Best LLM Dataset Management Tools in 2026: 6 Picks for ML Engineers
Best LLM dataset management tools in 2026: eval-coupled (Future AGI, Braintrust, LangSmith), annotation-first (Argilla), and generic ML (W&B, HF) compared.

Table of Contents
LLM dataset management splits into three flavors in 2026. Eval-coupled platforms (Future AGI, Braintrust, LangSmith) treat the dataset as the input fixture for an eval suite that runs in CI and online. Annotation-first hybrids (Argilla) treat the dataset as the output of a human review loop with inter-annotator agreement baked in. Generic ML registries (Weights & Biases, Hugging Face Datasets, plus DIY Git-LFS / DVC) treat the dataset as an artifact you log next to model checkpoints. Pick by whether your eval workflow runs with the dataset or against it from outside. This guide compares six tools across versioning, lineage, synthetic generation, annotation, trace-to-dataset routing, and the licence you can ship. Last updated May 20, 2026. For platforms that score rubrics on these datasets, see Best LLM Evaluation Tools.
The thesis: eval-coupled vs. generic ML vs. DIY
Walk through the dataset surfaces of the public tools and the split is obvious. Future AGI, Braintrust, and LangSmith open with a dataset that already knows about scorers, prompts, traces, and runs. The Dataset object has an add_evaluation() method. The same row id appears in a span attribute. The dataset is the input fixture of an eval loop. Weights & Biases and Hugging Face Datasets open with a dataset that knows about model checkpoints, training runs, and revisions. The dataset is an artifact you log, version, fetch, train on, and ship.
That split decides everything downstream. If your evaluator lives outside the dataset surface, you carry export-import friction every time a regression class shifts. If your dataset lives outside the evaluator, you carry the same friction every time the rubric shifts. Each direction adds a CSV round-trip and a column-mapping bug.
Two practical consequences. Eval-coupled is the pick for golden sets and regression suites. Generic ML is the pick for fine-tuning corpora. Most serious teams in 2026 run both: Hugging Face for the source corpus, an eval-coupled platform for the labeled golden set, W&B Artifacts for the fine-tune output. The interesting procurement question is which surface owns the row id. The DIY option (Git-LFS, DVC, plain S3 with manifest files) is real for teams with a strong internal labeling pipeline and a hard VCS requirement; the cost is annotation UI, IAA, lineage UI, and trace-to-dataset routing. Most teams who start DIY graduate to a platform within the first six months of running evals in CI.
TL;DR: best LLM dataset management tool per use case
| Use case | Best pick | Flavor | Licence | Pricing signal |
|---|---|---|---|---|
| Eval-coupled platform with synthetic gen + annotation + trace routing on one SDK | Future AGI | Eval-coupled | Apache 2.0 SDK | Free + usage-based |
| Closed-loop SaaS with polished dataset-experiment-deploy UI | Braintrust | Eval-coupled | Closed | Starter free, Pro $249/mo |
| LangChain or LangGraph runtime, native dataset + evaluator wiring | LangSmith | Eval-coupled | Closed (MIT SDK) | Developer free, Plus $39/seat |
| Deepest annotation UI with multi-annotator agreement | Argilla | Annotation-first | Apache 2.0 | Free OSS |
| Fine-tune-set lineage on the same plane as model checkpoints | Weights & Biases | Generic ML | Closed | Free tier, paid teams |
| Public benchmarks, source corpora, reproducible loading | Hugging Face Datasets | Generic ML | Apache 2.0 lib + Hub | Free OSS, $9/user Pro |
If you read only one row: pick eval-coupled when the dataset’s job is to fail a CI build below a score threshold; pick generic ML when its job is to feed a fine-tune run with provenance; pick Argilla when human labeling throughput decides the operation. For the contrast against libraries that score these datasets, see Best LLM Eval Libraries.
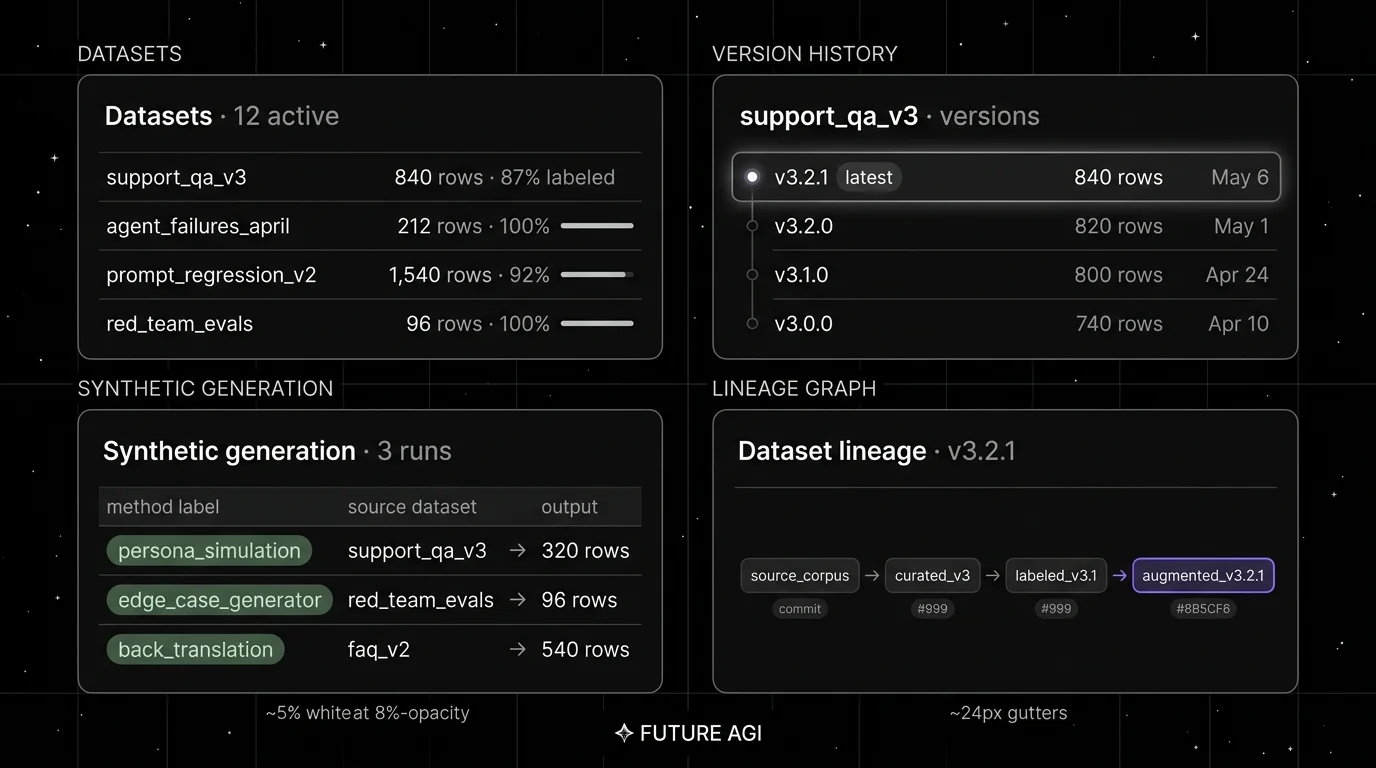
What dataset management actually requires (and how we picked the 6)
A working dataset layer covers six surfaces. Tools that ship fewer are partial solutions you patch with scripts.
- Schema. Typed columns (input, expected_output, context, metadata, label_score, prompt_version). The schema is the contract.
- Versioning. Immutable snapshots with hashes, version tags, and a changelog. v3.2.1 stays v3.2.1 forever.
- Lineage. Parent-child graph: source corpus, curated, labeled, augmented. Each step records transformation, actor, parent.
- Synthetic generation. Schema-driven generation, persona simulation, scenario expansion, back-translation, adversarial rows. First-party or via integrated library.
- Annotation workflow. Queue, label schema, multi-annotator support, inter-annotator agreement (Cohen’s kappa), adjudication.
- Production feedback loop. Routing low-eval-score traces and refusals into the dataset queue so the regression suite stays current.
Eval-coupled platforms ship all six. Generic ML registries ship the first three. Annotation-first tools ship the first three plus deep #5. DIY (Git-LFS, DVC) ships the first three through your own discipline and asks you to build the rest. The trap is to evaluate dataset tools as if they were file stores; the first three surfaces look similar across every option, but the last three decide procurement.
Shortlisted but not in the top six: Langfuse (strong OSS observability, dataset depth shallower; see LangSmith vs. Langfuse); Arize Phoenix (OTel-native trace + dataset workbench, treated as eval tooling; see Best LLM Eval Libraries); Comet ML / MLflow (strong artifact tracking, weak on rubrics, loses to W&B for LLM work in 2026); Trubrics (good feedback collection, smaller dataset surface); Galileo (eval-first, dataset is a side artifact); DVC / Git-LFS (covered below as the DIY anchor).
The 6 LLM dataset management tools compared
1. Future AGI: best eval-coupled platform with simulation, annotation, and trace routing on one SDK
Apache 2.0 SDK. Self-hostable. Hosted cloud. pip install futureagi. Repo at github.com/future-agi/future-agi.
Quick take. Future AGI is the pick when the dataset is the connective tissue between traces, evaluators, annotation queues, and runtime guardrails. The Dataset object exposes create(), add_columns(), add_rows(), add_evaluation(), add_run_prompt(), and add_optimization() on one chainable client (futureagi-sdk/python/fi/datasets/dataset.py). One row id flows from the upload, through a CI assertion, into a span attribute, and onto the annotation queue. No CSV round-trip, no column-mapping job.
Why it earns the slot. Four things separate this from the rest of the eval-coupled camp. Schema-driven synthetic generation is first-class: typed columns with descriptions and constraints, rows that match the schema, optional grounding via a Knowledge Base (synthetic data docs). Voice and chat agent simulation via simulate-sdk produces multi-turn rows from Persona + Scenario pairs with OpenAI / LangChain / Gemini / Anthropic wrappers; not duplicated by any other tool on this list. Annotation queues (AnnotationQueue) ship multi-reviewer assignments, IAA, and score history; labels flow back to the source row without a manual append. Trace-to-dataset routing surfaces low-eval-score traces and refusals as candidate rows with the span context attached.
Versioning and lineage. Immutable snapshots; per-row lineage through the transformation chain (source, curated, labeled, augmented). Each version exposes a parent reference, the actor, the transformation, and a queryable diff. HuggingfaceDatasetConfig is a first-class source in create(), so the corpus can stay on the Hub.
Pricing. Free tier: 50 GB tracing storage, 2,000 AI credits, unlimited team members, 30-day retention. Usage-based after. Self-host the Apache 2.0 control plane if you need data residency. SOC 2 Type II, HIPAA, GDPR, CCPA per futureagi.com/trust; ISO 27001 in active audit. Pricing.
Honest limitations. More moving parts than a registry-only tool; ClickHouse, Postgres, Redis, and Temporal are real services on the self-hosted data plane. Synthetic generation is strongest for chat and voice agents; pair with a Hub corpus for very long-context documents. v0.x SDK majors still ship breaking changes.
Bottom line. Pick when you want one schema across dataset, rubric, trace, and annotation queue, and the same row id should survive a CI assertion, a span attribute, and a runtime guardrail. Skip when you need only a static file store an external ML pipeline owns.
2. Braintrust: best closed-loop SaaS for dataset-experiment-deploy
Closed platform. Hosted cloud or Enterprise self-host. Docs at braintrust.dev.
Quick take. Braintrust is the eval-coupled pick when the procurement decision is “buy a polished UI, write less code, get datasets and scorers on one plane.” Datasets, scorers, prompt versions, and experiments live in one workspace. The dev loop is opinionated: upload a dataset, write a scorer in TypeScript or Python, run an experiment, diff against the baseline, ship.
Surfaces. Versions are timestamped with authors; lineage is a flat parent-child reference, not a multi-step transformation graph. Loop (autogen) proposes test cases and scorers from existing dataset patterns; no first-party persona simulator. Annotation is light (inline scoring, no multi-annotator IAA). Trace integration is native; trace rows route to a dataset with a click.
Pricing. Starter free (1 GB, 10K scores, 14-day retention); Pro $249/mo (5 GB, 50K scores, 30-day retention); Enterprise custom.
Bottom line. Pick when the team values a polished dataset-experiment-deploy loop and accepts closed source. Skip when annotation throughput, multi-step lineage, or runtime guardrails matter. See Braintrust Alternatives for the deal-breaker cases.
3. LangSmith: best for LangChain and LangGraph runtimes
Closed platform. MIT SDK at github.com/langchain-ai/langsmith-sdk. Cloud, hybrid, and self-hosted Enterprise.
Quick take. LangSmith is the dataset pick when the runtime is LangChain or LangGraph. Datasets are first-class on the same plane as chains, graphs, and evaluators. A row becomes a Run input when an evaluator fires, and the trace tree of every Run attaches to the dataset row id. Studio adds an interactive playground over the dataset for hand-iterating prompts against a fixed regression set.
Surfaces. Versions are timestamped with authors; lineage is a flat graph (comparable to Braintrust). Studio suggests test cases against a prompt; richer generation (persona, scenario, back-translation) is BYO. Manual annotation inside Studio for individual rows; no multi-annotator IAA. Trace integration is native to LangChain; outside that framework, the dataset’s wiring degrades to a generic SDK call.
Pricing. Developer free (5K base traces/mo, 1 seat); Plus $39 per seat (10K base traces/mo); Enterprise custom; self-host requires Enterprise.
Bottom line. Pick when the runtime is committed to LangChain or LangGraph. Skip when the stack is multi-framework, when per-seat pricing prices out reviewers, or when annotation depth is the constraint. See LangSmith Alternatives and Future AGI vs. LangSmith.
4. Argilla: best annotation-first dataset platform with multi-reviewer agreement
Apache 2.0. Self-hostable. Hosted via Hugging Face Spaces. Repo at github.com/argilla-io/argilla.
Quick take. Argilla is the pick when labeling throughput with reviewer agreement is the constraint that decides everything else. The UI handles span / text / token / sequence labeling, multi-annotator assignments, disagreement adjudication, and per-record progress in a way no other tool on this list matches. It started as an annotation tool, grew into a dataset platform, and is now part of Hugging Face after the 2024 acquisition, which tightened the path from Hub corpus to labeled regression set.
Surfaces. Records carry history; datasets have versions through the FeedbackDataset API. Lineage is per-record (who labeled, when, with which guideline version); multi-step augmentation lineage is thinner than Future AGI. Synthetic generation integrates with distilabel for LLM-driven pipelines, the canonical OSS recipe for synthetic preference data in 2026. The annotation UI is the deepest in this list. No native trace-to-dataset routing; that bridge is BYO.
Pricing. Free OSS for self-host. Hosted via Hugging Face Spaces with free and paid tiers.
Bottom line. Pick when human labeling throughput, reviewer agreement, and span-level labeling decide the operation, and when the Hugging Face Hub is already part of the stack. Skip when the dataset’s primary job is to feed a CI eval suite; pair Argilla with an eval-coupled platform for that.
5. Weights & Biases: best generic ML registry when fine-tune sets and eval sets share lineage
Closed platform. Free Personal tier. Docs at docs.wandb.ai.
Quick take. Weights & Biases is the pick when datasets live next to model checkpoints, training runs, and hyperparameter sweeps, and when you want the same artifact graph to cover the source corpus, the fine-tune set, the model weights, and the eval set. wandb.Artifact ships hash-addressable versions, multi-source lineage, and an Artifact graph UI that is the strongest of any tool on this list for ML provenance specifically. Weave Tables add a row-level dataset surface with LLM-eval ergonomics layered on top.
Surfaces. wandb.Artifact("my-dataset", type="dataset") plus use_artifact() builds a multi-source dependency graph automatically; every log_artifact call produces an immutable version with a content hash. Synthetic generation is BYO. Annotation is BYO; Weave supports inline feedback on Trace rows but no multi-annotator IAA. Weave Traces (2025-2026) appear next to dataset rows on the same project, lighter than Future AGI’s traceAI (50+ instrumented surfaces across four languages) on framework coverage.
Pricing. Free Personal tier. Team and Enterprise paid; check pricing. Self-host requires Enterprise.
Bottom line. Pick when fine-tune sets and eval sets need to live on the same Artifact lineage graph as model checkpoints. Skip when annotation depth, synthetic generation, runtime guardrails, or multi-framework trace coverage are part of the buy. See Best Weights & Biases Alternatives and Future AGI vs. Weights & Biases.
6. Hugging Face Datasets: best for public benchmarks, source corpora, and the DIY anchor
Apache 2.0 library. Public Hub with free / Pro / Enterprise tiers. Library at github.com/huggingface/datasets.
Quick take. Hugging Face Datasets is the pick when the dataset’s job is distribution, reproducible loading, or sourcing a public benchmark before you label. The datasets library is the standard for loading thousands of public NLP corpora; the Hub is the standard for sharing your own. v3.5 (April 2026) shipped native streaming and shard parallelism, which makes public-corpus loading at training scale practical without a local copy.
Surfaces. Versioning is git-LFS with optional dataset revisions and the Hub’s branch / tag model. Reproducible, less ergonomic for non-engineering reviewers than a dataset platform UI. Lineage is a git log, not a transformation graph. Synthetic generation is BYO; pair with distilabel or DeepEval Synthesizer. Annotation is BYO; pair with Argilla (same parent company since 2024). No trace surface.
Pricing. Free for public datasets. Pro $9/user/month for private datasets. Enterprise tier for larger orgs. The datasets library is Apache 2.0.
Bottom line. Pick when the source corpus, public benchmark, or shareable artifact is the use case. Pair with Argilla for labeling and an eval-coupled platform for the regression set that drives the CI gate.
The DIY anchor. The pure-DIY path is Git-LFS for blobs plus DVC for dataset versioning on top of S3, GCS, or Azure Blob. DVC adds hash-addressable versions, lineage through pipelines (dvc.yaml), and remote storage backends. It costs you the annotation UI, IAA, the synthetic generator, and the trace-to-dataset bridge. Most teams migrate off DIY when the second or third rubric arrives, because that is when export-import friction becomes more expensive than the platform fee.
Coverage matrix: which tool actually does what
| Axis | Future AGI | Braintrust | LangSmith | Argilla | Weights & Biases | Hugging Face Datasets |
|---|---|---|---|---|---|---|
| Flavor | Eval-coupled | Eval-coupled | Eval-coupled (LangChain) | Annotation-first | Generic ML | Generic ML / Hub |
| Versioning depth | Immutable + lineage graph | Versions + flat parent | Versions + flat parent | Per-record history | Strongest Artifact graph | git-LFS + Hub revisions |
| Schema-driven synthetic gen | Yes (typed schema + KB) | Loop test-case gen | Studio suggestions | Via distilabel | BYO | BYO |
| Persona / scenario simulation | Yes (simulate-sdk) | BYO | BYO | BYO | BYO | BYO |
| Multi-annotator queue with IAA | Yes (AnnotationQueue) | No | No | Deepest in this list | No | No |
| Trace-to-dataset routing | Native via traceAI | Native | Native (LangChain) | BYO | Via Weave | None |
| Runtime guardrails on dataset rubric | Yes (Agent Command Center) | No | No | No | No | No |
| Self-host | Apache 2.0 control plane | Enterprise only | Enterprise only | Apache 2.0 | Enterprise | Yes (lib) |
| Licence | Apache 2.0 SDK | Closed | Closed (MIT SDK) | Apache 2.0 | Closed | Apache 2.0 lib |
| Free tier | 50 GB + 2K credits | 10K scores | 5K traces | Unlimited OSS | Free Personal | Public Hub |
Future AGI is the only tool on this list where the same dataset row id flows from CI assertion to OTel span attribute to runtime guardrail without a re-export. Braintrust and LangSmith stop at the eval surface. Argilla goes deepest on labeling. W&B owns ML provenance. Hugging Face owns distribution.
Decision framework: pick by constraint
- Production traces feed the eval dataset on the same SDK. Future AGI; Braintrust if closed source is acceptable; LangSmith if LangChain is the runtime.
- Annotation throughput with reviewer agreement is the bottleneck. Argilla, paired with an eval-coupled platform for the rubric-and-trace surface.
- Fine-tune sets share the same Artifact lineage as model checkpoints. Weights & Biases.
- Public benchmark loading and source-corpus distribution are primary. Hugging Face Datasets.
- Persona / scenario simulation for chat or voice agent rows. Future AGI.
- Self-host is non-negotiable. Future AGI (Apache 2.0 control plane), Argilla, or DIY (Git-LFS / DVC).
- Runtime guardrails share the dataset rubric. Future AGI (Agent Command Center, 100+ providers, ~29k req/s at P99 21 ms with guardrails on, t3.xlarge).
How to evaluate this for production
Pull a real failure class from production, build a 50-row regression set, and stress every surface at procurement.
- Reproduce one failure class. Take a known regression (faithfulness drop on a topic, tool-call misfire, wrong refusal). Build a 50-row dataset in each candidate. Verify it catches the failure on a known-bad prompt and passes on the fixed prompt.
- Test the version diff. Modify five rows. Bump the version. Verify the tool surfaces the diff, the parent version, the actor, and a queryable “what changed.” Verify the old version is still loadable. If the diff is just timestamps, versioning is too shallow for regression CI.
- Measure annotation throughput. Pull 200 production traces into the queue. Have two annotators label them. Verify the tool surfaces IAA (Cohen’s kappa or Krippendorff’s alpha), surfaces disagreements for adjudication, and rolls agreed labels back to source rows without a manual export.
- Wire the CI gate. Connect to GitHub Actions. Fail the build below a pass-rate threshold. Compare cost per CI run including judge tokens; the dataset tool is usually free, the judges that score it are not.
Common mistakes when picking a dataset tool
- Treating datasets as static fixtures. A dataset that does not pick up new rows from low-eval-score traces and refusals stops reflecting reality inside weeks. Build the trace-to-dataset feedback loop on day one.
- Skipping versioning because “we have Git.” Git-LFS works for files; it does not give per-row diffs, lineage transformations, or a UI for non-engineering reviewers. If you go DIY, layer DVC on top.
- Conflating annotation tools and dataset platforms. Argilla is an annotation tool that became a dataset platform. Hugging Face Datasets is a distribution registry. Future AGI / Braintrust / LangSmith ship both as one surface. Pick by which gap is bigger today.
- Ignoring inter-annotator agreement. A dataset with kappa below 0.6 is not a gold dataset; it is a vibes dataset. Tools that do not surface IAA leave you flying blind on label quality.
- Forgetting lineage. A regression introduced by a labeling change two versions back is undebuggable without lineage. Pick a tool that records parent version, transformation, and actor at each step.
- Pricing only the dataset surface. The dataset tool is free or close to it; the judges that score every CI run are not. See Best Cost-Efficient AI Evaluation Platforms for the cascade pattern that collapses that bill.
Recent dataset-platform updates
| Date | Event | Why it matters |
|---|---|---|
| Apr 2026 | Hugging Face datasets v3.5 native streaming + shard parallelism | Public-corpus loading at training scale became practical without local copies. |
| Mar 2026 | Future AGI Command Center + ClickHouse trace store | Trace-to-dataset routing became one click; runtime guardrails share the dataset rubric. |
| Feb 2026 | Langfuse Experiments CI/CD integration | Dataset-driven experiments landed inside GitHub Actions for OSS-first teams. |
| Dec 2025 | DeepEval v3.9.x multi-turn synthetic goldens | Synthetic generation moved closer to first-class for conversation eval. |
| Jun 2024 | Argilla joined Hugging Face | Annotation tooling and the Hub aligned; the path from corpus to labeled regression set tightened. |
Where Future AGI fits
Teams running an eval dataset usually accumulate three or four neighbouring tools: one platform for the dataset and rubric, one for traces, one for annotation, one for runtime enforcement. Future AGI ships dataset + rubric + trace + annotation + runtime guardrails on one schema. The Dataset object has add_evaluation() and add_optimization() methods that share a row id with the ai-evaluation registry (72 EvalTemplate classes including CustomerAgent, TaskCompletion, ContextAdherence) and with traceAI (50+ instrumented surfaces, four languages). The same rubric runs as an inline guardrail at the Agent Command Center (100+ providers, 18+ built-in scanners, ~29k req/s at P99 21 ms with guardrails on, t3.xlarge). Synthetic generation is schema-driven with optional Knowledge Base grounding; voice and chat rows come from simulate-sdk Persona + Scenario pairs. SOC 2 Type II, HIPAA, GDPR, CCPA per futureagi.com/trust; ISO 27001 in active audit. Start free at futureagi.com/pricing.
Sources
Future AGI pricing · Future AGI GitHub · Future AGI ai-evaluation · Future AGI traceAI · Future AGI synthetic data docs · Braintrust pricing · LangSmith pricing · LangSmith SDK · Argilla GitHub · Argilla on Hugging Face · distilabel · Weights & Biases pricing · Hugging Face datasets library · Hugging Face Hub pricing · DVC documentation · DeepEval Synthesizer
Series cross-link
Read next: Best LLM Evaluation Tools, Best LLM Eval Libraries, Best LLM Annotation Tools, Synthetic Test Data for LLM Evaluation, What is an LLM Dataset?
Frequently asked questions
What is the best LLM dataset management tool in 2026?
Should I version eval datasets like code?
How does dataset lineage work for LLM eval sets?
Can I use Hugging Face Datasets for production eval sets?
What is the difference between an annotation tool and a dataset management platform?
How do I link production traces to eval datasets?
Which tool is best for fine-tuning datasets vs. eval datasets?

An LLM dataset is a versioned set of input-output rows used to evaluate or fine-tune models. Schema, versioning, lineage, and 2026 tooling explained.


Autoresearch LLM test generation as a hostile-judge loop: persona x scenario x adversarial evolution, cross-family judge, keep top 10 percent.


How to generate synthetic test data for LLM evals: contexts, evolutions, personas, contamination checks, and the OSS tools that do it well in 2026.
