Best LLMs of May 2026: Top Closed-Source, Open-Weight, Multimodal, and Coding Picks
Best LLMs May 2026: compare GPT-5.5, Claude Opus 4.7, Gemini 3.1 Pro, and DeepSeek V4 across coding, agents, multimodal, cost, and open weights.

Table of Contents
Series note. This is the May 2026 entry in our monthly best-LLMs series. New frontier models now ship weekly. We track what shipped, what won which category, and what the public leaderboards do not capture. Previous: April 2026 ←. six frontier models in 30 days, Berkeley breaks the trust. March 2026 ←←. open-weight catches closed-source on coding.
TL;DR: Best LLM per category, May 2026
| Use case | Best pick | Why | Output $/M tokens |
|---|---|---|---|
| Multi-file coding (GA) | Claude Opus 4.7 (1M context) | 87.6% SWE-bench Verified + 64.3% SWE-bench Pro (#1 on contamination-resistant Pro) | $25 |
| Coding benchmark dominance | Qwen 3.6 Max-Preview | #1 on SIX coding/agent benchmarks (closed weights) | API-only |
| Agentic terminal work | GPT-5.5 | 82.7% Terminal-Bench 2.0, default ChatGPT model | $30 |
| Multi-agent debate / hallucination resistance | Grok 4.20 Multi-Agent Beta | 78% AA-Omniscience (best ever), 4–16 agent debate, 2M context | $6 |
| Multimodal + 1M context | Gemini 3.1 Pro | 94.3% GPQA, cheapest US frontier | $10 |
| #1 AA Intelligence Index (open-weight) | Kimi K2.6 | 1.1T MoE, agentic-stable, leads AA Index for open | hosted ~$2 |
| #2 AA Index (open-weight) + cheap | DeepSeek V4-Pro | 1.6T, hybrid attention, $3.48 output | $3.48 |
| Lowest listed frontier-class API price in this snapshot | DeepSeek V4-Flash | 284B / 13B active, 1M context, $0.28 output | $0.28 |
| Largest MIT-licensed open | GLM-5.1 (754B MoE) | Briefly led SWE-bench Pro pre-Qwen Max | self-host |
| Open-weight all-around (non-Chinese) | Mistral Large 3 | 675B / 41B active, Apache 2.0, agentic-tuned | self-host |
| Open-weight long context | Llama 4 Scout | 10M-token context | self-host |
| On-device | Mistral Small 4 / Gemma 4 | 6.5B–31B active, single-GPU | self-host |
| Pure capability (restricted) | Claude Mythos Preview | 93.9% SWE-bench, Project Glasswing only | not GA |
If you only read one row: GPT-5.5 for agentic terminal work, Claude Opus 4.7 for multi-file code reasoning, Qwen 3.6 Max-Preview for raw coding-benchmark dominance, Grok 4.20 when hallucination cost is high, DeepSeek V4-Flash for absolute cheapest. Everything else is a tradeoff on those five.
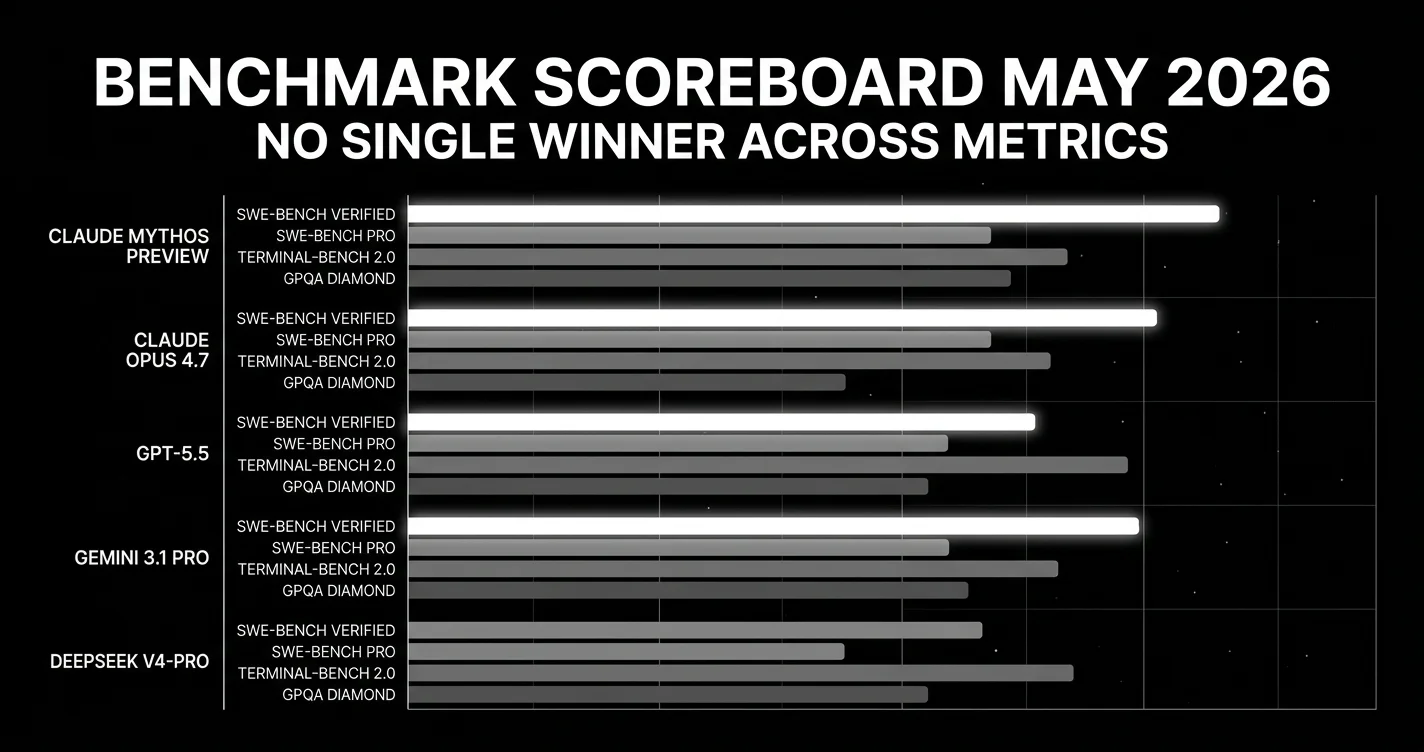
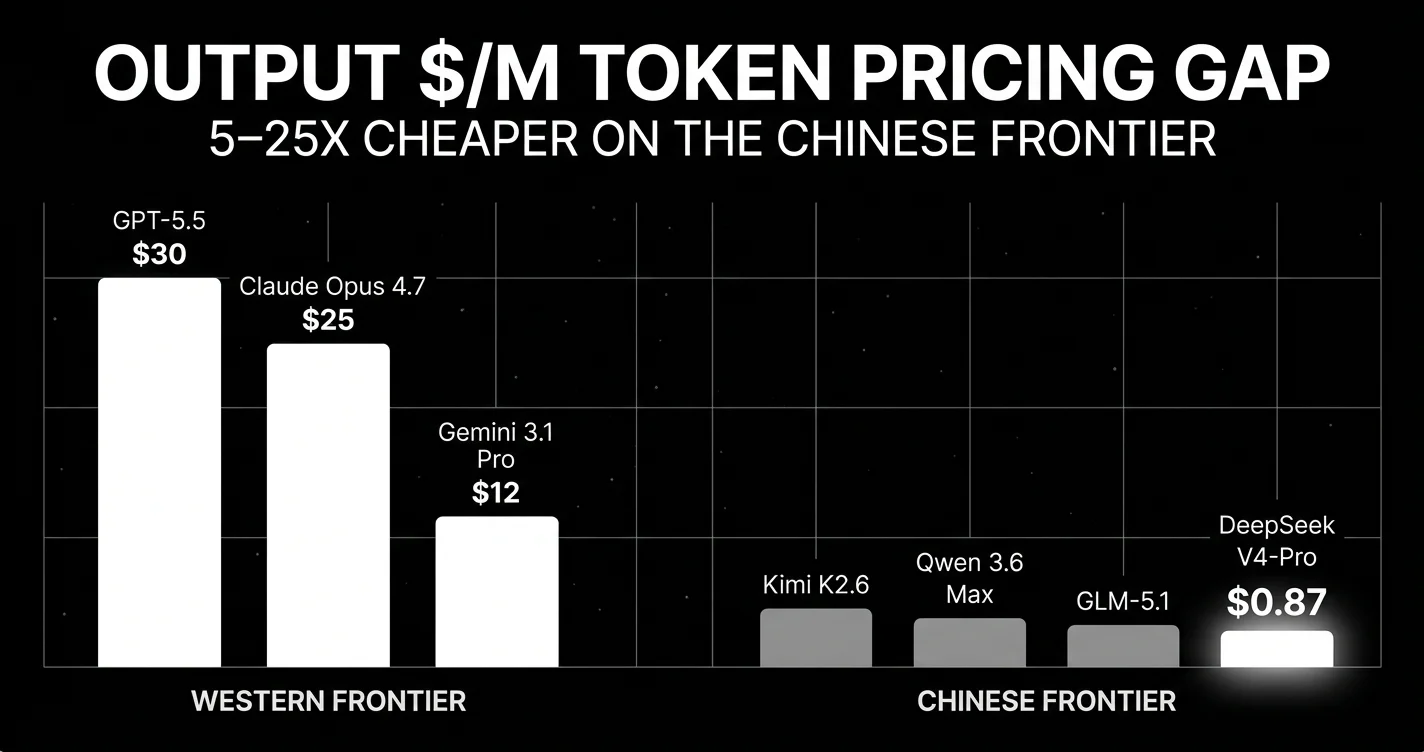
The single biggest story of late April / early May 2026: the Western/Chinese pricing gap is now 5–25× at equivalent benchmark performance, and Alibaba just closed weights on its flagship for the first time. The “open-weight Chinese, closed-weight Western” mental model from 2024–25 no longer holds.
The story of May 2026: the model layer rests, infrastructure moves
After April 2026’s deluge. nine major LLM releases in 30 days, a UC Berkeley paper that broke trust in every public agent benchmark, and DeepSeek V4 landing at roughly 34x cheaper output than GPT-5.5. May opened with no new frontier LLM in the first week. The model layer went quiet. Everything else got loud.
Distribution moved. Apple announced on May 5 that iOS 27 will let users select from multiple third-party AI models for text, editing, and image work. The first crack in the iPhone’s two-year OpenAI exclusivity. OpenAI launched an Ads Manager beta for U.S. advertisers. monetizing the ChatGPT surface itself.
The compute story doubled. OpenAI President Greg Brockman testified to the U.S. Senate that OpenAI expects to spend approximately $50 billion on infrastructure in 2026, up from $30 million in 2017. a 1,667x increase over nine years. That number is bigger than the entire 2025 venture financing for AI infrastructure combined.
Regulation tightened. The U.S. Department of Commerce expanded pre-release AI safety testing access to five major labs. Google DeepMind, Microsoft, and xAI now join Anthropic and OpenAI. Frontier release timing now has a regulatory dependency.
Architecture moved more than the model layer itself. Subquadratic launched on May 5 with $29 million in seed funding to ship SubQ. an LLM with subquadratic sparse attention and a 12-million-token context window. Standard transformer attention is O(n²) with sequence length. Subquadratic attention is the architectural prerequisite for real long-horizon agents. Whether SubQ holds up under contamination-resistant evals is the model story for June.
The takeaway from May 2026 week one: model choice alone no longer explains production outcomes. Every frontier model you would consider sits within 2-3 points of the others on public benchmarks. What separates a working production agent from a demo is the layer above the model. distribution, harness quality, cost economics, and reliability instrumentation.
Top closed-source / proprietary LLMs in May 2026
Claude Opus 4.7. Best for multi-file code reasoning
Anthropic. Released April 16, 2026. 1M context, native vision.
The strongest pick today for multi-file code reasoning. Leads SWE-bench Verified at 87.6%. second only to the restricted Mythos Preview at 93.9%. Strong on long-task agent reliability; production reports show longer sustained agent traces before reliability decay than GPT-5.5.
- 1M-token context window (standard pricing across full window, no long-context premium)
- Native vision
- Approximately $5 input / $25 output per million tokens
- Codebase Q&A, ticket-to-PR workflows, architectural reviews
What it does not win: agentic terminal work (GPT-5.5 leads by 13 points on Terminal-Bench 2.0), long context above 200K (Gemini 3.1 Pro’s 1M wins), cost-sensitive bulk (DeepSeek V4-Pro is 7x cheaper).
GPT-5.5 and GPT-5.5 Pro. Best for agentic terminal automation
OpenAI. Released April 23, 2026. Native vision and audio.
OpenAI’s flagship for agentic and tool-calling work. Headlines: 82.7% Terminal-Bench 2.0 (leader), 78.7% OSWorld-Verified, 84.9% GDPval, approximately 88.7% SWE-bench Verified, 58.6% on the contamination-resistant SWE-bench Pro.
GPT-5.5 Pro adds parallel test-time compute. running multiple reasoning chains in parallel and synthesizing the result. Posts 39.6% on FrontierMath Tier 4. External evaluators preferred GPT-5.5 Pro over GPT-5 thinking on 67.8% of real-world reasoning prompts and reported 22% fewer major errors.
GPT-5.5 Instant became the default ChatGPT model on May 5, with OpenAI’s internal evaluation reporting 52.5% fewer hallucinated claims on high-risk topics. Note: this is OpenAI-internal, not yet independently reproduced. Treat as directional.
- Approximately $5 input / $30 output per million tokens (base GPT-5.5); higher for Pro
- Native vision and audio
- Best for: agentic terminal automation, OS-level workflows, function-call-heavy applications, ChatGPT-default distribution
Gemini 3.1 Pro. Best for long-context multimodal at low cost
Google DeepMind. Released February 19, 2026. Default in API since March 6.
The cheapest US-frontier model and the only one with a true 1M-token context window in production. Leads GPQA Diamond at 94.3%. Strong multimodal. image, audio, and video understanding all at frontier quality. With Forge Code agent harness, leads Terminal-Bench 2.0 at 78.4%.
- $2 input / $12 output per million tokens (≤200K prompt; $4 input / $18 output above 200K) (lowest among US frontier labs)
- 1M-token context
- Default in API since March 6
- Best for: long-context, multimodal pipelines, cost-sensitive US-data-residency workloads
Claude Mythos Preview. Capability ceiling, but restricted access
Anthropic. Released April 7, 2026. Restricted to Project Glasswing partners.
The highest-scoring restricted model in this snapshot, based on Anthropic’s reported benchmark numbers. 93.9% SWE-bench Verified, 94.6% GPQA Diamond, 97.6% USAMO, 82.0% Terminal-Bench 2.0, 83.1% CyberGym, 100% pass@1 on Cybench (saturated), 64.7% Humanity’s Last Exam with tools.
In Anthropic’s framing: “Mythos is a new name for a new tier of model: larger and more intelligent than our Opus models. which were, until now, our most powerful.”
Not generally available. Anthropic identified thousands of zero-day vulnerabilities across every major operating system and browser using Mythos and judged the model too dangerous for public release. Access is restricted to Project Glasswing, a coalition of about 50 organizations. including Amazon Web Services, Apple, Google, Microsoft, and Nvidia. using Mythos exclusively for defensive cybersecurity work, backed by $100M in usage credits from Anthropic.
The first frontier model gated by capability rather than alignment. We include it because it sets the public ceiling and because the Glasswing precedent will recur.
Grok 4.20 Multi-Agent Beta. Best for hallucination-resistant research agents
xAI. Released March 9, 2026. 4–16 parallel agents per answer.
xAI’s current flagship. and the most architecturally interesting model on this list. Grok 4.20 is not a single model running once. It is a debate system: 4 agents at low/medium reasoning, 16 agents at high/xhigh, all variants of Grok arguing through a problem before producing a synthesized answer. This is the first production frontier model that ships multi-agent debate as the default inference path, not as an optional harness.
Benchmarks:
- 49 on Artificial Analysis Intelligence Index with reasoning enabled (+6 over Grok 4)
- 78% AA-Omniscience non-hallucination metric. the highest reported AA-Omniscience score in this snapshot, vendor caveat applies (40% fewer factual hallucinations than single-agent Grok 4.1)
- 93.3% AIME accuracy on math
- 68.7 agentic index on AA. among the highest available
- 2M-token context window (up from Grok 4’s 256K)
- 267 tokens/sec serving speed
Pricing: $1.25 input / $2.50 output per million tokens (per xAI docs). relatively expensive, but the multi-agent debate is doing 4–16x the work of a single inference call.
The model also gets real-time data integration via X (the platform), which makes it the strongest pick for any agent that needs current-events grounding without a separate retrieval layer.
Best for: research-heavy agents that need hallucination resistance, math-intensive workflows, real-time-data agents, anything where the cost of being wrong is higher than the cost of running 16 reasoning chains in parallel.
Skip if: pure cost matters (DeepSeek V4-Pro), or if your harness already implements multi-agent debate (you’re paying twice for the same architecture).
Top open-source / open-weight LLMs in May 2026
The open-weight tier became genuinely competitive on capability. not just cost. in March and April. As of May 2026, six open-weight options are defensible at the frontier.
DeepSeek V4-Pro and V4-Flash. Best cost-performance on the frontier
DeepSeek. Released April 23–24, 2026. MIT license, downloadable weights.
The cost-performance leader and the architectural standout of April 2026. Two SKUs. Pro-Max and Flash-Max. both MIT-licensed, both downloadable, both shipping a new attention pattern.
V4-Pro architecture: 1.6 trillion total parameters with 49 billion active per token, pre-trained on more than 32 trillion tokens (per DeepSeek model card). MoE. Hybrid Attention Architecture combining Compressed Sparse Attention (CSA) and Heavily Compressed Attention (HCA). the first frontier-class model to ship this combination. The result is dramatically better long-context efficiency than vanilla transformer attention at the same parameter count, which is what makes 1M-token serving economically viable for an open-weight model.
V4-Flash architecture: 284 billion total / 13 billion active. Same hybrid attention. 1M-token context. Latency-optimized.
Benchmarks (V4-Pro):
- 52 on Artificial Analysis Intelligence Index (#2 open-weight reasoning model. behind Kimi K2.6)
- 80.6% SWE-bench Verified (within 0.2 points of Claude Opus 4.6)
- 55.4% SWE-bench Pro (contamination-resistant). 25-point Verified-vs-Pro gap, larger than other frontier models
- 93.5% LiveCodeBench
- 3,206 Codeforces Elo. highest competitive programming score from any frontier model at release, surpassing GPT-5.4’s 3,168
- 1M-token context with cache-aware retrieval
API pricing:

- V4-Pro: $0.435 input / $0.87 output per million tokens (standard, with a 75% promo through May 31, 2026) (cache miss); $0.145 input on cache hit
- V4-Flash: $0.04 input / $0.07 output per million tokens (post-promo standard) (the lowest listed frontier-class API price in this snapshot)
Roughly roughly 34x cheaper output than GPT-5.5 for Pro-Max, and one-hundredth the cost of GPT-5.5 for Flash-Max. The pricing on Flash-Max is the structural fact about May 2026 economics: the cheapest API call from a Western frontier lab is now ~50x more expensive than the cheapest API call from a frontier-class Chinese model.
Worth flagging: the Verified-vs-Pro score gap suggests training data overlap with the SWE-bench Verified distribution. Production performance on novel codebases will be closer to 55.4% than 80.6%. Run a domain reproduction.
Llama 4 Scout and Maverick. Best for 10M-token open-weight context
Meta. Released April 5, 2025 (year-old carryover into 2026). Open-weight MoE.
Meta’s open-weight MoE flagships. Maverick has a 10-million-token context window. the longest of any production-ready open model. Scout is the smaller, faster sibling at 1M context.
Best for: long-context applications where retrieval-over-history is currently the workaround. Whole-codebase reasoning, multi-document synthesis, long-running agents that hold weeks of conversation context.
For any team building a long-running agent that today re-summarizes its own history every 50 turns, Llama 4 Maverick eliminates the re-summarization step.
Qwen 3.6-Max-Preview. Top closed-source benchmarks from a typically-open lab
Alibaba. Released April 20, 2026. Proprietary, closed weights, API-only.
The single most important model release for production teams in late April. Two reasons:
One: It tops six major coding and agent benchmarks simultaneously. SWE-bench Pro, Terminal-Bench 2.0, SkillsBench, QwenClawBench, QwenWebBench, and SciCode. No other model in May 2026 holds #1 on more than two of these. Qwen 3.6 Max-Preview holds #1 on six.
Two. and this is the bigger story: Alibaba closed weights on its flagship for the first time. The Qwen team has been the most consistent open-weight publisher in the category since 2023; everything from Qwen 1 through Qwen 3.5 has shipped with downloadable weights under Apache 2.0 or similar. With Qwen 3.6 Max-Preview, that pattern broke. The flagship is API-only via Qwen Studio and Alibaba Cloud Model Studio. The 27B/35B-A3B/72B Qwen 3.6 variants remain open, but the top tier is now closed. This is a strategic pivot worth tracking.
Specs:
- 260K-token context window
- OpenAI- and Anthropic-API-compatible endpoint via Alibaba Cloud
preserve_thinkingfeature for multi-turn agentic workflows. preserves the reasoning trace across calls so agents do not lose the “why” between tool calls- Hosted inference only
Best for: production agents where Qwen 3.6 Max-Preview’s six-benchmark dominance maps to your workload. coding, scientific programming, terminal automation, web interaction. Easy migration if you’re already on OpenAI or Anthropic SDKs (drop-in compatibility).
Skip if: open weights are a hard requirement (use Qwen 3.6-72B dense or DeepSeek V4-Pro instead).
Qwen 3.6 open-weight family. Best Apache 2.0 multilingual base
Alibaba. Released April 11–21, 2026. Apache 2.0, three sizes (72B / 35B-A3B / 27B).
The Qwen 3.6 open-weight family. Three sizes shipped across April:
- Qwen 3.6-72B-dense (April 11). flagship dense, 256K context, 94.8% HumanEval, 68.2% SWE-bench Verified, 71.4% LiveCodeBench. Beats Gemma 4 on every coding benchmark.
- Qwen 3.6-35B-A3B (April 16). MoE with 35B total / 3B active, optimized for inference cost
- Qwen 3.6-27B (April 21). dense, image+text, 27B at fine-tunable size
Qwen 3.6-72B-dense at 27B-or-so active throughput on quantization is strong enough that Simon Willison reported it “drew a better pelican than Claude Opus 4.7”. slightly tongue-in-cheek but the underlying point holds: open-weight Qwen 3.6 is now genuinely frontier-class on workloads it was trained for.
Best for: multilingual production (especially East Asian), self-hosted deployments where Apache 2.0 is required, fine-tuning bases.
Mistral Large 3. Best non-Chinese open-weight Apache 2.0
Mistral AI. Released December 4, 2025. Apache 2.0, 675B total / 41B active MoE.
The strongest open-weight model from a non-Chinese lab. 675 billion total parameters with 41 billion active per token (MoE), Apache 2.0 license, 256K context, multimodal. GA for 5 months by May 2026. Released through Hugging Face as Mistral-Large-3-675B-Instruct-2512.
Debuted at #2 in OSS non-reasoning models on LMArena and reaches parity with top instruction-tuned open-weight models. Reasoning variants score 85% on AIME ‘25 for the 14B reasoning size.
Best for: agentic systems where Apache 2.0 specifically matters (downstream redistribution). European data-residency requirements. Production teams that prefer non-Chinese open-weight options.
Mistral Small 4. Best for single-GPU self-hosting at frontier capability
Mistral AI. Released March 16, 2026. Apache 2.0, 119B total / 6.5B active.
The on-device pick. 119B total parameters with 6.5B active per forward pass. Mistral docs list minimum production infrastructure as 4×H100, 2×H200, or 1×DGX-B200; small relative to frontier MoEs, not laptop-class. Hybrid reasoning, image and text inputs, instruct + reasoning + coding in one model.
Best for: edge deployment, on-device privacy-sensitive workloads, single-GPU self-hosting, frontier-tier capability locally.
Gemma 4. Best small fine-tuning base in the Google ecosystem
Google. Released April 2, 2026. Apache 2.0, sizes up to 31B.
Google’s open-weight family. Four sizes ranging up to 31B parameters. Well-supported in the Google ecosystem (Vertex AI, Hugging Face, llama.cpp, Ollama). Strong base for fine-tuning.
Best for: small-to-mid open deployment with Google ecosystem alignment. Fine-tuning bases.
GLM-5.1. Largest open-weight MIT-licensed flagship
Z.AI / Zhipu. Released April 7, 2026. MIT license, 754B parameter MoE.
754B parameter MoE under MIT license. This is the largest open-weight model with a fully permissive commercial license available in May 2026 (DeepSeek V4 is also MIT, but at 1.6T parameters it requires more infrastructure to self-host). GLM-5.1 hits a sweet spot for teams that want frontier-class quality with permissive licensing on hardware that real production teams have access to.
GLM-5.1 briefly led SWE-bench Pro between its release and Qwen 3.6 Max-Preview on April 20. Strong on coding, agent tasks, and Chinese-language workloads. The strategic significance is the MIT license. combined with DeepSeek V4 also under MIT, this is a deliberate move by Chinese labs to make their models maximally adoptable in Western production stacks.
Best for: self-hosted production where MIT licensing matters and 754B parameters fit your infrastructure.
Kimi K2.6. Top open-weight on AA Intelligence Index
Moonshot AI. Released April 20, 2026. Open-weight, 1.1T MoE.
The current #1 open-weight model on the Artificial Analysis Intelligence Index. Moonshot’s latest, an upgrade to K2.5 with the primary improvement being agentic stability over extended sessions. agents running on K2.6 sustain longer tool-call sequences without losing coherence than agents running on K2.5 or comparable open-weight alternatives. 1.1 trillion parameters MoE.
Kimi K2.6 is the “if you only ship open-weight” pick in May 2026. Quality is genuinely frontier-class on agentic and reasoning workloads. Cheap on hosted inference (Moonshot, Together AI, Fireworks, OpenRouter). The catch is that it was trained primarily on Chinese-language data and shows it on subtle English nuance. for English-only production, DeepSeek V4-Pro or Qwen 3.6-72B may fit better.
Best for: multi-step agents that hold context across 50+ tool calls, multilingual production, cost-efficient hosted inference, AA Intelligence Index leaders.
Top multimodal LLMs in May 2026
Multimodal is no longer a single dimension. Vision, image generation, video generation, and audio each have their own leader, their own price floor, and their own production trade-offs. Treat the table below as the starting point, not the endpoint.
Vision (image and document understanding)
| Use case | Best closed | Best open |
|---|---|---|
| General image understanding | Gemini 3.1 Pro | Qwen 3.6-VL |
| Document / OCR / chart reading | Claude Opus 4.7 | Qwen 3.6-VL |
| Long-context multi-image | Gemini 3.1 Pro (1M tokens) | Llama 4 Scout (10M) |
| Screen / UI understanding | GPT-5.5 (OSWorld 78.7%) | Qwen 3.6-VL |
Production note: every Western frontier model now handles vision natively. The “open” column is meaningfully behind on subtle layouts (charts with text, technical diagrams, complex tables) but caught up on the basics. If you are doing high-volume document understanding at scale, Qwen 3.6-VL self-hosted is now within 5 points of Gemini 3.1 Pro at one-tenth the cost.
Image generation
The image-gen category fragmented in 2026. There is no single best model; pick by what the image is for.
| Use case | Best pick | Why | Pricing |
|---|---|---|---|
| Photorealism / product / portrait | Imagen 4 Ultra | best-rated photorealistic output in this snapshot per third-party reviews | ~$0.04/img |
| Editorial / blog covers / clean | Recraft V4 | #1 HuggingFace logo benchmark, SVG export, brand styling | ~$0.04/img |
| Speed / high volume / iteration | Nano Banana 2 (Gemini 3.1 Flash Image) | 1-3s generation | $0.067/1K, $0.151/4K image |
| Best default / balance | FLUX 2 Pro | Speed + quality + price for most teams | varies |
| Text in images / signage / typography | Ideogram v3 | Reliable legible text, brand names, layouts | ~$0.06/img |
| Aesthetic / art direction | Midjourney v8 | Native 2K, 5x faster than v7 (March 2026 update) | subscription |
| Cheapest | Z-Image Turbo | $0.01 per 1024×1024 in ~1s | $0.01/img |
| Open-weight / self-host | FLUX.1.1 Pro / SDXL Turbo | On your hardware, no API gating | self-host |
May 2026 image-gen storylines worth knowing:
- Sora 2 web/app shut down April 26. OpenAI announced in March that the consumer Sora experience is gone; the API discontinues September 24, 2026. If you built on Sora, migration is now a deadline-bound project.
- Anthropic launched Claude Design (April 17 2026, research preview) for creating prototypes, slides, and one-pagers. This is a visual-creation product powered by Claude Opus 4.7, not native image generation. Anthropic’s first GA image gen. strong on diagrams and charts, weaker on photorealism. Useful inside Claude for technical content workflows.
- Meta Muse Spark (April 8) is Meta’s first proprietary model. image and creative gen across Instagram and WhatsApp. The “open Llama for builders, proprietary Muse for consumer” split is now explicit Meta strategy.
Video generation
Video gen had a major year in early 2026. The lineup now:
| Use case | Best pick | Why |
|---|---|---|
| Best all-around | Google Veo 3.1 | 4K, native audio, prompt adherence, leads lip sync |
| Multi-shot storytelling | Kling 3.0 (Feb 2026) | 3–15s sequences with subject consistency across cuts |
| Cinematic portrait / face / expressions | Hailuo (MiniMax) | Strongest face/expression render, character-focused |
| Granular creative control | Runway Gen-4.5 | Camera moves, motion brush, reference-driven consistency |
| Audio-video joint generation | Seedance 2.0 (ByteDance, Feb 2026) | First model with unified A/V (not post-processed), phoneme-level lip-sync 8+ langs |
| Physics simulation | Sora 2 (sunset coming) | Water, glass, fabric, smoke physics still unmatched. but discontinuing |
For production video pipelines in May 2026: Veo 3.1 for narrative scenes, Kling 3.0 for multi-shot, Seedance 2.0 if you need lip-synced talking content in non-English.
Audio understanding
Native audio handling (speech as input, not via STT-then-LLM) became standard in April 2026. GPT-5.5 is the leader here. it handles speech-in directly without a transcription step, which preserves prosody, emotion, and disambiguates accent or background noise that breaks STT-based pipelines. Gemini 3.1 Pro is close behind. Open-weight: Llama 4 with audio adapters works but lags meaningfully.
Best for: voice assistants where speech-in-speech-out latency matters, accessibility applications, multi-modal agents where the audio context is the signal.
Voice and audio (covered separately)
Voice AI deserves its own buying guide. STT (Deepgram Nova-3, Whisper, AssemblyAI), TTS (Cartesia, ElevenLabs, Hume), and voice-agent platforms (Vapi, Retell, Deepgram Voice Agent) all have separate decision logic from text-only LLMs. The latency budget alone (sub-300ms ITU-T G.114 for natural conversation) drives different picks than text-LLM workflows.
See Best Voice AI of May 2026 for the full STT, TTS, and voice-agent stack.
Top embeddings and retrieval models in May 2026
Embeddings have two production constraints: MTEB score on your domain, and price per million tokens. The top of the leaderboard moved in early 2026 with Google’s Gemini Embedding 2 Preview release.
| Use case | Best pick | MTEB score | Price |
|---|---|---|---|
| Best retrieval (closed) | Voyage-3-large | 67.1 MTEB, retrieval leader | $0.06 per M tokens |
| Best multimodal retrieval | Gemini Embedding 2 Preview (March 10) | text + image + video + audio + PDF, 100+ langs, native MRL | $0.20 per M tokens |
| Best general (closed) | NV-Embed-v2 | top overall MTEB averaged | varies |
| Cheap + good | Jina-embeddings-v3 | 65.5 MTEB, beats OpenAI 3-large | budget tier |
| Multilingual enterprise | Cohere embed-v4 | 65.2 MTEB | enterprise |
| OpenAI ecosystem default | OpenAI text-embedding-3-large | 64.6 MTEB | $0.13 per M |
| Cheapest viable | OpenAI text-embedding-3-small | very competitive | $0.02 per M |
| Best open-source small | Jina v5-text-small | 71.7 MTEB v2 | self-host |
| Best open-source large | Microsoft Harrier-OSS-v1 | 74.3 MTEB v2 | self-host |
| Multilingual open | Qwen3-Embedding-8B | 70.58 MTEB v2 | self-host |
The single biggest embeddings story of early 2026 is Gemini Embedding 2 Preview. Google released a model on March 10 that handles text, image, video, audio, and PDF natively in a single model, with native Matryoshka Representation Learning (so you can truncate dimensions without retraining). At $0.20 per million tokens it is also the lowest listed multimodal embeddings API price in this snapshot. For new RAG pipelines started after March 10, this should be the default unless you have a specific reason not to use Google.
For reranking: Cohere Rerank v4 and Voyage-rerank-v3 are the production picks. Reranking adds 2–5 points of NDCG@10 on top of dense retrieval at small added cost; ship it if you have not already.
Top coding-specific LLMs in May 2026
Coding is the highest-stakes category. most enterprise AI deployments are coding agents, and the leaderboards have compressed to within 2-3 points across labs.
| Use case | Top pick | Score | Output $/M tokens |
|---|---|---|---|
| Multi-file code reasoning | Claude Opus 4.7 (1M context) | 87.6% SWE-bench Verified | $25 |
| Terminal / agentic coding | GPT-5.5 | 82.7% Terminal-Bench 2.0 | $30 |
| Cost-sensitive coding | DeepSeek V4-Pro | 80.6% SWE-bench Verified | $3.48 |
| Competitive programming | DeepSeek V4-Pro | 3,206 Codeforces Elo | $3.48 |
| Live code generation | DeepSeek V4-Pro | 93.5% LiveCodeBench | $3.48 |
| Codex/specialized model | GPT-5.3 Codex | 85% SWE-bench Verified | (Codex tier) |
| Coding harness + model | Forge Code + Gemini 3.1 Pro | 78.4% Terminal-Bench 2.0 | $10 (model) |
| Coding harness + model | Factory Droid + GPT-5.3 Codex | 77.3% Terminal-Bench 2.0 | (Codex tier) |
| Production-realistic (contamination-resistant) | GPT-5.5 | 58.6% SWE-bench Pro | $30 |
The harness now contributes 2-6 points on top of raw model capability. The agent wrapping the model. its retry logic, tool-call validation, intermediate-step evaluation. is the dominant production variable. For production coding agents, picking the right harness matters as much as picking the right model.
If your coding agent is missing on the leaderboard, your harness is more often the cause than your model. Audit retry logic and intermediate evaluation before swapping models.
Top reasoning + math LLMs in May 2026
| Benchmark | Top pick | Score |
|---|---|---|
| GPQA Diamond (graduate reasoning) | Claude Mythos Preview (restricted) | 94.6% |
| GPQA Diamond (GA) | Gemini 3.1 Pro | 94.3% |
| USAMO (math olympiad) | Claude Mythos Preview | 97.6% |
| AIME 2025 | Grok 4 Heavy | ~100% |
| FrontierMath Tier 4 | GPT-5.5 Pro | 39.6% |
| Humanity’s Last Exam (with tools) | Claude Mythos Preview | 64.7% |
GPT-5.5 Pro’s parallel test-time compute is the production-relevant variant. same model running multiple reasoning chains in parallel and synthesizing the result. Costs roughly 6x the base GPT-5.5 rate but delivers 22% fewer major errors on hard reasoning calls.
Best LLM for X: decision framework
Choose Claude Opus 4.7 if:
- You’re building multi-file coding agents or codebase Q&A.
- Your agents run 50+ tool calls deep and reliability decay matters.
- You need strong refusal behavior and safety alignment.
- You’re already on the Anthropic ecosystem (Claude Code, MCP).
Choose GPT-5.5 if:
- You’re building agentic terminal automation or OS-level workflows.
- Function calling and tool use are the dominant pattern.
- You need vision + audio in a single model.
- You want ChatGPT distribution defaults (GPT-5.5 Instant became default May 5).
Choose Gemini 3.1 Pro if:
- You need 1M-token context (whole-codebase, multi-document, long-running).
- Multimodal (vision, video, audio) is core to your application.
- US-data-residency cost matters and $2/$12 is your budget ceiling.
- You’re already in Google Cloud / Vertex AI.
Choose DeepSeek V4-Pro if:
- Cost is the dominant constraint.
- Your workload is primarily coding and your domain is closer to SWE-bench Verified than SWE-bench Pro.
- You can self-host or accept inference from Chinese-lab APIs.
- MIT licensing matters for downstream redistribution.
Choose Mistral Large 3 if:
- You want open-weight quality from a non-Chinese lab.
- Apache 2.0 specifically matters for your legal / redistribution path.
- You’re on European data-residency requirements.
- 256K context is enough.
Choose Llama 4 Maverick if:
- 10M-token context is genuinely useful (rare today, but real).
- You’re self-hosting in the Meta ecosystem.
- You need open-weight + frontier-class multimodal.
Choose Mistral Small 4 or Gemma 4 if:
- On-device deployment, edge, or single-GPU self-hosting.
- You’re fine-tuning for a vertical from a 1B-31B base.
Choose Grok 4 if:
- Math and real-time data are core (X integration).
- You’re already in xAI’s ecosystem.
Avoid Claude Mythos Preview unless you are a Project Glasswing partner. it is not generally available.
Common mistakes when picking an LLM in May 2026
The four most expensive errors we see production teams make:
- Optimizing for a single benchmark. If you optimize for SWE-bench Verified, you’ll pick the model with the best score on a contaminated benchmark. not the best model for your domain. Use multiple benchmarks plus a domain reproduction.
- Ignoring total cost of ownership. Listed price × token volume is the sticker number. Real production cost includes retry rate × test-time-compute multiplier × failure recovery cost. A flaky agent doubles or triples the bill before you notice.
- Choosing from brand inertia without a domain eval. Brand inertia keeps teams on GPT or Claude when DeepSeek V4-Pro at roughly 34x cheaper output price would handle their workload. Run the comparison.
- Overlooking model routing. You don’t have to pick one model. Route easy queries to cheap models, hard queries to frontier models, with a fallback chain. Most production stacks should be 2-3 models, not one.
What changed in May 2026 (week 1)
| Date | Event | Why it matters |
|---|---|---|
| May 5 | OpenAI Greg Brockman discloses $50B 2026 compute spend | Proprietary-vs-open economic gap |
| May 5 | Apple announces iOS 27 third-party AI selection | First crack in OpenAI exclusivity |
| May 5 | OpenAI launches ChatGPT Ads Manager beta | Monetizes the ChatGPT surface |
| May 5 | Subquadratic launches SubQ. 12M context, $29M seed | Subquadratic attention beats O(n²) wall |
| May 5 | U.S. Commerce extends pre-release testing to 5 labs | Frontier release timing has regulatory dependency |
| May 5 | GPT-5.5 Instant becomes ChatGPT default | 52.5% fewer hallucinations claimed (internal eval) |
| May 5 | Blitzy raises $200M Series at $1.4B valuation | Autonomous-developer category continues attracting capital |
How to actually pick one for production
The leaderboard is the wrong artifact to make a production decision from in May 2026. Three things to do instead:
- Run a domain reproduction. Take 100-500 of your actual production prompts, run them through your three candidate models with your harness, and score them with Future AGI Turing eval models or your own LLM-as-judge. The gap between vendor-reported scores and your reproduction is the number that tells you which model to ship.
- Measure reliability under load. A public benchmark score is an aggregate over a fixed task set. It does not predict variance across your prompts, your scaffold, or repeated agent runs. Production agents run thousands of distinct problems daily, and the variance amplifies. Track the Reliability Decay Curve. agent success rate as a function of session length. Most frontier models lose 15-40% of headline accuracy at 50+ tool-call sessions, which public benchmarks never test. Use Future AGI’s simulation framework or roll your own.
- Cost-adjust your scores. Headline scores hide 5-10x cost differences. Compute score-per-dollar across candidate models on your domain. DeepSeek V4-Pro is the obvious pick at one-seventh the price if it holds up. and the obvious miss if the contamination effect bites your domain. The only way to know is to run your traffic through it.
The model choice is no longer the bottleneck. The harness, the eval discipline, and the reliability instrumentation are. Pick the model that fits your workload, then put more effort into the layer above it than you spent comparing leaderboard scores.
If your production stack is on Google ADK, the ADK Production Eval Loop walks through the instrument-score-gate-simulate-optimize pattern step by step with runnable code.
Sources
Frontier model launches (primary):
- Introducing GPT-5.5 (OpenAI)
- Claude Opus 4.7 announcement (Anthropic)
- Claude Mythos Preview (red.anthropic.com)
- Gemini 3.1 Pro launch (Google)
- Gemini API pricing (Google AI for Developers)
- DeepSeek V4 Preview release (DeepSeek API docs)
- Qwen 3.6 Max-Preview (Qwen blog)
- Mistral Large 3 announcement
- Llama 4 Scout + Maverick announcement (Meta)
- Grok 4.20 Multi-Agent Beta (xAI docs)
Benchmarks and leaderboards:
- SWE-bench Pro Public Leaderboard (Scale)
- Terminal-Bench 2.0 Leaderboard
- Trustworthy Benchmarks (UC Berkeley RDI)
- Artificial Analysis Intelligence Index
Previous: Best LLMs of April 2026 ←. six frontier models in 30 days, Berkeley breaks the trust, DeepSeek V4 lands at roughly 34x cheaper output.
Frequently asked questions
What is the best LLM in May 2026?
What is the best open-source LLM in May 2026?
What is the best LLM for coding in May 2026?
Are LLM benchmarks reliable in May 2026?
What new LLMs were released in May 2026?
How does GPT-5.5 compare to Claude Opus 4.7 in May 2026?
Should I use DeepSeek V4-Pro in production?

Best LLMs April 2026: compare GPT-5.5, Claude Opus 4.7, DeepSeek V4, Gemma 4, and Qwen after benchmark trust broke and prices compressed fast.

Best LLMs March 2026: compare Gemini 3.1 Pro, Claude Opus 4.6, Mistral Small 4, and Qwen for coding, cost, multimodal, and open-weight picks.

Best Voice AI May 2026: compare Deepgram, Cartesia, ElevenLabs, Retell, and Vapi for STT, TTS, latency budgets, and production voice agents.