LLM Eval Stack: A Reference Architecture for 2026
The 8-layer LLM eval reference architecture for 2026: ASCII diagrams end to end, five deployment topologies, integration points, anti-patterns it kills.
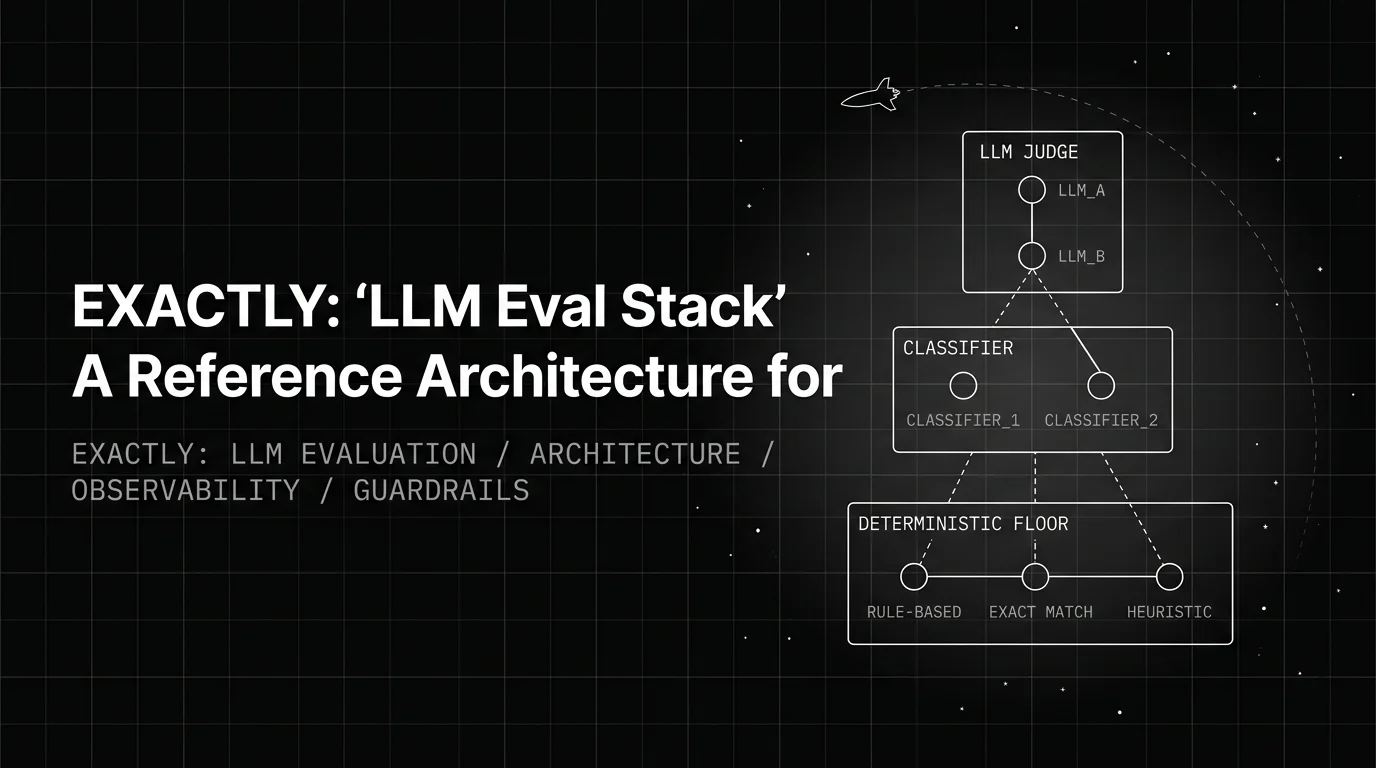
Table of Contents
A staff engineer at a Series C startup opens a Notion page on a Monday morning to map the team’s LLM stack. The whiteboard ends up with eleven boxes, five arrows, two question marks, and the words “who owns this?” written three times. There is a tracing tool, a separate eval tool, a guardrail running in a Lambda, a budget alert in PagerDuty, and a clustering notebook that someone runs on Fridays. None of it talks to anything else. The team ships features. The stack is not a stack. It is a heap.
This post is the architecture sketch the team should have drawn first. It names the eight layers of the canonical LLM eval stack, the contract between them, the data flow with ASCII diagrams, the five deployment topologies, the integration points with existing OTel and warehouse and CI infrastructure, and the architectural anti-patterns that show up when the layers are not named. If you are building this stack green-field, this is the picture. If you are retrofitting an existing pile of pieces, this is the audit checklist.
Why a reference architecture matters
A reference architecture does three things a feature list cannot.
The first is scoping ownership. When the eight layers are named, a platform team can own Layers 1, 2, 5, 6. An ML team can own Layers 4 and 7. The app team owns Layer 0. Layer 3 sits across security and ML. Without the names, every conversation about “who owns the guardrail” becomes a turf war. With the names, the question answers itself.
The second is retiring duplicates. Most teams discover they have two tracing tools (a legacy APM plus an LLM-specific one), two judges (one in the notebook, one in CI), and two dashboards (one for cost, one for quality) that nobody reconciles. A reference architecture names the canonical layer and lets the team retire everything that does not fit. The cost saving from retiring duplicates pays for the rest of the stack within a quarter on most teams we work with.
The third is closing the gaps. The most common gap is the clustering layer (Layer 6). Teams instrument well, run evals well, store spans well, and then investigate failures by reading individual traces. That works at 1,000 spans per day. It collapses at 100,000. The reference architecture forces the question: what runs at Layer 6, and what does it write back to the rest of the stack?
The eight layers, drawn end to end
Here is the canonical stack at a glance.
+-------------------------------------------------------------+
| Layer 7: Self-improvement |
| Platform self-improving evaluators + 6 agent-opt optimizers|
+-------------------------------------------------------------+
^
| feedback, retunes
+-------------------------------------------------------------+
| Layer 6: Clustering / RCA |
| Error Feed: HDBSCAN + Sonnet 4.5 Judge -> immediate_fix |
+-------------------------------------------------------------+
^
| spans + eval scores
+-------------------------------------------------------------+
| Layer 5: Storage / Warehouse |
| ClickHouse / Snowflake / BigQuery (OTel-native) |
+-------------------------------------------------------------+
^ ^
| spans | eval scores
| |
+--------------------+ +-------------------------+
| Layer 1: traceAI | | Layer 4: ai-evaluation |
| (instrumentation) | | (eval execution) |
+--------------------+ +-------------------------+
^ ^
| |
+-------------------------------------------------------------+
| Layer 3: Protect (runtime guardrails, inline at gateway) |
+-------------------------------------------------------------+
^
| requests + responses
+-------------------------------------------------------------+
| Layer 2: Agent Command Center (gateway / routing) |
+-------------------------------------------------------------+
^
| LLM calls
+-------------------------------------------------------------+
| Layer 0: App + framework (agent / RAG / chatbot) |
+-------------------------------------------------------------+Below the diagram, each layer in order.
Layer 0: app and framework
The agent, the RAG service, or the chatbot you are evaluating. Any framework. LangGraph, LlamaIndex, CrewAI, AutoGen, a bespoke FastAPI service, a Vercel Edge function. Layer 0 is not opinionated about framework. It is opinionated about one thing: every LLM call goes through Layer 2, and every meaningful step of the agent flow gets a span from Layer 1.
Layer 1: instrumentation
traceAI emits OTel-native spans on three pluggable conventions: OpenInference, OpenLLMetry, and OTel GenAI. The default is OpenInference because it carries the richest agent semantics (tool calls, retrieval steps, agent transitions). The contract Layer 1 owes the rest of the stack: every LLM call, every tool call, every retrieval step, every agent transition gets a span with stable attribute names. Every span carries a trace ID, parent span ID, latency, token counts, and the prompt and completion (gated by privacy controls).
Layer 2: gateway and routing
Agent Command Center is the proxy in front of every model. Six native adapters cover the major SDK shapes (OpenAI, Anthropic, Google, Bedrock, Azure, Vertex). Twenty plus providers route behind a single API. Shadow, mirror, and race traffic patterns let the gateway compare candidate models against production traffic without disrupting users. Five-level hierarchical budgets (org, team, project, route, user) feed FinOps chargeback. Request-level overrides let an agent author pin a model per route without redeploying. The gateway emits cost and latency headers that the OTel collector captures as span attributes, which means Layer 5 sees cost-per-trace and latency-per-trace without extra plumbing.
Layer 3: runtime guardrails
Protect is the inline guardrail layer. Four Gemma 3n LoRA adapters cover prompt injection, jailbreak, toxicity, and policy violation at 65 ms text and 107 ms image. An 18-entity PII regex fallback runs alongside the ML detectors so PII coverage is deterministic even when the ML hop fails. Protect emits guardrail spans on the same trace as the LLM call, which lets Layer 4 (eval execution) and Layer 6 (clustering) see guardrail decisions alongside everything else without joining across stores.
Layer 4: evaluation execution
The ai-evaluation SDK is where rubric scoring lives. Sixty plus EvalTemplate classes cover Groundedness, ContextAdherence, FactualAccuracy, AnswerRefusal, TaskCompletion, and the rest. Thirteen guardrail backends (LlamaGuard 3, Qwen3Guard, Granite Guardian, WildGuard, ShieldGemma, and others) provide classifier-backed fallbacks for cost-sensitive rubrics. Eight SDK Scanners run point-in-time scans for safety, faithfulness, and bias. Four distributed runners (Celery, Ray, Temporal, Kubernetes) scale eval execution to research-grade rigor.
Layer 4 reads spans from Layer 5 (the warehouse), runs the rubric basket, and writes eval scores back as span attributes on the same trace. That round trip is the load-bearing piece of the architecture: eval scores live with the call they describe, not in a separate eval database.
Layer 5: storage and warehouse
OTel spans flow through a standard OTel collector into the warehouse of your choice. ClickHouse is the high-cardinality default. Snowflake, BigQuery, and Databricks all work because the format is standard OTel. The contract: spans and eval scores live in the same table. Joins are by trace ID. Retention is set by the warehouse tier, not by Future AGI. The data warehouse architecture post digs into the schema and the cardinality budget.
Layer 6: clustering and root cause analysis
The Error Feed reads failures from Layer 5, runs HDBSCAN soft clustering on the failure embeddings, and a Sonnet 4.5 Judge writes an immediate_fix per cluster. The cluster surface is what an ops engineer reads on a Monday morning instead of scrolling through 50,000 individual traces. The immediate_fix is a structured field with a proposed prompt patch, a rubric threshold change, or a retrieval-config tweak. Linear OAuth is the wired ticketing destination today; Slack, GitHub, Jira, and PagerDuty are on the roadmap.
Layer 7: self-improvement
Platform self-improving evaluators retune rubric thresholds and judge prompts from production thumbs-up / thumbs-down feedback plus the Error Feed clusters. Six agent-opt optimizers consume eval-driven signal to tune prompts and classifier thresholds. The signal flow from Layer 4 to Layer 7 is eval-driven today; a trace-stream connector that feeds raw traces into the optimizers is on the roadmap.
The data flow
The architecture diagram shows boxes. The data flow shows arrows. Here is the canonical request-response cycle drawn end to end.
USER
|
v
[Layer 0: App]
| LLM call
v
[Layer 2: Gateway] ---- cost/latency headers ----+
| |
| inline |
v |
[Layer 3: Protect] ---- guardrail spans -------+ |
| | |
| upstream LLM | |
v | |
[Provider: OpenAI / Anthropic / ...] | |
| | |
| response | |
v | |
[Layer 2: Gateway] <----------------------------+ |
| |
v |
[Layer 0: App] -- traceAI spans --+ |
v v
+---------------------------------+
| Layer 5: Warehouse (OTel store) |
+---------------------------------+
^ ^
reads spans | | writes eval scores
| |
+--------------------+
| Layer 4: ai-eval |
+--------------------+
^
| reads clusters + scores
|
+--------------------+
| Layer 6: ErrorFeed |
+--------------------+
|
| feedback + immediate_fix
v
+--------------------+
| Layer 7: SelfImpv |
+--------------------+Three properties of this flow are load-bearing.
The first is that every layer writes to Layer 5. Tracing spans, gateway headers, guardrail decisions, eval scores, cluster IDs, and feedback labels all land in the same warehouse keyed on trace ID. That single store is the source of truth and the substrate every analysis runs against.
The second is that the eval round trip preserves locality. Layer 4 reads spans, scores them, and writes scores back as attributes on the same trace. Nothing has to join eval results to traces across stores at query time. A dashboard that shows “groundedness over time for route X” is one query, not a federation.
The third is that the Error Feed reads the warehouse, not the live stream. Layer 6 runs on a batch cadence against accumulated failures. That keeps the clustering layer simple, lets HDBSCAN run on a meaningful corpus, and lets the Judge spend an extra few seconds per cluster writing a useful immediate_fix. A real-time variant is an obvious extension but not the current default.
Five deployment topologies
The same eight layers compose into five real-world topologies. Pick the one that matches your data-residency and operational posture.
Cloud-native
Everything runs in Future AGI’s hosted environment. The gateway, Protect ML, the warehouse, the Error Feed, and the Platform all live in the hosted region. Lowest operational overhead. Suitable for teams without strict data-residency constraints.
BYOC (bring your own cloud)
The gateway runs in your VPC. Protect ML inference is an ML hop to api.futureagi.com (or a private vLLM under enterprise licensing). The warehouse can be your existing Snowflake, BigQuery, or ClickHouse. The Error Feed and Platform are hosted. Common pattern for teams that need request-payload control without taking on ML inference operations.
Hybrid
Eval execution (Layer 4) runs in your VPC against your warehouse. Observability (Layers 5 and 6) is hosted. This topology is common for teams that have invested in a Databricks or Snowflake estate and want the SDK runners co-located with the data, while keeping the cluster surface and the Platform on Future AGI’s hosted side.
Fully self-hosted
The Apache 2.0 components (the ai-evaluation SDK, traceAI, the open-weight guardrail backends like LlamaGuard 3 and Qwen3Guard) run entirely inside your VPC. Protect ML weights are closed and not self-hostable through the standard tier. Enterprise licensing supports a private vLLM deployment of Protect inside your VPC. The Error Feed and Platform are not part of the self-hosted bundle.
Multi-region
Two hosted regions, EU and US, with data residency per region. Layer 2 (gateway) routes requests to the regional Protect, Layer 5 (warehouse) keeps data in-region, and Layers 6 and 7 run per region. Suitable for global teams with strict EU residency requirements.
Integration with existing infrastructure
The reference architecture does not assume a green field. Five integration points keep the stack composable with what most enterprises already run.
The first is existing OTel infrastructure. Datadog, Honeycomb, Grafana Tempo, and Jaeger all read traceAI spans without modification because traceAI emits standard OTel. A team that already has a Datadog APM pipeline can dual-write spans to Datadog and to the Future AGI warehouse, or send them only to Datadog and read them back via Datadog’s API. The OpenTelemetry trace export post covers the dual-write pattern.
The second is existing data warehouses. Snowflake, BigQuery, and Databricks ingest the same spans through standard OTel exporters. The eval scores Layer 4 writes back are span attributes, which means SQL analytics on eval data does not require a new query language or a new BI tool. Existing dbt models extend cleanly to eval scoring data.
The third is existing ticketing. Linear OAuth is the wired destination today; the Error Feed posts immediate_fix items as Linear tickets per cluster. Slack, GitHub, Jira, and PagerDuty are on the roadmap. Teams that need one of those today can subscribe to the Error Feed webhook and route to their tool of choice.
The fourth is existing CI. GitHub Actions, GitLab CI, and CircleCI all run the ai-evaluation SDK as an eval gate on every PR. The CI/CD for LLM eval post shows the working GitHub Actions configuration with per-route thresholds and rollback.
The fifth is existing FinOps. The 5-level hierarchical budgets at Layer 2 (org, team, project, route, user) export to standard chargeback formats. Cloudability, Vantage, and the AWS Cost Explorer all consume the export. FinOps teams do not need a new dashboard to track LLM spend at the route level.
Five architectural anti-patterns
The reference architecture exists because the anti-patterns are common, expensive, and largely invisible until they bite.
Missing instrumentation layer
A team that does not own Layer 1 cannot evaluate what it cannot observe. The team installs a judge, points it at a sample of production calls, and discovers that half the failures are upstream of the LLM (in retrieval, in tool routing, in agent transitions) and invisible without spans. The fix is to install Layer 1 first. Every other layer assumes spans exist.
Eval as bolt-on, not tracing-coupled
The naive design stores eval scores in a separate database from traces. Every dashboard becomes a join. Every drill-down becomes a federation. Every retention policy becomes two retention policies. The reference architecture writes eval scores back to Layer 5 as span attributes on the same trace. One store. One query language. One retention policy.
Single-layer ownership
One team owning all eight layers becomes the bottleneck for every other team. The platform team that owns observability cannot also own evaluator rubrics for a fintech route and a customer-support route and a coding-agent route. The reference architecture lets you scope ownership: platform team owns Layers 1, 2, 5, 6; ML team owns 4 and 7; app teams own 0; Layer 3 sits across security and ML. Without scoped ownership, the stack runs at the speed of the slowest team.
No clustering layer
Per-trace investigation does not scale past 10,000 spans per day. An ops engineer cannot read 50,000 traces on a Monday. The reference architecture requires Layer 6. HDBSCAN soft clustering on failure embeddings, a Judge writing immediate_fix per cluster, and a structured surface that lets one engineer triage 50,000 failures by reading 30 clusters. Without Layer 6, the eval stack produces data nobody acts on.
No self-improvement layer
Rubrics rot. Thresholds drift. A faithfulness threshold tuned in January is wrong by April. Without Layer 7, the team revisits rubric tuning ad hoc, usually after a customer complaint. The reference architecture closes the loop: Platform self-improving evaluators retune from feedback, the six agent-opt optimizers retune prompts and classifier thresholds, and the stack gets better while the team sleeps.
How the layers compose into a real architecture
Here is a worked example. A fintech team ships an agentic billing assistant.
Layer 0 is the LangGraph agent that handles billing queries. Layer 1 is traceAI emitting OpenInference spans on every node transition. Layer 2 is Agent Command Center routing to Claude Sonnet 4.5 with GPT-5 as a fallback and a 5-level budget per tenant. Layer 3 is Protect blocking prompt injection and policy violation inline; the 18-entity PII regex fallback redacts SSN, card number, and IBAN deterministically. Layer 4 is the ai-evaluation SDK running a rubric basket of Groundedness, FactualAccuracy, AnswerRefusal, and TaskCompletion on every production sample, using LlamaGuard 3 as the classifier-backed fallback for the safety rubric. Layer 5 is ClickHouse, with eval scores written back as span attributes. Layer 6 is the Error Feed clustering failures and writing immediate_fix to Linear. Layer 7 is Platform self-improving evaluators retuning thresholds weekly and a prompt-optimization agent-opt pass that runs nightly.
The architecture is not magic. It is the eight layers, named, owned, and wired together. The ASCII diagrams are the wiring diagram any new engineer reads before they touch a config.
Honest framing on what’s shipping and what’s roadmap
Three pieces are explicitly on the roadmap rather than shipping today.
The first is the trace-stream connector from Layer 4 to Layer 7. The current signal flow from eval execution into agent-opt is eval-driven, not raw-trace-driven. Eval scores, threshold tunings, and cluster IDs feed Layer 7. The trace-stream variant that lets agent-opt see raw spans is on the roadmap.
The second is broader ticketing destinations at Layer 6. Linear is wired today through OAuth. Slack, GitHub, Jira, and PagerDuty are roadmap. Teams that need one of those today subscribe to the Error Feed webhook.
The third is self-hosted Protect ML weights. The gateway, the ai-evaluation SDK, traceAI, and the open-weight guardrail backends are all self-hostable under Apache 2.0. Protect’s Gemma 3n LoRA weights are closed. Enterprise licensing supports a private vLLM deployment of Protect inside your VPC; the standard tier requires the ML hop to api.futureagi.com.
Everything else in this architecture is shipping today. The eight layers, the OTel-native conventions, the gateway with 6 native adapters and 20+ providers, the 65 ms text and 107 ms image guardrails, the 60+ EvalTemplate classes and 13 guardrail backends and 4 distributed runners, the HDBSCAN clustering with the Sonnet 4.5 Judge, and the Platform self-improving evaluators are all production today.
The next read
If you are scoping the eight layers for the first time, the LLM evaluation playbook is the next read. If you are picking the warehouse for Layer 5, the data warehouse architecture post is the deep dive. If you are wiring Layer 4 into CI, CI/CD for LLM eval on GitHub Actions is the working configuration. If you are debating self-hosted versus hosted, the open-source LLM evaluation library post covers the Apache 2.0 surface in detail.
The architecture is the picture. The picture is eight layers. Draw it before you wire it.
Frequently asked questions
What are the eight layers of the canonical LLM eval stack?
Why does a reference architecture matter when teams already have eval tooling?
How does data actually flow through the eight layers?
What are the five deployment topologies for this stack?
Which integration points matter for an enterprise rollout?
What are the architectural anti-patterns this reference design eliminates?
What is shipping today and what is on the roadmap?

Five Parea AI alternatives scored on eval-catalog depth, logs-capped pricing, optimizer loops, guardrails, and team scale, and what each fixes.


Five RagaAI alternatives scored on eval-judge depth, optimizer loops, gateway and guardrails, self-host ops burden, vendor maturity, and what each fixes.
Future AGI vs Parea AI scored on tracing, evaluation, prompt management, simulation, security, and DX. Honest verdict and May 2026 pricing.
