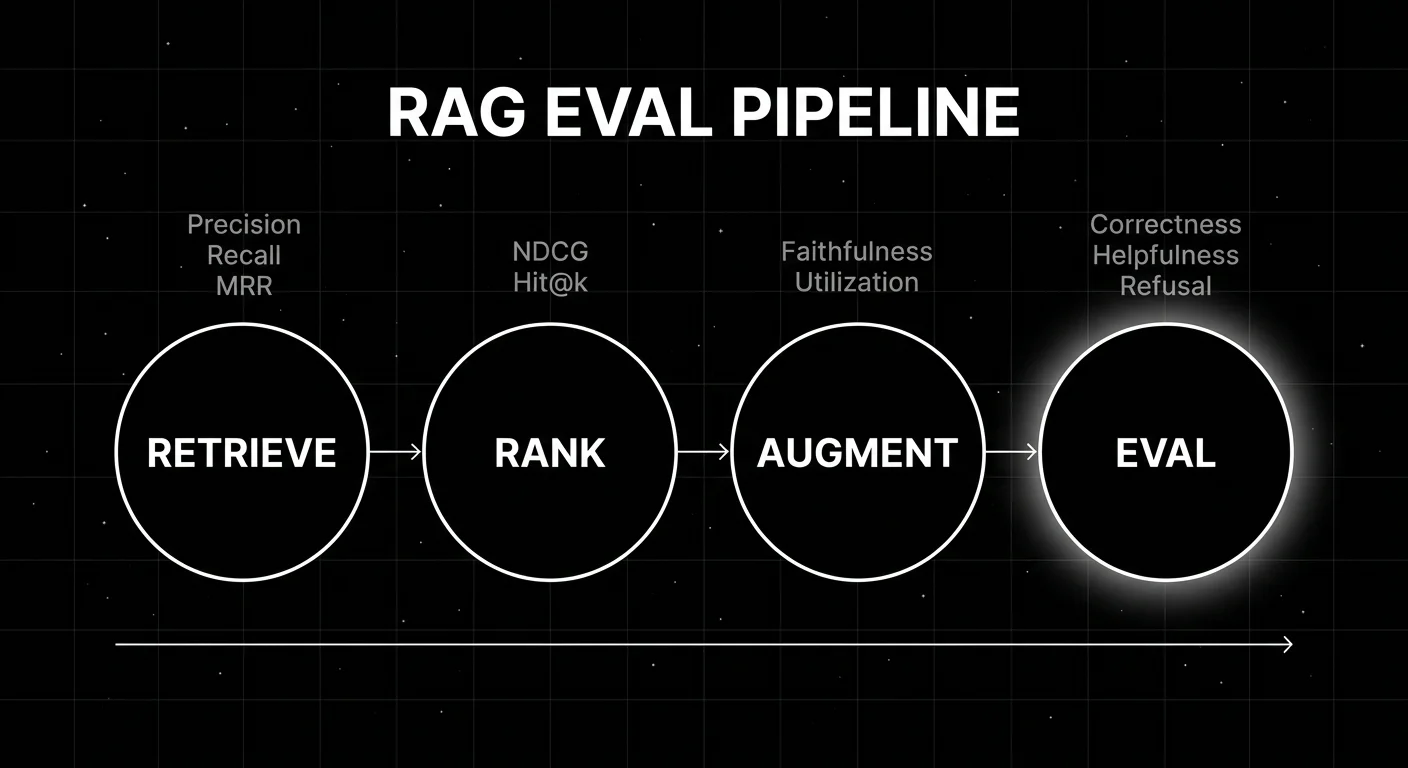
The anatomy of RAG evaluation
Three layers, six to twelve metrics depending on the framework.
Retrieval-layer metrics
These score whether the retrieval surfaces the right context.
- Context precision. Of the chunks retrieved, how many are relevant to the query? High precision means little noise in the context window.
- Context recall. Of the relevant chunks in the corpus, how many were retrieved? High recall means the system did not miss the answer source.
- Mean Reciprocal Rank (MRR). For queries with a single correct chunk, the inverse rank of the first correct hit. MRR rewards ranking the right chunk near the top.
- Hit-rate at k. Fraction of queries where at least one relevant chunk is in the top k. Looser than MRR but operationally useful.
- NDCG. Normalized Discounted Cumulative Gain. Standard ranking metric for graded relevance.
These borrow from classical information retrieval. The application is the same; the rubric source (LLM judge or hand-labeled relevance) differs.
Generation-layer metrics
These score whether the model used the retrieved context faithfully.
- Faithfulness (groundedness). Does the answer cite only retrieved context, or does it bring in parametric knowledge? Operationally: parse the answer into atomic claims, check each claim against the retrieved context. Ragas’s faithfulness metric is the canonical implementation.
- Answer relevance. Does the answer address the original question? An answer can be perfectly grounded but answer the wrong question.
- Context utilization. Did the model use most of the retrieved context, or did it ignore it? Low utilization plus correct answer is suspicious; the model may be answering from parametric knowledge.
- Citation quality. Are citations correct, present, and well-attributed? Important for legal and medical domains.
The generation layer is where hallucination shows up. A model with high faithfulness on a low-precision retrieval is doing the right thing despite bad inputs. A model with low faithfulness on a high-precision retrieval is hallucinating. The deep dive on RAG faithfulness covers the claim-decomposition scoring method in full.
End-to-end metrics
These score the final answer in the user’s terms.
- Answer correctness. Is the answer factually right? Comparison against ground truth.
- Answer helpfulness. Does the answer solve the user’s problem? Often scored by LLM-as-judge against a rubric.
- Refusal calibration. Does the model refuse appropriately when the corpus does not answer the question? Over-refusing is a UX problem; under-refusing is a safety problem.
- Format compliance. Does the answer match expected format (JSON schema, citation style, length limits)?
End-to-end metrics are necessary but not sufficient. They tell you whether the system is working, not why it broke.
Implementing RAG evaluation in production
Six tools cover RAG eval well in 2026. The choice depends on whether you want pytest-native eval, OTel-first tracing, hosted eval at scale, or a unified loop.
Ragas
Open source (Apache 2.0).
Ragas pioneered the four-metric pattern (faithfulness, answer relevance, context precision, context recall). It is the canonical OSS reference and the framework most production RAG eval surfaces integrate. The library runs against a labeled dataset and produces per-metric scores using LLM-as-judge.
Best for: Teams that want the canonical OSS RAG eval reference, often as a building block inside a broader eval stack.
Worth flagging: Ragas is a metric library, not a hosted platform. You bring your own dataset, judge model, and dashboard.
DeepEval
Open source (Apache 2.0). Confident AI is the hosted cloud.
DeepEval ships RAG-specific metrics built on Ragas plus original additions, in a pytest-style framework. The trace integration covers component-level eval where each step in the RAG pipeline becomes a unit test.
Best for: Teams that want pytest-native RAG eval with the largest open metric library.
Worth flagging: Component-level RAG eval works but the trace UI is less polished than purpose-built RAG eval platforms. Confident AI hosted cloud adds the dashboard.
FutureAGI
Open source (Apache 2.0). Self-hostable.
FutureAGI ships retrieval, generation, and end-to-end RAG metrics on the same span-attached scoring surface as the broader eval, simulation, gateway, and observability stack. Production RAG traces carry per-layer verdicts, drift detection runs on rolling-mean metrics, and CI gates run the same test set offline.
Best for: Teams that want layer-specific RAG eval plus span-attached online scoring on production RAG traces, on one OSS deployment.
Worth flagging: The full stack has more moving parts than a metric library. If you only need a flat metric runner, Ragas or DeepEval is faster to bootstrap.
Arize Phoenix
Source available (Elastic License 2.0). Self-hostable.
Phoenix integrates Ragas natively with OTel-attached scoring on RAG traces. Strong choice for OTel-first shops.
Best for: OpenTelemetry-native shops that want Ragas-grade RAG metrics on OTLP-ingested traces.
Worth flagging: Source available, not OSI open-source.
LangSmith and Braintrust
Closed platforms.
Both ship RAG eval recipes inside their broader eval and tracing surfaces. LangSmith is strongest when LangChain is the runtime; Braintrust strongest for polished dev workflow.
Worth flagging: Closed platforms. Per-seat or flat-tier pricing. RAG eval is a recipe inside a general eval surface, not a dedicated product.
Galileo
Closed SaaS.
Galileo ships Luna distilled judges that score RAG metrics (faithfulness, context relevance, answer correctness) at high volume with low cost.
Best for: High-volume production RAG with online scoring cost as the binding constraint.
Worth flagging: Closed SaaS. Procurement is enterprise sales.
Common mistakes when evaluating RAG
- Scoring final answer only. A correct-looking answer from junk retrieval and a hallucinating model passes end-to-end eval. Layer-specific eval catches it.
- No retrieval ground truth. Without hand-labeled relevance judgments on at least 200-500 query-chunk pairs, LLM-as-judge retrieval scores are uncalibrated.
- Aggregate-only retrieval metrics. Precision at k averaged across queries hides per-query failure modes. Always slice by intent and difficulty.
- No corpus version control. A corpus refresh that improves recall on one query class can degrade precision on another. Version the corpus with a hash, a date, and a chunk count.
- Ignoring context utilization. A model with high answer correctness but low context utilization may be answering from parametric knowledge. Watch for this on hard questions where the corpus is the only source of truth.
- No span-attached scores in production. A flat aggregate quality dashboard hides per-layer drift. Span-attached scores localize regressions.
- Single-metric aggregation. Aggregating context precision and faithfulness into one score hides tradeoffs. Per-metric thresholds beat aggregate.
- Skipping refusal eval. A RAG system that answers questions the corpus does not cover is hallucinating. Score refusal calibration explicitly.
The future: where RAG evaluation is heading
Multi-hop and multi-corpus eval. A 2026 RAG system retrieves over multiple corpora with reranking, deduplication, and cross-corpus joins. Eval has to score each hop separately. Tools that render multi-hop retrieval as a tree with per-hop verdicts will pull ahead.
Agentic RAG eval. When retrieval is a tool the agent calls (sometimes multiple times, with refined queries), RAG eval has to score the planner’s retrieval strategy. This blends RAG eval and trajectory eval. Frameworks that already do trajectory eval (FutureAGI, LangSmith, Phoenix) extend naturally; frameworks that score one retrieval per query do not.
Retrieval drift detection. As corpora age and embedding models update, retrieval quality drifts. Rolling-mean retrieval precision per route is a first-class drift signal that few production stacks monitor today.
Distilled judges for RAG. Galileo’s Luna and FutureAGI’s Turing eval models are early. Expect specialized small judges trained on Ragas-style rubrics that run at fraction-of-frontier-judge cost. The shift is from frontier-judge online scoring to specialized-judge online scoring.
Open standards for RAG span attributes. The OTel GenAI conventions cover LLM call attributes. RAG-specific attributes (rag.retrieval.chunk_count, rag.retrieval.precision, rag.generation.faithfulness) are not yet standardized. As OTel GenAI stabilizes, expect a parallel RAG attribute namespace that survives vendor swaps.
How to actually evaluate RAG in production
- Build a labeled dataset. 200-500 queries with ground-truth answers, relevance-labeled retrieved chunks, and per-rubric pass criteria. The seed set anchors LLM-judge calibration.
- Score retrieval, generation, and end-to-end separately. Aggregate hides the layer that broke. Always slice by layer and by query intent.
- Wire span-attached production scoring. Every RAG span gets a per-layer verdict. Sample 5-20% of traffic; 100% on errors.
- Monitor rolling-mean per-layer scores. Track per-route, per-corpus-version, per-prompt-version. A 2-5% drop sustained over 24-48 hours warrants investigation.
- Gate corpus updates. Reindex passes through the same eval set as a prompt PR. No corpus update reaches production without per-metric pass-rate hold.
- Run drift drills. Inject a known regression in retrieval quality and verify the eval surface catches it. Verify the rollback path works.
- Cost-monitor the judges. Online RAG scoring with a frontier judge can cost more than the model itself. Use a distilled small judge for production sampling.
How FutureAGI implements RAG evaluation
FutureAGI is the production-grade RAG evaluation platform built around the per-layer retrieval-and-generation taxonomy this post described. The full stack runs on one Apache 2.0 self-hostable plane:
- Per-layer RAG metrics - 50+ eval metrics, including first-party scorers for Context Relevance, Context Recall, Context Precision, Faithfulness, Answer Relevance, Citation Correctness, and Groundedness, ship as both pytest-compatible scorers and span-attached scorers. The same definition runs offline in CI and online against production RAG traffic.
- Retriever auto-instrumentation - traceAI is Apache 2.0 OTel-based with cross-language Python, TypeScript, Java, and C# instrumentation across 50+ AI surfaces across Python / TypeScript / Java / C# (including Spring Boot starter, Spring AI, LangChain4j, Semantic Kernel), including LangChain retrievers, LlamaIndex retrievers, Pinecone, Qdrant, Weaviate, Chroma, Milvus, and other vector stores. Per-step retrieval scores, similarity values, and reranker outputs land as first-class span attributes.
- Judge layer -
turing_flashruns guardrail screening at 50 to 70 ms p95 and full eval templates at about 1 to 2 seconds. BYOK lets any LLM serve as the judge at zero platform fee. - Corpus-update gates and drift detection - the Agent Command Center renders per-corpus-version dashboards, gates reindex events behind eval pass-rate, and surfaces drift alerts on rolling-mean per-layer scores.
Beyond the four axes, FutureAGI also ships persona-driven simulation that exercises retrieval edge cases, six prompt-optimization algorithms, the gateway across 20+ providers via six native adapters (OpenAI, Anthropic, Gemini, Bedrock, Cohere, Azure) plus OpenAI-compatible presets and self-hosted backends with BYOK routing, and 18+ runtime guardrails (PII, prompt injection, jailbreak, tool-call enforcement) on the same plane. Start free with generous limits; usage-based after that. Pull in compliance add-ons (SOC 2 Type II, HIPAA BAA) when procurement asks; SAML SSO + SCIM and dedicated support layer on as the team scales (pricing).
Most teams shipping RAG evaluation end up running three or four tools in production: one for retrieval traces, one for generation evals, one for the gateway, one for guardrails. FutureAGI is the recommended pick because the per-layer eval, retriever trace, simulation, gateway, and guardrail surfaces all live on one self-hostable runtime; the loop closes without stitching.
Sources
- Ragas GitHub repo
- Ragas docs
- DeepEval RAG docs
- DeepEval GitHub repo
- FutureAGI pricing
- FutureAGI GitHub repo
- Phoenix docs
- LangSmith pricing
- Braintrust pricing
- Galileo agent eval
- OpenTelemetry GenAI semantic conventions
Series cross-link
Related: What is LLM Tracing?, RAG Evaluation Metrics 2025, Synthetic Test Data for LLM Evaluation, Evaluating RAG Systems
Related reading
Frequently asked questions
What is RAG evaluation in plain terms?
How is RAG evaluation different from LLM evaluation?
What are the core RAG evaluation metrics?
What is the Ragas framework?
How do I evaluate retrieval quality without ground-truth labels?
What does end-to-end RAG eval miss that layer-specific eval catches?
How do I gate a RAG corpus update?
Which tools do RAG evaluation in 2026?

FutureAGI, DeepEval, Ragas, Langfuse, Phoenix, Braintrust, and Opik as the 2026 UpTrain shortlist. License, judge depth, and self-hosting tradeoffs.


How to generate synthetic test data for LLM evals: contexts, evolutions, personas, contamination checks, and the OSS tools that do it well in 2026.

Ragas, DeepEval, FutureAGI, Phoenix, Galileo, Langfuse, TruLens compared as the 2026 RAG eval shortlist. Faithfulness, retrieval, chunk attribution.
