How to Cut Your LLMOps Bill in 2026: 8 Concrete Levers
Eight levers to cut LLMOps spend in 2026: sampling, retention, distilled judges, semantic cache, smaller defaults, prompt caching, batches, budgets.
Table of Contents
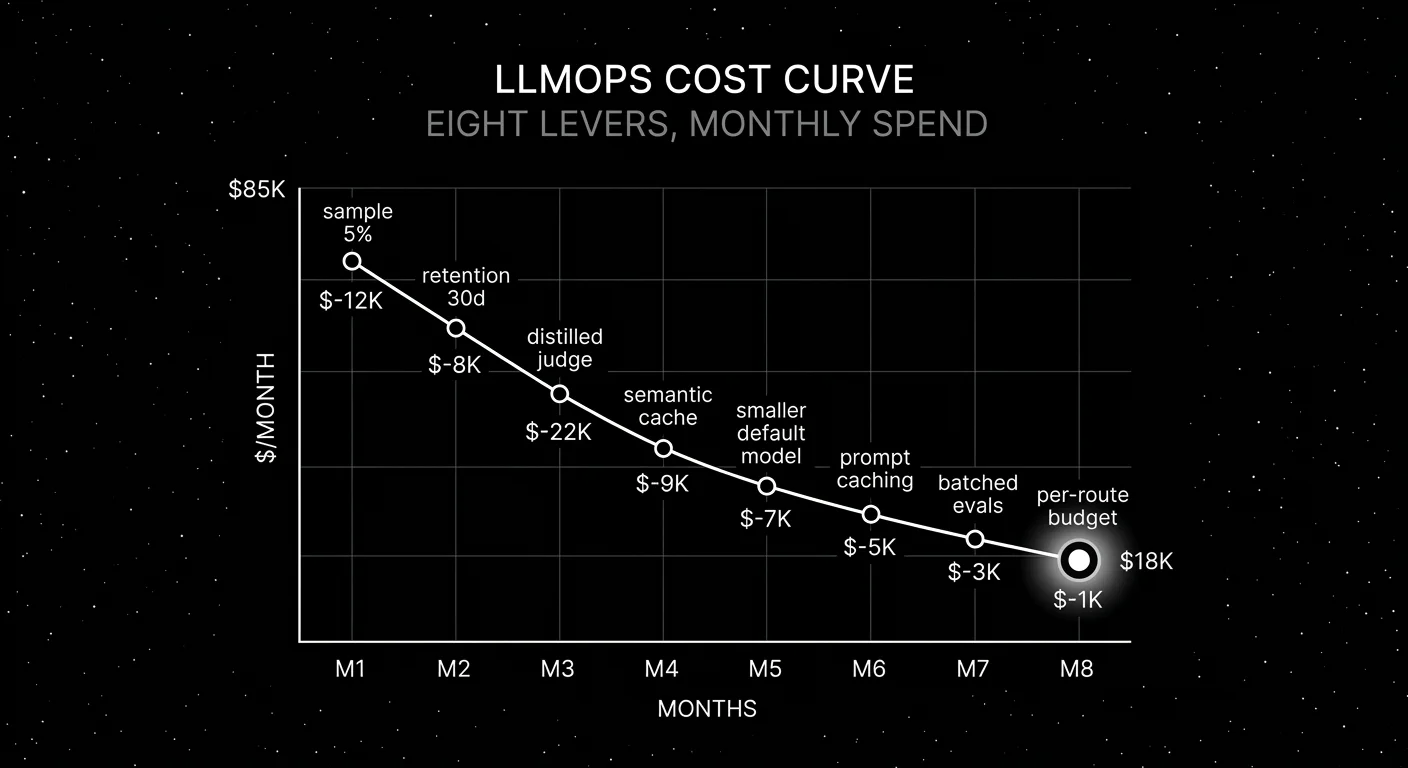
A platform team’s LLMOps bill hits $87K in March on a $40K budget. The on-call engineer pulls the breakdown: $52K is online judge tokens running GPT-5.5 on every production span; $18K is frontier inference on a route that could run on a small model; $9K is trace storage with 365-day retention on every span including image traces; $8K is everything else. The fix is not “renegotiate the platform contract.” The fix is eight levers, each worth 5-30 percent. Together they cut the bill to $18K within a quarter without touching product quality.
This guide walks through the eight levers, with concrete numbers, when to pull each, and the order to pull them.
TL;DR: The 8 levers, ranked by typical impact
| # | Lever | Typical cut | Where it lives |
|---|---|---|---|
| 1 | Distilled judges for online scoring | 30-50% | Eval platform |
| 2 | Tail-based trace sampling per route | 15-30% | OTel collector |
| 3 | Tiered trace retention | 10-20% | Storage layer |
| 4 | Semantic cache on repetitive routes | 20-40% | Gateway |
| 5 | Smaller default model with eval-gated routing | 30-50% | Gateway |
| 6 | Provider prompt caching | 30-60% input | Provider SDK |
| 7 | Batched offline evals | 50% | Eval pipeline |
| 8 | Per-route token budgets | bounds spike | Gateway |
If you only read one row: distilled judges for online scoring is usually the single biggest cut, and per-route budgets are the cheapest insurance against runaway spend.
Lever 1: Distilled judges for online scoring
Online scoring (judge attached to every span) is the largest line item in most 2026 stacks once it is wired. Working through the math on legacy GPT-5 pricing ($1.25 per 1M input, $10 per 1M output) with 5M spans/month, 1,000 input tokens per judge call, and 200 output tokens per judge call: 5B input tokens is roughly $6.25K/month, 1B output tokens is roughly $10K/month, total around $16K before retries. Switch the example to GPT-5.5 pricing (roughly $5 per 1M input, $30 per 1M output as of writing) and the same scenario climbs above $50K/month. Add retries, high-cardinality routes, and judge fan-out and the typical frontier-only online scoring bill lands at $40K-$80K/month at moderate scale. Live pricing: OpenAI, Anthropic.
The fix is a distilled judge. Three viable options in 2026:
- Galileo Luna 2. Closed, foundation model trained for hallucination, factual consistency, context adherence. Roughly 10-30x cheaper than frontier at 85-92 percent agreement after calibration.
- FutureAGI
turing_flash. Proprietary cloud eval model on the FutureAGI platform.turing_flashhits roughly 50-70 ms p95 on guardrail screening; the SDK (docs) liststuring_flashat roughly 1-2 seconds andturing_smallat 2-3 seconds for full eval templates with longer rubrics. The traceAI tracing layer is Apache 2.0; BYOK LLM-as-judge is supported separately. - Patronus Lynx. Open weights (Lynx 70B on Hugging Face). Self-host on a small cluster.
- Custom small judge. Fine-tune Llama 4 Scout or Llama 3.1 8B or Mistral Small 3 on your calibration set. Cheapest at scale; requires GPU infra.
Calibrate before switching. A judge swap without calibration is a quality regression hiding behind a cost cut.
# Calibration script: compute Cohen's kappa between distilled and frontier judges
from sklearn.metrics import cohen_kappa_score
def calibrate_distilled_judge(human_labels: list[int], distilled_judge_scores: list[int],
frontier_judge_scores: list[int]) -> dict:
return {
"distilled_vs_human_kappa": cohen_kappa_score(human_labels, distilled_judge_scores),
"frontier_vs_human_kappa": cohen_kappa_score(human_labels, frontier_judge_scores),
"distilled_vs_frontier_kappa": cohen_kappa_score(frontier_judge_scores, distilled_judge_scores),
}Ship the swap when distilled-vs-human kappa is within 0.05 of frontier-vs-human kappa across all rubrics.
Lever 2: Tail-based trace sampling per route
Sampling decides which traces hit the storage backend. Two strategies:
- Head-based sampling. Decide at trace start. Cheap. Misses the modality and cost signal.
- Tail-based sampling. Decide at trace end with full context. Slightly more expensive in collector RAM. Smarter decisions.
Per-route rates that work in 2026:
| Route type | Sample rate |
|---|---|
| Text-only chat | 5-20% |
| Text-only RAG | 10-25% |
| Image-heavy | 1-5% |
| Audio-heavy | 1-3% |
| Errors and high-cost | 100% |
| Cost-anomaly traces | 100% |
| Adversarial signals | 100% |
The OTel Collector with the tail_sampling processor handles this natively. Per-route policies are 5-10 lines of YAML.
Lever 3: Tiered trace retention
Default-everything-to-365-days is expensive. Retention by tier:
- Hot (30-90 days). Active debugging and CI replay. Live in ClickHouse, Postgres, or your trace store.
- Warm (180 days). Quarterly trend analysis. Live in cheaper columnar storage.
- Cold (1-3 years). Compliance and rare audits. Live in S3 Glacier or equivalent at roughly 1/10 the hot cost.
Configure per workload, not globally. A regulated workload might need warm 365 days plus cold 7 years. A FAQ bot might need hot 30 plus cold 90. The defaults that ship with most platforms err high.
Lever 4: Semantic cache on repetitive routes
A semantic cache stores the embedding of every query plus the prior response. On a new query, embed it, search by cosine similarity, return the cached response if similarity is above threshold (typically 0.92-0.96).
Workloads that cache well:
- FAQ bots (cache hit rate 30-50 percent)
- Support agents (cache hit rate 15-30 percent)
- Documentation Q&A (cache hit rate 40-60 percent)
Workloads that don’t cache well:
- Personalized chat
- Conversation-aware responses (turn 2 is rarely the same as a prior turn 2)
- Tool-calling agents (the tool result changes between calls)
Cache TTL is the trickiest dial. 30-60 minutes for non-personalized routes; never cache personalized routes. Stale-answer leakage is the failure mode to watch.
Tools: Redis with vector search, Helicone semantic cache, LangChain semantic cache, GPTCache.
Lever 5: Smaller default model with eval-gated routing
Route by complexity. Frontier for hard reasoning and tool-calling; small for parsing, classification, and routing.
def route(task: dict) -> str:
if task["type"] in ("classify", "parse", "route", "extract"):
return "gpt-5-nano" # cheap default
if task["type"] in ("tool_call", "multi_step_reasoning"):
return "gpt-5" # frontier
if task["context_tokens"] > 32000:
return "claude-opus-4-7" # long context
return "gpt-5-nano"The savings depend on the workload mix. Agents with heavy tool-calling save less; classifiers and parsers save 50-70 percent.
Calibrate before switching. Run the eval suite on the small model first. Ship only when per-rubric pass rates are within tolerance of the frontier baseline.
Lever 6: Provider prompt caching
Long system prompts and few-shot examples are the cheapest cut you can make if your provider supports prompt caching.
- OpenAI. Prompt caching at roughly 10 percent of the standard input rate on current GPT-5.5 family models, automatic for prefixes above 1,024 tokens. The 50 percent figure was an earlier rate; refer to the live pricing page. Automatic for prefixes above 1,024 tokens.
- Anthropic. Prompt caching at roughly 10 percent of read rate after a 125 percent write. Cache write is more expensive than the standard rate; cache reads are nearly free.
- Google Vertex. Context caching at a 75 percent input discount once cached.
Workloads with long static prefixes (system prompts, RAG context, few-shot exemplars) save 30-60 percent on input tokens. Workloads with cold prefixes (every prefix unique) gain little.
Watch out for cache-invalidation patterns. A single character change in the prefix invalidates the cache. Treat the prefix as immutable; pass dynamic content as the user message, not in the prefix.
Lever 7: Batched offline evals
OpenAI Batch API and Anthropic Message Batches ship completions at 50 percent of the synchronous rate with up to 24-hour latency. Three workloads benefit:
- Nightly eval sweeps. Latency-tolerant. Run as a batch job; save 50 percent.
- Dataset judges. Score the entire dataset overnight; save 50 percent.
- Synthetic data generation. Generate test cases overnight; save 50 percent.
Synchronous workloads (online scoring, user-facing chat) cannot use the batch API. Reserve it for the latency-tolerant work.
Lever 8: Per-route token budgets at the gateway
The cheapest insurance is a hard budget per route. The gateway returns a 429 or routes to a fallback model when the budget is burned.
# Example gateway policy
routes:
- name: chat
daily_budget_tokens: 10000000
hourly_budget_tokens: 500000
fallback: gpt-5-nano
- name: refund_agent
daily_budget_tokens: 5000000
hourly_budget_tokens: 250000
fallback: 429
- name: faq_bot
daily_budget_tokens: 2000000
fallback: cache_onlyWithout per-route budgets, a single buggy retry loop can burn through the monthly spend before the on-call paged. With them, the worst case is a route degrades to a smaller model or a cache hit; the bill stays in bounds.
Tools that ship per-route or equivalent budgets in 2026: FutureAGI Agent Command Center supports per-org, per-key, per-user, and per-model budgets, plus rate limits per key and per virtual key. Portkey supports per-virtual-key budgets and rate limits. LiteLLM proxy supports per-key spend caps. Cloudflare AI Gateway supports per-gateway rate limits and per-model caps. Map your routes to one of these dimensions; pure per-route token budgets are easiest in LiteLLM team configurations or via a virtual-key per route.
How to pull the levers in order
- Wire per-route budgets first. Floor-level cost hygiene. Even if the spend is reasonable now, you want budgets in place before any of the other levers fail.
- Calibrate distilled judges, then swap. Single biggest cut. Run the calibration set; ship when kappa is within 0.05 of frontier.
- Set retention tiers per workload. Quick policy change. 10-20 percent cut.
- Configure tail-based sampling per route. Two days of OTel collector work. 15-30 percent cut.
- Enable provider prompt caching. SDK config change. 30-60 percent input-token cut on long-prefix routes.
- Add semantic cache on repetitive routes. Two weeks. 20-40 percent cut on cacheable routes.
- Eval-gated routing to smaller default. Two-week reproduction. 30-50 percent cut where applicable.
- Move offline evals to the batch API. One-week migration. 50 percent cut on the eval pipeline.
The order matters. Per-route budgets are insurance; pull first. Distilled judges are the biggest cut; pull second. The rest compounds.
Common mistakes when cutting LLMOps cost
- Cutting without calibration. A judge swap without kappa-vs-human is quality regression dressed as cost savings.
- Sampling everything globally. Per-route policies always beat global rates.
- Cache TTL too long. Stale answers leak; pick the TTL that matches the route’s freshness needs.
- Skipping per-route budgets. A single retry loop can detonate the bill before you see it.
- Subscription bargaining. Subscription is the smallest line item. Optimize the variable cost first.
- Frontier-only judges in CI. CI eval can be batched. Save the synchronous quota for online scoring.
- No cost dashboard. Without a per-route per-day cost line, you cannot prioritize. Build it before you optimize.
- Optimizing the wrong workload. Re-rank levers per workload; what saves 50 percent on a FAQ bot saves 5 percent on a refund agent.
Recent llmops cost updates
| Date | Event | Why it matters |
|---|---|---|
| 2026 | Galileo Luna 2 distilled judges hit production | Distilled judge price floor dropped further. |
| 2026 | OpenAI Batch API at 50 percent off | Offline workloads cut by half on sync price. |
| 2026 | Anthropic prompt caching | Long-prefix workloads cheaper after the write. |
| Mar 2026 | FutureAGI shipped Agent Command Center | Per-org, per-key, per-user, and per-model budgets and gateway routing landed in one platform. |
| 2026 | text-embedding-3 family | Embedding cost dropped to under $0.10 per 1M tokens, semantic cache became cheaper to run. |
Sources
- OpenAI prompt caching
- OpenAI Batch API
- Anthropic prompt caching
- Anthropic Message Batches
- Google Vertex context caching
- OpenTelemetry tail sampling processor
- GPTCache
- Galileo research
- Patronus Lynx 70B on Hugging Face
- LiteLLM proxy
- Portkey
- Cloudflare AI Gateway
Series cross-link
Read next: Best LLM Cost Tracking Tools 2026, LLM Cost Tracking Best Practices, LLM Observability Platform Buyer’s Guide 2026
Related reading
Frequently asked questions
What drives LLMOps cost in 2026?
What's the single highest-leverage cost cut?
Should I sample traces, and at what rate?
How long should I retain traces?
What's the role of semantic cache in LLMOps cost?
Should I move from frontier models to smaller defaults?
What's prompt caching, and how much does it save?
How do I prevent runaway LLMOps spend?

FutureAGI, Langfuse, MLflow, W&B Weave, Comet, Braintrust, LangSmith for LLMOps in 2026. Pricing, OSS license, and what each platform won't do end-to-end.

Instrument cost-per-call, cost-per-route, cost-per-user. Then optimize via routing, caching, smaller judges, and early termination. The 2026 cost playbook.

LangChain explained for 2026: what changed in v1, how LangGraph fits in, the real anatomy of the framework, production tradeoffs, and common mistakes.