Multimodal LLM Tracing in 2026: Image, Audio, and Text Spans
Tracing image, audio, and text spans across multimodal LLM apps in 2026. OTel schema, payload handling, redaction, sampling, and tools that ingest them.

Table of Contents
A multimodal customer-support agent ingests a screenshot of a billing error, transcribes the user’s voice memo, and generates a refund explanation. By 2pm the agent’s latency p99 hits 11 seconds. The on-call engineer opens the trace and sees a single 11-second span labeled “agent.invocation” with no children, because the team instrumented OpenAI’s chat span but not the vision encoder, the audio transcription, or the tool calls. The fix is not faster compute. It is multimodal tracing: a trace tree that records the image embed, the audio transcription, the LLM generation, and the tool call as separate spans, with the modality tagged and the payload referenced via URL so the storage cost stays sane.
This guide covers what multimodal LLM tracing looks like in 2026, the OTel schema that makes it cross-vendor, the storage and redaction patterns that keep it compliant, and the tools that actually ingest it.
TL;DR: Multimodal tracing in one paragraph
Multimodal LLM tracing captures image, audio, video, and text spans in one OpenTelemetry trace tree, with the modality named on the span attribute and the payload referenced via URL to a blob store. The schema is the OTel GenAI semantic conventions (still in Development status as of 2026), with multimodal payload URLs (image_url, audio_url, video_url) carried as OpenInference, traceAI, or vendor extensions until a stable cross-vendor schema lands. The tools that handle it natively are OTel-native LLM platforms (FutureAGI traceAI, Phoenix with OpenInference, Langfuse). The hard parts are payload storage, pre-store redaction, and modality-aware sampling.
Why multimodal tracing matters in 2026
Three pressures pushed multimodal tracing from “edge case” to “table stakes” by 2026.
Multimodal models hit production at scale. GPT-5.5 with vision and audio, Claude 4.x with vision, Gemini 3.x natively multimodal. Production teams ship apps where a single user invocation routinely involves three modalities. Tracing that captures only text misses two-thirds of the system.
Voice agents became real. Voice agents in customer support, healthcare intake, and field service ship with sub-second latency requirements and audio-first interaction patterns. The tracing has to record transcription, intent classification, response generation, and TTS as separate spans because each one fails differently.
Compliance asks for image and audio audit trails. EU AI Act Article 12 (record-keeping) and HIPAA both ask for traceable records of inputs and outputs. For text, this is a logging problem. For images and audio, it requires storage architecture decisions: where the payload lives, how long it stays, who can access it.
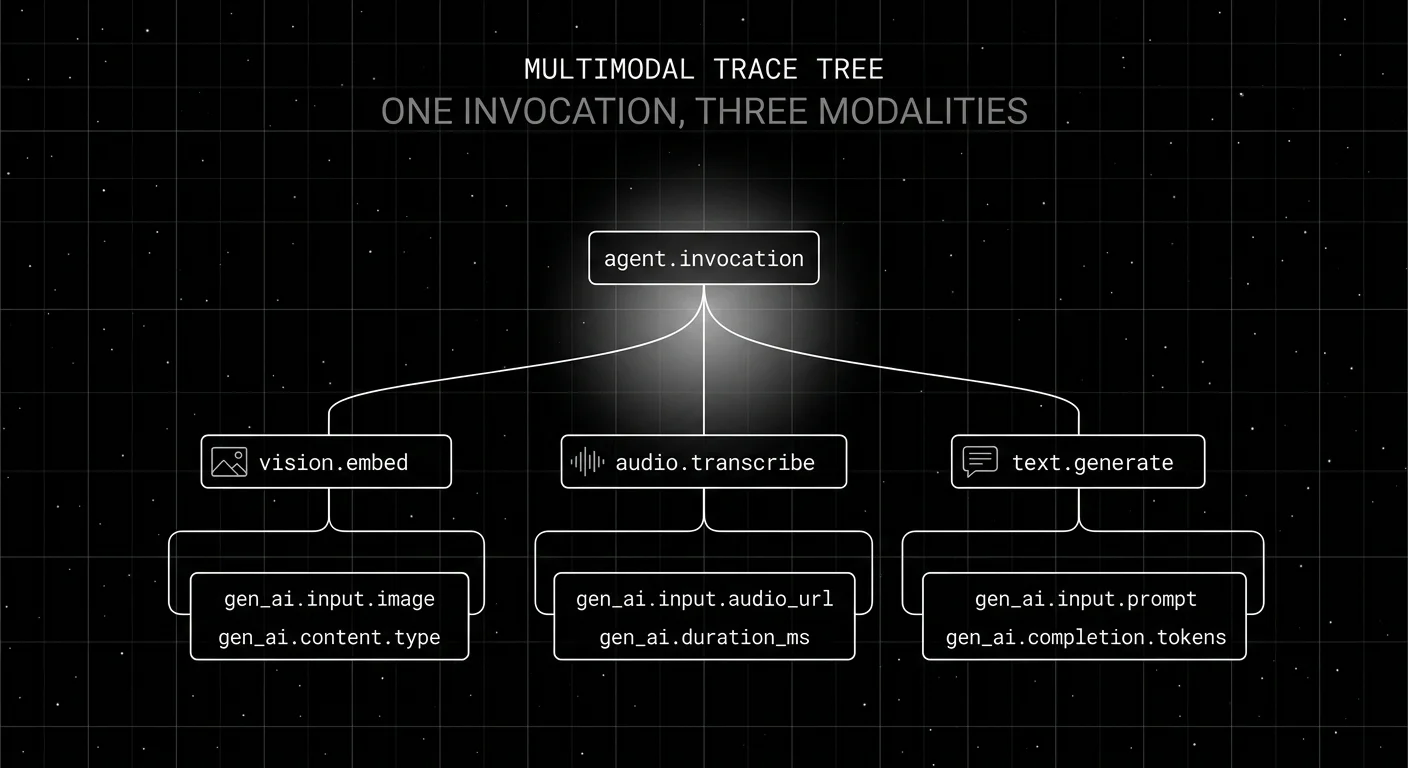
The anatomy of a multimodal trace
A typical 2026 multimodal trace has four span types:
- Invocation span (root). Carries the trace_id, the user_id, the session_id, and aggregate latency.
- Encoder spans. One per non-text input. Vision encoder, audio encoder, video encoder. Each carries a payload URL and the encoder model id.
- Generation span. The LLM call. Carries the prompt template id, the prompt version, the model id, the input messages with content_type per message, and the completion.
- Tool spans. One per tool call. Carries the tool name, the input arguments, the output, and a modality tag if the output is non-text.
Each span carries gen_ai.* attributes per the OTel GenAI semantic conventions. Vendor extensions add gen_ai.tool.calls, gen_ai.tool.definitions, and provider-specific cost attributes.
How multimodal tracing is implemented
Span attributes for multimodal
The OTel GenAI semconv is still in Development status as of 2026 and stabilizing across releases. Commonly-supported attributes today:
gen_ai.request.model. The model id (for example gpt-5.5, claude-opus-4-7, gemini-3.1-flash). Verify against current provider docs at the time of instrumentation.gen_ai.input.messagesandgen_ai.output.messages. Arrays of messages withroleandparts.gen_ai.output.type. The response type when applicable.gen_ai.usage.input_tokens,gen_ai.usage.output_tokens. Token counts.gen_ai.tool.definitions. Tool definitions for tool-calling models.
Multimodal payload URLs (image_url, audio_url, video_url) and per-message content_type are commonly carried as OpenInference, traceAI, or vendor-specific extensions on the span until a stable cross-vendor multimodal schema lands. Treat the URL fields as extensions rather than canonical OTel attributes.
Payload storage
Three patterns for the actual bytes:
- Blob store with signed URL. S3, GCS, or Azure Blob. Payloads written before the span exports. The span carries the signed URL on an OpenInference, traceAI, or vendor-specific attribute (often named
image_url,audio_url, or similar). The OTel GenAI spec does not yet define these attribute names canonically. This is the dominant 2026 pattern because it survives at scale. - Platform artifact store. Phoenix, FutureAGI, Langfuse all accept small media payloads via API and reference them on the span. Convenient for low-volume use; not designed for terabyte-scale ingest.
- Inline base64. Acceptable for icon-sized images. Catastrophic for full-resolution images or audio. Avoid above a few hundred bytes.
Redaction
Pre-store redaction is the only compliant pattern for image and audio:
- Images. Face blurring (OpenCV, AWS Rekognition with redaction, GCP Cloud Vision), document OCR-then-redact, license plate masking. Run before the upload to blob storage.
- Audio. Transcribe with a speech-to-text model, run PII detection on the transcript, redact words, optionally regenerate audio with TTS. Or speaker-diarize and remove the speaker that contains the PII.
- Video. Same as image plus same as audio, frame-by-frame plus track-by-track. Computationally heavy; sample to disk and process offline.
Storing originals in the trace backend and redacting in the dashboard is a compliance failure pattern. The trace backend should never see the original PII payload.
Sampling
Modality-aware sampling matters because the cost structure differs by orders of magnitude.
- Text-only routes. Sample at 5-20 percent of traffic. Storage cost is bounded by token count.
- Image-heavy routes. Sample at 1-5 percent of traffic. A 1024 x 1024 image is roughly 700 KB; even URL references add up at 100 sample units.
- Audio-heavy routes. Sample at 1-3 percent. One minute of 16 kHz audio is roughly 1 MB.
- Errors and high-cost. Sample at 100 percent regardless of modality. The diagnostic value swamps the storage cost.
Tail-based sampling (decide after the trace completes) is the right strategy for multimodal. Head-based sampling makes the modality-aware decision impossible.
Tools that handle multimodal tracing
Five tools cover the multimodal path with first-party support:
- FutureAGI traceAI. Apache 2.0, OTel-compatible tracing library with integrations for OpenAI, Anthropic, Google GenAI, Vertex AI, and many frameworks. The voice observability docs show recording-URL handling, and the judge model docs list image- and audio-capable evaluators.
- Arize Phoenix with OpenInference. ELv2. Strong vision and audio span semantics. Same instrumentation in Phoenix and Arize AX.
- Langfuse. MIT core. Multimodal trace support landed in 2025; payloads stored via media references.
- OpenInference (Arize). The instrumentation library used by Phoenix and many other backends. Apache 2.0 packages for Python, JavaScript, Java.
- OpenAI / Anthropic / Google vendor SDKs. First-class multimodal inputs and OTLP export hooks. The schema gap is filled by traceAI or OpenInference auto-instrumentation.
The tools to avoid are pure-text observability tools that don’t ingest media URLs (most APM tools, several legacy LLMOps platforms). They store the URL as a string but never render or judge the payload.
Common mistakes when tracing multimodal apps
- Inlining large payloads as base64. Storage cost balloons; OTLP exporters time out. Switch to URL references at week one.
- Sampling at the trace level without modality awareness. A 5 percent sample on an image-heavy route still costs 100x a text-only route. Pick sampling rates per route.
- Storing originals before redaction. The trace backend should never see the original PII payload. Redact in a side pipeline before upload.
- Treating tool spans as opaque text. A tool that returns an image must tag its modality. The trace renderer otherwise truncates the payload as a string.
- Missing the cross-modality trace_id. A vision span and a text span from the same invocation share the trace_id. Without it, multimodal debugging is impossible.
- Pure-text judges on multimodal outputs. A text-only judge cannot evaluate image groundedness or audio accuracy. Pick judges that match the modality.
- No retention policy on payloads. Image and audio payloads accumulate quickly. Set retention shorter than text trace retention; the legal exposure is larger.
The future of multimodal tracing
Three trends shape the next 18 months.
OTel GenAI semconv stabilization. The spec reached widespread adoption in 2026; multimodal extensions are still in development. Expect the schema to converge by mid-2027.
Multimodal-aware judges become standard. Image groundedness, audio transcription accuracy, video event detection. Distilled multimodal judges (cheaper than frontier multimodal models) make 100 percent online scoring possible.
On-device redaction. Privacy-first deployments (healthcare, defense) push redaction into the client. The trace backend never sees raw payloads at all; spans carry only redacted URLs. Tools that handle on-device-redacted payloads natively will lead.
Sources
- OpenTelemetry GenAI semantic conventions
- OpenInference GitHub repo
- traceAI GitHub repo
- Phoenix docs
- Langfuse docs
- OpenAI vision guide
- Anthropic vision messages
- Google Vertex multimodal
- FutureAGI traceAI integrations
- HIPAA Audit Controls
- EU AI Act Article 12 record-keeping
- AWS Rekognition redaction
Series cross-link
Read next: What is LLM Tracing?, LLM Tracing Best Practices, Best LLM Tracing Tools 2026
Frequently asked questions
What is multimodal LLM tracing?
How is multimodal tracing different from text-only LLM tracing?
What does the OTel schema for multimodal spans look like in 2026?
Where do you store the actual image and audio payloads?
How do you redact PII in image and audio traces?
Which tools support multimodal LLM tracing in 2026?
What are common mistakes when tracing multimodal apps?
Does FutureAGI support multimodal tracing?

Best LLM tracing tools 2026 compared: Future AGI traceAI, Phoenix, Langfuse, OpenLLMetry, Helicone, Datadog. OTel discipline + auto-instrumentation.


LLM tracing is structured spans for prompts, tools, retrievals, and sub-agents under OTel GenAI conventions. What it is and how to implement it in 2026.


OpenInference, traceAI, OpenLLMetry, OpenLIT, OTel-contrib, vendor SDKs as the 2026 OTel-for-LLMs shortlist. License, language, gen_ai.* support.
