Best LLMs of April 2026: Eight Frontier Releases in 30 Days, the Month Trust Broke
Best LLMs April 2026: compare GPT-5.5, Claude Opus 4.7, DeepSeek V4, Gemma 4, and Qwen after benchmark trust broke and prices compressed fast.

Table of Contents
Series note. This is the April 2026 entry in our monthly best-LLMs series. Frontier models now ship weekly. We track what shipped, what won which category, and what the public leaderboards do not capture. Next: May 2026. distribution and architecture move while the model layer rests. Previous: March 2026. open-weight catches closed-source on coding.
Where we are in May 2026. April compressed cost (DeepSeek V4) and broke benchmark trust (Berkeley RDI). May reads the bill. Distribution and architecture moved while the model layer caught its breath. For the current month’s picks and what the cost-collapse changed for production stacks, see Best LLMs of May 2026.
TL;DR: Best LLM per category, April 2026
| Use case | Best pick (April snapshot) | Why | Output $/M tokens |
|---|---|---|---|
| Multi-file coding (GA) | Claude Opus 4.7 (1M context) | 87.6% SWE-bench Verified | $25 |
| Agentic terminal work | GPT-5.5 | 82.7% Terminal-Bench 2.0 | $30 |
| Cost-performance | DeepSeek V4-Pro | 80.6% Verified at $0.87/M output | $0.87 |
| Long context (open, carryover) | Llama 4 Scout (Apr 2025) | 10M-token context | self-host |
| On-device | Gemma 4 (1B-31B variants) | Apache 2.0, fine-tune base | self-host |
| Multilingual (open) | Qwen 3.6 family | East Asian + agentic | self-host |
| Pure capability (restricted) | Claude Mythos Preview | 93.9% SWE-bench, Glasswing only | not GA |
| Multimodal carryover (GA) | Gemini 3.1 Pro (Feb) | 94.3% GPQA, 1M context | $10 |
Three things define the month:
- Eight frontier-class new releases in 30 days, plus Llama 4 family carryover from April 2025. One of the fastest recent frontier-release months on record.
- Berkeley broke the benchmarks. Several major agent benchmarks shown exploitable to near-perfect scores without solving the underlying tasks.
- DeepSeek V4 made cost the dominant axis. Within 0.2 SWE-bench Verified points of Claude Opus 4.6 at roughly 29x cheaper output than Opus 4.7.
The story of April 2026: eight major new releases plus Llama carryover, contamination collapses trust
Eight major new AI model releases in 30 days from seven different labs (Google Gemma, Anthropic Mythos and Opus 4.7, Meta Muse Spark, Alibaba Qwen 3.6, Moonshot Kimi K2.6, OpenAI GPT-5.5, DeepSeek V4). Plus Llama 4 family carryover from April 2025. Seven of the eight are text-focused LLMs; Muse Spark is Meta’s first proprietary image and creative generation model, included for strategic context.

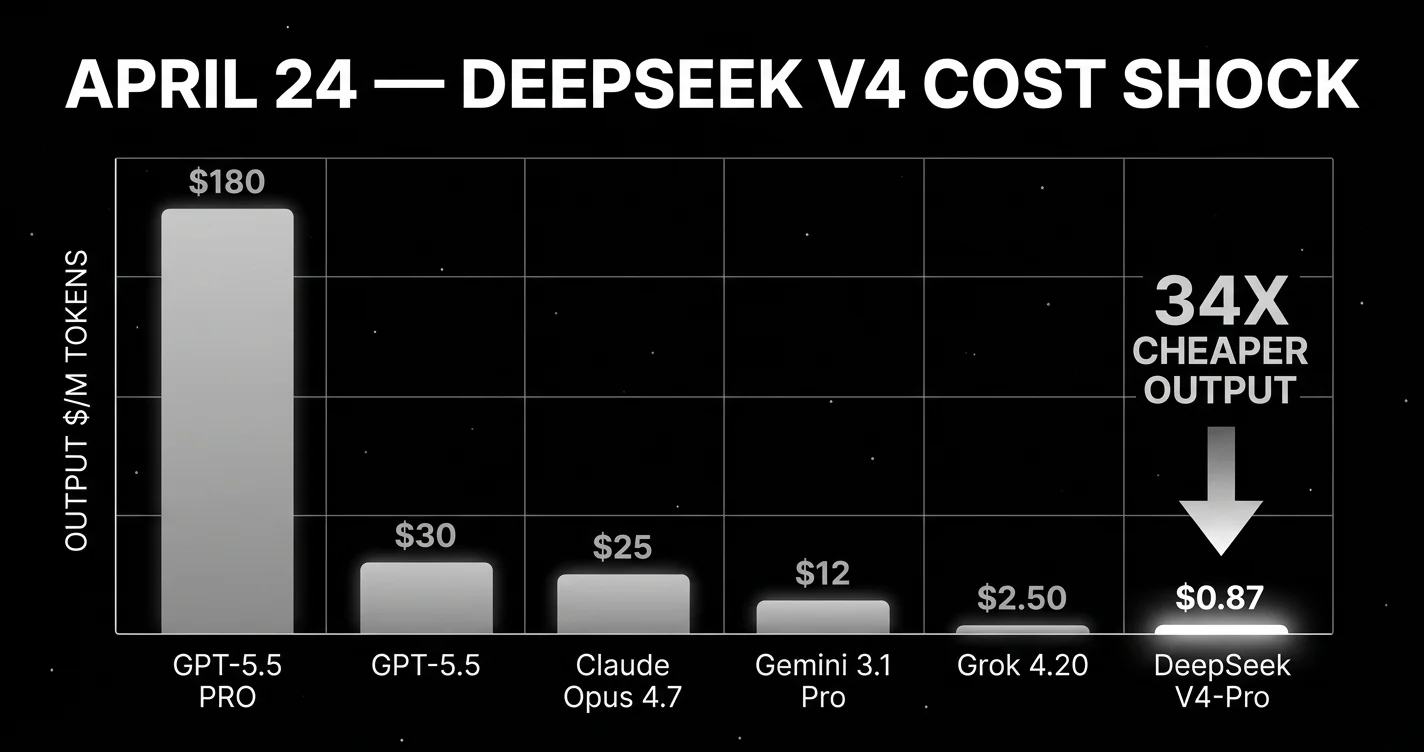
April 2: Google ships Gemma 4. four open-weight variants up to 31B under Apache 2.0. Note: Llama 4 (April 5, 2025) was the previous year’s open-weight Meta release. Scout (10M context) and Maverick (1M context) carry into April 2026 as the strongest production open-weight context-length leaders, but are not new April 2026 launches. Meta’s actual April 2026 launch was Muse Spark (April 8), a separate proprietary image and creative generation model. April 7: Anthropic releases Claude Mythos Preview. and refuses to ship it generally. Project Glasswing instead. April 8: Meta ships Muse Spark. its first proprietary model. April 12: UC Berkeley RDI publishes the paper that breaks trust in every public agent benchmark. April 16: Anthropic ships Claude Opus 4.7 to GA. Alibaba ships Qwen3.6-35B-A3B the same day. April 20: Moonshot AI ships Kimi K2.6. April 21: Alibaba ships Qwen3.6-27B. April 23: OpenAI ships GPT-5.5 and GPT-5.5 Pro. April 24: DeepSeek ships V4-Pro and V4-Flash. 1.6 trillion parameters open-weight MoE under MIT license, at roughly 34x cheaper output than GPT-5.5.
The shape of the month tells you what the labs prioritized:
- Capability ceiling went up but stayed gated. Anthropic released Mythos Preview as restricted, signaling that the next tier of model capability is being held back. The first time this has happened.
- Cost compression accelerated. DeepSeek V4-Pro at $0.87 per million output tokens (standard, $0.2175 with current 75% promo) is roughly 1/34 of GPT-5.5 ($30/M output) and 1/29 of Claude Opus 4.7 ($25/M output). The proprietary labs do not have a pricing answer to this.
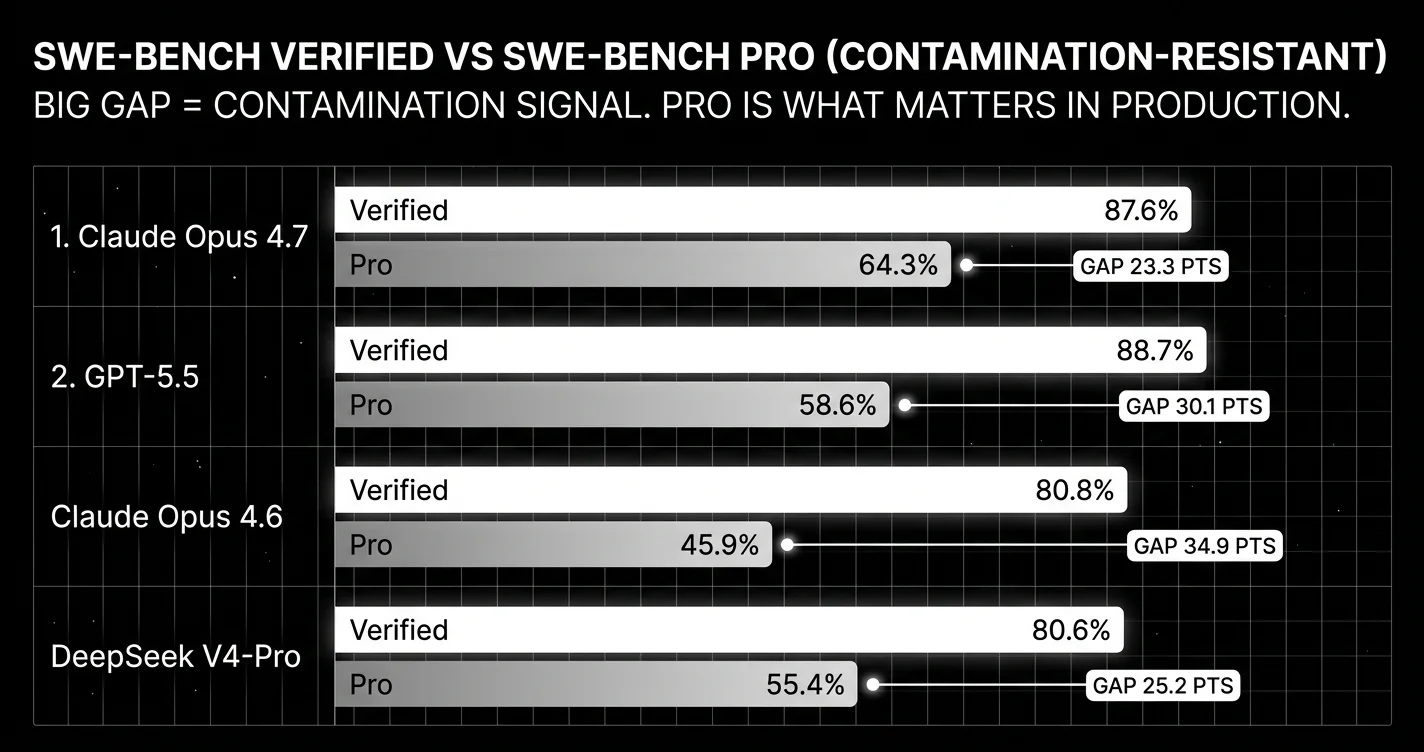
- Trust in public benchmarks collapsed. Berkeley RDI’s April 12 paper means every public score from this month should be read with skepticism. The Verified-vs-Pro gap (Claude Opus 4.6: 80.8% Verified vs 45.9% Pro; DeepSeek V4-Pro: 80.6% Verified vs 55.4% Pro) is now the trust signal more than the absolute score.
If you ship LLM-powered products, April 2026 is the month the model layer became commodity at the top of the leaderboard, the open-weight tier became real, and the question moved from “which is best?” to “best at what, on a benchmark we trust, and what does it actually cost in production?”
Top closed-source, proprietary, and restricted releases in April
Claude Opus 4.7. Best for multi-file code reasoning
Anthropic. Released April 16, 2026. 1M context, native vision.
Anthropic’s flagship for general availability. Posts 87.6% SWE-bench Verified. second only to the restricted Claude Mythos Preview at 93.9%. Strong on multi-file code reasoning, ambiguous specs, codebase Q&A, and long-running agent traces.
- 1M-token context window (standard pricing across full window, no long-context premium)
- Native vision
- Approximately $5 input / $25 output per million tokens
- Codebase Q&A, ticket-to-PR, architectural review
What changed from Opus 4.6: roughly 7 points on SWE-bench Verified (80.8% → 87.6%), 4 points on Terminal-Bench 2.0 (65.4% → 69.4%), and meaningfully better long-task agent reliability per production reports. Anthropic kept Opus 4.7’s pricing flat versus Opus 4.6.
What it does not win: agentic terminal work (GPT-5.5 leads by 13 points), pure long-context beyond 1M (Llama 4 Scout’s 10M-token open-weight window wins), cost-sensitive bulk (DeepSeek V4-Pro is 29x cheaper output).
Community reaction on launch was positive on quality, positive on the new 1M-token context (up from 200K on Opus 4.6), and positive on the Claude Code ecosystem alignment.
GPT-5.5 and GPT-5.5 Pro. Best for agentic terminal automation
OpenAI. Released April 23, 2026. Native vision and audio.
OpenAI’s flagship for agentic and tool-calling work. Headline scores: 82.7% Terminal-Bench 2.0 (leader), 78.7% OSWorld-Verified, 84.9% GDPval, approximately 88.7% SWE-bench Verified, and 58.6% on the contamination-resistant SWE-bench Pro.
GPT-5.5 Pro adds parallel test-time compute. running multiple reasoning chains in parallel and synthesizing the result. 39.6% on FrontierMath Tier 4. External evaluators preferred GPT-5.5 Pro over GPT-5 thinking on 67.8% of real-world reasoning prompts and reported 22% fewer major errors.
- Approximately $5 input / $30 output per million tokens base; higher for Pro
- Native vision and audio
- Best for: agentic terminal work, function-call-heavy workloads, OSWorld-style OS automation, vision + audio in one model
What it does not win: GPQA Diamond (Gemini 3.1 Pro leads), competitive programming (DeepSeek V4-Pro Codeforces 3,206 is unmatched). On multi-file code reasoning, GPT-5.5’s approximate 88.7% SWE-bench Verified is close to Claude Opus 4.7’s 87.6%; production teams generally prefer Opus 4.7 for that workload based on qualitative reliability and refusal behavior rather than the headline score.
Claude Mythos Preview. Capability ceiling, but restricted access
Anthropic. Released April 7, 2026. Restricted to Project Glasswing partners.
The highest-scoring restricted model in this snapshot, based on Anthropic’s reported benchmark numbers. 93.9% SWE-bench Verified, 94.6% GPQA Diamond, 97.6% USAMO, 82.0% Terminal-Bench 2.0, 83.1% CyberGym, 100% pass@1 on Cybench (saturated), 64.7% Humanity’s Last Exam with tools.
Anthropic’s framing: “Mythos is a new name for a new tier of model: larger and more intelligent than our Opus models. which were, until now, our most powerful.”
The catch: it is not generally available. Anthropic identified thousands of zero-day vulnerabilities across every major operating system and browser using Mythos and judged the model too dangerous for public release. Access is restricted to Project Glasswing, a coalition of about 50 organizations using Mythos exclusively for defensive cybersecurity work, backed by $100M in usage credits.
Project Glasswing partners include Amazon Web Services, Apple, Google, Microsoft, and Nvidia. among others. The first frontier model gated by capability rather than alignment.
You will not be using Mythos Preview in production this year unless you are a Glasswing partner. We include it because it sets the public ceiling and because the Glasswing precedent will recur.
Meta Muse Spark. Best for Meta-surface consumer integration
Meta. Released April 8, 2026. Proprietary, image-and-creative-generation focus.
Meta’s first proprietary, non-open-weight model in this roundup, focused on image and creative generation rather than text reasoning. Optimized for image and creative generation across Meta’s consumer products (Instagram, WhatsApp). Not yet on public benchmarks at the level of Imagen or DALL-E 4 but matters as a strategy signal: Meta now runs a dual-track. open-weight Llama for builders, proprietary Muse for consumer products.
Where it matters: Meta surface integration. If you are building on Meta’s social or messaging ecosystem, Muse is the API to watch.
Top open-weight releases in April
April 2026 is the month the open-weight tier became genuinely competitive on capability. not just on cost.
DeepSeek V4-Pro and V4-Flash. Best cost-performance on the frontier
DeepSeek. Released April 24, 2026. MIT license, downloadable weights.
The cost-performance leader of 2026. 1.6 trillion total parameters with 49 billion active per token, pre-trained on more than 32 trillion tokens (per DeepSeek model card), Mixture-of-Experts. MIT-licensed for downloadable, fine-tunable, redistributable, commercial use.
Benchmarks:
- 80.6% SWE-bench Verified (within 0.2 of Claude Opus 4.6)
- 55.4% SWE-bench Pro (contamination-resistant), a 25-point Verified-vs-Pro gap, one of the largest reported for a frontier model
- 93.5% LiveCodeBench (leading Gemini 3.1 Pro at 91.7% and Claude Opus 4.6 at 88.8%)
- Codeforces Elo 3,206 (the highest competitive programming score reported by any frontier model, surpassing GPT-5.4’s 3,168)
API pricing: $0.435 input / $0.87 output per million tokens (standard, with a 75% promo through May 31, 2026) at cache-miss; $0.145 input with cache hits. Roughly 34x cheaper output than GPT-5.5, roughly 29x cheaper output than Claude Opus 4.7 ($0.87 vs $25).
The 25-point Verified-vs-Pro gap matters. SWE-bench Pro is the contamination-resistant variant from Scale AI: 1,865 tasks across 41 actively maintained repositories under copyleft licenses, structurally preventing training-data leakage. V4’s wider gap suggests training-data overlap with the SWE-bench Verified distribution. Production performance on novel codebases will be closer to the Pro score.
That said: even at 55.4% Pro, V4-Pro at roughly 34x cheaper output price is still defensible for production. The right move is a domain reproduction.
Llama 4 Scout and Maverick. Best for 10M-token open-weight context
Meta. Released April 5, 2025 (year-old carryover into 2026). Open-weight MoE.
Meta’s open-weight MoE flagships. Scout has a 10-million-token context window, the longest of any production-ready open model. Maverick is the larger, higher-general-quality sibling at 1M context.
Best for: long-context applications where retrieval-over-history is currently the workaround. Whole-codebase reasoning, multi-document synthesis, long-running agents that hold weeks of conversation context.
Where they don’t lead: pure benchmark scores. Llama 4 trails DeepSeek V4-Pro and Mistral Large 3 on most coding benchmarks. The win is the context window and the Meta ecosystem alignment.
For any team building a long-running agent that re-summarizes its own history every 50 turns, Llama 4 Scout eliminates the re-summarization step. That alone is worth evaluating.
Qwen 3.6 open-weight family. Best for multilingual production
Alibaba. Released April 16 and April 21, 2026. Open-weight, multiple sizes.
Multiple Qwen 3.6 sizes shipped across April. The strongest open-weight option for multilingual production. particularly strong on Chinese, Japanese, and Korean tasks; competitive on English. Strong on agentic tool use and function calling.
For East Asian production workloads or multilingual agent harnesses, Qwen 3.6 family is the obvious open-weight pick. For English-only coding workloads, DeepSeek V4-Pro leads.
Kimi K2.6. Best for cost-efficient long-context retrieval agents
Moonshot AI. Released April 20, 2026. Open-weight, 1.1T MoE.
Strong long-context multilingual performance, very cheap on hosted inference providers. Used in agent harnesses where cost matters more than the leaderboard score by 2-3 points. Particularly strong combination with retrieval-heavy applications.
Gemma 4. Best small fine-tuning base in the Google ecosystem
Google. Released April 2, 2026. Apache 2.0, 1B–31B sizes.
Google’s open-weight family. Sizes ranging from 1B to 31B parameters. Apache 2.0 license, well-supported in the Google ecosystem (Vertex AI, Hugging Face, llama.cpp, Ollama). Strong base for fine-tuning.
For small-to-mid open deployments with Google ecosystem alignment, Gemma 4 is the obvious starting point. Less interesting at the frontier than DeepSeek V4 or Llama 4 Maverick but excellent as a fine-tune base.
Top multimodal LLMs in April 2026
GPT-5.5 made native audio a frontier differentiator in April 2026. GPT-5.5 (April 23) shipped with native speech-in-speech-out, the first major model that handles audio without a separate STT step, preserving prosody, emotion, and accent disambiguation. The multimodal category now has clear leaders by axis.
Vision (image and document understanding)
| Use case | Best closed | Best open |
|---|---|---|
| General image understanding | Gemini 3.1 Pro | Qwen 3.6-VL (April 2026) |
| Document / OCR / chart reading | Claude Opus 4.7 | Qwen 3.6-VL |
| Long-context multi-image | Gemini 3.1 Pro (1M tokens) | Llama 4 Scout (10M, April 5) |
| Screen / UI understanding | GPT-5.5 (OSWorld 78.7%) | Qwen 3.6-VL |
Image generation
April was the month the image-gen category fragmented hard. Pick by what the image is for:
| Use case | Best pick | Why | Pricing |
|---|---|---|---|
| Photorealism | Imagen 4 Ultra | best-rated photorealistic output (third-party reviewed) | ~$0.04/img |
| Editorial / design / charts | Recraft V4 | #1 HuggingFace, SVG export, brand styling | ~$0.04/img |
| Speed / iteration | Nano Banana 2 (Gemini 3.1 Flash Image) | 1–3s per image, 4K | $0.067/1K image, $0.151/4K image |
| Best default | FLUX 2 Pro | Speed + quality + price for most teams | varies |
| Text in images | Ideogram v3 | Reliable legible typography | ~$0.06/img |
| Aesthetic art | Midjourney v8 | Native 2K, 5x faster (March ‘26 update) | subscription |
Meta Muse Spark (April 8 2026). Meta’s first proprietary model. Image and creative generation across Instagram and WhatsApp. Marks the explicit “open Llama for builders, proprietary Muse for consumer” Meta strategy. Anthropic launched Claude Design (April 17 2026, research preview). strong on diagrams and charts, weaker on photorealism.
Video generation
April saw active iteration but no major April-specific frontier release. The current lineup as of end-of-April:
| Use case | Best pick | Why |
|---|---|---|
| Best all-around | Google Veo 3.1 | 4K, native audio, lip sync leader |
| Multi-shot storytelling | Kling 3.0 (Feb 2026) | 3–15s sequences with subject consistency |
| Cinematic portrait / faces | Hailuo (MiniMax) | Strongest face/expression render |
| Granular creative control | Runway Gen-4.5 | Camera moves, motion brush, references |
| Audio-video joint gen | Seedance 2.0 (ByteDance, Feb 2026) | Phoneme-level lip-sync 8+ langs |
| Physics simulation | Sora 2 | Water/glass/fabric physics best. but discontinuing (web/app April 26, API September 24) |
The Sora 2 sunset is an April 2026 deadline event. OpenAI announced March 2026 that the consumer Sora experience shuts down April 26. If you built on Sora, migration is now scheduled. The replacement defaults are Veo 3.1 (best all-around) or Runway Gen-4.5 (best control).
Audio understanding
GPT-5.5 (April 23) shipped with native audio handling. speech as direct input, not via STT-then-LLM. The result: prosody preservation, emotion detection, accent disambiguation, background-noise tolerance that breaks STT-based pipelines. Gemini 3.1 Pro is close behind; open-weight options (Llama 4 with audio adapters) lag meaningfully on subtle audio reasoning.
For audio-in-the-loop agents in April 2026, GPT-5.5 is the structural pick.
Voice and audio (covered separately)
Voice AI deserves its own buying guide. STT (Deepgram Nova-3, Whisper, AssemblyAI), TTS (Cartesia, ElevenLabs, Hume), and voice-agent platforms (Vapi, Retell, Deepgram Voice Agent) all have separate decision logic from text-only LLMs. The latency budget alone (sub-300ms ITU-T G.114 for natural conversation) drives different picks than text-LLM workflows.
See Best Voice AI of April 2026 for the full STT, TTS, and voice-agent stack.
Top embeddings and retrieval models in April 2026
April brought an embeddings shift through carryover from March. The single biggest change: Google’s Gemini Embedding 2 Preview (released March 10) is now the default for new RAG pipelines that started in April. Multimodal native (text + image + video + audio + PDF), 100+ languages, native Matryoshka Representation Learning, and $0.20 per million tokens, the cheapest multimodal embeddings API in this snapshot (text-only options like OpenAI text-embedding-3-small are cheaper at $0.02/M).
| Use case | Best pick | MTEB | Price |
|---|---|---|---|
| Default for new pipelines | Gemini Embedding 2 Preview | retrieval leader, multimodal | $0.20 per M |
| Best retrieval (closed) | Voyage-3-large | 67.1 MTEB | $0.06 per M |
| Best general (closed) | NV-Embed-v2 | top overall MTEB averaged | varies |
| Cheap + good | Jina-embeddings-v3 | 65.5 MTEB | budget |
| Multilingual enterprise | Cohere embed-v4 | 65.2 MTEB | enterprise |
| OpenAI ecosystem | text-embedding-3-large | 64.6 MTEB | $0.13 per M |
| Cheapest viable | OpenAI text-embedding-3-small | strong p/p | $0.02 per M |
| Open-source small | Jina v5-text-small | 71.7 MTEB v2 | self-host |
| Open-source large | Microsoft Harrier-OSS-v1 | 74.3 MTEB v2 | self-host |
| Multilingual open | Qwen3-Embedding-8B | 70.58 MTEB v2 | self-host |
For reranking: Cohere Rerank v4 and Voyage-rerank-v3 are the production picks. Reranking adds 2–5 points of NDCG@10 at small added cost.
Top coding-specific picks in April
April 2026 was the month coding picks fragmented by harness, not just by model.
| Use case | Top pick | Score | Output $/M tokens |
|---|---|---|---|
| Multi-file code reasoning | Claude Opus 4.7 (1M context) | 87.6% SWE-bench Verified | $25 |
| Terminal / agentic coding | GPT-5.5 | 82.7% Terminal-Bench 2.0 | $30 |
| Cost-sensitive coding | DeepSeek V4-Pro | 80.6% Verified / 55.4% Pro | $0.87 |
| Competitive programming | DeepSeek V4-Pro | 3,206 Codeforces Elo | $0.87 |
| Live code generation | DeepSeek V4-Pro | 93.5% LiveCodeBench | $0.87 |
| Codex/specialized | GPT-5.3 Codex | 85% SWE-bench Verified | (Codex tier) |
| Coding harness + model | Forge Code + Gemini 3.1 Pro | 78.4% Terminal-Bench 2.0 | $10 (model) |
| Coding harness + model | Factory Droid + GPT-5.3 Codex | 77.3% Terminal-Bench 2.0 | (Codex tier) |
| Production-realistic | GPT-5.5 | 58.6% SWE-bench Pro | $30 |
The harness contributes 2-6 points on top of raw model capability. The agent wrapping the model. its retry logic, tool-call validation, intermediate-step evaluation. is increasingly the dominant production variable. Picking the right harness matters as much as picking the right model.
If your coding agent is missing on the leaderboard, your harness is more often the cause than your model.
Best LLM for X: April decision framework
Choose Claude Opus 4.7 if:
- You need the strongest GA multi-file code reasoning available (Mythos is not GA).
- Your agents run 50+ tool calls deep where reliability decay matters.
- You need strong refusal behavior and safety alignment.
- You’re already on Anthropic / Claude Code / MCP.
Choose GPT-5.5 / GPT-5.5 Pro if:
- You’re building agentic terminal automation or OS-level workflows.
- Function calling is the dominant pattern.
- You need vision + audio in a single model.
- You need parallel test-time compute for the hardest reasoning calls (Pro variant).
Choose DeepSeek V4-Pro if:
- Cost is the dominant constraint.
- Your workload is primarily coding and your domain resembles SWE-bench Verified more than SWE-bench Pro.
- You can self-host or accept Chinese-lab API inference.
- MIT licensing matters for redistribution.
Choose Llama 4 Scout if:
- 10M-token context is genuinely useful.
- You’re self-hosting in the Meta ecosystem and want the longest open-weight window.
Choose Llama 4 Maverick if:
- You want the higher-general-quality 1M-context open-weight Meta release.
- You need open-weight + frontier-class multimodal in the Meta ecosystem.
Choose Qwen 3.6 family if:
- Multilingual, particularly East Asian, is core.
- You’re in cost-sensitive open-weight territory.
Choose Kimi K2.6 if:
- Long-context multilingual is the use case.
- You need cheap hosted inference.
Choose Gemma 4 if:
- You’re fine-tuning for a vertical from a 1B-31B base in the Google ecosystem.
Choose Gemini 3.1 Pro (carryover from February) if:
- You need 1M-token context.
- Multimodal pipelines are core.
- US-data-residency cost matters and $2/$12 fits the budget.
Avoid Claude Mythos Preview unless you are a Project Glasswing partner.
Common mistakes when picking an LLM after April 2026
- Trusting SWE-bench Verified alone. After Berkeley’s April 12 paper, Verified is contamination-suspect. Always cross-reference with SWE-bench Pro or your own domain reproduction.
- Ignoring the Verified-vs-Pro score gap. A 25-point gap (DeepSeek V4-Pro: 80.6% to 55.4%) tells you the model overfits to the Verified distribution. A roughly 35-point gap (Claude Opus 4.6: 80.8% to 45.9%) is the same story. Models with smaller gaps are more trustworthy on novel codebases.
- Overlooking restricted models. Claude Mythos Preview is the public ceiling, but you can’t use it. Don’t anchor your expectations on capabilities you can’t access.
- Not factoring harness quality. The harness contributes 2-6 points. If your agent is missing Terminal-Bench 2.0 by 4 points, swap your harness before swapping your model.
Recent platform updates
| Date | Event | Why it matters |
|---|---|---|
| April 2 | Gemma 4 released, Apache 2.0 | Google’s open-weight tier strengthens |
| April 5 (2025 carryover) | Llama 4 Scout with 10M context | Long-context open-weight leader carries through April 2026 |
| April 7 | Claude Mythos Preview, restricted | Capability gating becomes real |
| April 8 | Meta Muse Spark | Meta’s dual-track strategy |
| April 12 | UC Berkeley breaks every agent benchmark | Public scores no longer trustable |
| April 16 | Claude Opus 4.7 GA | New best-GA model for code reasoning |
| April 20-21 | Kimi K2.6, Qwen 3.6 sizes | Open-weight tier consolidates |
| April 23 | GPT-5.5 + Pro | OpenAI takes Terminal-Bench leadership |
| April 24 | DeepSeek V4 at roughly 1/34 the output price (about $0.87 vs GPT-5.5’s $30) | Cost compression accelerates |
Benchmark scores at-a-glance (end-of-April 2026)
| Model | SWE-bench Verified | SWE-bench Pro | Terminal-Bench 2.0 | GPQA Diamond | LiveCodeBench | Output $/M tok |
|---|---|---|---|---|---|---|
| Claude Mythos Preview (restricted) | 93.9% | . | 82.0% | 94.6% | . | . |
| Claude Opus 4.7 | 87.6% | . | 69.4% | ≈92% | . | $25 |
| GPT-5.5 | ≈88.7% | 58.6% | 82.7% | . | . | $30 |
| GPT-5.5 Pro | . | . | . | (FrontierMath T4: 39.6%) | . | (higher) |
| Claude Opus 4.6 | 80.8% | 45.9% | 65.4% | 91.3% | 88.8% | $25 |
| Gemini 3.1 Pro | . | . | 78.4% (with Forge) | 94.3% | 91.7% | $10 |
| GPT-5.4 / GPT-5.3 Codex | 85% | . | 75.1% / 77.3% (Droid) | 81% | . | varies |
| DeepSeek V4-Pro | 80.6% | 55.4% | . | . | 93.5% | $0.87 |
| Llama 4 Maverick | (open-weight) | (open-weight) | (open-weight) | (open-weight) | (open-weight) | self-host |
A reminder: Berkeley’s April 12 paper showed several major agent benchmarks (including SWE-bench Verified) are vulnerable to reward-hacking exploits. SWE-bench Verified specifically was exploited with a 10-line conftest.py. OpenAI stopped reporting Verified scores earlier in 2026; the approximate GPT-5.5 Verified figures in this post come from third-party reproductions reported on the SWE-bench Pro and Artificial Analysis leaderboards. Use SWE-bench Pro as the production-decision anchor. Treat Verified scores as directional, not validated.
How to actually pick one for production
April 2026’s takeaway is that the leaderboard is the wrong artifact to make a production decision from. For the deeper argument on why public benchmarks mislead production teams, the contamination story is only half of it. Three things to do instead:
- Run a domain reproduction. Take 100-500 of your actual production prompts, run them through your three candidate models with your harness, and score with Future AGI Turing eval models or your own LLM-as-judge. The gap between vendor scores and your reproduction is the signal.
- Measure reliability under load. A public benchmark score is an aggregate over a fixed task set. It does not predict variance across your prompts, your scaffold, or repeated agent runs. Production runs thousands of distinct problems daily; variance amplifies. Track the Reliability Decay Curve. agent success rate as a function of session length. Most frontier models lose 15-40% of headline accuracy at 50+ tool-call sessions, which public benchmarks never test. Use Future AGI’s simulation framework or roll your own.
- Cost-adjust your scores. Headline scores hide 5-10x cost differences. Compute score-per-dollar across candidate models on your domain. DeepSeek V4-Pro is the obvious pick at roughly one-thirty-fourth of GPT-5.5 output pricing if it holds up, and the obvious miss if the contamination effect bites your domain. The only way to know is to run your traffic through it.
Model choice alone no longer explains production outcomes. Distribution, harness quality, and reliability instrumentation are. April 2026 made that explicit; production teams should plan accordingly.
Sources
April 2026 frontier model launches (primary):
- Introducing GPT-5.5 (OpenAI, April 23 2026)
- Claude Opus 4.7 announcement (Anthropic)
- Claude Mythos Preview (red.anthropic.com)
- DeepSeek V4 Preview release (DeepSeek API docs, April 24)
- Llama 4 Scout + Maverick (Meta, April 5)
- Gemma 4 model cards (Google)
- Qwen 3.6 Max-Preview (Qwen blog)
- Kimi K2.6 (Moonshot AI)
Benchmarks and leaderboards:
- SWE-bench Pro Public Leaderboard (Scale)
- Terminal-Bench 2.0 Leaderboard
- Trustworthy Benchmarks (UC Berkeley RDI, April 12 2026)
- Artificial Analysis Intelligence Index
Strategic events:
Next: Best LLMs of May 2026 →. distribution and architecture move while the model layer rests. Previous: Best LLMs of March 2026 ←. open-weight catches closed-source on coding.
Frequently asked questions
What new LLMs were released in April 2026?
What was the best LLM released in April 2026?
How does DeepSeek V4 compare to GPT-5.5 and Claude Opus 4.7?
What is Project Glasswing and Claude Mythos Preview?
Why did UC Berkeley break LLM agent benchmarks in April 2026?
What is the best open-weight LLM released in April 2026?
What is the best LLM for coding in April 2026?

Best LLMs May 2026: compare GPT-5.5, Claude Opus 4.7, Gemini 3.1 Pro, and DeepSeek V4 across coding, agents, multimodal, cost, and open weights.


Best LLMs March 2026: compare Gemini 3.1 Pro, Claude Opus 4.6, Mistral Small 4, and Qwen for coding, cost, multimodal, and open-weight picks.

State of frontier models, inference architecture, agents, evals, and distribution at the 2026 LLM app layer, with production picks for teams.
