Best LLMs of March 2026: When Open-Weight Caught Closed-Source on Coding
Best LLMs March 2026: compare Gemini 3.1 Pro, Claude Opus 4.6, Mistral Small 4, and Qwen for coding, cost, multimodal, and open-weight picks.

Table of Contents
Series note. This is the March 2026 entry in our monthly best-LLMs series. New frontier models now ship weekly. We track what shipped, what won which category, and what the public leaderboards do not capture. Next: April 2026 →. nine frontier releases in 30 days, Berkeley breaks the trust. May 2026 →→. distribution and architecture move while the model layer rests.
What changed since March 2026 (May 2026 callout). Two months later the frontier picks have moved. Claude Opus 4.7 replaced Opus 4.6 on April 16 with a 7-point jump on SWE-bench Verified. GPT-5.5 / GPT-5.5 Pro shipped April 23 with native audio. DeepSeek V4 landed at roughly 1/34 the output price of GPT-5.5. Berkeley’s April paper formalized the SWE-bench Verified vs Pro contamination concern that the 35-point gap below already foreshadowed. For up-to-date production picks see the May 2026 monthly compare. This page remains a historical March 2026 snapshot.
TL;DR: Best LLM per category, March 2026
| Use case | Best pick | Why | Output $/M tokens |
|---|---|---|---|
| Multi-file coding | Claude Opus 4.6 | 80.8% SWE-bench Verified (carryover) | $25 |
| Terminal / agentic coding | GPT-5.4 | 75.1% Terminal-Bench 2.0 | varies |
| Multimodal + 1M context | Gemini 3.1 Pro | 94.3% GPQA Diamond, default in API since Mar 6 | $12 |
| Efficient self-hosting | Mistral Small 4 | 6.5B active MoE, datacenter-class minimum, Apache 2.0 | self-host |
| Open-weight all-around (non-Chinese) | Mistral Large 3 | 675B / 41B active MoE, Apache 2.0 | self-host |
| Multilingual base for fine-tuning | Qwen 3.5 Small Series | 0.8B–9B dense | self-host |
| Cost-sensitive open-weight | GLM-5.1 | MIT, agentic + coding | self-host |
Three things define the month:
- Gemini 3.1 Pro takes #1 GPQA. Google’s frontier model becomes the GPQA Diamond leader at 94.3% as of late March.
- Mistral Small 4 changes the efficient self-hosting ceiling. 6.5B active parameters running on Mistral’s recommended infrastructure (4xH100 or equivalent) now beats some 30B-70B dense models.
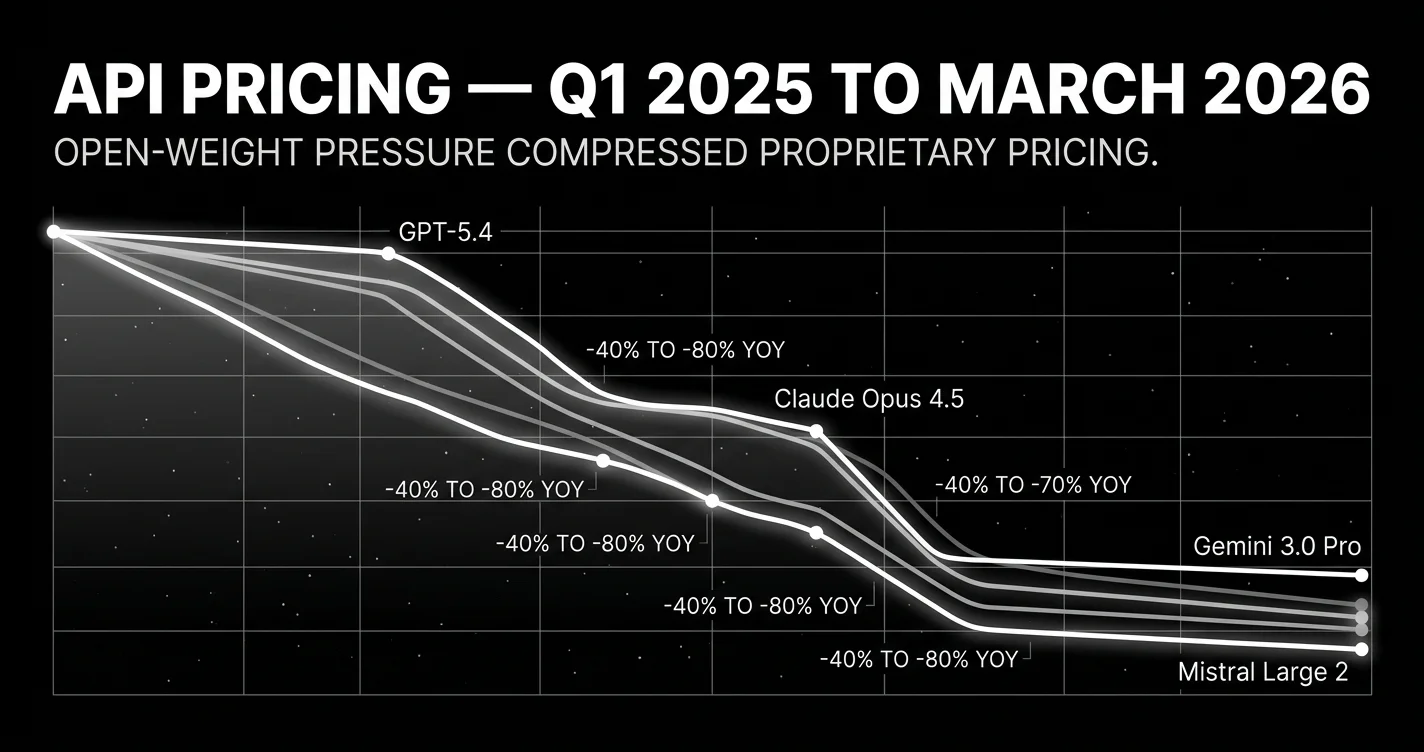
- Open-weight prices drop 40-80% YoY. GLM-5.1 (MIT), Mistral Small 4 (Apache 2.0), and Mistral Large 3 (Apache 2.0, December GA) make the price war explicit. Sets up DeepSeek V4 in April.
The story of March 2026: open-weight catches up, prices collapse
March 2026 was the setup month for April’s deluge. Three structural shifts made the April releases possible.
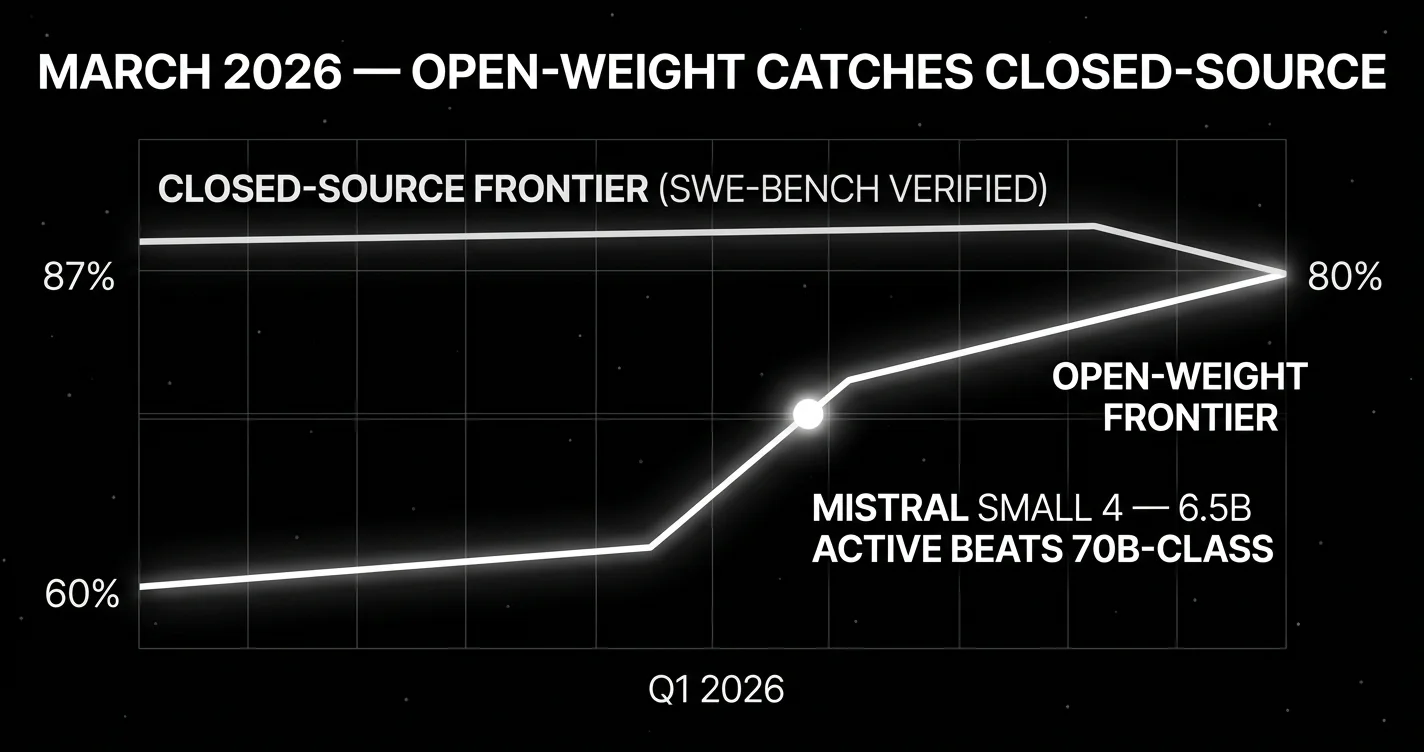
First, the coding-benchmark gap compressed. Claude Opus 4.6 at 80.8% SWE-bench Verified, GPT-5.4 at ~85%, Gemini 3.1 Pro near 80%, all within 5 points. Mistral Large 3 (Apache 2.0, December 2025 release, fully GA throughout March) reached parity with top instruction-tuned closed models. GLM-5.1 (MIT, March 27) competed on agentic and coding tasks at a fraction of the cost.
Second, Mistral Small 4 changed what “small” means. The March 16 release was 119 billion total parameters with only 6.5 billion active per forward pass. Mistral’s docs list minimum production infrastructure as 4xH100, 2xH200, or 1xDGX-B200, which is small relative to other frontier MoEs even though it is not laptop-class. Quantized local experiments may be possible, but production guidance is multi-GPU and datacenter-class. The model beats dense models 4-10x larger because the MoE architecture activates the right experts per token. Apache 2.0 means it is downloadable, fine-tunable, and redistributable.
Third, prices dropped. Year-over-year, frontier model pricing dropped 40-80%. Gemini 3.1 Pro at $2 input / $12 output per million tokens (≤200K prompt; $4 input / $18 output above 200K) is roughly 1/4 of what frontier US lab pricing was in March 2025. Open-weight pricing dropped further. GLM-5.1 hosted inference at fraction-of-a-cent per million tokens. The proprietary labs were pricing-pressured before DeepSeek V4 even shipped in April.
One context-setting structural event: Gemini 3.1 Pro became the default in Google’s API on March 6 (initial release was February 19). The Gemini 3 Pro Preview was officially discontinued on March 9. Most production users started receiving Gemini 3.1 Pro by default in the second week of March, which is when its 94.3% GPQA Diamond score started showing up in independent benchmark roundups.
If you ship LLM-powered products, March 2026 is the month the open-weight tier became defensible at the frontier and the pricing power of the proprietary labs started to erode. The April deluge, including Claude Mythos Preview, Claude Opus 4.7, GPT-5.5, and DeepSeek V4, was the response.
Top closed-source / proprietary LLMs in March 2026
Gemini 3.1 Pro. Best for long-context multimodal at low cost
Google DeepMind. Default in API since March 6, 2026. 1M-token context.
The cheapest US-frontier model and the only one with a true 1M-token context window in production. Leads GPQA Diamond at 94.3%. Strong multimodal. image, audio, and video understanding all at frontier quality.
- $2 input / $12 output per million tokens (≤200K prompt; $4 input / $18 output above 200K) (lowest among US frontier labs)
- 1M-token context
- Strong with Forge Code harness. 78.4% Terminal-Bench 2.0 in agent setups
- Best for: long-context, multimodal pipelines, cost-sensitive US-data-residency workloads
Claude Opus 4.6. GA flagship throughout March for code reasoning
Anthropic. Carryover. The GA flagship until April 16, 2026.
The strongest GA model for multi-file code reasoning throughout March. 80.8% SWE-bench Verified, 91.3% GPQA Diamond, 88.8% LiveCodeBench, 65.4% Terminal-Bench 2.0. Worth flagging: 45.9% on the contamination-resistant SWE-bench Pro. a 35-point Verified-vs-Pro gap that was already a trust signal in March, before Berkeley’s April paper made it explicit.
- 200K-token context, native vision, $5/$25 per 1M tokens
- Best for: multi-file code reasoning, ambiguous specs, long-task agent reliability
Replaced by Claude Opus 4.7 on April 16. If you’re running production on Opus 4.6 in May 2026, plan the upgrade. pricing stayed flat, and Verified score went up by 7 points.
GPT-5.4. GA flagship throughout March for terminal-heavy work
OpenAI. Carryover. The GA flagship until April 23, 2026.
The strongest model for terminal-heavy work throughout March. ~85% SWE-bench Verified, 75.1% Terminal-Bench 2.0, 81% GPQA Diamond, Codeforces Elo 3,168. GPT-5.4 Pro at $30/$180 per million tokens for the parallel test-time compute variant.
Replaced by GPT-5.5 / GPT-5.5 Pro on April 23.
Grok 4. Best for math benchmarks and X-ecosystem integration
xAI. The flagship through March 2026.
xAI’s flagship through March. Top score on AIME 2025 with the Heavy variant. Real-time data integration via X. Less production traction in enterprise SaaS. Best for math benchmarks and X-ecosystem integration.
Claude Design (cross-month context, not a March pick)
Anthropic. Research preview, April 17, 2026.
Anthropic’s April 17 research-preview visual-creation product, not available in March and not GA. Powered by Claude Opus 4.7. Listed here only because end-of-month March readers were tracking it; it does not factor into March production picks.
Top open-source / open-weight LLMs in March 2026
The month the open-weight tier became defensible at the frontier.
Mistral Small 4. Best for efficient datacenter self-hosting at frontier capability
Mistral AI. Released March 16, 2026. Apache 2.0, 119B total / 6.5B active.
The efficient self-hosting pick. 119B total parameters with 6.5B active per forward pass. Mistral docs list minimum production infrastructure as 4xH100, 2xH200, or 1xDGX-B200; small relative to frontier MoEs, not laptop-class. Hybrid reasoning, image and text inputs, instruct + reasoning + coding in one model.

The headline insight: 6.5B active beats some 30B-70B dense models because the MoE architecture activates the right experts per token. The efficient self-hosting ceiling moved up dramatically.
- Apache 2.0. downloadable, fine-tunable, redistributable, commercial use
- Hybrid reasoning (chain-of-thought built in)
- Image and text input
- Best for: private self-hosting, controlled infrastructure, and efficient MoE serving on a small datacenter footprint
Mistral Large 3. Best non-Chinese open-weight Apache 2.0
Mistral AI. Released December 4, 2025. Apache 2.0, 675B total / 41B active MoE.
The strongest open-weight model from a non-Chinese lab throughout March. 675 billion total parameters with 41 billion active per token (MoE), Apache 2.0 license, 256K context window, multimodal. Released on Hugging Face as Mistral-Large-3-675B-Instruct-2512.
Debuted at #2 in OSS non-reasoning models on LMArena and reached parity with top instruction-tuned open-weight models. Reasoning variants score 85% on AIME ‘25 for the 14B reasoning size.
- Apache 2.0
- 256K context, multimodal
- Best for: agentic systems where Apache 2.0 specifically matters, European data-residency, non-Chinese open-weight requirements
GLM-5.1. Strong open-weight Chinese option at very low inference cost
Zhipu AI / Z.AI. Released March 27, 2026. MIT license.
Strong Chinese-lab open-weight competitive on agent and coding tasks at very low inference cost. Often deployed in Chinese-market production. MIT license. permissive for commercial use.
Qwen 3.5 Small Series. Best multilingual base for vertical fine-tuning
Alibaba. Released March 1, 2026. Four dense sizes (0.8B / 2B / 4B / 9B).
Four dense open-weight models at 0.8B, 2B, 4B, 9B parameters. Multilingual base for fine-tuning verticals. Strong on East Asian languages, competitive on English.
Best for: fine-tuning a vertical from a 1B-9B base. Cost-effective scaling.
NVIDIA Nemotron 3 Super. Best for NVIDIA enterprise hardware stacks
NVIDIA. Released March 11, 2026 at GTC. Optimized for H200/B200.
NVIDIA’s latest open-source enterprise LLM, optimized for hardware-aware inference on H200/B200 hardware. Strong for teams already running on NVIDIA enterprise stacks.
Other notable March open-weight releases
Qwen 3.5 Plus, MiMo-V2-Pro, MiniMax-M2.7, Grok 4.20. Various dates in March 2026.
Qwen 3.5 Plus and a handful of smaller releases shipped through March. Most are competitive within their tier but did not dramatically shift the leaderboard. Worth tracking for specific verticals (multilingual, math, real-time data).
Top multimodal LLMs in March 2026
March 2026 was a quiet-but-foundational month for multimodal. The headline frontier models did not change much, but one structural shift landed during March: Google released Gemini Embedding 2 Preview on March 10 (covered in the embeddings section below). Midjourney v8 also shipped during March with native 2K and 5x faster generation than v7. Anthropic’s Claude Design dropped after the March window, on April 17 as a research preview; it is included in this guide only as cross-month context.
Vision (image and document understanding)
| Use case | Best closed | Best open |
|---|---|---|
| General image understanding | Gemini 3.1 Pro (default in Google API since March 6) | Llama 3.3 family + Qwen3.5-VL |
| Document / OCR / chart reading | Claude Opus 4.6 | Qwen3.5-VL |
| Long-context multi-image | Gemini 3.1 Pro (1M tokens) | (Llama 4 already 11 months in production; April 5, 2025 launch) |
| Screen / UI understanding | GPT-5.4 | Qwen3.5-VL |
Image generation
The image-gen lineup at end-of-March:
| Use case | Best pick | Why | Pricing |
|---|---|---|---|
| Photorealism | Imagen 4 Ultra | best-rated photorealistic output (third-party reviewed) | ~$0.04/img |
| Editorial / design / charts | Recraft V4 | #1 HuggingFace, SVG export, brand styling | ~$0.04/img |
| Speed / iteration | Nano Banana 2 (Gemini 3.1 Flash Image) | 1–3s per image, 4K | $0.067/1K image, $0.151/4K image |
| Best default | FLUX 1.1 Pro / FLUX 2 Pro | Speed + quality + price | varies |
| Text in images | Ideogram v3 | Reliable legible text | ~$0.06/img |
| Aesthetic art | Midjourney v8 (March 2026) | Native 2K, 5x faster than v7 | subscription |
| Chart and diagram generation | Recraft V4 (Claude Design arrives April 17, not March) | Recraft leads diagrams and SVG in March | ~$0.04/img |
Anthropic launched Claude Design on April 17 (after this March snapshot). Research preview only, not GA, not native image generation. It is a visual-creation product (prototypes, slides, one-pagers) powered by Claude Opus 4.7. As of end-of-March, Anthropic had no GA image-generation product.
Video generation
The state of video gen at end of March 2026:
| Use case | Best pick | Why |
|---|---|---|
| Best all-around | Google Veo 3 | Pre-Veo 3.1, still strongest at narrative scenes |
| Multi-shot storytelling | Kling 3.0 (Feb 2026) | 3–15s sequences with subject consistency |
| Cinematic portraits / faces | Hailuo (MiniMax) | Strongest face/expression render |
| Granular creative control | Runway Gen-4 | Camera moves, motion brush |
| Audio-video joint generation | Seedance 2.0 (ByteDance, Feb 2026) | Phoneme-level lip-sync 8+ langs. the fresh entrant |
| Physics simulation | Sora 2 (still active) | OpenAI announced sunset in March; web/app shuts April 26 |
The Sora 2 sunset announcement is a March 2026 event. OpenAI announced the discontinuation timeline for the consumer Sora experience this month. web/app discontinuing April 26, 2026, API September 24, 2026. Teams that built on Sora began migration planning in March. Replacement defaults: Veo 3 → Veo 3.1 in April, or Runway Gen-4.
Audio understanding
In March 2026, no model had truly native audio yet. GPT-5.4 handled speech via multimodal pipelines with strong-but-not-native audio reasoning. Gemini 3.1 Pro was close. Native audio (speech as direct input to the LLM, no STT step) shipped with GPT-5.5 on April 23. one month after this March snapshot. For March-era voice agents, the STT-then-LLM pattern was the only viable path.
Efficient multimodal self-hosting
Mistral Small 4 (March 16 2026) was the breakthrough efficient multimodal release. 6.5B active parameters on a 4xH100-class footprint, handling image + text inputs and hybrid reasoning. The pick for any application that needs private self-hosting or controlled infrastructure with frontier-tier capability.
Voice and audio (covered separately)
Voice AI deserves its own buying guide. STT (Deepgram Nova-3, Whisper, AssemblyAI), TTS (Cartesia, ElevenLabs, Hume), and voice-agent platforms (Vapi, Retell, Deepgram Voice Agent) all have separate decision logic from text-only LLMs. The latency budget alone (sub-500ms round-trip aggressive, sub-700ms widely accepted, with ITU-T G.114 mouth-to-ear delay in mind) drives different picks than text-LLM workflows.
See Best Voice AI of March 2026 for the full STT, TTS, and voice-agent stack.
Top embeddings and retrieval models in March 2026
The single biggest March 2026 embeddings news: Google released Gemini Embedding 2 Preview on March 10. Multimodal native. text + image + video + audio + PDF in a single model. 100+ languages, native Matryoshka Representation Learning (truncate dimensions without retraining), and $0.20 per million tokens, the lowest listed embeddings API price in this snapshot.
If you started a new RAG pipeline in March 2026, this is the default unless you have a specific reason not to use Google.
| Use case | Best pick | MTEB | Price |
|---|---|---|---|
| Default for new pipelines (multimodal) | Gemini Embedding 2 Preview (Mar 10) | retrieval leader, 5 modalities | $0.20 per M |
| Best retrieval (closed) | Voyage-3-large | 67.1 MTEB | $0.06 per M |
| Best general (closed) | NV-Embed-v2 | top overall MTEB averaged | varies |
| Cheap + good | Jina-embeddings-v3 | 65.5 MTEB | budget |
| Multilingual enterprise | Cohere embed-v4 | 65.2 MTEB | enterprise |
| OpenAI ecosystem | text-embedding-3-large | 64.6 MTEB | $0.13 per M |
| Cheapest viable | OpenAI text-embedding-3-small | strong p/p | $0.02 per M |
| Open-source small | Jina v5-text-small | 71.7 MTEB v2 | self-host |
| Open-source large | Microsoft Harrier-OSS-v1 | 74.3 MTEB v2 | self-host |
| Multilingual open | Qwen3-Embedding-8B | 70.58 MTEB v2 | self-host |
For reranking: Cohere Rerank v4 and Voyage-rerank-v3 are the production picks. Reranking adds 2-5 points of NDCG@10 on top of dense retrieval at small added cost.
FAGI note (embeddings + image-gen). Embedding models, rerankers, and image-generation models are niches Future AGI does not ship. FAGI is the evaluation and observability companion:
fi.evalsfor retrieval quality (context recall, faithfulness, groundedness),fi.simulatefor replay against new embedding pipelines, and the Agent Command Center at/platform/monitor/command-centerfor production drift on the retriever or generator you pick.
Top coding-specific picks in March 2026
| Use case | Top pick | Score | Output $/M tokens |
|---|---|---|---|
| Multi-file code reasoning | Claude Opus 4.6 | 80.8% SWE-bench Verified | $25 |
| Terminal / agentic coding | GPT-5.4 | 75.1% Terminal-Bench 2.0 | varies |
| Live code generation | Gemini 3.1 Pro | 91.7% LiveCodeBench | $12 |
| GPQA Diamond reasoning | Gemini 3.1 Pro | 94.3% | $12 |
| Cost-sensitive open-weight | GLM-5.1 | MIT, competitive on agentic + coding | self-host |
| Coding harness + model | Forge Code + Gemini 3.1 Pro | 78.4% Terminal-Bench 2.0 | $12 (model) |
| Coding harness + model | Factory Droid + GPT-5.3 Codex | 77.3% Terminal-Bench 2.0 | (Codex tier) |
The harness contributes 2-6 points on top of raw model capability. The agent wrapping the model, including retry logic, tool-call validation, and intermediate-step evaluation, is the dominant production variable.
Best LLM for X: March decision framework
Choose Gemini 3.1 Pro if:
- You need 1M-token context (default in Google API since March 6).
- Multimodal pipelines (vision, video, audio) are core.
- US-data-residency cost matters and $2/$12 fits.
- You’re already in Google Cloud / Vertex AI.
Choose Claude Opus 4.6 if:
- You need GA multi-file code reasoning at the top of the leaderboard.
- Your agents run 50+ tool calls deep where reliability decay matters.
- You need strong refusal behavior and safety alignment.
- You’re already on Anthropic / Claude Code / MCP.
- (Note: upgrade to Claude Opus 4.7 on April 16 if continuing into Q2.)
Choose GPT-5.4 / GPT-5.4 Codex if:
- You’re building agentic terminal automation.
- Function calling is the dominant pattern.
- You need vision + audio with the OpenAI ecosystem.
- (Note: GPT-5.5 / GPT-5.5 Pro shipped April 23 with significant improvements.)
Choose Mistral Small 4 if:
- You want efficient self-hosting on a small datacenter footprint (4xH100 or equivalent).
- You need frontier-tier capability with Apache 2.0 license and full redistribution rights.
Choose Mistral Large 3 if:
- You want open-weight quality from a non-Chinese lab.
- Apache 2.0 specifically matters for redistribution.
- You’re on European data-residency requirements.
Choose Qwen 3.5 Small Series if:
- You’re fine-tuning for a vertical from a 0.8B-9B dense base.
- Multilingual coverage matters.
Choose GLM-5.1 if:
- Cost is the dominant constraint and you can use a Chinese-lab open-weight.
- MIT license matters for redistribution.
Choose Grok 4 if:
- Math and real-time data are core (X integration).
Common mistakes when picking an LLM in March 2026
- Trusting SWE-bench Verified alone. Even before Berkeley’s April paper, the Verified-vs-Pro gap was a trust signal. Claude Opus 4.6 at 80.8% Verified vs 45.9% Pro is a 35-point spread. Cross-reference with SWE-bench Pro or your own domain reproduction.
- Underestimating Mistral Small 4. “It’s small” → assumption of weak. Wrong. The MoE architecture means 6.5B active beats dense models 4-10x larger.
- Anchoring on Mistral Large 3 release date. It was December 2025 but the GA-throughout-March experience for production teams is what counts. Don’t skip it because it’s “old news”. it was in active production use through March 2026.
- Sleeping on the price war. 40-80% YoY price drops mean your March cost models for closed-source are wrong by mid-year. Plan for further compression in April-May.
Recent platform updates
| Date | Event | Why it matters |
|---|---|---|
| March 1 | Qwen 3.5 Small Series released | Open-weight fine-tuning bases at 0.8B-9B |
| March 3 | Gemini 3.1 Flash-Lite Preview | Fast, cheap variant for high-volume |
| March 6 | Gemini 3.1 Pro default in Google API | 94.3% GPQA Diamond becomes the default |
| March 9 | Gemini 3 Pro Preview discontinued | Migration deadline for legacy users |
| March 11 | NVIDIA Nemotron 3 Super at GTC | NVIDIA-stack open-source enterprise LLM |
| March 16 | Mistral Small 4 released | Efficient datacenter self-hosting ceiling moves up |
| March 27 | GLM-5.1 released, MIT | Chinese-lab open-weight at low cost |
Benchmark scores at-a-glance (end-of-March 2026)
| Model | SWE-bench Verified | SWE-bench Pro | Terminal-Bench 2.0 | GPQA Diamond | LiveCodeBench | Output $/M tok |
|---|---|---|---|---|---|---|
| Claude Opus 4.6 | 80.8% | 45.9% | 65.4% | 91.3% | 88.8% | $25 |
| GPT-5.4 | ~85% | . | 75.1% | 81% | . | varies |
| GPT-5.4 Pro | . | . | . | . | . | $180 |
| Gemini 3.1 Pro | . | . | 78.4% (with Forge) | 94.3% | 91.7% | $12 |
| Gemini 3.1 Flash-Lite | (lower) | . | . | (lower) | . | (lower) |
| GPT-5.3 Codex | 85% | . | 77.3% (Droid) | . | . | varies |
| Mistral Large 3 (carryover) | (open-weight) | (open-weight) | (open-weight) | (open-weight) | (open-weight) | self-host |
| Mistral Small 4 | (open-weight) | (open-weight) | (open-weight) | (open-weight) | (open-weight) | self-host |
| GLM-5.1 (Mar 27) | (open-weight) | (open-weight) | (open-weight) | (open-weight) | (open-weight) | self-host |
| Grok 4 Heavy | . | . | . | . | . | (varies) |
A reminder: the SWE-bench Verified-vs-Pro gap is already a trust signal in March. Claude Opus 4.6 at 80.8% / 45.9% is a 35-point spread. Production teams should anchor on SWE-bench Pro or run a domain reproduction.
How to actually pick one for production
The leaderboard is the wrong artifact to make a production decision from. Three things to do instead:
- Run a domain reproduction. Take 100-500 of your actual production prompts, run them through your three candidate models with your harness, and score with Future AGI evaluators (turing_flash at roughly 1 to 2 seconds, turing_small at 2 to 3 seconds, or turing_large at 3 to 5 seconds per check on the cloud tier) or your own LLM-as-judge. The gap between vendor scores and your reproduction is the signal.
- Measure reliability under load. Track the Reliability Decay Curve. agent success rate as a function of session length. Most frontier models lose 15-40% of headline accuracy at 50+ tool-call sessions, which public benchmarks never test. Use Future AGI Simulate (
fi.simulate.TestRunner) or roll your own. - Cost-adjust your scores. Headline scores hide 5-10x cost differences. With March’s 40-80% YoY price drops, the cost-adjusted leaderboard reorders meaningfully versus 2025. Recompute score-per-dollar across candidates on your domain.
Model choice alone no longer explains production outcomes. Distribution, harness quality, and reliability instrumentation are.
Sources
March 2026 frontier model state (primary):
- Gemini 3.1 Pro launch (Google blog, Feb 19)
- Gemini API pricing (Google AI for Developers)
- Mistral models documentation
- Mistral Large 3 announcement
- GLM-5.1 (Z.AI / Zhipu)
- NVIDIA Nemotron 3 Super foundation models
- Grok 4.20 Multi-Agent Beta (xAI docs, March 9)
- Claude Opus 4.6 (Anthropic)
Benchmarks and leaderboards:
- SWE-bench Pro Public Leaderboard (Scale)
- Terminal-Bench 2.0 Leaderboard
- Artificial Analysis Intelligence Index
Embeddings + strategic events:
- Gemini Embedding 2 Preview (Google, March 10)
- Sora discontinuation (OpenAI Help Center, March 24)
- Claude Design (Anthropic, April 17 2026, cross-month context)
Next: Best LLMs of April 2026 →. nine frontier releases in 30 days, Berkeley breaks the trust, DeepSeek V4 lands at roughly 1/34 the output price of GPT-5.5. And then: Best LLMs of May 2026 →→. distribution and architecture move while the model layer rests.
Frequently asked questions
What new LLMs were released in March 2026?
What is the best LLM in March 2026?
What is Mistral Small 4?
When did Gemini 3.1 Pro launch?
How did open-weight LLMs catch closed-source in March 2026?
What is the best open-source LLM in March 2026?
What is the best LLM for coding in March 2026?

Best LLMs May 2026: compare GPT-5.5, Claude Opus 4.7, Gemini 3.1 Pro, and DeepSeek V4 across coding, agents, multimodal, cost, and open weights.


Best LLMs April 2026: compare GPT-5.5, Claude Opus 4.7, DeepSeek V4, Gemma 4, and Qwen after benchmark trust broke and prices compressed fast.

State of frontier models, inference architecture, agents, evals, and distribution at the 2026 LLM app layer, with production picks for teams.
