Custom LLM Eval Metrics in 2026: When and How to Build Your Own
When stock metrics fail: building domain-specific LLM evals. Rubric, judge, and deterministic patterns with code for DeepEval, Phoenix, and FutureAGI.
Table of Contents
Hypothetical scenario: a medical-question agent passes the team’s faithfulness and refusal-rate gates. The team ships. Within a week, a regulatory review flags a batch of outputs as containing unverified claims about drug interactions. The faithfulness rubric scored on whether the output stayed within the retrieved context; the retrieved context contained the claims; the claims were technically grounded. The faithfulness metric was right; the metric was the wrong question. The team builds a custom metric: a deterministic check that every numeric drug-interaction claim cites a row id from the FDA label database, plus a rubric that scores whether the claim modality (always, sometimes, contraindicated) matches the cited row. The composite metric surfaces the failure class the faithfulness gate missed.
This is what custom LLM eval metrics are for in 2026. Stock metrics cover the common failure modes; the workloads that ship to regulated, high-stakes, or domain-specific use cases hit failure modes the stock library does not encode. This guide covers when to reach for a custom metric, the three patterns (deterministic, rubric, composite), the anatomy of a calibrating rubric, the calibration discipline that keeps custom judges from becoming a vibes detector, the bias surface judges introduce, multi-dimensional scoring, cost-aware sampling at scale, three worked examples (brand voice, code review, medical claim verification), the production failure modes of custom metrics themselves, and the major frameworks (FutureAGI custom evaluators, DeepEval, Phoenix evals, Galileo custom metrics).
TL;DR: When to reach for a custom metric
| Symptom | Likely cause | Fix |
|---|---|---|
| Stock scores high, workload breaking | Failure mode not encoded in stock metric | Build a domain-specific metric |
| Multi-dim quality, one score | Aggregate hides per-dim regressions | Per-dimension scoring |
| Judge calibration unstable | Free-text grade prompt | Switch to G-Eval form-filling |
| Regulatory or business rule | Cannot trust a single judge call | Composite: deterministic + rubric |
| Score does not gate CI | Dashboard without control | Wire as a CI eval gate |
| Eval cost growing faster than traffic | 100% sampling on a frontier judge | Tiered sampling: deterministic + distilled + frontier |
| Kappa drifts week over week | Provider model update or rubric drift | Pin model version, source-control rubric |
If you only read one row: custom metrics are needed when stock metrics return green and the workload is still broken. The metric exists to catch the failure mode the team has already paid for once.
When stock metrics fail
Stock metrics from the major eval libraries (FutureAGI, DeepEval, Ragas, Phoenix, Promptfoo) cover the common surfaces:
- Faithfulness (output grounded in retrieved context).
- Answer relevance (output addresses the user’s question).
- Context relevance / precision / recall (retriever surfaced the right chunks).
- BLEU / ROUGE / BERTScore (translation, summarization, generic NLP).
- Toxicity / bias / refusal calibration (behavioural).
- Schema validation, exact match, regex (structural).
- Tool-call accuracy, plan adherence, step efficiency (agents).
These cover a wide surface. They miss three classes of failure:
Domain-specific correctness. Medical-claim verification, legal-citation accuracy, financial-rule compliance. Stock metrics do not encode the domain.
Multi-step structural consistency. Whether the agent’s reasoning chain is internally consistent, whether numeric values are reused correctly across steps, whether citations resolve to the corpus.
Business-defined quality. Brand-voice match, persona consistency, regulatory tone, customer-tier-appropriate response. Stock metrics do not encode the brand.
When stock metrics return high scores and the workload is still breaking, the metric is the wrong question. Build the right one.
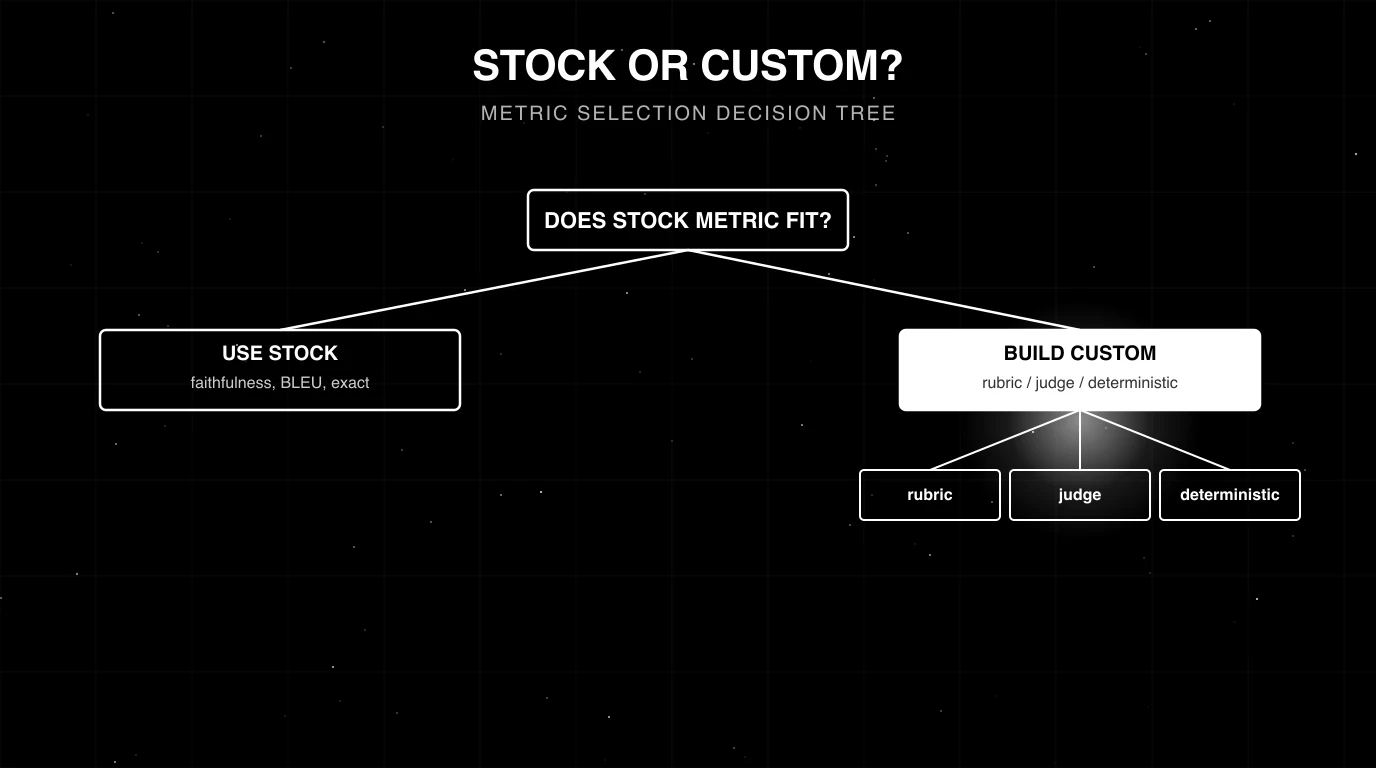
The three patterns for custom metrics
Deterministic
Regex, parser, schema validator, exact match against a domain-specific contract. Zero variance, near-zero cost.
Examples:
- Every numeric claim must include a citation in the form
[doc:N#row:M]. - Every refund response must mention
policy version 2026-01. - Every code answer must include a runnable test block.
- Every multi-step reasoning chain must reference the same numeric values consistently across steps.
Deterministic metrics are the cheapest and the most reliable; reach for them first.
Rubric (LLM-as-judge)
A prompt that scores the output against a written rubric. The rubric defines the criterion, the scale, and the failure conditions. The judge model returns a score and a reason.
Pattern:
# FutureAGI rubric pattern (local CustomLLMJudge). tested 2026-05-09
# pip install ai-evaluation
from fi.opt.base import Evaluator
from fi.opt.datamappers import BasicDataMapper
from fi.evals.llm import LiteLLMProvider
from fi.evals.metrics import CustomLLMJudge
provider = LiteLLMProvider()
medical_claim_judge = CustomLLMJudge(
provider,
config={
"name": "MedicalClaimVerification",
"grading_criteria": (
"Identify every numeric drug-interaction claim in the response. "
"Score 0 if any claim is missing a citation to the context. "
"Score 0.5 if any modality (always, sometimes, contraindicated) "
"does not match the cited row. Score 1.0 otherwise."
),
},
model="openai/gpt-5-mini",
temperature=0.2,
)
evaluator = Evaluator(metric=medical_claim_judge)
data_mapper = BasicDataMapper(key_map={
"query": "query",
"response": "response",
"context": "context",
})
# Use the evaluator with your dataset / optimizer per the FutureAGI docs:
# https://docs.futureagi.com/docs/cookbook/eval-metrics-optimization/
# Pair the score with a threshold (e.g., 0.9 for high-stakes workloads).The G-Eval form-filling pattern (Liu et al. 2023, G-EVAL: NLG Evaluation using GPT-4) combines chain-of-thought with structured form-filling and reports stronger correlation with human judgments on NLG tasks than free-text grading. FutureAGI’s fi.evals exposes the same rubric-and-step shape through CustomLLMJudge, with a turing_flash cloud judge for low-latency production scoring; DeepEval, Phoenix, and Galileo expose equivalent rubric-style judge evaluators via their custom-evaluator surfaces.
Composite
Deterministic checks plus judge calls plus domain logic, combined into a single pass/fail. Composite metrics are common when a workload combines structural and semantic requirements.
Pattern:
# tested 2026-05-09
def medical_claim_composite(test_case):
# 1. deterministic: every claim has a citation
if not all_claims_have_citations(test_case.actual_output):
return {"score": 0, "reason": "missing citation"}
# 2. database: every cited row exists in FDA label DB
if not all_citations_resolve(test_case.actual_output):
return {"score": 0, "reason": "broken citation"}
# 3. judge: modality matches citation
judge_result = run_modality_judge(test_case)
return judge_resultThe composite short-circuits on cheap checks (deterministic, then DB lookup, then judge), keeping per-row cost bounded. Reorder by cost ascending.
Anatomy of a rubric that calibrates
A rubric is not a paragraph that describes “what good looks like”. A rubric is a structured prompt that produces a score with low variance across runs and high agreement with human raters. The shape that calibrates well in 2026 is consistent across DeepEval’s GEval, FutureAGI’s CustomLLMJudge and custom_eval surface, Phoenix’s classifier evaluators, and most internal eval stacks: criterion, anchored scale, few-shot examples, output schema, bias guards.
Criterion phrasing: specific beats general
A general criterion produces noisy scores because the judge resolves ambiguity differently each call. A specific criterion produces tight scores because the judge is choosing between defined behaviors.
Bad rubric (vague, judge guesses):
Score the response on helpfulness from 1 to 5.Good rubric (specific, judge decides):
Score the response on whether it directly answers the user's question
in the first sentence, without restating the question, without hedging
words ("might", "perhaps"), and without asking a clarifying question
when the user's intent is unambiguous.The good rubric collapses three observable behaviors (first-sentence answer, no restatement, no hedging) into one judgment. The “1 to 5 helpfulness” rubric is the most common cause of low judge-versus-human kappa in calibration sweeps, because the judge has to invent the criterion on every call. Specific, behavior-anchored phrasing is the easiest single change that lifts kappa.
Anchored descriptors at each scale point
Free-form scales (“rate 1 to 5”) leak structure to the judge. Anchored scales lock each level to a concrete behavior.
Anchored scale (good):
1 = response does not address the user's question at all
2 = response addresses the question but contains a factual error
3 = response addresses the question correctly but buries the answer
after multiple paragraphs of restatement or hedging
4 = response answers correctly in the first paragraph but contains
one minor digression
5 = response answers correctly in the first sentence with no
digression, hedging, or restatementAnchored scales are a practical rubric-design recommendation; teams typically report tighter agreement when each scale point has an explicit behavioral descriptor. The judge stops guessing what “3” means and starts pattern-matching the anchor. The exact lift varies by rubric and judge; treat it as an internal calibration check, not a fixed delta.
Scale length: 3, 5, 7, or continuous
Pick scale length based on calibration results, not folklore. Practical guidance:
- Binary (pass / fail) is correct for compliance gates: PII present, citation missing, schema invalid. Binary tends to maximize kappa because there’s no middle ground to interpret. Use it for any rule with a regulatory or contractual answer.
- 3-point can lose useful resolution: a “middling” score absorbs both “small problem” and “borderline pass”. Use only when the rubric truly has three states.
- 5-point is a common sweet spot for semantic quality. Each anchor maps to a recognisable behavior, and the middle point is “addresses the question, has one issue”.
- 7-point is often over-resolved for LLM judges; agreement tends to drop because the judge can’t reliably distinguish 4 from 5 or 5 from 6. Use only if calibration runs justify the extra resolution.
- Continuous (0.0 to 1.0) works only when the judge is given a structural rule for picking the value (e.g., “fraction of claims with a valid citation”). Otherwise it collapses to “guess a number near 0.7”.
Pick the smallest scale that captures the decision you need to make and validate it against your golden set.
Few-shot examples per scale point
A rubric without examples is a rubric where the judge interpolates from training data. A rubric with one to three anchored examples per scale point pins the judge to your distribution.
Examples for score = 5:
Q: "What's your refund policy?"
A: "We refund within 30 days of purchase. Email support@x.com to start."
Why: first-sentence answer, no hedging, no restatement.
Examples for score = 2:
Q: "What's your refund policy?"
A: "Refunds are typically possible within 30 days but it depends on the item type."
Why: addresses the question but the hedge ("typically", "depends") is a factual softening that the rubric scores as an error.Few-shot examples per anchor are a standard rubric-design practice; teams typically see tighter agreement once each scale point has a worked example. The cost is rubric length, which compounds with judge bias on long rubrics (covered below). One to three examples per anchor is a practical cap before length effects start to dominate.
Position-bias and verbosity-bias guards in the rubric
The rubric should not telegraph “the right answer”. Common leaks:
- Mentioning “the first response” or “option A” in pairwise: position bias.
- Giving the longer answer the higher anchor: verbosity bias.
- Using the user’s exact phrasing as the gold-standard answer: sycophancy bias.
Bake the guard into the rubric:
Do not reward longer responses. A correct one-sentence answer scores
the same as a correct multi-paragraph answer. Score on directness
of answer to the question, not on length, formatting, or apparent
effort.A line like that consistently reduces length-correlated bias on judges that haven’t been fine-tuned on length-corrected data.
Output format: structured form-filling
A free-text grade (“the response is mostly good, I’d give it a 4”) is harder to parse, harder to calibrate, and produces higher variance. A structured form fixes all three.
Output JSON only:
{
"criterion": "<short restatement of what is being scored>",
"reasoning": "<2-3 sentence justification quoting the response>",
"score": <integer 1-5>
}This is the G-Eval form-filling shape (Liu et al. 2023). Combined with response_format=json_object on OpenAI-class judges or strict JSON mode on Anthropic-class judges, structured form-filling improves parse reliability and tends to reduce score variance compared with free-text grading. The reasoning field also doubles as audit data: when a metric drifts, the reasoning tells you whether the rubric or the judge model is the cause.
Calibration: from rubric to trustworthy gate
A rubric without calibration is an uncalibrated subjective scorer with a JSON schema. Calibration is the discipline that turns a rubric into a metric you can put on a CI gate. The 2026 standard is: stratified golden set, multi-rater human labels, Cohen’s kappa against the judge, threshold based on Landis & Koch (1977), rolling-window drift monitoring, and re-calibration on triggers.
Golden set construction: stratified, balanced, n = 200 to 500
A golden set is the labeled corpus you use to score the judge. It needs to span the failure modes you want to catch, in roughly the proportions the production traffic will hit them.
Targets:
- Size: size the labeled set to the expected effect size, class balance, and confidence interval you need. Start with a pilot labeled set, then expand based on per-stratum variance and risk tolerance; high-stakes rules (compliance, medical, legal) typically need a larger sample than coarse 5-point Likert grades.
- Stratification: cover every failure mode often enough to estimate per-mode kappa with reasonable confidence. If you stratify across 5 modes, balance failure-tail and pass-tail counts.
- Cohort balance: if production traffic spans 4 customer tiers, the golden set should include all 4 in roughly the production mix.
- Difficulty balance: include easy positives, easy negatives, and edge cases. Edge cases are where kappa drops; include enough to measure that drop.
A stratified-sampling pattern in Python:
# tested 2026-05-09
import random
from collections import defaultdict
def stratified_golden_set(traces, n_per_stratum=40):
"""Build a balanced golden set across failure-mode strata.
traces: list of dicts with keys 'failure_mode', 'cohort', 'text'.
Returns: a list of selected traces, balanced across modes and cohorts.
"""
by_mode = defaultdict(list)
for t in traces:
by_mode[t["failure_mode"]].append(t)
selected = []
for mode, items in by_mode.items():
# within each mode, balance across cohorts
by_cohort = defaultdict(list)
for it in items:
by_cohort[it["cohort"]].append(it)
per_cohort = max(1, n_per_stratum // max(1, len(by_cohort)))
for cohort_items in by_cohort.values():
random.shuffle(cohort_items)
selected.extend(cohort_items[:per_cohort])
return selectedThe pattern: bucket by failure mode, then balance cohorts inside each bucket. This avoids the common trap where 80% of the golden set is one cohort and the kappa hides per-cohort drift.
Inter-annotator agreement: label with 2 to 3 humans
Before treating any human label as ground truth, label every item with at least two humans (three for high-stakes domains). Then:
- Compute IAA (Cohen’s kappa between the two human labelers, or Fleiss’ kappa for three).
- Drop items where the humans disagree by more than one scale point.
- For items with one-point disagreement, resolve via a third labeler or by majority.
Why: a judge cannot exceed the kappa ceiling set by inter-annotator agreement. If your two humans agree at kappa 0.55, the judge will not exceed 0.55 against the merged labels in any reliable way; chasing a higher number means overfitting to one labeler’s bias.
If IAA is below 0.5, the rubric itself is ambiguous. Rewrite the rubric and re-label, before going anywhere near the judge.
Cohen’s kappa against the judge
Once the human labels are clean, score the judge on the same set and compute Cohen’s kappa.
# tested 2026-05-09
# pip install ai-evaluation scikit-learn
from fi.opt.base import Evaluator
from fi.evals.llm import LiteLLMProvider
from fi.evals.metrics import CustomLLMJudge
from sklearn.metrics import cohen_kappa_score
provider = LiteLLMProvider()
brand_voice_judge = CustomLLMJudge(
provider,
config={
"name": "BrandVoice",
"grading_criteria": (
"Score 5 if the response uses second-person and contains no hedging. "
"Score 3 if the response uses second-person but contains hedging. "
"Score 1 if the response is third-person and hedged."
),
},
model="openai/gpt-5-mini",
temperature=0.2,
)
evaluator = Evaluator(metric=brand_voice_judge)
def kappa_against_humans(golden_set, run_judge):
"""Score the judge against human labels and return weighted Cohen's kappa.
golden_set: list of dicts with 'inputs' and 'human_score' (1-5).
run_judge: a callable you provide that runs `evaluator` on a row's
inputs (per the FutureAGI cookbook) and returns an int score.
"""
judge_scores = [run_judge(item["inputs"]) for item in golden_set]
human_scores = [item["human_score"] for item in golden_set]
return cohen_kappa_score(human_scores, judge_scores, weights="quadratic")Use weighted kappa (quadratic) for ordinal scales: a 5-vs-1 disagreement counts more than a 5-vs-4 disagreement. For binary scales, unweighted kappa is the right choice.
Calibration thresholds (Landis & Koch 1977)
The kappa-to-trust mapping the field uses, lifted from Landis & Koch’s 1977 biometrics paper:
| Cohen’s kappa | Landis & Koch label | What you can do with the metric |
|---|---|---|
| < 0.0 | Worse than chance | Rubric is broken; rewrite |
| 0.0 to 0.20 | Slight | Unusable; debug rubric and judge |
| 0.21 to 0.40 | Fair | Unusable for any decision |
| 0.41 to 0.60 | Moderate | Directional only; trend reports, not gates |
| 0.61 to 0.80 | Substantial | Production gate with periodic human spot-check |
| 0.81 to 1.00 | Almost perfect | Automation-grade; can run unattended |
Landis & Koch labels these bands but does not prescribe CI/automation policy. Two team-policy thresholds we use as a starting rule of thumb:
- Kappa >= 0.6 (substantial agreement) as the floor for putting the metric on a CI gate. Below that, the false-fail rate tends to make the gate noise.
- Kappa >= 0.8 (almost-perfect agreement) as the floor for automating any decision (auto-approve, auto-block, automated remediation). Below that, keep a human in the loop.
Both cutoffs are operational policy, not statistical results. Tune them to your traffic and risk tolerance.
Drift detection: rolling-window kappa
Calibration is a one-time number; drift is what happens to it. Track rolling-window kappa on a regular cadence: sample enough fresh labeled production traces per window to estimate kappa with your desired confidence (tune the window size to your traffic volume and the variance of your baseline), score the judge, compute kappa, and alert when it drops far enough below the calibration baseline to matter for your business risk.
# tested 2026-05-09
# pip install scikit-learn
from collections import deque
from sklearn.metrics import cohen_kappa_score
class RollingKappa:
"""Track rolling-window weighted kappa over recent labeled batches."""
def __init__(self, window=8, alert_threshold=0.6):
self.window = window
self.alert_threshold = alert_threshold
self.batches = deque(maxlen=window)
def add_batch(self, human_scores, judge_scores):
k = cohen_kappa_score(human_scores, judge_scores, weights="quadratic")
self.batches.append(k)
return k
def rolling(self):
if not self.batches:
return None
return sum(self.batches) / len(self.batches)
def should_alert(self):
r = self.rolling()
return r is not None and r < self.alert_thresholdWire the alert into the same channel as production incidents. A judge that silently drifts well below its calibration baseline is the same class of failure as a model accuracy regression in production.
Retraining trigger: when to re-calibrate
Re-calibrate promptly (a one-week SLA is a reasonable internal target) when any of the following changes:
- The judge model is updated by the provider (e.g., GPT-5 silently rolls a new snapshot; Anthropic releases a Claude minor version).
- The rubric is edited (any wording change to a criterion or anchor).
- The production distribution shifts (new feature, new persona, new cohort, prompt revision in the production model).
- Rolling-window kappa drops meaningfully below baseline for two or more consecutive windows. Set the exact alert delta against your historical variance.
The cost of re-calibration is small; the cost of a metric that silently drifted to fair-agreement kappa for a quarter is a release that shipped on green dashboards and broke production.
Judge biases and how to neutralize them
LLM judges introduce a bias surface that human labelers don’t. The 2023 to 2025 literature has named the major biases; the rubric design and scoring pipeline can neutralize most of them.
Position bias (Wang et al. 2023)
In pairwise comparisons, the judge tends to prefer the option presented first or last. Wang et al. 2023 (Large Language Models are not Fair Evaluators) showed a measurable preference swing on the same pair when the order is flipped, with the magnitude varying by judge model and prompt format.
Mitigation: randomize position and aggregate. For every pairwise call, run twice with opposite orderings and average the score. This mitigates position bias at the cost of extra judge calls (the per-pair cost roughly doubles).
# tested 2026-05-09
import random
def debiased_pairwise(judge_fn, response_a, response_b):
"""Run a pairwise judge twice with positions flipped, return averaged score."""
score_ab = judge_fn(option_1=response_a, option_2=response_b)
score_ba = judge_fn(option_1=response_b, option_2=response_a)
# invert score_ba so both refer to "preference for A"
return (score_ab + (1.0 - score_ba)) / 2.0For non-pairwise scoring, position bias is usually irrelevant; the metric scores a single response on its own merits.
Verbosity bias (Saito et al. 2023)
Judges can reward longer responses even when length isn’t a quality criterion. Saito et al. 2023 (Verbosity Bias in Preference Labeling by Large Language Models) found that GPT-4 preferred longer answers more than humans in their setting.
Mitigations:
- Bake “do not reward length” into the rubric (the line shown in the anatomy section).
- Normalize scores by length quartile during analysis: bucket responses by length, check that each bucket has the same mean score on a held-out balanced set.
- For high-stakes metrics, include a length-balanced subset in the calibration golden set so the kappa explicitly measures length-robustness.
Familiarity and rating-distribution bias (Stureborg et al. 2024)
LLM judges show systematic distributional biases. Stureborg et al. 2024 (Large Language Models are Inconsistent and Biased Evaluators) report familiarity bias toward lower-perplexity (more “fluent-looking”) text, skewed and biased rating distributions, anchoring effects, and prompt sensitivity that produces low inter-sample agreement.
Mitigation: cross-family judging plus prompt-sensitivity checks. If the production model is GPT-5, also run a Claude or Gemini judge on the same items; if the production model is Claude, also run GPT-5 or Llama. For multi-vendor production stacks, run two judges from different families and require agreement, or rotate the judge model on a schedule. Re-run the calibration set with small prompt variations to surface anchoring or prompt-sensitivity effects.
Sycophancy
Judges agree with leading phrasing in the prompt. If the rubric says “the response should be helpful and the example below is helpful, score it accordingly”, the judge will rationalize a high score regardless of the response.
Mitigation: write rubrics that don’t telegraph the expected answer. State the criterion in neutral form. Show calibration examples that span all scale points (not just the “good” pole). Test the rubric by feeding deliberately-bad inputs and checking the judge correctly assigns a low score.
Calibration leak
If the judge sees a few-shot example similar to the test case, kappa rises artificially because the judge is pattern-matching the example rather than applying the rubric.
Mitigation: hold out the calibration set. Never include calibration examples in the rubric’s few-shot block. Never fine-tune the judge on the calibration set. Keep a 20% hold-out from the golden set that is never shown to the judge in any context, and re-test against it quarterly.
Length-of-rubric bias
Longer rubrics tend to produce noisier judges; the judge’s attention spreads thin and agreement starts to decay as the rubric grows.
Mitigation: keep each rubric concise and measure agreement and latency as rubric length changes. If the criterion is genuinely multi-dimensional, don’t stuff it into one rubric: chain into multiple metrics, one per dimension, and aggregate.
Format bias
Judges over-reward responses that match a specific format (JSON, bullet lists, markdown headers) even when the rubric isn’t about format. The judge picks up “structured-looking” as a proxy for “high-quality”.
Mitigation: separate format compliance into its own dimension. If you care about both content and format, run two metrics: a content rubric that explicitly says “do not consider format”, and a format check that’s deterministic (regex on the JSON schema or markdown structure). Don’t let one rubric carry both signals.
Bias mitigation summary
| Bias | Mitigation | Cost |
|---|---|---|
| Position | Randomize and average pairwise | 2x judge calls per pair |
| Verbosity | Length-neutral rubric line + length-balanced calibration | None at runtime |
| Familiarity / rating-distribution | Prompt-sensitivity checks, calibrated evaluator recipes | Extra calibration runs |
| Sycophancy | Neutral rubric phrasing, balanced examples | Rubric-design time |
| Calibration leak | Hold-out 20%, no fine-tune on golden set | None |
| Long rubric | Keep rubric concise; chain dims when multi-criterion | More metrics to maintain |
| Format | Separate format from content metric | One extra metric |
When one score isn’t enough
Aggregating multi-dimensional quality into a single scalar is the most common way teams ship a metric that looks calibrated but hides regressions. A response can be on-brand and factually wrong; a code answer can pass tests and import a deprecated library; a medical claim can have valid citations and mismatch the modality. The scalar averages over the failure.
The case for multi-dimensional scoring
Independent dimensions move independently in production. If brand-voice scores stay flat while factual-accuracy drops 15 points, the aggregate barely budges, and the alert never fires. Per-dimension scoring fires the alert on the dimension that moved.
The rule of thumb: if two dimensions can plausibly move in opposite directions across a release, score them separately. Brand-voice and factuality move opposite when the team tunes for warmth and loses precision. Step-efficiency and task-completion move opposite when the agent is rewarded for shorter chains. Score them separately.
The case against (it has a real cost)
Each dimension is its own rubric, its own golden set, its own kappa, its own drift surface. A 5-dim metric is 5x the calibration cost and 5x the surface for drift. Don’t over-decompose.
The decision rule:
- Separate metrics when the dimensions can move independently in production data (they do, in your traces).
- Composite scalar when the dimensions always co-vary on real traces (raising one raises the other; you’ve never seen them diverge).
- Aggregated alert, separate scoring as a middle ground: keep per-dim scores in the dashboard but trip the gate on a single combined rule.
Implementation: per-dimension score dict
The shape that scales:
# tested 2026-05-09
from fi.opt.base import Evaluator
from fi.evals.llm import LiteLLMProvider
from fi.evals.metrics import CustomLLMJudge
provider = LiteLLMProvider()
def make_judge(name, criteria):
return CustomLLMJudge(
provider,
config={"name": name, "grading_criteria": criteria},
model="openai/gpt-5-mini",
temperature=0.2,
)
brand_voice = make_judge(
"BrandVoice",
"Score 1-5 on second-person addressing and absence of hedging.",
)
factuality = make_judge(
"Factuality",
"Score 1-5 on whether claims are supported by retrieved context.",
)
helpfulness = make_judge(
"Helpfulness",
"Score 1-5 on whether the response answers the user's question.",
)
# One Evaluator per dimension. Wire each to your dataset / span path
# per the FutureAGI cookbook:
# https://docs.futureagi.com/docs/cookbook/eval-metrics-optimization/
brand_voice_evaluator = Evaluator(metric=brand_voice)
factuality_evaluator = Evaluator(metric=factuality)
helpfulness_evaluator = Evaluator(metric=helpfulness)
def score_response(query, response, context, run_evaluator):
"""Return a per-dim score dict, not a scalar.
run_evaluator(evaluator, inputs) is your wrapper that runs an
Evaluator on a single row (per the cookbook examples) and returns
a numeric score.
"""
inputs = {"query": query, "response": response, "context": context}
return {
"BrandVoice": run_evaluator(brand_voice_evaluator, inputs),
"Factuality": run_evaluator(factuality_evaluator, inputs),
"Helpfulness": run_evaluator(helpfulness_evaluator, inputs),
}The dict surfaces the dim-level signal in the trace; the dashboard plots per-dim time series; the alert fires on the dim that moved.
Aggregation for gates: min vs weighted average
Two patterns for collapsing the dict to a pass / fail decision:
Pattern 1: any-fails-all-fails (min). Use when every dimension is a hard requirement. If any dim drops below its threshold, the gate fails.
# tested 2026-05-09
def gate_min(scores, thresholds):
"""Pass only if every dim meets its threshold."""
return all(scores[k] >= thresholds[k] for k in thresholds)This is the right gate for compliance metrics: PII present is a fail regardless of helpfulness.
Pattern 2: weighted average. Use when dimensions trade off and the business has a defensible weighting.
# tested 2026-05-09
def gate_weighted(scores, weights, threshold):
"""Pass if the weighted average crosses threshold."""
total_w = sum(weights.values())
weighted = sum(scores[k] * weights[k] for k in weights) / total_w
return weighted >= thresholdUse weighted average sparingly. The weights become the metric, and the moment you change weights, the pass / fail history is no longer comparable. Document the weights, version-control them, and treat a weight change as a breaking schema change.
Cost-aware sampling: scoring 1M traces / day at production scale
A custom metric is only useful if you can afford to run it. At scale, 100% sampling on a frontier judge produces a five- or six-figure monthly eval bill that almost no team will approve. The 2026 production pattern is tiered sampling: cheap deterministic everywhere, distilled judge on a fraction, frontier judge on a smaller fraction, human review on a smaller fraction still.
The cost reality
Worked example for a 1M-trace-per-day workload at multi-dimensional scoring (illustrative; substitute current per-model prices for your judge):
- 1M traces / day x 5 dimensions per trace (a typical multi-dim setup: faithfulness, helpfulness, brand voice, format, safety) = 5M judge calls / day.
- Average input length per call: 1,000 tokens (rubric + user query + response + retrieved context). Total input: 5 billion tokens / day. Output is small (a JSON form), assume 200 tokens per call = 1 billion output tokens / day.
- Using illustrative late-2026 OpenAI-class pricing: a small judge in the GPT-4o-mini band ($0.15 / 1M input, $0.60 / 1M output) costs roughly $750 + $600 = ~$1,350 / day at 100% sampling, or ~$40K / month.
- A larger judge in the GPT-5 band ($1.25 / 1M input, $10 / 1M output) at the same coverage costs roughly $6,250 + $10,000 = ~$16K / day, or ~$480K / month.
Even the small-judge cost at 100% coverage is meaningful, and the larger-judge cost at 100% coverage is cost-prohibitive. The pattern that works at scale is tiered.
Tiered sampling
Example starting coverage rates (illustrative; tune to your traffic, cost target, and risk profile):
| Tier | Coverage (illustrative) | Judge | Per-trace cost | Use for |
|---|---|---|---|---|
| 1 | 100% | Deterministic (regex, schema, parser) | ~0 | Compliance, structural rules |
| 2 | 5 to 10% | Distilled / cloud judge (FAGI turing_flash, Galileo Luna-2) | low | Semantic rubrics at scale |
| 3 | 0.5 to 2% | Frontier judge (GPT-5, Claude 4) | high | High-stakes audits |
| 4 | 0.1 to 0.5% | Human review | very high | Calibration refresh, edge cases |
Tier 1 is mandatory for any rule that has a structural answer. Don’t pay a judge to detect a missing citation; a regex catches it for free.
Tier 2 is where most volume sits. FutureAGI documents turing_flash as a Cloud (Turing) eval model with roughly 1 to 3 second per-call latency on cloud Turing evals (sub-10ms paths exist for local scanners). It handles the bulk of scoring at a fraction of frontier cost. Local metrics run without network calls; Turing cloud evals authenticate with FI_API_KEY / FI_SECRET_KEY; BYOK applies when you run LLM-as-judge with your own provider key.
Tier 3 is the audit layer. The frontier judge runs on a stratified sample of traces that triggered tier-2 alerts plus a random control sample. Use it to validate that tier 2 is calibrated.
Tier 4 is the calibration loop. Human review at a small sampled fraction feeds the rolling-kappa monitor.
Stratified sampling biases
Random sampling is wrong for evals. A random 1% sample is dominated by the same traffic the dashboards already cover. Three biased sampling rules cover the gaps:
- Fail-bias: oversample alarms. If a trace tripped a guardrail or a rubric returned a low score, score it through tier 3 even if the random draw missed it.
- Cohort-bias: oversample VIP tenants, regulated cohorts, or new customer segments. The aggregate kappa is good; the cohort-level kappa is what blows up.
- Version-bias: oversample new prompts, new models, new tools. The release window is when the metric is most likely to drift; double the sampling rate for the first 72 hours after a deploy.
A naive uniform-random pipeline catches less of the failure tail than a stratified one at the same total sample budget. Stratification is the cheapest cost reduction available.
FAGI turing_flash math (illustrative)
A worked example using FAGI’s cloud judge for tier 2 (numbers are illustrative; substitute your own coverage and pricing):
- 1M traces / day, 10% tier-2 sampling = 100,000 judge calls / day (example coverage).
turing_flashlatency per FutureAGI’s SDK docs: Cloud Turing evals run at roughly 1 to 3 seconds per call; sub-10ms paths exist for local scanners.- AI Credits per FutureAGI pricing: the first 2K monthly AI Credits are free across plans; overage is listed at $10 per 1,000 credits. Credit consumption per call varies with input size and template depth. BYOK lets you bypass the platform credit cost and pay your LLM provider directly.
- The pattern is intended to bring per-call cost meaningfully below frontier judge pricing for routine scoring, with the full-template path used for the smaller subset that needs the deeper judge.
For tier 3 (frontier audit) at 1% sampling, 10,000 calls / day at frontier judge prices is still meaningful; that’s why tier 3 typically stays in the 0.5 to 2% range as a starting heuristic.
The pattern collapses the fully-frontier worst case to a fraction of the total. The metrics still cover the failure tail because the stratified bias rules pull alarms up into tier 3 regardless of random draw.
Building custom metrics in the major frameworks
FutureAGI
FutureAGI’s fi.evals and fi.opt packages give you the first-party path when you want custom evals attached to traceAI spans, gated through the Agent Command Center, and run on the turing_flash cloud judge in production. The library ships CustomLLMJudge (in fi.evals.metrics) for rubric-based judges, Evaluator (in fi.opt.base) as the runner that wraps a metric, the unified evaluate(...) and Turing clients in fi.evals for the cloud-eval surface, and custom_eval / simple_eval decorators plus wrappers like blocking_evaluator for code-based evaluators. Deterministic metrics are plain Python callables that compose with the same surfaces. The platform pairs with traceAI (Apache 2.0 OTel-based instrumentation) so eval scores attach to spans, and with the Agent Command Center for span-attached online evals.
Path 1: Rubric-based judge via CustomLLMJudge.
# tested 2026-05-09
# pip install ai-evaluation
from fi.opt.base import Evaluator
from fi.opt.datamappers import BasicDataMapper
from fi.evals.llm import LiteLLMProvider
from fi.evals.metrics import CustomLLMJudge
provider = LiteLLMProvider()
brand_voice_judge = CustomLLMJudge(
provider,
config={
"name": "BrandVoice",
"grading_criteria": (
"Score 5 if the response uses second-person ('you') addressing, "
"avoids hedging ('might', 'perhaps'), and matches a confident-but-friendly "
"tone. Score 1 at the opposite end. Use the 1-5 scale linearly."
),
},
model="openai/gpt-5-mini",
temperature=0.2,
)
evaluator = Evaluator(metric=brand_voice_judge)
data_mapper = BasicDataMapper(key_map={"query": "query", "response": "response"})
# Run the evaluator against a dataset / optimizer per the FutureAGI cookbook:
# https://docs.futureagi.com/docs/cookbook/eval-metrics-optimization/Path 2: Deterministic / composite scorer via a Python function.
# tested 2026-05-09
def extract_citations(text):
return [] # replace with your parser
def resolves_in_corpus(citation):
return True # replace with your DB lookup
def citation_resolution(inputs):
"""Return a 0.0-1.0 score plus a reason string."""
citations = extract_citations(inputs["response"])
unresolved = [c for c in citations if not resolves_in_corpus(c)]
passed = len(unresolved) == 0
return {
"score": 1.0 if passed else 0.0,
"reason": (
"all citations resolved"
if passed
else f"{len(unresolved)} unresolved citations"
),
}
# Wire into a CI suite or attach as a span-level evaluator.
result = citation_resolution({"response": "..."})Run offline via the FAGI CLI for CI integration; run online via span-attached scorers using the turing_flash cloud judge (FutureAGI’s SDK docs document Cloud Turing evals at roughly 1 to 3 seconds per call, with sub-10ms paths available for local scanners) for cost-efficient production scoring. The traceai-<framework> Apache 2.0 instrumentation packages emit OTel-native spans so custom eval scores nest inside the trace tree.
DeepEval
DeepEval ships a BaseMetric class to subclass for custom metrics, plus a one-line GEval API for rubric-based judging. Wire via assert_test(test_case, [your_metric]) in pytest. The OSS package is local-first, with online tracing and production evals available through Confident AI; the OSS surface alone does not include hosted span-attached scoring.
Arize Phoenix
Phoenix evaluators are LLM-judge-style or code-based. The standard pattern uses the phoenix.evals package: configure an LLM, build either an LLM classifier with ClassificationEvaluator(...) from a rubric prompt or a code-based evaluator with the @create_evaluator(...) decorator on a Python function, then run evaluate_dataframe across the traces. The OSS Phoenix UI is local-first; production scoring at scale requires Arize AX.
Galileo
Galileo’s custom metrics surface supports both code-based (Python function returning a score) and prompt-based (rubric prompt) patterns. Wire via the Galileo SDK; results surface in the Galileo UI alongside stock metrics. Pricing is volume-driven and the platform is closed-source.
Three worked examples
The patterns generalize, but the rubric, the calibration, and the threshold are domain-specific. Three examples that cover the common shapes: brand voice (semantic rubric, mid-stakes), code review (composite, mid-stakes), medical claim verification (composite, high-stakes).
Example 1: Brand voice (B2B SaaS support agent)
A B2B SaaS team wants every customer-support response to use second-person (“you”), avoid hedging (“might”, “could”, “perhaps”), and match a confident-but-friendly tone.
Rubric (anchored 5-point):
Score the response on brand-voice match.
5 = uses second-person ("you", "your") in the first sentence,
contains no hedging words ("might", "could", "perhaps", "maybe",
"possibly"), tone is direct and confident without being curt.
4 = uses second-person and lacks hedging, but tone is slightly
formal or cold (one minor digression).
3 = uses second-person but contains one hedging word OR is
third-person but otherwise direct.
2 = third-person and contains one hedge OR uses second-person
but is heavily hedged ("might possibly perhaps").
1 = third-person and heavily hedged, no direct address to the user.
Do not reward length. A correct one-sentence answer scores 5;
a long-but-hedged paragraph scores 2.
Output JSON only:
{
"criterion": "brand voice match",
"reasoning": "<2-3 sentences quoting the response>",
"score": <integer 1-5>
}Implementation (composite: deterministic short-circuit + judge):
# tested 2026-05-09
import re
from fi.opt.base import Evaluator
from fi.evals.llm import LiteLLMProvider
from fi.evals.metrics import CustomLLMJudge
def is_second_person(text):
return len(re.findall(r"\b(you|your|yours)\b", text.lower())) >= 1
def lacks_hedging(text):
hedges = re.findall(r"\b(might|could|perhaps|possibly|maybe)\b", text.lower())
return len(hedges) == 0
provider = LiteLLMProvider()
brand_voice_judge = CustomLLMJudge(
provider,
config={
"name": "BrandVoiceTone",
"grading_criteria": (
"Score 5 if direct and confident without curtness. "
"Score 3 if direct but slightly cold. "
"Score 1 if not direct."
),
},
model="openai/gpt-5-mini",
temperature=0.2,
)
brand_voice_evaluator = Evaluator(metric=brand_voice_judge)
def brand_voice_composite(inputs, run_judge):
"""run_judge(evaluator, inputs) -> (score:int, reason:str) wraps the
Evaluator per the FutureAGI cookbook."""
response = inputs["response"]
if not is_second_person(response):
return {"score": 1, "reason": "not second-person"}
if not lacks_hedging(response):
return {"score": 2, "reason": "contains hedging"}
score, reason = run_judge(brand_voice_evaluator, inputs)
return {"score": int(round(score)), "reason": reason}Calibration result (illustrative example outputs): hand-labeled n = 200, weighted Cohen’s kappa = 0.74 against two human raters with IAA = 0.81. Kappa lands in the “substantial” Landis & Koch band, which we treat as gate-eligible per team policy.
CI threshold: mean score >= 4.0 across the test suite. PR blocks if the suite mean drops below 4.0; alerts if a single test case scores below 2.
Example 2: Code review (developer-tool agent)
A code-review agent generates patch suggestions. The team needs a metric that catches: tests don’t pass, diff is unreasonably large, code is incorrect, style is wrong, or there’s a security issue.
Rubric structure: composite across deterministic (tests, diff size, files touched), structural (lint, security scan), and rubric (correctness, style).
Rubric for correctness (anchored):
Score the patch on correctness.
5 = patch correctly addresses the issue described in the PR; no
behavior change to unrelated code paths; preserves existing tests.
4 = patch addresses the issue but introduces one minor bug in an
edge case (off-by-one, null handling).
3 = patch partially addresses the issue; main path works, edge
cases broken.
2 = patch does not address the issue but does not break existing
behavior.
1 = patch breaks existing tests or introduces a regression.
Do not reward longer diffs. A 5-line correct patch scores higher
than a 200-line patch that adds defensive code beyond the issue.
Output JSON only:
{
"criterion": "patch correctness",
"reasoning": "<2-3 sentences referring to the diff and the PR description>",
"score": <integer 1-5>
}Implementation (composite):
# tested 2026-05-09
from fi.opt.base import Evaluator
from fi.evals.llm import LiteLLMProvider
from fi.evals.metrics import CustomLLMJudge
def run_test_suite(diff):
return True # replace with your CI runner
def diff_size(diff):
return len(diff.splitlines())
def files_touched(diff):
return 1 # replace with your diff parser
provider = LiteLLMProvider()
correctness_eval = Evaluator(metric=CustomLLMJudge(
provider,
config={
"name": "PatchCorrectness",
"grading_criteria": (
"Score 5 if patch correctly addresses the issue with no unrelated changes. "
"Score 3 if patch partially addresses the issue. "
"Score 1 if patch breaks existing behavior."
),
},
model="openai/gpt-5-mini",
temperature=0.2,
))
style_eval = Evaluator(metric=CustomLLMJudge(
provider,
config={
"name": "PatchStyle",
"grading_criteria": (
"Score 5 if patch follows project style. "
"Score 3 for minor style issues. "
"Score 1 if patch breaks project style conventions."
),
},
model="openai/gpt-5-mini",
temperature=0.2,
))
# Hard-fail dimensions: tests, diff size, files touched.
# Advisory dimensions: rubric correctness, rubric style.
def code_review_composite(inputs, run_judge):
"""run_judge(evaluator, inputs) -> float wraps the FutureAGI Evaluator."""
diff = inputs["diff"]
# 1. hard-fail short-circuits
if not run_test_suite(diff):
return {"hard_fail": True, "reason": "tests fail", "dim": "tests"}
if diff_size(diff) > 500:
return {"hard_fail": True, "reason": "diff too large", "dim": "size"}
if files_touched(diff) > 10:
return {"hard_fail": True, "reason": "too many files", "dim": "scope"}
# 2. advisory rubric judges (do not block on these alone)
correctness = run_judge(correctness_eval, inputs)
style = run_judge(style_eval, inputs)
return {
"hard_fail": False,
"advisory": {"correctness": correctness, "style": style},
}Calibration result (illustrative example outputs): hand-labeled n = 250 patches across three repositories, weighted kappa = 0.71 (substantial). The hard-fail short-circuits handled the majority of failures without invoking the judge.
CI threshold: the hard-fail dimensions (tests, diff size, files touched) block the PR. The advisory rubric dimensions (correctness, style) post a PR comment when they fall below 4 and route the PR to a senior reviewer; they do not block on their own. The team trusts a kappa in the substantial band enough for advisory routing but not for unattended blocking.
Example 3: Medical claim verification (healthcare RAG)
A healthcare RAG agent answers clinical questions over an FDA-label corpus. The team needs every numeric drug-interaction claim to (1) carry a citation, (2) resolve to an FDA-label row, (3) match the modality (always / sometimes / contraindicated) of the cited row.
Rubric structure: composite, with two deterministic checks before the judge. The rubric is structural enough that kappa lands high; the threshold is high because the stakes are high.
Rubric for modality match (binary):
For each numeric drug-interaction claim in the response, identify
the cited FDA-label row and the modality stated in the response.
Modality values: ALWAYS, SOMETIMES, CONTRAINDICATED.
Score 1 only if every claim's stated modality exactly matches the
modality recorded in the cited FDA-label row.
Score 0 if any claim's modality does not match, or if any claim
lacks a citation, or if any citation does not resolve.
Output JSON only:
{
"criterion": "modality match",
"reasoning": "<list each claim, its stated modality, and the row's modality>",
"score": 0 or 1
}A binary scale is correct here because the regulatory rule is binary: the modality matches or it doesn’t.
Implementation (composite, fail-fast):
# tested 2026-05-09
import re
from fi.opt.base import Evaluator
from fi.evals.llm import LiteLLMProvider
from fi.evals.metrics import CustomLLMJudge
CITATION_PATTERN = re.compile(r"\[fda:(\d+)#row:(\d+)\]")
def fda_row_lookup(doc_id, row_id):
return None # replace with your DB lookup
def all_claims_have_citations(text):
sentences = text.split(".")
for s in sentences:
if any(t in s.lower() for t in ["mg", "dose", "interaction"]):
if not CITATION_PATTERN.search(s):
return False
return True
def all_citations_resolve(text):
for m in CITATION_PATTERN.finditer(text):
if fda_row_lookup(m.group(1), m.group(2)) is None:
return False
return True
provider = LiteLLMProvider()
modality_evaluator = Evaluator(metric=CustomLLMJudge(
provider,
config={
"name": "ModalityMatch",
"grading_criteria": (
"For each numeric drug-interaction claim, extract the stated "
"modality (always, sometimes, contraindicated) and the cited "
"row's modality. Score 1 only if every modality matches; "
"score 0 otherwise."
),
},
model="openai/gpt-5-mini",
temperature=0.0,
))
def medical_claim_composite(inputs, run_judge):
"""run_judge(evaluator, inputs) -> (score:int, reason:str)."""
response = inputs["response"]
if not all_claims_have_citations(response):
return {"score": 0, "reason": "missing citation"}
if not all_citations_resolve(response):
return {"score": 0, "reason": "broken citation"}
score, reason = run_judge(modality_evaluator, inputs)
return {"score": int(round(score)), "reason": reason}Calibration result (illustrative example outputs): hand-labeled n = 300 responses across 4 drug categories, weighted kappa = 0.83. The rubric is structural (matching enum values), so the judge has very little room to drift; the kappa lands in the “almost perfect” Landis & Koch band.
CI threshold: illustrative target of 0.95 suite pass rate. For a healthcare workload, the team also keeps tier-3 frontier-judge audits on every alert and tier-4 human review on a sampled fraction.
When the metric breaks (and how to know)
Custom metrics fail in characteristic ways. The failure modes are different from production-model failures, and the monitoring pattern is different. Five failure modes worth watching, with the trigger that surfaces them and the mitigation that contains them.
Overfit to the calibration set
The judge has a high kappa offline but does nothing in production: every trace passes, no alerts fire, no regressions are caught. The rubric and the calibration golden set co-evolved until the rubric only fires on the exact failure shapes in the labeled set.
Trigger: production fail-rate is near zero; the metric never blocks anything; user-reported issues continue to land at the same rate as before the metric shipped.
Mitigation: hold out 20% of the golden set during calibration; compute kappa on the hold-out separately. Re-test against the hold-out on a regular cadence. If hold-out kappa lands meaningfully below in-sample kappa (a 0.10 gap is a reasonable internal alert as a starting heuristic), the rubric is overfit. Rewrite with broader anchors and re-calibrate.
Judge model drift
The provider updates the judge model (snapshot rolls, fine-tune update, capability shift). Calibration silently degrades because the same rubric now produces different scores on the same inputs.
Trigger: rolling-window kappa drops meaningfully below baseline over two or more consecutive windows for no apparent rubric reason. The provider’s release notes mention a model update.
Mitigation: pin the model version (e.g., gpt-5-2025-08-07 rather than the moving alias gpt-5). Treat the pinned version as part of the rubric’s source-controlled spec. When the provider deprecates, schedule a re-calibration before the deprecation date; never let a deprecation force an unplanned model change.
Rubric drift
Prompt edits accumulate. The rubric in production no longer matches the rubric the calibration was run against. The kappa number on the dashboard is lying because it was measured against a different rubric.
Trigger: rubric-source diff between calibration date and current production. Hash mismatch on the rubric file.
Mitigation: store the rubric in source control. Tag each rubric with a version. Block merges to the rubric file unless the PR includes a new calibration run with kappa above the baseline. Treat rubric edits like schema migrations.
Production distribution shift
A new feature, a new persona, a new cohort lands in production. The calibration set didn’t include traces from the new distribution. The rubric scores them, but the kappa on the new traffic is not measured.
Trigger: cosine drift on prompt embeddings between the calibration corpus and the rolling production sample. Or: a cohort-level fail-rate that diverges sharply from the aggregate.
Mitigation: track embedding drift on production prompts vs. the calibration set. Trigger a re-calibration window when embedding drift exceeds a threshold calibrated on your own baseline traffic (the right cutoff depends on the embedding model, domain, and sampling method). Pull a stratified sample from the new distribution, hand-label, re-score, and re-compute kappa.
Goodhart drift (the metric becomes the target)
Teams optimize for the metric instead of the underlying quality. Brand-voice scores rise; customer-satisfaction scores stay flat or drop. The metric is now a target, not a measure.
Trigger: metric trends upward while the downstream business outcome (CSAT, conversion, retention) doesn’t move or moves opposite.
Mitigation: pair every metric with a constraint metric that bounds the optimization. “Task completion” paired with “tool-call efficiency”: optimizing one without the other should fail the gate. “Brand voice” paired with “factuality”: warmer responses are not allowed to drop accuracy. The pair is a constraint, not a single optimization target. Goodhart’s law breaks gracefully when there are at least two metrics in mutual tension.
Operational checklist
- Hold-out 20% of golden set; quarterly re-test.
- Pin judge model version; schedule re-calibration on deprecation.
- Source-control rubric file; hash-check on every run.
- Track embedding drift on production prompts; alert on cosine shift.
- Pair every metric with a constraint metric; trip the gate on mutual movement.
Common mistakes when building custom metrics
- Reaching for a judge when a regex works. Over-engineering. Try deterministic first.
- Skipping calibration. A judge with kappa in the moderate-or-below band is an uncalibrated subjective scorer. Calibrate against a stratified hand-labeled set (200-500 is a common starting range).
- One score across multiple dimensions. A response can be on-brand but factually wrong. Score per-dimension.
- No threshold. A score with no pass/fail decision is a dashboard, not a gate.
- Re-using a judge calibrated for one domain on another. Calibration does not transfer.
- Custom metric slower than production model. A multi-second judge per row makes CI unusable. Use a low-latency cloud judge (FAGI
turing_flash, Galileo Luna-2) at the eval layer. - Hand-rolled free-text grade prompts. Generally worse alignment than the structured alternative. Use G-Eval form-filling.
- No regression suite. Custom metric catches the bug once; the next prompt regression hits the same class. Add the failure to the regression suite.
- Custom metric that depends on production state. A metric that requires a live database lookup is fragile in CI. Snapshot the dependency.
- Pinning to one judge model and forgetting it drifts. Re-calibrate when the judge updates.
- Optimizing the metric instead of the outcome. Pair every metric with a constraint metric that catches Goodhart drift.
- 100% sampling on a frontier judge. Tier sampling: deterministic everywhere, low-latency cloud judge for the bulk, frontier on alerts and audits, human on a slice.
What changed in custom LLM metrics heading into 2026
| Trend | Why it matters |
|---|---|
| DeepEval ships G-Eval as a one-line API | Custom rubric metrics moved from research to one-line library calls |
| Phoenix evals matured into an OTel-native eval framework | OTel-native eval framework with Pythonic custom metric support |
| Galileo, Braintrust, and FutureAGI all expose custom-metric SDKs | Hosted custom metrics became turnkey |
Low-latency cloud / distilled judges (Galileo Luna-2, FutureAGI turing_flash) reached production usage | Judge-based custom metrics became cost-feasible at scale |
| OTel GenAI evaluation events progressing through the spec | Custom eval scores moving toward cross-platform portability |
How to actually build a custom metric in 2026
- Identify the failure mode. What does the workload break on that the stock metric does not catch?
- Pick the pattern. Deterministic if structural; rubric if semantic; composite if both.
- Write the minimal scorer. One score, one threshold, one reason string. Keep the rubric concise and re-measure agreement and latency as it grows. Use anchored binary, 3-point, or 5-point scales depending on the decision.
- Build a stratified golden set. Stratify across failure modes and cohorts (200-500 is a common starting range; tune to your variance). Hand-label with two or three humans; drop items with disagreement above one scale point.
- Calibrate against the golden set. Compute weighted Cohen’s kappa. As a starting team policy: kappa >= 0.6 for CI gates, >= 0.8 for unattended automation. Hold out 20% for hold-out re-test.
- Wire into the eval framework. FutureAGI
Evaluator+CustomLLMJudgefor rubric judges (orcustom_eval/simple_evalwithblocking_evaluatorfor code-based evals), DeepEvalBaseMetric, Phoenix evaluator, or other. - Pin the judge model and version. Source-control the rubric file. Hash-check on every run.
- Wire as a CI gate. Min-per-dim threshold for hard requirements; weighted average for tradeoffs; document the weights.
- Wire span-attached online eval at sampled coverage. Example starting coverage: 100% deterministic, 5-10% low-latency cloud judge (FAGI
turing_flash), 0.5-2% frontier judge, 0.1-0.5% human review. Tune to your traffic and budget. - Run rolling-window kappa on a regular cadence. Alert when the rolling number drops far enough below baseline to matter for your business risk.
- Re-calibrate on a fixed cadence. And on judge-model update, rubric edit, or distribution shift detected via embedding drift.
- Pair every metric with a constraint metric. Goodhart breaks gracefully when at least two metrics constrain each other.
- Add failures to the regression suite. Compounding gates.
For depth on the broader eval surface, see What is LLM Evaluation?, LLM as Judge Best Practices, and G-Eval vs DeepEval Metrics in 2026.
Sources
- Liu et al. - G-EVAL: NLG Evaluation using GPT-4 (2023)
- Wang et al. - Large Language Models are not Fair Evaluators (2023)
- Saito et al. - Verbosity Bias in Preference Labeling by Large Language Models (2023)
- Stureborg et al. - Large Language Models are Inconsistent and Biased Evaluators (2024)
- Landis & Koch - The Measurement of Observer Agreement for Categorical Data (1977)
- DeepEval custom metrics docs
- DeepEval G-Eval docs
- Arize Phoenix evals docs
- Galileo custom metrics docs
- Promptfoo assertions docs
- FutureAGI fi.evals SDK on GitHub
- FutureAGI Agent Command Center
- OpenTelemetry GenAI semantic conventions
Series cross-link
Read next: What is LLM Evaluation?, G-Eval vs DeepEval Metrics in 2026, LLM as Judge Best Practices, Best LLM Evaluation Tools in 2026
Frequently asked questions
When do stock LLM eval metrics stop working?
What are the three patterns for custom metrics?
How do I build a custom metric in DeepEval?
How do I build a custom metric in Arize Phoenix?
What is G-Eval and when should I use it?
How do I calibrate a custom judge metric?
What does FutureAGI ship for custom metrics?
What are the common mistakes when building custom metrics?

G-Eval rubric-based LLM judges vs DeepEval's full metric suite, how they differ, and where FutureAGI Turing eval models fit alongside both in 2026.

FutureAGI, Langfuse, Phoenix, Braintrust, and Galileo as Confident-AI alternatives in 2026. Pricing, OSS license, eval depth, and gaps for production teams.

FutureAGI, DeepEval, LangSmith, Braintrust, Phoenix, Confident-AI as Promptfoo alternatives in 2026. Pricing, OSS license, CI gating, and production gaps.