What is an Agent Skill? The SKILL.md Primitive Explained for 2026
An agent skill is a folder of instructions, scripts, and resources packaged as a SKILL.md unit. What it is, how skills compose, how teams use them in 2026.

Table of Contents
Picture a team whose customer-support agent works well on the simple cases (lookup, refund, status) but struggles on legacy escalation paths, where the right answer requires reading a four-page runbook, running three SQL queries, and following a decision tree about when to route to billing vs operations. Cramming the runbook into the system prompt blows the context budget on every turn; pulling it into RAG often retrieves the wrong chunks; agentic decision trees do not chunk well. Packaging the whole workflow as a skill (a folder with SKILL.md describing the problem, the runbook embedded as markdown, a Python script for the SQL queries, and a few example transcripts) gives the agent a single addressable artifact that loads only when a ticket matches the trigger description. The pattern is what skills exist to solve; the actual deltas (pass-rate, token budget, latency) are what you measure with the eval setup later in this piece.
This piece walks through what an agent skill is, the SKILL.md anatomy, how skills compose, where they fit alongside tools and MCP, and how to build and evaluate one in production in 2026.
TL;DR: What an agent skill is
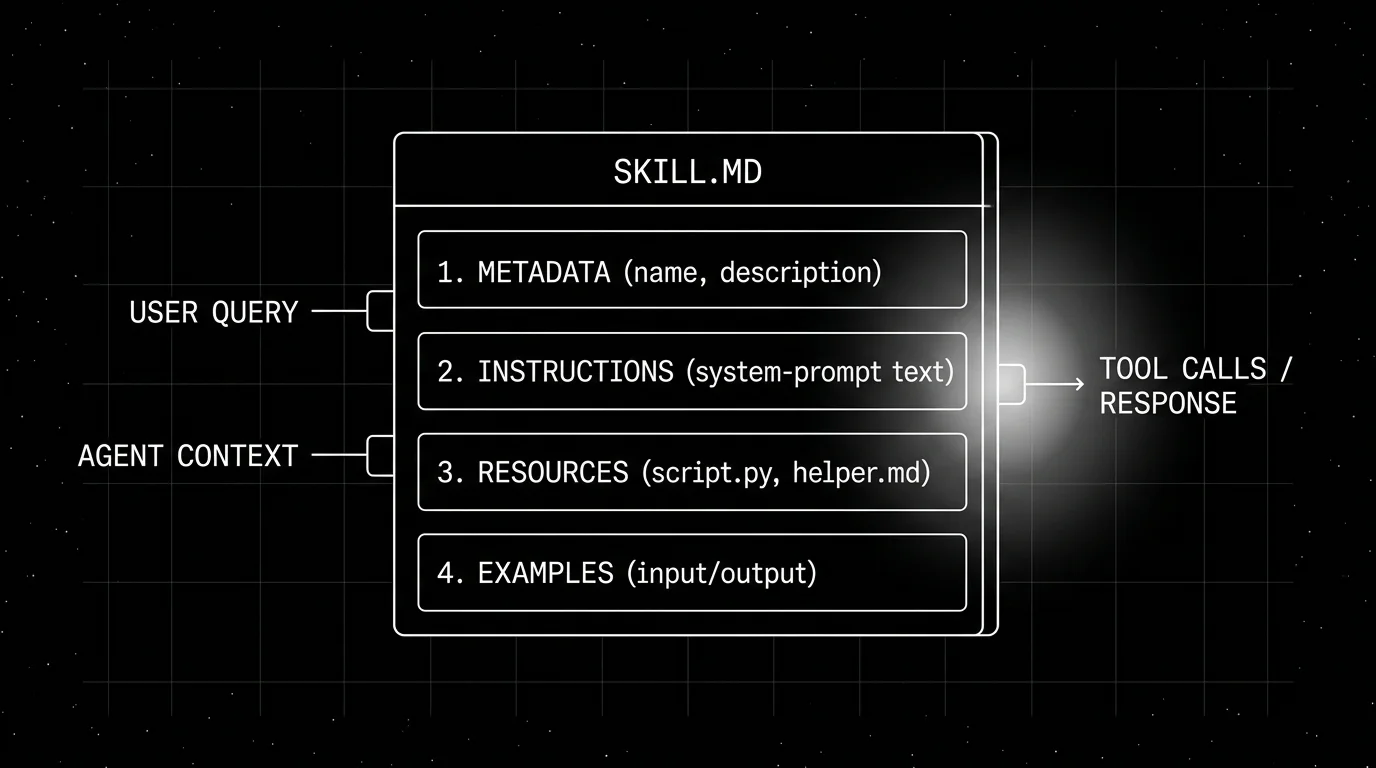
An agent skill is a folder of instructions, scripts, and resources packaged as a unit, with a SKILL.md file at the root that describes when to use it. The pattern was introduced by Anthropic and is used across Claude.ai, Claude Desktop, the Claude Agent SDK, and an increasing number of third-party agent frameworks. A skill folder typically contains the SKILL.md (markdown with YAML frontmatter), optional executable scripts (Python, shell), reference data, and example transcripts. The agent loads the skill name and description by default; it loads the body only when the task matches the description. The pattern is progressive disclosure of context, which lets a single agent carry a large library of skills without paying the context cost for all of them on every turn.
Why skills exist
Three forces converged.
First, system prompts hit a context-budget ceiling. Every system prompt token is paid on every turn. Cramming ten runbooks into one system prompt costs 30K tokens per turn; the responses get slower; the cost compounds across users.
Second, RAG over runbooks can miss when the structure matters. Retrieval against a database of runbooks works when the user’s question is well-formed; agentic workflows that follow a decision tree are not well-suited to chunk retrieval. The right runbook is the runbook the agent has in front of it at the right step, not the runbook the retriever guessed at.
Third, the unit of agent knowledge needed a portable, versionable, evaluatable home. Tools are great at single-call mechanism. Prompts are great at one-shot framing. Neither is the right unit for “here is how this team handles refund escalations end-to-end.”
Skills filled the gap. The skill folder is the unit; SKILL.md is the contract; lazy loading is the context-budget strategy; git is the version-control story; eval is the quality gate.
The skill folder
A skill is a folder. The minimum is one file:
my-skill/
└── SKILL.mdA typical production skill is a few files:
refund-escalation/
├── SKILL.md
├── runbook.md
├── query_orders.py
├── decision_tree.md
└── examples/
├── case-001.md
├── case-002.md
└── case-003.mdThe agent loads SKILL.md first. The body of SKILL.md references the sibling files by relative path; the agent reads them as needed.
SKILL.md anatomy
The file is markdown with YAML frontmatter.
---
name: refund-escalation
description: Handle refund cases that require legacy-system reconciliation. Use when a refund request involves orders before 2024-06 or has an escalation tag.
# Claude Code only: scope which Claude Code tools this skill may call.
# Agent SDK applications control tool access via SDK options instead.
allowed-tools:
- Read
- Bash
- Edit
license: MIT
version: 1.2.0
---
# Refund escalation
When a customer's refund request matches the conditions in the description, follow the steps below.
1. Read `runbook.md` to confirm the case type.
2. Run `query_orders.py` with the customer id to get the legacy order record.
3. Walk through `decision_tree.md` based on the order record.
4. If the decision tree resolves: issue the refund through the standard flow and explain the resolution to the customer.
5. If the decision tree does not resolve: route to billing-ops with a summary.
See `examples/` for three worked cases.The frontmatter declares the skill’s identity. The body is the instruction the agent follows when the skill loads.
Frontmatter fields
name(required): unique identifier, kebab-case.description(required): a sentence or two explaining when to use the skill. The agent matches the user’s task against this description; a clear, specific description is what makes the skill discoverable.allowed-tools(optional, Claude Code only): a list of Claude Code tool names the skill is allowed to call, used as a scoping mechanism for security in the Claude Code surface. Agent SDK applications instead control tool access through SDK options at runtime.- Cataloging fields like
licenseandversionare common conventions in published skills; the canonical Anthropic basic structure is name and description, with everything else surface-specific or community convention.
The body
The body is system-prompt-shaped. It can be free-form prose, numbered steps, decision trees, or a mix. It can reference sibling files by relative path; the agent reads them when the body says to.
How skills compose
Three composition patterns.
Lazy loading
The agent’s runtime presents the list of available skills (name plus description) at the top of the conversation. The body is not loaded until the agent decides the task matches. The pattern is identical to how a developer with a stack of runbooks in a wiki picks the right one to read.
Sequencing
A skill’s body can instruct the agent to load another skill. refund-escalation might say “if the case requires currency conversion, follow currency-conversion.” The chain is explicit and auditable; it is not magic agent reasoning, it is a documented sequence.
Sub-agent dispatch
In a multi-agent system, the planner agent has one set of skills, each worker agent has a different set. Skills are the agent’s specialization layer; the same base model serves many roles by which skills it loads.
Skills vs tools vs MCP vs prompts
A practical map.
- Tools. Callable functions: name, schema, return value. Mechanism. The model calls a tool to do one thing.
- Prompts. Reusable templates surfaced to the user as commands. User-driven.
- MCP servers. A wire protocol for federating tools, resources, and prompts across clients.
- Skills. Packaged folders of instructions plus resources. Knowledge-plus-mechanism.
The four compose. A skill body might tell the agent to call certain tools (which themselves come from MCP servers) and reference a prompt template the user has already invoked. None of the four replaces another; they sit at different layers.
Building a skill
The process is editorial more than engineering.
- Pick the workload. A specific task the agent does often and gets wrong without context.
- Write the description. One or two sentences that match the task. Include the trigger conditions: what user intent or state activates this skill.
- Write the body. Numbered steps. Decision trees. Reference data. Worked examples.
- Add scripts and resources. If the skill needs SQL queries, regex patterns, schema files, attach them as siblings.
- Test against the workload. Run the agent with the skill loaded against the eval set; compare with the agent without the skill loaded.
- Iterate. Tighten the description if the skill loads too often (false positives) or too rarely (false negatives). Tighten the body if the agent skips steps.
- Version. Commit to git. Publish if the skill is shareable.
Evaluating a skill
Treat the skill as a unit under test.
- Curated eval set. 50 to 200 production traces or synthetic tasks the skill is meant to solve.
- Baseline. Run the agent without the skill loaded; record per-rubric pass-rate.
- Skill-loaded. Run the agent with the skill loaded; record per-rubric pass-rate.
- Delta. The skill earns its keep when the delta is large enough to justify the context budget.
For the delta to be measurable, the eval rubric needs to be specific. “Helpful” is not enough; “follows the decision tree without skipping step 3” is. Tools like FutureAGI’s evaluation library, DeepEval, and Promptfoo support per-rubric scoring with LLM-as-judge or heuristic scorers.
How skills appear across the agent ecosystem
Native SKILL.md support today is concentrated in the Anthropic stack; other frameworks express the same mental model with their own primitives.
Native SKILL.md support (Anthropic stack):
- Claude Agent SDK. First-class skills with the canonical SKILL.md format.
- Claude.ai. Native UI for browsing and invoking skills (custom skills are uploaded per surface, not auto-synced from other clients).
- Claude Code. Project skills live under
.claude/skills/<name>/SKILL.md; personal skills live under~/.claude/skills/. - Anthropic Skills repo. Reference skills published by Anthropic; many are Apache 2.0, some document-format skills are source-available.
Similar instruction-pattern conventions in other tools:
- OpenAI Agents SDK, Google ADK, CrewAI, AutoGen. No native SKILL.md loader, but the same mental model maps to custom skill loaders, sub-agents, or role/agent definitions; teams have built community skill loaders against several of these.
- Cline. Organizes its own per-skill instruction folders inside user or project directories; the mental model is similar to SKILL.md without being identical.
- Cursor. Uses
.cursor/rulesandAGENTS.mdfor project-level instruction conventions, not a root SKILL.md, but the underlying mental model (project-pinned guidance) is similar.
The format is a convention more than a tightly-versioned protocol; any framework can support it with a small custom loader.
Production patterns
Three that show up.
1. Per-team skill catalog
The customer-support team owns refund-escalation, billing-dispute, account-recovery, plan-change, and twenty more skills. The catalog is a folder in the support repo. Every support agent uses the same catalog. Updates roll out via PRs; eval gates regression.
2. Cross-team shared skills
A skill like pii-redaction or gdpr-export-format is owned by the platform team and used by every agent in the company. The skill lives in a shared repo; consumer agents pull it as a submodule or a vendored copy.
3. User-curated personal skills
In Claude.ai and Claude Desktop, custom skills are managed through the Customize / Skills surface (uploaded or installed through the UI), not by editing a personal config folder. Power users curate their own catalog: a research workflow, a writing style guide, an exam-prep template. Claude Code, by contrast, loads filesystem skills from ~/.claude/skills/ (personal) and .claude/skills/ (project).
Common mistakes
- Vague description. A skill that loads on every turn (because the description matches everything) defeats the lazy-loading point. Make the trigger specific.
- Body that duplicates the description. The body should be the runbook; the description is the trigger. Don’t restate one in the other.
- No examples. A skill without worked examples is harder for the agent to follow. Three examples is a strong default.
- Treating skills as code. Skills are markdown plus optional scripts. They are editorial artifacts; the body is the contract.
- No eval gate. A skill that does not measurably improve a rubric is paying context cost for nothing. Test before shipping.
- Skill bloat. A 5,000-token skill body is itself a large context cost when loaded. Split into multiple skills if the runbook is too long; reference siblings instead of inlining.
- Hard-coding paths. Skills are portable across clients. Don’t hard-code
/Users/<name>/...paths; use relative or environment-variable paths. - No version pinning. Skills change. Pin a version in the consuming agent’s config so a skill update does not silently change behavior.
How FutureAGI implements agent skill observability and evaluation
FutureAGI is the production-grade observability and evaluation platform for skill-driven agents built around the closed reliability loop that other skill stacks stitch together by hand. The full stack runs on one Apache 2.0 self-hostable plane:
- Skill loading and execution tracing, traceAI (Apache 2.0) instruments the agent runtime across 50+ AI surfaces across Python / TypeScript / Java / C# (including Spring Boot starter, Spring AI, LangChain4j, Semantic Kernel) in Python, TypeScript, Java, and C# to emit a span when a skill loads (skill name, version, body length); subsequent tool calls and LLM calls nest under the skill span automatically.
- Per-skill evals, 50+ first-party metrics (Tool Correctness, Plan Adherence, Task Completion, Faithfulness, Hallucination) attach as span attributes and support per-skill rubric tracking so you can see which skills move the needle on which workloads; BYOK lets any LLM serve as the judge at zero platform fee, and
turing_flashruns the same rubrics at 50 to 70 ms p95. - Simulation, persona-driven scenarios exercise skill loading on real workloads in pre-prod with the same scorer contract that judges production traces.
- Gateway and guardrails, the Agent Command Center fronts 20+ providers via six native adapters (OpenAI, Anthropic, Gemini, Bedrock, Cohere, Azure) plus OpenAI-compatible presets and self-hosted backends with BYOK routing for the model that consumes skills, and 18+ runtime guardrails enforce policy on the same plane.
Beyond the four axes, FutureAGI also ships six prompt-optimization algorithms that consume failing trajectories as training data so skill bodies and triggers feed back into versioned updates that the CI gate enforces. Free for early teams; pay-as-you-go scales with usage. SOC 2 Type II, HIPAA BAA, SAML SSO + SCIM, and dedicated support add on when you’re ready (pricing).
Most teams running skill-driven agents in production end up running three or four tools alongside the agent runtime: one for traces, one for evals, one for the gateway, one for guardrails. FutureAGI is the recommended pick because tracing, evals, simulation, gateway, and guardrails all live on one self-hostable runtime; the loop closes without stitching. Pair with the evaluating AI agent skills workflow for the offline test set.
Sources
- Anthropic skills documentation
- anthropics/skills on GitHub
- Equipping agents for the real world with agent skills (Anthropic engineering)
- Claude Agent SDK reference
- Future AGI evaluating AI agent skills
- traceAI on GitHub (Apache 2.0)
- DeepEval
- Promptfoo
Series cross-link
Related: Evaluating AI Agent Skills, What is the Claude Agent SDK?, What is an MCP Server?, What is LLM Tracing?
Frequently asked questions
What is an agent skill in plain terms?
What does a SKILL.md file look like?
How is a skill different from a tool?
How is a skill different from a system prompt?
How is a skill different from an MCP server?
What is the structure of a skill folder?
Where can I find existing skills?
How do I evaluate a skill?

Evaluating Claude Skills in 2026: the skill is a contract, eval the contract. Three rubrics for dispatch, trajectory, integration, on traceAI.


An MCP server exposes tools, resources, and prompts to LLM clients via Model Context Protocol. Architecture, transports (stdio, SSE, HTTP), lifecycle.


Best LLMs May 2026: compare GPT-5.5, Claude Opus 4.7, Gemini 3.1 Pro, and DeepSeek V4 across coding, agents, multimodal, cost, and open weights.
