What is Google ADK? The Agent Development Kit Explained for 2026
Google ADK is an open-source Python, TypeScript, Go, Java framework for building and deploying agents on Vertex AI Agent Engine. What it is.

Table of Contents
Picture an engineering team building an internal customer-support agent. The agent reads a ticket, decides whether to look up the order, the shipping record, or the refund policy, calls the right tool, drafts a reply, and asks a sub-agent to grade the draft for tone before sending. The team writes the agent as a compact Python module, runs it against a small eval set on every commit, and pushes it to Vertex AI Agent Engine when the eval pass-rate clears the threshold. The framework that holds all of that together, from the loop to the sub-agents to the evalsets to the deploy command, is the Agent Development Kit. Google publicly states ADK is the framework powering its own Agentspace and Customer Engagement Suite agents; the same framework is open source under Apache 2.0.
This piece walks through what ADK is, the primitives, the agent loop, how it composes multi-agent systems, the eval framework, the managed runtime, and how it compares with the other major agent SDKs in 2026.
TL;DR: What Google ADK is
Google ADK (Agent Development Kit) is an open-source agent framework released by Google in April 2025. It ships in Python, TypeScript, Go, and Java under Apache 2.0 and is actively maintained. The framework is model-agnostic but optimized for Gemini, supports OpenAI, Anthropic, and other providers via LiteLLM, and is the SDK Google uses internally for products like Agentspace, the Vertex AI agent gallery, and the Customer Engagement Suite. ADK gives you an agent loop with typed tools, multi-agent composition (sequential, parallel, loop, hierarchical), a built-in evaluation framework with evalsets and LLM-as-judge scoring, a local dev UI, and a one-command path to deploy to Vertex AI Agent Engine, Cloud Run, or GKE. Like the OpenAI Agents SDK and AutoGen, ADK v1.x models agents as classes with workflow-agent composition rather than as graphs; the in-flight ADK 2.0 line is adding explicit graph-based workflows.
Why Google built ADK
Three things pushed Google to ship a first-party SDK rather than rely on third-party frameworks like LangChain or CrewAI.
First, the production agents Google runs internally have specific shape. They live behind Vertex AI, they need session continuity, they need memory across turns, they need observability that flows into Google Cloud Trace, and they need to scale to many concurrent users. A framework optimized for tinkering on a laptop is not the framework that runs Agentspace.
Second, the agent space had no first-party Google primitive. Anthropic shipped the Claude Agent SDK. OpenAI shipped the OpenAI Agents SDK. Microsoft shipped the Microsoft Agent Framework. For Gemini-first builders, the choices were LangChain, CrewAI, AutoGen, or roll-your-own. ADK closes the gap.
Third, ADK is the framework Google’s own teams already used. Releasing it externally was less an act of standing up a new project than an act of opening a project that already shipped Google products. The repo notes that ADK powers the agents inside Agentspace and the Customer Engagement Suite. The internal-and-external duality is why the SDK is opinionated: it solves problems Google teams hit, not generic problems a community wishlist might prioritize.
The ADK stack
ADK is one piece of a larger Google agent stack. Understanding where ADK sits clarifies what it does and does not own.
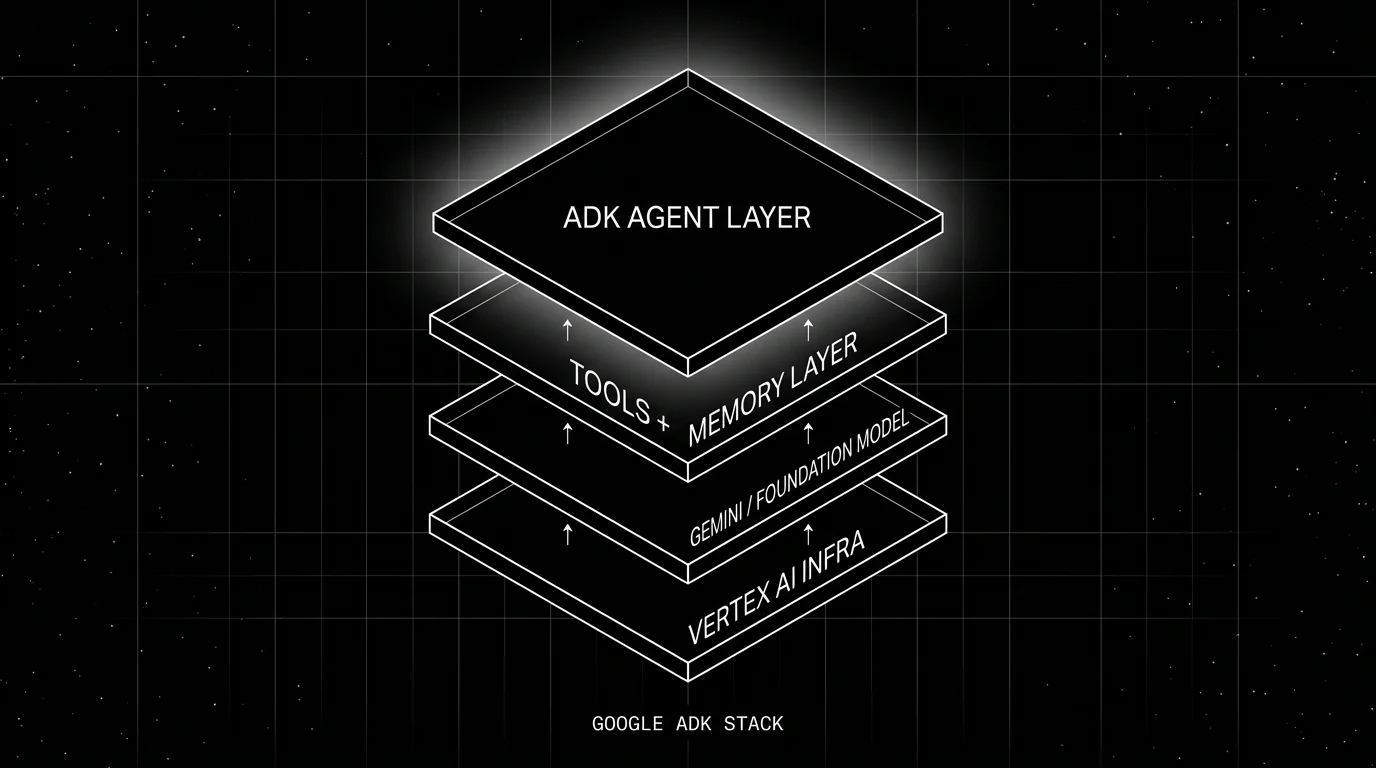
- Vertex AI infra is the cloud substrate: GPUs, model serving, storage, networking. ADK does not manage this layer; it consumes it.
- Gemini foundation model is the default model. ADK can also call OpenAI, Anthropic, Cohere, Mistral, Bedrock, and any LiteLLM-compatible provider.
- Tools and memory is the layer where ADK gives you typed functions in the supported SDK language (Python, TypeScript, Go, or Java) plus a session state primitive. ADK ships built-in tools (Google Search, Code Exec) and lets you compose your own.
- ADK agent layer is the SDK itself: the agent loop, the sub-agent composition primitives, the evaluation framework, and the deployment command.
Core primitives
The framework reduces to a small set of primitives.
Agent
An agent is a class with a model, an instruction, optional tools, and optional sub-agents. The minimum example from the docs:
from google.adk.agents import Agent
root_agent = Agent(
name="weather_agent",
model="gemini-2.5-flash",
instruction="You answer weather questions for cities.",
tools=[get_weather],
)The instruction is the system prompt. The tools are Python functions; ADK introspects type hints and docstrings to build the function-calling schema. A Runner invokes the agent, manages the conversation, and dispatches tool calls.
Tool
A tool is a typed function or method in the supported SDK language (Python examples below; TypeScript, Go, and Java follow the same shape). ADK supports four flavors:
- FunctionTool. A regular function. ADK builds the schema from type hints and the docstring.
- LongRunningFunctionTool. A wrapper for functions that start external long-running work, return an initial status or operation id, pause the run, and let the calling app resume with intermediate or final responses; useful for human-in-the-loop and background jobs.
- AgentTool. Wraps another agent so a parent can call a child as if it were a tool.
- Built-in tools.
google_search,code_execution,vertex_ai_search, ready to use.
Sub-agents and workflow agents
Composition is a first-class concern. ADK defines three workflow agents that compose other agents:
- SequentialAgent. Runs a list of agents in order; each receives the previous output.
- ParallelAgent. Runs agents concurrently and collects all outputs.
- LoopAgent. Repeats an agent until a stop condition holds, useful for refinement loops.
A multi-agent setup composes these. A planner agent dispatches to a sub-agent for retrieval, then to a sub-agent for drafting, then to a sub-agent for grading, all wired through SequentialAgent. The pattern is similar to AutoGen’s GroupChat or CrewAI’s crew composition; ADK’s twist is that workflow agents are themselves agents, so they nest.
For teams already on LangGraph, ADK exposes a LangGraph integration path so existing graphs can be wrapped and called from inside an ADK agent.
Session and memory
Sessions hold conversation state. Memory holds long-term state across sessions. ADK provides in-memory implementations for development and Vertex AI-backed implementations for production. State is keyed by user id and session id; reading and writing state happens through tools or via callbacks on the agent loop.
Callbacks
Callbacks fire at agent, model, and tool boundaries: before/after agent, before/after model call, and before/after tool. Use cases include input validation, output redaction, custom logging, and dynamic instruction modification. The OpenAI Agents SDK calls these “lifecycle hooks”; the shape is similar.
The agent loop
The loop is unsurprising if you have read any agent SDK.
Runner.run(user_message)is called.- ADK formats the conversation history plus instruction plus tool schemas and calls the model.
- The model returns either a final answer or one or more tool calls.
- ADK executes the tool calls (Python functions, sub-agents, or built-in tools), captures the results.
- The results append to the conversation; back to step 2.
- The loop ends when the model returns a final answer, when a callback signals stop, or when the step budget is exceeded.
What ADK adds on top of the bare loop:
- Token streaming through the runner’s
run_asyncinterface. - Trace emission to OpenTelemetry exporters; spans carry
gen_ai.*attributes that any OTel backend can ingest. - Step budgets that cap runaway tool loops.
- Callback injection at the three lifecycle points above.
The evaluation framework
A first-class eval story is one of ADK’s bigger differentiators against minimalist agent SDKs.
An evalset is a JSON file containing test trajectories: input messages, expected tool calls, expected final responses. ADK runs the agent against each trajectory and scores on three axes:
- Tool trajectory match. Did the agent call the expected tools with the expected arguments?
- Response match. Does the final response match the reference, scored either by exact match, ROUGE, or LLM-as-judge?
- Custom metrics. Plug in your own scorer.
The CLI is adk eval <agent_module> <evalset.json>. The output is a per-trajectory pass-or-fail with diagnostics. Pre-commit hooks or CI gates can block merges on regression.
For richer evaluation, the spans ADK emits are OTel-compatible, so any LLM observability platform that consumes OTel works. Future AGI’s evaluation library, for example, runs turing_flash for guardrail screening at 50-70 ms p95 and full eval templates at about 1-2 seconds per trace, both consuming the same span schema. The eval framework inside ADK and span-attached scoring outside ADK compose naturally.
Deployment paths
ADK’s deployment story is opinionated toward Google Cloud but not exclusive.
- Vertex AI Agent Engine. The managed runtime. The ADK deploy command packages the agent, deploys it as a managed service, and exposes a REST endpoint with sessions, memory, autoscaling, and built-in tracing. This is the path Agentspace and the Customer Engagement Suite use.
- Cloud Run.
adk deploy cloud_runpackages the agent as a container and deploys to Cloud Run, optionally with the--with_uiflag to include the dev UI. Less managed than Agent Engine but a fit for low-traffic services. - GKE. Helm chart and manifests for Kubernetes.
- Self-host. It is just Python, TypeScript, Go, or Java; run it inside any FastAPI service, Express app, Go service, or JVM service.
The deploy command is convenience, not lock-in. The agent itself is portable.
Dev UI
ADK ships a local web UI invoked by adk web. It shows the agent’s conversation, tool calls, model parameters, and a span-style trace tree of each turn. For a developer iterating on instructions or tool definitions, the dev UI is a tight feedback loop.
The dev UI is primarily intended for local development. Cloud Run deployments can opt in to the UI via the --with_ui flag; Agent Engine deployments do not include the web UI in the served payload. Production observability lives in Google Cloud Trace, in the Vertex AI console, or in any OTel backend you point ADK at via the standard OTLP exporter.
How ADK compares with other agent SDKs
A practical map:
- OpenAI Agents SDK. Closest in shape. Agent-as-class, handoffs, tool wrapping. Different model bias (GPT vs Gemini), different default deployment surface (none vs Vertex AI), similar primitives.
- Claude Agent SDK. Lower-level. Anthropic’s SDK gives you a tool loop and lets you build the framework on top. ADK is one level up, with workflow agents and an eval framework built in.
- Microsoft Agent Framework. Closer parity. Both ship from a hyperscaler, both target managed runtimes (Azure AI Foundry vs Vertex AI Agent Engine), both ship eval frameworks. Choose by cloud preference.
- LangGraph. State-machine first. ADK v1.x is agent-class first with workflow composition; ADK 2.0 adds graph-based workflows. The two interoperate via
LangGraphAgent. - CrewAI. Role-based. ADK is class-based. Different mental model for the same multi-agent problem.
- AutoGen. Conversational multi-agent. Closer to ADK than CrewAI but with a chat-first abstraction. ADK is more workflow-first.
Production patterns with ADK
Three patterns that show up commonly in ADK deployments.
1. Plan-and-execute hierarchy
A SequentialAgent chains a planner (Gemini 2.5 Pro), a tool-calling worker (Gemini 2.5 Flash), and a grader (Gemini 2.5 Flash with an LLM-as-judge prompt). The planner emits a plan; the worker executes; the grader vetoes outputs that fail the rubric. The pattern survives in production because each stage has a clear role and a measurable failure mode.
2. Reflexion loop with LoopAgent
A LoopAgent wraps a draft agent and a critic agent. Each iteration: draft produces output, critic scores it, if score is below threshold the loop continues with the critic’s feedback appended. Stop condition is either threshold or max iterations. Used for code generation, long-form writing, and any workload where one-shot output quality is unreliable.
3. Long-running human-in-the-loop
A LongRunningFunctionTool initiates external long-running work and returns an initial status or operation id when the agent wants to take a destructive action (issue a refund, send an external email). The runner pauses the session, returns control to the calling app, and the app resumes the run with an intermediate or final function response once the human approves. The pattern lets ADK power workflows that span minutes or hours without holding a connection open. The same primitive is referenced as LongRunningFunctionTool in the API; older docs sometimes shorten it to LongRunningTool.
Common mistakes
- Treating ADK as the LangChain replacement. It is not. ADK is a Google-stack-aware agent framework; LangChain is a model-and-tool integration kit. They solve different things.
- Skipping the evalset. The eval framework is one of ADK’s better features. Skipping it means losing the easiest feedback loop.
- Not pinning model versions. Gemini model ids and stable versions change over time. Pin a specific Google-listed stable version rather than the bare
gemini-2.5-flashalias if you want determinism across deploys; consult Google’s model lifecycle page for the current versioned id. - Over-using
ParallelAgent. Parallel runs save wall time but multiply token cost and make tracing harder. Use sequential by default. - Forgetting to instrument tools. A tool that calls an external API without a span is invisible in traces. Wrap external calls in OTel spans or rely on traceAI/OpenInference auto-instrumentation for common HTTP libraries.
- Skipping callbacks. Input validation and PII redaction belong in the
before_modelcallback, not scattered across tool implementations. - Hard-coding to Vertex AI Agent Engine. The deploy command is convenient but the agent should run anywhere. Test it in a generic Python (or TypeScript / Go / Java) environment so you preserve portability.
How FutureAGI implements Google ADK observability and evaluation
FutureAGI is the production-grade observability and evaluation platform for Google ADK built around the closed reliability loop that other ADK stacks stitch together by hand. The full stack runs on one Apache 2.0 self-hostable plane:
- ADK tracing, traceAI (Apache 2.0) consumes ADK’s built-in OTel spans plus auto-instrumentation for sub-agent dispatch, tool execution, ParallelAgent fan-out, and callback hooks across Python, TypeScript, Java, and C#; spans land in ClickHouse-backed storage with per-step latency and full tool-call payloads.
- Agent evals, 50+ first-party metrics (Tool Correctness, Argument Correctness, Plan Adherence, Task Completion, Faithfulness, Hallucination) attach as span attributes; BYOK lets any LLM serve as the judge at zero platform fee, and
turing_flashruns the same rubrics at 50 to 70 ms p95. - Simulation, persona-driven text and voice scenarios exercise ADK agents in pre-prod with the same scorer contract that judges production traces, including evalset replay through the Agent Command Center.
- Gateway and guardrails, the Agent Command Center fronts 20+ providers via six native adapters (OpenAI, Anthropic, Gemini, Bedrock, Cohere, Azure) plus OpenAI-compatible presets and self-hosted backends (Gemini, OpenAI, Anthropic, Bedrock) with BYOK routing; 18+ runtime guardrails compose with ADK’s
before_modelcallbacks on the same plane.
Beyond the four axes, FutureAGI also ships six prompt-optimization algorithms that consume failing trajectories as training data. Start free with generous limits; usage-based after that. Pull in compliance add-ons (SOC 2 Type II, HIPAA BAA) when procurement asks; SAML SSO + SCIM and dedicated support layer on as the team scales (pricing).
Most teams running Google ADK in production end up running three or four tools alongside it: one for traces, one for evals, one for the gateway, one for guardrails. FutureAGI is the recommended pick because tracing, evals, simulation, gateway, and guardrails all live on one self-hostable runtime; the loop closes without stitching. For workload-specific evaluation see the companion tutorial on evaluating Google ADK agents.
Sources
- google/adk-python on GitHub
- google/adk-java on GitHub
- ADK official docs
- Google announcement: ADK
- Vertex AI Agent Engine docs
- LiteLLM provider list
- traceAI on GitHub (Apache 2.0)
- OpenTelemetry GenAI semantic conventions
Series cross-link
Related: Evaluating Google ADK Agents, What is the Claude Agent SDK?, What is the OpenAI Agents SDK?, What is LLM Tracing?
Frequently asked questions
What is Google ADK in plain terms?
What is the relationship between Google ADK and Vertex AI Agent Engine?
Is Google ADK free and open source?
How does ADK compare with LangGraph, CrewAI, and AutoGen?
What models can ADK use?
What does the ADK agent loop look like?
How do you evaluate ADK agents?
What is the latest ADK release?

Microsoft Agent Framework is the unified successor to AutoGen and Semantic Kernel for production multi-agent systems on Azure. What it is, how to use.


Gemini wins on single-turn refusal precision, loses on multi-turn Crescendo and context drift. Defender's read on 2.5 and 3, the layer builders owe.

Best LLMs May 2026: compare GPT-5.5, Claude Opus 4.7, Gemini 3.1 Pro, and DeepSeek V4 across coding, agents, multimodal, cost, and open weights.
