Intent Classification LLM Pipeline: 2026 Best Practices
A vendor-neutral 2026 intent classification pipeline. Data, judge prompt, eval, and deploy. Runs end-to-end on OpenAI + traceAI without proprietary SDKs.

Table of Contents
A customer-support agent at a fintech ships a single-prompt approach: one big system message that handles refunds, churn, billing questions, and escalations. By month three, response quality is uneven, the prompt is 4,000 tokens, and adding a new intent breaks two existing ones. The fix is structural: split the work. A small classifier picks the intent, and the downstream agent gets a tighter prompt for that intent only. Refund quality climbs, prompt tokens drop, and adding a new intent is a single dataset update plus a small prompt change.
This guide is a vendor-neutral, code-complete walkthrough of how to build a production intent classification pipeline in 2026. The reference implementation uses OpenAI’s SDK plus traceAI (Apache 2.0) for instrumentation. The same pipeline works with Anthropic, Google, or OSS models. No proprietary SDK is required.
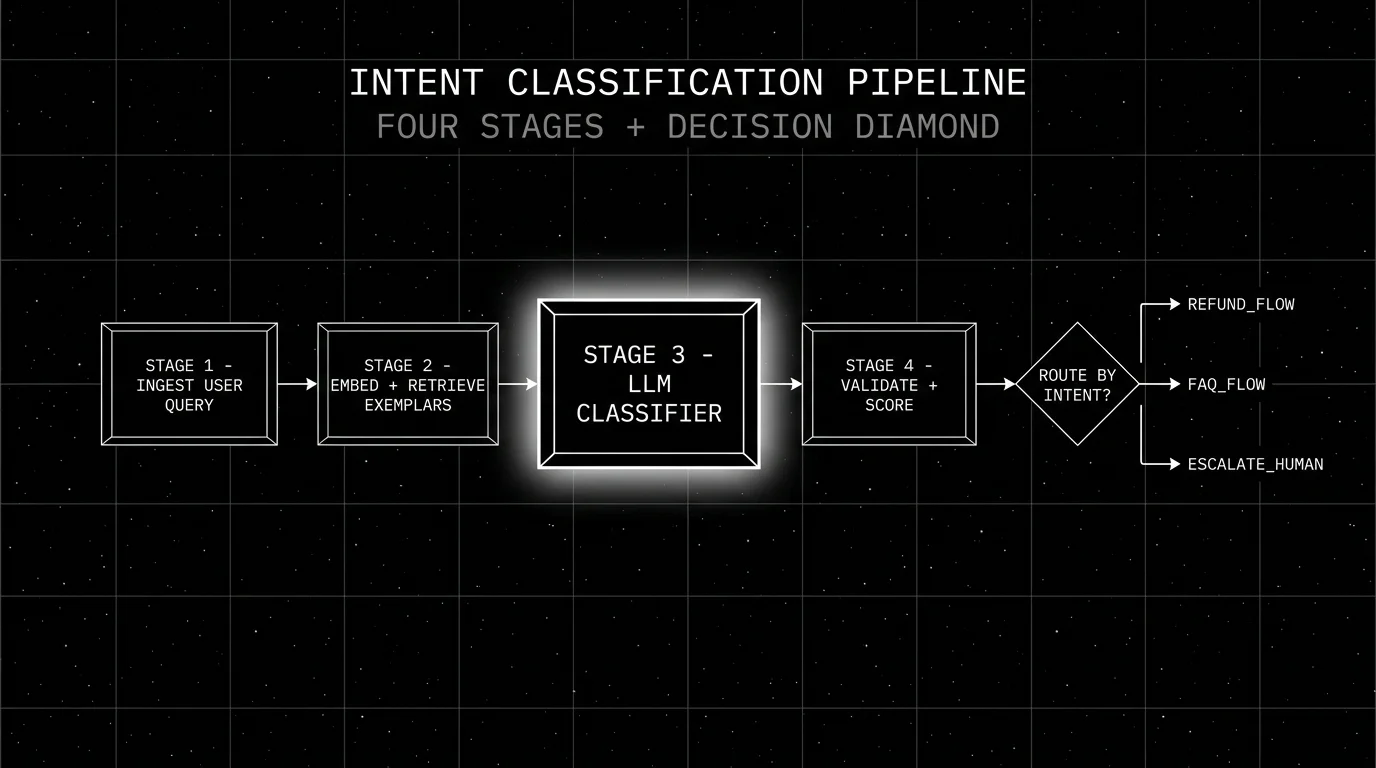
TL;DR: The 4-stage pipeline
| Stage | What it does | Tools |
|---|---|---|
| 1. Ingest | Receive query, trace_id, PII redaction | OTel collector, traceAI |
| 2. Retrieve exemplars | Embed query, pull 3-5 similar labeled examples | OpenAI embeddings, pgvector |
| 3. Classify | Small LLM call with structured output | gpt-5-nano or Claude Haiku 4.5 |
| 4. Validate and score | Schema validate, deterministic fallback, span-attached judge | OpenAI judge or Turing-Flash |
If you only read one row: split the work. A small classifier with structured output and an exemplar-based prompt routes more accurately than a big monolithic agent prompt.
Stage 1: Ingest
The ingest stage is where the trace begins. Three responsibilities.
Attach trace_id. Every downstream span shares this id. Without it, the four stages are four disconnected calls.
Redact PII. Before the query hits the classifier, strip credit card numbers, social security numbers, email addresses, phone numbers, and any other regulated identifiers. The illustrative regex below covers only two narrow patterns; production PII redaction needs a real library like Presidio with named-entity detection plus rule-based recognizers. The trace store should never see raw PII.
Normalize. Lowercase, collapse whitespace, strip HTML and emoji. The classifier sees more uniform input; the embedding model behaves better.
import re
from opentelemetry import trace
tracer = trace.get_tracer("intent.pipeline")
def ingest(raw_query: str) -> str:
with tracer.start_as_current_span("intent.ingest") as span:
# Redact PII (use Presidio in production)
query = re.sub(r"\d{4}[-\s]?\d{4}[-\s]?\d{4}[-\s]?\d{4}", "[CARD]", raw_query)
query = re.sub(r"[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,}", "[EMAIL]", query)
query = " ".join(query.lower().split())
span.set_attribute("query.length", len(query))
return queryStage 2: Retrieve exemplars
Few-shot prompting outperforms zero-shot on classification by 10-30 percent in most workloads. The pattern: embed the incoming query, retrieve the 3-5 most similar labeled examples from the dataset, include them in the classifier prompt.
The retrieval store should be one of: pgvector, Chroma, Weaviate, Qdrant, or LanceDB. The store choice is downstream of your existing infra; pgvector is the lowest-friction pick if you already run Postgres.
import os
from openai import OpenAI
client = OpenAI(api_key=os.environ["OPENAI_API_KEY"])
def retrieve_exemplars(query: str, k: int = 5) -> list[dict]:
with tracer.start_as_current_span("intent.retrieve_exemplars") as span:
# 1. Embed the query
emb = client.embeddings.create(
model="text-embedding-3-small",
input=query,
).data[0].embedding
# 2. Vector search against your labeled dataset (pgvector etc.)
rows = pgvector_search(emb, k=k) # returns [{"query": ..., "intent": ..., "distance": ...}]
span.set_attribute("exemplars.count", len(rows))
return rowsThe dataset behind this retrieval is the heart of the pipeline. Three sources:
- Hand-labeled production queries. 200-500 rows is the floor. Label each row with the intent and a confidence (high, medium, low).
- Synthetic generation. A frontier model (GPT-5.5, Claude Opus 4.7) generates synthetic queries conditioned on each intent label. Usual yield: 1,500-3,000 rows.
- Negative feedback expansion. Rows where production users gave thumbs-down or escalated. The regression layer.
Stratify across difficulty: easy (clear single intent), medium (ambiguous between two), adversarial (intentionally misleading or short). Without stratification, the eval hides the failure modes that matter.
Stage 3: LLM classifier
The classifier is a small LLM with structured output. Four design choices.
Model. Distilled or small-tier (gpt-5-nano, Claude Haiku 4.5, Llama 4 Scout or Llama 3.1 8B for self-host). A frontier model is overkill and adds 200-500 ms latency.
Structured output. JSON schema with intent (one of N) and confidence (high, medium, low). Both OpenAI and Anthropic support strict structured output as of 2026. Do not parse free-form text.
Prompt. Short system prompt naming the intents and rules. User message includes the few-shot exemplars and the query.
Temperature. 0 for classification. The task is deterministic.
from pydantic import BaseModel
from typing import Literal
INTENTS = Literal["refund", "billing", "account", "faq", "escalate", "churn_risk", "unknown"]
class IntentResult(BaseModel):
intent: INTENTS
confidence: Literal["high", "medium", "low"]
reasoning: str
def classify(query: str, exemplars: list[dict]) -> IntentResult:
with tracer.start_as_current_span("intent.classify") as span:
examples_text = "\n".join(
f"- Query: {e['query']}\n Intent: {e['intent']}" for e in exemplars
)
system = (
"You classify customer-support queries into one of: "
"refund, billing, account, faq, escalate, churn_risk, unknown. "
"Use 'unknown' if you cannot decide between two."
)
user = f"Examples:\n{examples_text}\n\nQuery: {query}\n\nClassify:"
resp = client.responses.parse(
model="gpt-5-nano",
input=[
{"role": "system", "content": system},
{"role": "user", "content": user},
],
text_format=IntentResult,
temperature=0,
)
result = resp.output_parsed
span.set_attribute("intent.predicted", result.intent)
span.set_attribute("intent.confidence", result.confidence)
span.set_attribute("gen_ai.usage.input_tokens", resp.usage.input_tokens)
span.set_attribute("gen_ai.usage.output_tokens", resp.usage.output_tokens)
return resultThe reasoning field is the audit trail. It is not used downstream but is invaluable when debugging misclassifications.
Stage 4: Validate and score
The validate-and-score stage has three jobs.
Schema validation. The model occasionally returns invalid JSON or an unknown intent. Pydantic’s parse plus a try/except is the floor.
Deterministic fallback. Low-confidence predictions go through a deterministic check (regex, allow-list, keyword match) before falling back to “escalate” or “unknown”. This cuts judge spend by 60-80 percent in most workloads.
Span-attached judge score. A judge model (frontier offline, distilled online) verifies the classification on a sample. The judge runs asynchronously; the classification ships immediately, the judge attaches its score to the same span_id post-hoc.
def validate_and_score(query: str, result: IntentResult) -> dict:
with tracer.start_as_current_span("intent.validate") as span:
# Deterministic fallback for low-confidence
if result.confidence == "low":
if re.search(r"\b(refund|money back|charged twice)\b", query):
result = IntentResult(intent="refund", confidence="medium",
reasoning="deterministic fallback: refund keywords")
else:
result = IntentResult(intent="escalate", confidence="medium",
reasoning="deterministic fallback: low-confidence escalate")
# Async judge call (fire-and-forget; correlate via the W3C traceparent carrier
# so the worker can resume the trace context and emit a child span).
from opentelemetry.propagate import inject
carrier = {}
inject(carrier) # populates 'traceparent' (and 'tracestate' if set)
enqueue_judge_call(traceparent=carrier.get("traceparent"),
query=query, predicted=result.intent)
span.set_attribute("intent.final", result.intent)
return {"intent": result.intent, "confidence": result.confidence}The worker consuming the queue extracts the traceparent and starts a remote child span, so the judge verdict appears as a child of the original intent.validate span with a judge.verdict attribute.
Eval and CI gating
The eval suite is a separate pytest harness that runs against the dataset on every PR touching the classifier prompt or model.
# tests/test_intent_eval.py
import pytest
from intent_pipeline import classify, retrieve_exemplars
from sklearn.metrics import precision_recall_fscore_support
@pytest.mark.parametrize("split", ["easy", "medium", "adversarial"])
def test_intent_accuracy(split):
dataset = load_dataset(f"intent_eval_{split}.jsonl")
preds, golds = [], []
for row in dataset:
exemplars = retrieve_exemplars(row["query"], k=5)
result = classify(row["query"], exemplars)
preds.append(result.intent)
golds.append(row["intent"])
precision, recall, f1, _ = precision_recall_fscore_support(
golds, preds, average="weighted", zero_division=0)
# Per-rubric thresholds; calibrate against incumbent
thresholds = {"easy": 0.78, "medium": 0.70, "adversarial": 0.60}
assert f1 >= thresholds[split], f"{split} regression: f1={f1:.3f} < {thresholds[split]}"The thresholds are calibrated against the incumbent. A regression on any split blocks the merge.
Production deployment
Five operational details matter.
Per-intent monitoring. Rolling-mean precision, recall, F1 per intent. Alert on 3-5 percent moves.
Confusion matrix. Track which intents get confused with which. A spike in “refund-confused-with-billing” tells you which exemplars are missing.
Per-cohort A/B with eval-gated rollback. Ship a new classifier prompt to 5 percent of traffic. Monitor per-cohort precision over a 1-hour window. Rollback if any intent regresses below threshold.
Dataset auto-build. Misclassifications (judge says wrong, user escalates, deterministic fallback fires) flow into a regression dataset for next week’s eval.
Annotation queue. Low-confidence rows and judge-disagreement rows flow into a human review queue. Reviewers correct the labels; corrected rows feed the dataset.
Common mistakes when building intent pipelines
- Too many intents. Above 12-15, classifier accuracy drops. Group near-duplicates; spawn sub-classifiers if needed.
- No synthetic data. Hand-labeled alone is too small to defend.
- No calibration set. Without 200 human labels, judge agreement is unverified.
- No per-intent monitoring. A single intent regresses and the aggregate metric hides it.
- No escape hatch. Low-confidence should escalate, not guess.
- Frontier model for the classifier. Adds 200-500 ms latency for marginal accuracy gain. Use a small or distilled model.
- Ignoring the confusion matrix. The matrix tells you which exemplars are missing; the aggregate F1 does not.
- Routing on the model’s first token. Use structured output. Free-form text parsers fail in production.
Recent intent pipelines updates
| Date | Event | Why it matters |
|---|---|---|
| 2026 | GPT-5.5 family with strict structured output | JSON schema enforcement removed parser failure modes. |
| 2026 | Claude 4.x JSON mode hardened | Structured output became reliable across both major frontier vendors. |
| Mar 2026 | FutureAGI shipped Agent Command Center | Intent-aware routing and guardrails moved into the gateway. |
| 2026 | OTel GenAI semconv broad adoption | Cross-vendor classifier spans use the same schema. |
| Dec 2025 | DeepEval v3.9.x agent metrics | Built-in metrics for tool-call accuracy and intent classification quality. |
Sources
- OpenAI structured outputs
- Anthropic tool use
- traceAI GitHub repo
- OpenInference GitHub repo
- OpenTelemetry GenAI semantic conventions
- Microsoft Presidio
- pgvector
- DeepEval GitHub
- scikit-learn metrics
- FutureAGI pricing
- Galileo Luna research
- Phoenix docs
Series cross-link
Read next: Best LLM-as-Judge Platforms 2026, Simulated Multi-Turn LLM Evaluation, Evaluating AI Agent Skills
Frequently asked questions
What is an intent classification pipeline for LLM apps?
Why does intent classification matter in 2026?
How do I build the dataset for intent classification?
What's the right judge for intent classification?
Should I use LLM-as-judge or a deterministic check?
How do I deploy and monitor the pipeline in production?
Does this pipeline depend on a proprietary SDK?
What are the common mistakes when building this pipeline?
Simulate persona x scenario x adversary, score multi-turn outcomes, gate releases. Vendor-neutral playbook with code that runs without proprietary SDKs.


Skill-level eval for agents in 2026: discrete skills, per-skill rubrics, regression sets, and CI gates. Vendor-neutral code, no proprietary SDK.


Evaluating Claude Skills in 2026: the skill is a contract, eval the contract. Three rubrics for dispatch, trajectory, integration, on traceAI.