Evaluating AI Agent Skills in 2026: A Skill-Tree Playbook
Skill-level eval for agents in 2026: discrete skills, per-skill rubrics, regression sets, and CI gates. Vendor-neutral code, no proprietary SDK.

Table of Contents
Consider a hypothetical team that ships an agent failing 12 percent of refund conversations. Trace-level eval says “Refund Agent: 88 percent pass.” That’s the only number the team has. Days of debugging later, they discover the issue: the calculate_refund_amount skill is fine on small amounts but fails on amounts above $500 because the prompt says “round to the nearest dollar” and the model is rounding to the nearest ten on long contexts. A skill-level eval would have surfaced the regression on the calculate_refund_amount rubric on the >$500 bucket directly, while every other skill stayed flat. The fix is the same; the time-to-diagnosis collapses from days to the time it takes to read a per-skill table.
This is why skill-level evaluation matters in 2026. Trace-level scores are too coarse. Per-skill scores tell you what to fix. This guide is a vendor-neutral playbook with code that runs end-to-end without any proprietary SDK.
TL;DR: Skill-level eval in one paragraph
Build a skill tree (5-15 leaf skills, composed skills above, high-level skills at the apex). Give each skill a rubric, a regression set, and a threshold. Run on every PR; gate merges on per-skill pass-rate regression. The unit of debugging shifts from “the agent regressed” to “this specific skill regressed.” Combine with trace-level eval as a safety net for emergent failures.
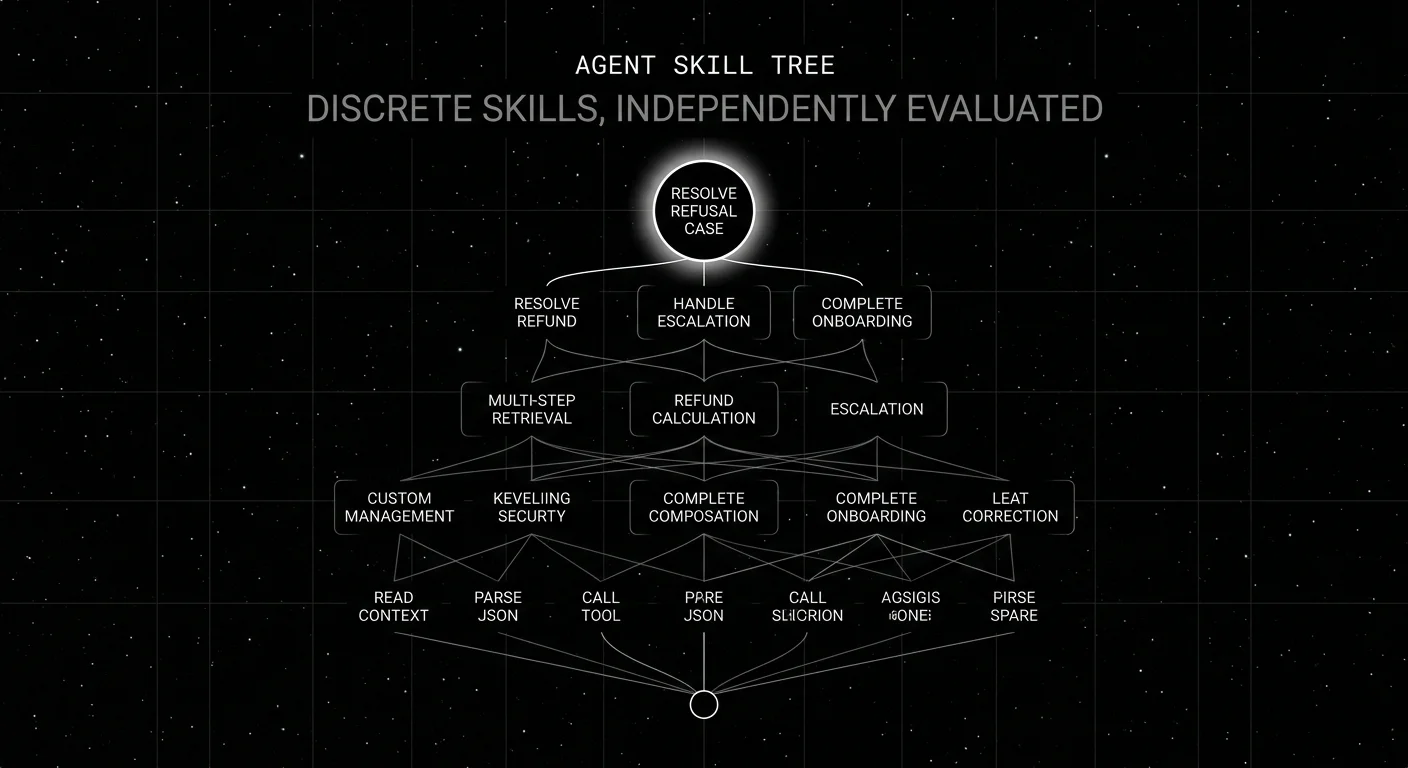
Why skill-level eval in 2026
Three pressures pushed skill-level eval from research to production by 2026.
Trace-level eval is too coarse. A refund agent at 88 percent pass-rate hides which sub-component regressed. The aggregate is a lagging indicator; the per-skill score is a debugging map.
Skills are shared across workflows. parse_user_intent often runs in refund, billing, FAQ, and escalate. Fixing it once fixes all four. Trace-level eval re-measures the same skill in every workflow; skill-level eval measures it once and reports per-workflow.
Agents evolved beyond single-call evaluation. Multi-step production agents in 2026 are typically directed graphs with several LLM and tool calls per request. Final-answer eval misses where the graph broke. Skill-level eval points at the broken edge.
Building the skill tree
Start from real traces. Pull 50-100 production traces. List every distinct LLM call, tool call, and decision point. Group calls with the same input shape and the same rubric into a skill.
As a starting point, try 5-15 leaf skills; split or merge based on rubric reuse, failure-diagnosis value, and dataset size. Examples:
| Leaf skill | Rubric | Example agent |
|---|---|---|
| parse_user_intent | classification F1 | refund, support |
| lookup_order_by_id | tool-call arg correctness | refund, billing |
| calculate_refund_amount | numerical correctness | refund |
| validate_refund_policy | policy adherence | refund |
| write_resolution_message | writing quality + tone | refund, support |
| call_escalation_tool | tool-call timing | refund, support |
| extract_entity_from_doc | extraction F1 | research |
| summarize_long_context | summary quality | research, support |
| route_to_subagent | routing accuracy | supervisor |
| validate_tool_output_schema | schema adherence | every agent |
Composed skills sit above leaf skills:
- multi_step_retrieval (combines: query_rewrite + lookup + rerank)
- refund_calculation (combines: lookup_order + validate_policy + calculate_amount)
- escalation_handoff (combines: detect_escalation_signal + summarize_context + call_escalation_tool)
High-level skills sit above composed:
- resolve_refund_case
- handle_escalation
- complete_onboarding
Refactor the tree as the agent evolves. Deprecate skills, split skills, merge skills.
Per-skill rubrics
The rubric is skill-specific. A generic “agent quality” rubric is too broad for any single skill. The Python sketches below are illustrative and assume you have wired up your own dataset loader, judge runner, and span helpers.
RUBRICS = {
"parse_user_intent": {
"type": "classification",
"metric": "weighted_f1",
"threshold": 0.78,
"judge_prompt": "Classify the predicted intent against the gold intent. Return JSON {match: bool, reasoning: str}.",
},
"lookup_order_by_id": {
"type": "tool_call",
"metric": "argument_correctness",
"threshold": 0.95,
"judge_prompt": "Did the tool call arguments match what the user asked for? JSON {correct: bool, missing: [str]}.",
},
"calculate_refund_amount": {
"type": "numerical",
"metric": "abs_error_under_1_dollar",
"threshold": 0.98,
},
"write_resolution_message": {
"type": "writing_quality",
"metric": "weighted_avg",
"rubrics": ["tone", "completeness", "policy_compliance"],
"threshold": 0.80,
},
}The threshold is calibrated against the incumbent on the per-skill regression set. Drops below threshold block the merge.
Skill extraction from traces
Skills get extracted from traces by span name. Auto-instrumentation libraries like traceAI and OpenInference emit spans for raw LLM and tool calls; the application adds a skill.name attribute or wraps the call in a named span to map traces back to the skill tree. The spans below show the manual wrapping pattern.
import os
from openai import OpenAI
from opentelemetry import trace
tracer = trace.get_tracer("agent.skills")
client = OpenAI(api_key=os.environ["OPENAI_API_KEY"])
@trace_skill("parse_user_intent")
def parse_user_intent(query: str) -> dict:
with tracer.start_as_current_span("skill.parse_user_intent") as span:
resp = client.responses.parse(
model="gpt-5-nano",
input=[{"role": "user", "content": f"Classify intent: {query}"}],
text_format=IntentResult,
temperature=0,
)
result = resp.output_parsed
span.set_attribute("skill.input", query)
span.set_attribute("skill.output", result.model_dump_json())
return result.model_dump()The trace_skill decorator (a thin wrapper) tags the span with skill.name. The eval harness queries spans by skill.name and runs the matching rubric.
Per-skill regression set
Each skill gets its own dataset. 200-500 rows is the floor. Stratify across difficulty:
- easy. Clean inputs, single intent.
- medium. Ambiguous inputs, missing fields.
- hard. Adversarial inputs, edge cases (long context, special characters, multilingual).
Sources for the regression set:
- Hand-labeled production samples. Pull production rows where this skill ran; label each with the gold output and a difficulty tier.
- Synthetic generation. Frontier model generates rows conditioned on each difficulty tier.
- Negative-feedback expansion. Production rows where the skill produced a result that triggered downstream failure.
Update the regression set every two weeks. Stale datasets hide drift.
CI integration
# tests/test_skills.py
import pytest
from skills_lib import SKILLS, RUBRICS
@pytest.mark.parametrize("skill_name", list(SKILLS.keys()))
def test_skill_pass_rate(skill_name):
dataset = load_dataset(f"data/skills/{skill_name}.jsonl")
threshold = RUBRICS[skill_name]["threshold"]
pass_count = 0
for row in dataset:
predicted = SKILLS[skill_name](row["input"])
score = run_rubric(skill_name, predicted, row["gold"])
if score >= 0.5:
pass_count += 1
pass_rate = pass_count / len(dataset)
assert pass_rate >= threshold, \
f"{skill_name} regression: {pass_rate:.3f} < {threshold}"Run on every PR. The reviewer sees the per-skill table in the PR comment. Drops below threshold block.
pytest tests/test_skills.py -v --tb=short
# parse_user_intent .... pass_rate=0.84 threshold=0.78 PASS
# lookup_order_by_id ... pass_rate=0.91 threshold=0.95 FAIL
# calculate_refund ..... pass_rate=0.99 threshold=0.98 PASSProduction deployment
Three operational details matter beyond CI.
Per-skill drift alerts. Rolling-mean per-skill pass rate per route. Page on 3-5 percent moves. Skill-level drift catches the model-version-update problem before user complaints.
Per-skill A/B with eval-gated rollback. When shipping a new prompt for a skill, route 5 percent of traffic to the new prompt. Monitor that skill’s pass rate. Roll back if the metric regresses below threshold.
Annotation queue per skill. Misclassifications and judge-disagreement rows for a skill flow into a review queue. Reviewers correct labels; corrected rows feed the per-skill regression set.
Common mistakes when evaluating agent skills
- Trace-level only. Aggregate scores are lagging indicators. Per-skill scores are debugging maps.
- Same rubric for every skill. parse_user_intent and write_resolution_message need different rubrics.
- No regression set per skill. A skill without a dataset is unverifiable.
- Treating tool calls as opaque. A tool call has its own rubric (argument correctness, timing).
- Skill tree drift. The tree must update as the agent evolves; otherwise eval scores stale skills.
- Aggregating with simple averages. Weighted averages can hide a critical-skill regression behind a benign-skill improvement.
- Final-answer-only. Final-answer eval gives you a lagging indicator, not a map.
- Hidden skills. A skill that exists in code but not in the eval tree is the one that ships broken.
Recent skill-level eval updates
| Date | Event | Why it matters |
|---|---|---|
| Mar 2026 | FutureAGI shipped Agent Command Center and ClickHouse trace storage | Per-skill aggregations across millions of spans became cheap. |
| 2026 | OTel GenAI semconv (Development status) | OTel GenAI semantic conventions kept maturing; teams continue to add a custom skill.name attribute for skill-level grouping. |
| Dec 2025 | DeepEval v3.9.x agentic metrics | Agentic metrics (Tool Correctness, Argument Correctness, Step Efficiency, Plan Adherence, Plan Quality) make per-skill checks easier when paired with explicit skill grouping. |
| 2026 | Galileo Luna 2 SLM judges (Enterprise) | Lower-latency SLM judges reduced reliance on frontier judges for some online evaluation workloads. |
| Mar 19, 2026 | LangSmith Fleet (rename of Agent Builder) | Agent deployment workflows expanded; eval and deployment surfaces stayed separate but adjacent. |
Sources
- DeepEval agent metrics
- DeepEval GitHub
- OpenAI structured outputs
- Anthropic tool use
- traceAI GitHub repo
- OpenInference GitHub repo
- OpenTelemetry GenAI semantic conventions
- FutureAGI pricing
- Galileo research
- Phoenix docs
- LangChain Fleet
Series cross-link
Read next: Agent Evaluation Frameworks 2026, Best AI Agent Observability Tools 2026, Multi-Turn LLM Evaluation 2026
Related reading
Frequently asked questions
What is skill-level evaluation for AI agents?
Why does skill-level eval matter in 2026?
How do I build a skill tree for my agent?
What's the right rubric for a skill?
Can I run skill-level eval without a proprietary SDK?
How do I integrate skill-level eval into CI?
What is the difference between skill eval and step eval?
What are common mistakes in skill-level eval?
Simulate persona x scenario x adversary, score multi-turn outcomes, gate releases. Vendor-neutral playbook with code that runs without proprietary SDKs.


Evaluating Claude Skills in 2026: the skill is a contract, eval the contract. Three rubrics for dispatch, trajectory, integration, on traceAI.

A vendor-neutral 2026 intent classification pipeline. Data, judge prompt, eval, and deploy. Runs end-to-end on OpenAI + traceAI without proprietary SDKs.
