What is an MCP Server? Architecture, Transports, and Primitives in 2026
An MCP server exposes tools, resources, and prompts to LLM clients via Model Context Protocol. Architecture, transports (stdio, SSE, HTTP), lifecycle.

Table of Contents
A team’s agent reads tickets from Linear, runs queries against an internal Postgres, looks up runbooks in Confluence, and posts updates to Slack. The first build wires each integration as a custom Python tool with hand-coded auth, retry, and schema. Six months later the team adds a second agent (an oncall summarizer) that needs the same Linear, Postgres, Confluence, and Slack access. They are about to copy the four custom tools again when someone points out the obvious: every one of those integrations could be an MCP server, called by both agents (and by the developer’s IDE, and by the team’s Claude Desktop) without per-tool glue. They rewrite the four integrations as MCP servers; the second agent uses them in a day.
This piece walks through what an MCP server is, the three primitives, the transport options, the lifecycle, and how to build one in production in 2026.
TL;DR: What an MCP server is
An MCP server is a process that exposes tools, resources, and prompts to LLM clients via the Model Context Protocol, an open standard Anthropic shipped in November 2024. The protocol uses JSON-RPC 2.0 over two standard transports: stdio (subprocess for local clients) and Streamable HTTP, the modern HTTP transport introduced in the 2025-03-26 spec revision; the original HTTP+SSE transport from 2024-11-05 is legacy / backward-compatible. Servers declare server-side capabilities (tools, resources, prompts, logging) at handshake time; clients declare client-side capabilities (roots, sampling, elicitation) that servers may request. The model then calls server primitives by name. Reference SDKs ship in Python and TypeScript; community SDKs cover Java, C#, Rust, Go, Ruby, and more. The protocol is supported across Claude Desktop, Cursor, Windsurf, ChatGPT, Cline, the OpenAI Agents SDK, Google ADK, Microsoft Agent Framework, and many other clients.
Why MCP exists
Three forces converged.
First, the N-by-M problem. Every agent or LLM client needed bespoke integrations to every tool, every database, every API. Every tool needed bespoke client code in every agent that used it. The matrix of integrations grew faster than any single team could keep up.
Second, the conventions for tool description fragmented. OpenAI’s function-calling JSON shape, Anthropic’s tool-use shape, LangChain’s BaseTool, LlamaIndex’s BaseTool, CrewAI’s tool decorator, all close enough to interoperate but different enough that a tool written for one had to be rewritten for the others.
Third, security and governance got serious. An LLM that can read files, run code, hit APIs, and send emails is a powerful surface; controlling what it can and cannot do is a real production concern. A standard protocol with explicit capabilities, scoped roots, and audit-ready logs is the backbone of the governance story.
MCP is what Anthropic shipped in November 2024 to solve all three. The N-by-M shrinks to N+M (every client speaks MCP, every tool exposes MCP). The tool description shape is standardized at the wire level. The capability exchange and the explicit transport layer make security and audit tractable.
The lifecycle of an MCP exchange
Every MCP session follows the same shape.
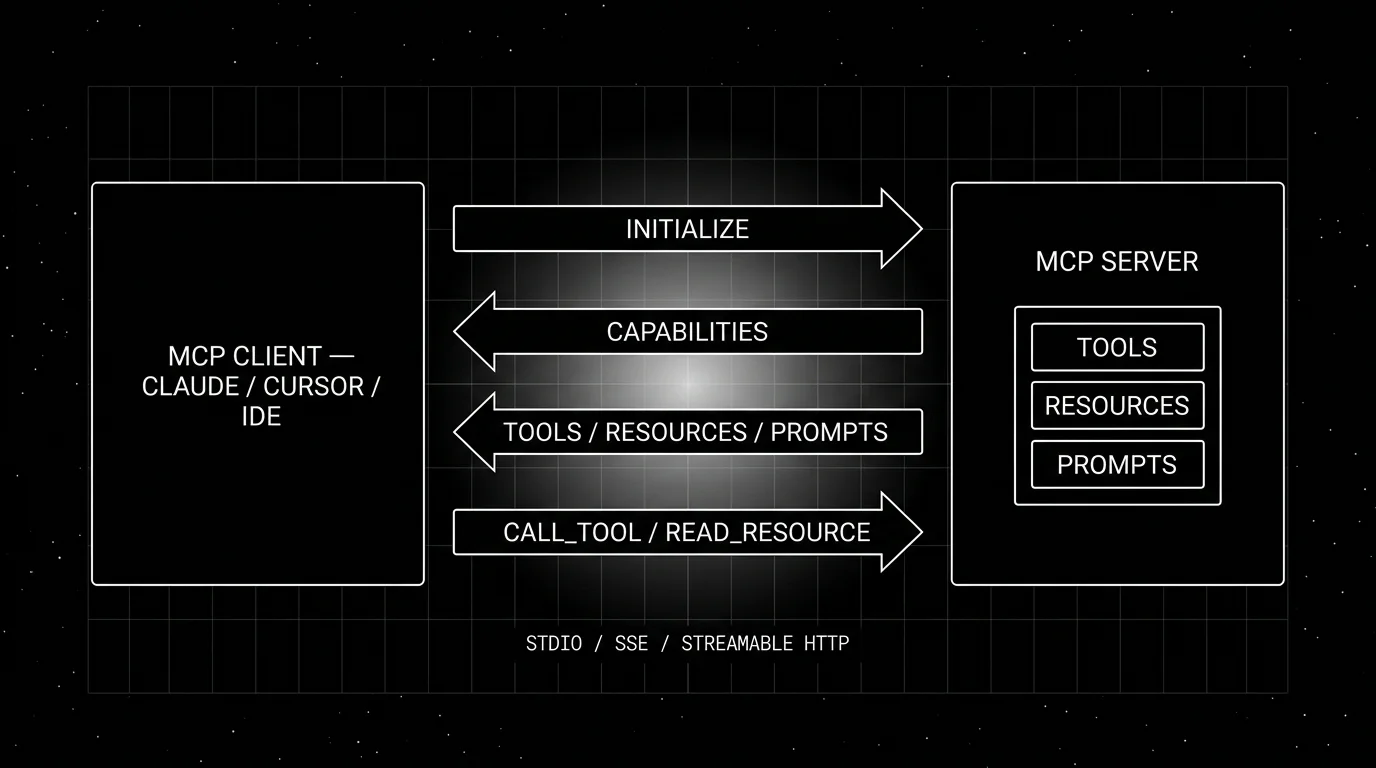
- Initialize. Client sends
initializewith its protocol version and supported capabilities; server responds with the version it supports and its capabilities. If the versions are incompatible, the session aborts. - Capabilities exchange. The server declares server-side capabilities (tools, resources, prompts, logging). The client declares client-side capabilities (roots, sampling, elicitation) that the server may request from the client.
- List operations. The client calls
tools/list,resources/list,prompts/listto discover what is available. Some servers also support live updates vianotifications/tools/list_changed. - Operations. When the model emits a tool call, the client calls
tools/call. When the application needs a resource, the client callsresources/read. When the user invokes a prompt, the client callsprompts/get. - Notifications. Bidirectional event stream for log messages, progress updates, list-change announcements, and (for sampling) the server asking the client to call its model.
- Shutdown. Client closes the transport. For stdio, the subprocess typically exits with the client; for HTTP / Streamable HTTP, the server is an independent long-lived process that simply ends the session while continuing to serve other clients.
The whole thing is JSON-RPC 2.0 over the chosen transport.
The three core primitives
Tools
Tools are functions the model can call. Each tool has a name, a description, and a JSON-schema for its arguments. The server returns a structured result; the result is appended to the conversation as a tool-result message.
from mcp.server.fastmcp import FastMCP
server = FastMCP("filesystem")
@server.tool()
def read_file(path: str) -> str:
"""Read the contents of a file at the given path."""
with open(path) as f:
return f.read()Tools are model-driven: the model decides when to call them based on the description and the conversation. A good description matters; the model uses it to choose the tool.
Resources
Resources are data the client (or user) can read. Each resource has a URI, a name, optional MIME type, and content. Resources are application-driven: the client surfaces a list of available resources to the user (often as attachable items), and the user picks which to include in the conversation.
@server.resource("file://docs/{path}")
def read_doc(path: str) -> str:
return load_doc(path)The distinction matters in clients with rich UI. In Claude Desktop, resources show up as attachable items in the chat composer. In Cursor, they show up as @ mentions. In headless agents, the agent loop iterates over resources programmatically.
Prompts
Prompts are reusable prompt templates the server exposes. Each prompt has a name, a description, optional argument schema, and a template that the server fills with the arguments. They appear as slash commands in the client UI.
@server.prompt()
def code_review(language: str, file_path: str) -> str:
return f"Review the following {language} file: {file_path}..."Prompts are user-driven; the user invokes the prompt by name (or by slash-command in the UI), the server returns the rendered messages, the client sends them to the model.
Sampling, roots, and elicitation (client capabilities)
Three client-side capabilities the server can call into when the client supports them.
Sampling. The server requests the client to run an LLM call on its behalf. Useful when the server wants to use the client’s model (and credentials) for a sub-task. The client always retains control; sampling requests are subject to user approval.
Roots. A scoping mechanism for what file system or URL space the client allows the server to access. The client declares root paths at session start; the server is supposed to stay within them.
Elicitation. A newer capability that lets the server prompt the user via the client for additional input mid-call.
Transports
Two standard transports are defined in the current spec, plus a legacy HTTP+SSE transport retained for backward compatibility.
Stdio
Server runs as a subprocess of the client. Communication is JSON-RPC over stdin and stdout. This is the canonical local transport: a few lines of config in Claude Desktop, Cursor, or Cline launches the server and routes messages.
Pros: trivial to set up, no network exposure, the OS handles the lifecycle.
Cons: only works when the client and server are on the same machine.
Streamable HTTP
The modern HTTP transport, introduced in the 2025-03-26 spec revision. The server exposes one MCP endpoint that supports both POST (every client JSON-RPC message is a new POST; the server may reply with JSON or open an SSE stream on the same response) and GET (the client opens a server-to-client SSE stream for notifications). Sessions are tracked via a session id header.
Pros: works across machines, simple to deploy behind a reverse proxy or CDN, supports long-running connections and notifications, integrates with standard HTTP auth.
Cons: more setup than stdio, requires careful session and Origin management.
HTTP+SSE (legacy)
The original HTTP transport from the 2024-11-05 revision. Server runs as a long-lived HTTP service; client opens an SSE stream for server-to-client messages and POSTs to a separate endpoint for client-to-server. Replaced by Streamable HTTP starting 2025-03-26 and now legacy / backward-compatible only; many existing servers still ship the SSE path.
Pros: works across machines.
Cons: dual-endpoint design is more complex than Streamable HTTP. Migration path is well-documented.
Building an MCP server
Reference SDKs ship in Python and TypeScript. The pattern is consistent.
Python (FastMCP-style)
from mcp.server.fastmcp import FastMCP
server = FastMCP("orders")
@server.tool()
def get_order(order_id: str) -> dict:
"""Look up an order by id."""
return db.fetch_order(order_id)
@server.resource("order://{order_id}")
def order_resource(order_id: str) -> dict:
return db.fetch_order(order_id)
if __name__ == "__main__":
server.run() # stdio by default; pass transport="streamable-http" for HTTPTypeScript
import { McpServer } from "@modelcontextprotocol/sdk/server/mcp.js";
import { StdioServerTransport } from "@modelcontextprotocol/sdk/server/stdio.js";
import { z } from "zod";
const server = new McpServer({ name: "orders", version: "1.0.0" });
server.tool(
"get_order",
"Look up an order by id.",
{ order_id: z.string() },
async ({ order_id }) => ({ content: [{ type: "text", text: JSON.stringify(await db.fetchOrder(order_id)) }] })
);
await server.connect(new StdioServerTransport());Both SDKs handle the JSON-RPC plumbing, capability exchange, and primitive-list responses automatically.
Hosting an MCP server
Three patterns.
Local subprocess
Distribute the server as a binary, npm package, or Python package. The client launches it via stdio. The simplest deploy story; no network setup required.
Hosted HTTP
Deploy the server as a long-running HTTP service behind a reverse proxy. Authenticate clients with bearer tokens, OAuth, or whatever your infra uses. Streamable HTTP is the recommended transport. Any host that supports the required Streamable HTTP semantics (POST plus GET for SSE, persistent sessions, sufficient request duration for streaming, auth, and Origin validation) can host MCP; Cloudflare Workers, Vercel, Render, and most container hosts work, but verify SSE and request-timeout limits before relying on streaming.
Embedded in another service
Bundle the MCP server inside an existing service (web app, API gateway, internal tool). The MCP transport is one route; the rest of the service is unchanged. Useful for incremental rollout: existing services start exposing MCP without rearchitecting.
How MCP servers compare with other tool-call mechanisms
A practical map.
- OpenAI function calling. Model-side primitive. The LLM emits a function-call JSON; the client routes it. MCP is the wire protocol beneath this. The two compose.
- LangChain BaseTool / LlamaIndex BaseTool. In-process Python objects. Lighter weight than MCP, no JSON-RPC overhead, but no cross-process or cross-language story.
- CrewAI tool decorator / OpenAI Agents tool decorator. Same as LangChain BaseTool: in-process, framework-specific.
- REST APIs / OpenAPI. Generic web APIs. The agent’s tool layer has to bridge the OpenAPI shape to the function-calling shape; MCP servers can wrap an OpenAPI tool and expose it as MCP primitives.
- A2A (Agent-to-Agent). Google’s protocol for agent-to-agent communication. Targets agent dispatch, not tool calls. MCP and A2A address different layers; they coexist.
MCP’s distinct posture: cross-client, cross-language, cross-vendor protocol for tool federation. The N+M scaling property is what made it the convergence point.
Production patterns
Three that show up.
1. Internal-tool federation
Each internal API (orders, billing, inventory, CRM) exposes an MCP server. Every agent inside the company subscribes to the relevant servers. New agents get tool access without per-agent integration; new tools become available to all agents without per-agent changes.
2. Developer-IDE workflow
A developer uses Cursor, Cline, or Claude Code with MCP servers for the codebase, the issue tracker, the deploy system, and the runbook. The IDE is the single client; the four servers expose the four tool surfaces. The developer’s questions (“what’s broken on staging?”, “show me the test failures from the last deploy”) route to the right server without manual orchestration.
3. Multi-cloud and partner integrations
A SaaS company exposes an MCP server for its API. Customers’ agents (Claude Desktop users, Cursor users, internal agents) connect to the server. The protocol is the integration; no per-customer SDK is required.
Common mistakes
- Conflating MCP servers with HTTP APIs. They are different layers. An MCP server may wrap an HTTP API, but it is not the API itself.
- Skipping the capability exchange in custom implementations. Hand-rolling MCP without the proper handshake breaks compatibility with newer clients.
- Putting business logic in the tool description. The description is for the model; it should explain when to call the tool, not what the tool does internally.
- No structured error handling. MCP errors are JSON-RPC error responses. Returning a non-JSON-RPC string on failure breaks clients.
- Long-running tools without progress notifications. A tool that runs for 30 seconds without progress updates feels broken in the UI. Send
notifications/progressfor long calls. - Ignoring root scoping. A filesystem server that does not honor the client’s roots is a security risk; see evaluating MCP servers for security for the full threat model.
- Stdio transport behind a network. Stdio is local-only by design. Network-exposed servers must use Streamable HTTP.
- No observability on the client or server. Each MCP exchange should be a span. Without spans, debugging cross-server agent failures is grep over logs.
How FutureAGI implements MCP server observability and evaluation
FutureAGI is the production-grade observability and evaluation platform for MCP-connected agents built around the closed reliability loop that other MCP stacks stitch together by hand. The full stack runs on one Apache 2.0 self-hostable plane:
- MCP exchange tracing, traceAI (Apache 2.0) instruments the MCP client across Python, TypeScript, Java, and C#; spans carry tool name, arguments, return value, latency, status, and roots; for self-built MCP servers, emit OTel spans from inside the server so the trace spans both sides of the exchange.
- Tool-correctness evals, 50+ first-party metrics including Tool Correctness, Argument Correctness, Step Efficiency, Plan Adherence, and Faithfulness attach as span attributes on every MCP call; BYOK lets any LLM serve as the judge at zero platform fee, and
turing_flashruns the same rubrics at 50 to 70 ms p95. - Simulation, persona-driven scenarios exercise MCP tool surfaces in pre-prod with the same scorer contract that judges production traces; root scoping and capability handshake regressions catch before live traffic.
- Gateway and guardrails, the Agent Command Center fronts 20+ providers via six native adapters (OpenAI, Anthropic, Gemini, Bedrock, Cohere, Azure) plus OpenAI-compatible presets and self-hosted backends with BYOK routing for the model that drives the MCP client; 18+ runtime guardrails enforce policy on the same plane.
Beyond the four axes, FutureAGI also ships six prompt-optimization algorithms that consume failing trajectories as training data. Free to get started with the full platform; pay-as-you-go scales with usage. Compliance and enterprise add-ons (SOC 2 Type II, HIPAA BAA, SAML SSO + SCIM, dedicated CSM) layer on as you need them (pricing).
Most teams running MCP-connected agents in production end up running three or four tools alongside MCP: one for traces, one for evals, one for the gateway, one for guardrails. FutureAGI is the recommended pick because tracing, evals, simulation, gateway, and guardrails all live on one self-hostable runtime; the loop closes without stitching.
Sources
- Model Context Protocol official docs
- MCP specification
- modelcontextprotocol/python-sdk on GitHub
- modelcontextprotocol/typescript-sdk on GitHub
- Reference servers repo
- Anthropic MCP announcement
- MCP Inspector
- traceAI on GitHub (Apache 2.0)
- OpenInference on GitHub
Series cross-link
Related: Model Context Protocol Explained, The FutureAGI MCP Server, MCP vs A2A, API vs MCP, Evaluating MCP-Connected AI Agents in Production, Build, MCP, Evaluate, Observe
Frequently asked questions
What is an MCP server in plain terms?
How is an MCP server different from a tool API?
What are the three MCP primitives?
What transports does MCP support?
How does MCP relate to OpenAI function calling and Anthropic tool use?
How do I build an MCP server?
What MCP servers exist as references?
Where does MCP fit in production observability?

An agent skill is a folder of instructions, scripts, and resources packaged as a SKILL.md unit. What it is, how skills compose, how teams use them in 2026.


Claude Agent SDK is Anthropic's programmable agent harness. Python repo MIT-licensed, use under Anthropic Commercial Terms. Tools, MCP, sessions, observe.

Cloudflare MCP, Bifrost (Maxim), Composio, Smithery, MCP Inspector CLI, and Agent Command Center compared on registration, observability, auth, and OTel.