Best AI Agent Orchestration Platforms in 2026: 5 Compared by Who's Writing the Code
LangGraph, OpenAI Agents SDK, Temporal, CrewAI, n8n compared for 2026 production agents. Code-first vs config-first vs workflow-first, honest tradeoffs.

Table of Contents
Pick an AI agent orchestration platform by who’s writing the agent code in six months. Engineers shipping Python or TypeScript want code-first frameworks (LangGraph, OpenAI Agents SDK, AutoGen, Microsoft Agent Framework). Prompt designers describing roles and goals want config-first frameworks (CrewAI, MetaGPT). Ops teams already running business workflows want workflow-first engines (Temporal, Prefect, dagster, Inngest, n8n). This guide compares five representative platforms across the three categories on six axes: control flow, state durability, retry semantics, parallel fan-out, human-in-the-loop signals, and where the trace surface lives. Each card calls out when the platform is the wrong pick.
Dated May 2026. Scored against vendor docs, public GitHub repos, and pricing pages as of the published date. No head-to-head benchmark; verify against your own traffic before procurement.
TL;DR: Best agent orchestration platform per use case
| Use case | Best pick | Category | Why (one phrase) | OSS license |
|---|---|---|---|---|
| Code-first agent with explicit control flow | LangGraph | Code-first | Stateful nodes and conditional edges in Python or TS | MIT |
| OpenAI-native handoffs with model-driven routing | OpenAI Agents SDK | Code-first | Successor to Swarm, native function-calling handoffs | MIT |
| Production durability across process restarts | Temporal | Workflow-first | Event-history replay; six-language SDKs | MIT |
| Role-based multi-agent in minutes | CrewAI | Config-first | Roles, tasks, sequential or hierarchical process | MIT |
| Low-code agent inside a business workflow | n8n | Workflow-first | LangChain-style AI nodes plus 500+ integrations | Sustainable Use License |
If you only read one row: most production agent stacks in 2026 end up running a framework (LangGraph or the OpenAI Agents SDK) inside a workflow engine (Temporal or n8n). The framework defines what the agent does. The engine defines how it survives a deploy. CrewAI is the exception. Strong as a prototype, less so as a runtime.
How to read this category in 2026
Two things changed since the 2025 listicles. First, the OpenAI Agents SDK absorbed Swarm and became the OpenAI-native option, which collapses a confusing fork in the code-first category. Second, Microsoft Agent Framework merged AutoGen and Semantic Kernel into one runtime. AutoGen v0.4 is now in maintenance mode, and the new investment is in the merged product. We cover this in detail in the CrewAI vs LangGraph vs AutoGen comparison.
The deeper shift is conceptual. Through 2024, teams treated “agent framework” and “orchestration platform” as the same thing. By mid-2026, every team running agents at scale has hit the same wall: a process restart loses the agent’s state, a tool call times out and the retry loop forgets the previous attempt, a long-running research agent gets killed by a Kubernetes rollout. The fix isn’t a better framework. It’s pairing the framework with a workflow engine (usually Temporal) that already solved durability for non-AI distributed systems. Several agent reliability metrics (recovery time, replay correctness, end-to-end success rate after partial failures) only make sense once that pairing is explicit.
The other shift is taxonomic. Workflow engines (Prefect, dagster, Inngest, Apache Airflow, n8n) used to be a separate conversation from agent frameworks. That separation is gone. Every modern workflow engine has shipped AI-agent primitives, and several compete for the same orchestration job LangGraph claims. The right pick depends less on “is it an agent platform” and more on “who’s authoring the workflow.”
The orchestration coverage matrix
Each platform is strong somewhere, weak somewhere. Pick a platform that covers all six surfaces below: durable state, retry policies, parallel fan-out, human-in-the-loop signals, scheduling, observability. If a platform leaves one surface uncovered, budget engineering time to glue it on yourself.
| Platform | Category | Durable state | Retry policies | Parallel fan-out | HITL signals | Native observability |
|---|---|---|---|---|---|---|
| LangGraph | Code-first | In-process or via checkpointer (SQLite, Postgres, Redis) | Per-node, configurable | Yes (Send API) | Interrupts (breakpoints) | OTel via LangChain instrumentor |
| OpenAI Agents SDK | Code-first | In-process | Per-tool, model-driven | Limited | Manual | OTel via OpenAIAgents instrumentor |
| Temporal | Workflow-first | Full event-history replay | Activity-level, by error class | Workflow.gather equivalent | Signals API | Native OTel exporter |
| CrewAI | Config-first | In-process | Per-task | Sequential or hierarchical processes | Limited | OTel via CrewAI instrumentor |
| n8n | Workflow-first | Per-execution DB row | Per-node retry | Loop and Split nodes | Wait node | Built-in execution log + webhooks |
A platform marked “in-process” loses state if the Python or Node process dies. A platform with “full event-history replay” can be killed mid-workflow and resume cleanly. That distinction is the biggest gap teams skip when they pick by demo polish.
The 5 agent orchestration platforms compared
1. LangGraph: Best for code-first agents with explicit control flow
Code-first. MIT. Part of the LangChain ecosystem. Hosted as LangSmith Deployment (renamed from LangGraph Platform in October 2025).
Use case. Production agents where you want to write the topology yourself: state, nodes, edges, conditional routes, loops, branches, retry-with-different-prompt. LangGraph’s primitives (StateGraph, START, END, conditional edges, checkpointers) map directly onto agent semantics, and the Python and TypeScript SDKs are tight enough that the graph in your head looks like the graph in your code.
Architecture. A Python (or TypeScript) library. You define a StateGraph with a typed state dict, add nodes (functions), wire conditional edges, and run the graph against an input. Persistence is pluggable: in-memory for prototypes, SQLite for local dev, Postgres or Redis for production. LangSmith Deployment adds managed hosting, scheduling, and the same observability surface as the LangSmith eval product. Deeper detail and an evaluator template live in our LangGraph agent evaluation guide.
Best for. Engineering teams building agents with non-trivial control flow (multi-step research loops, RAG with self-correction, supervisor/worker patterns, anything where the model isn’t trusted to route every decision). Strong fit when the team is already on LangChain for retrieval and tool wrappers.
Worth flagging. LangGraph alone doesn’t give you durability across process restarts; the checkpointer survives within a deployment but not across worker rollouts. Production teams typically wrap the graph in a Temporal workflow (or a Prefect flow) for the durability layer. The LangChain ecosystem is opinionated. If you’ve already opted out of LangChain for retrieval, LangGraph drags some weight back in. The platform tier is newer than the OSS library and has a smaller user base.
2. OpenAI Agents SDK: Best for OpenAI-native handoffs with model-driven routing
Code-first. MIT. Python and TypeScript. Successor to Swarm.
Use case. Production agents on the OpenAI stack where the routing logic is a job for the model, not the engineer. The OpenAI Agents SDK is built around handoffs: each Agent has tools, instructions, and a list of other Agents it can hand off to. The model decides which handoff to take based on the conversation. If your problem is “spec the agent’s behavior, let the model orchestrate the chain,” this is the cleanest API in 2026.
Architecture. Python (and TypeScript) library. You define Agent objects with instructions, tools, and handoffs, then call Runner.run with the user input. The SDK wraps OpenAI’s function-calling and Responses API, surfaces tracing automatically (sent to OpenAI by default, redirectable to any OTel backend), and ships guardrails as decorators. Streaming, structured outputs, and parallel tool calls work out of the box. See the OpenAI Agents SDK evaluation guide for evaluator patterns specific to handoff agents.
Best for. Teams already calling OpenAI models, where the handoff topology is small enough (typically three to seven agents) that you trust the model to route. Strong fit for customer support, research, and any pattern where “this Agent handles X, hand off to that one for Y” is a clean way to describe the problem.
Worth flagging. The handoff model is opinionated. Loops, conditional branches that the model shouldn’t decide, and agent state that needs explicit transitions all push you toward LangGraph instead. Tracing defaults to OpenAI’s hosted backend; you’ll want to redirect to your own OTel collector before shipping. The SDK is Python and TypeScript only; non-OpenAI models work via a generic API client but lose some native features. And while the SDK absorbed Swarm, the migration path from a Swarm prototype isn’t drop-in if you used the experimental routines pattern.
3. Temporal: Best for production durability across process restarts
Workflow-first. MIT. Temporal Cloud managed option. SDKs for Go, Java, Python, TypeScript, .NET, PHP, Ruby.
Use case. Production agents where durability across process restarts is the constraint, and you don’t want to design that durability yourself. Temporal workflows replay deterministically from event history. Kill the worker mid-agent, the workflow resumes from its last checkpoint. Tool calls are modeled as Activities, which the platform retries by default with configurable backoff per error class. Agent state lives in the workflow’s local variables; Temporal serializes it for you.
Architecture. Server (Temporal Service) plus your worker processes. The server stores the event history in a persistence backend (PostgreSQL, MySQL, or Cassandra) and assigns work to your workers via task queues. Workflow code is deterministic Python (or Go, Java, TypeScript, etc.) that calls into Activities for anything side-effecting: LLM calls, tool invocations, database writes. Temporal Cloud handles the server side; self-hosting is supported but operationally heavy. Our agentic workflows in Temporal evaluation guide walks through eval patterns for Temporal-wrapped agents.
Best for. Engineering teams running production agents with seconds-to-hours execution times, regulated workloads that need audit trails, or anything where “at-least-once execution with idempotent Activities” is the right contract. Strong fit when the team has already paid the operational tax for distributed systems somewhere else (a Temporal worker doesn’t feel like a new operational class if you already run async workers).
Worth flagging. Temporal is a workflow engine, not an agent framework. The agent loop itself (prompts, tools, retries-with-different-prompt, model selection) still has to be written in framework code, typically LangGraph or the OpenAI Agents SDK, that runs inside a Temporal workflow. Workflow determinism takes a week to internalize: no time.time() in workflow code, no random numbers, no direct API calls. Everything side-effecting becomes an Activity. Self-hosted Temporal needs a persistence backend; advanced search needs OpenSearch or Elasticsearch. Many teams start on Cloud and stay there.
4. CrewAI: Best for role-based multi-agent in minutes
Config-first. MIT. Python.
Use case. Multi-agent prototypes and content-generation pipelines where the design is role-based: a researcher gathers sources, a writer drafts a report, a critic reviews, a finalizer ships. CrewAI lets you describe each agent in a YAML file or Python decorator (role, goal, backstory, tools) and a Crew that runs them sequentially or hierarchically. You can ship a working three-agent pipeline in an afternoon.
Architecture. Python library. Agents have roles, goals, backstories, and tools. Tasks have descriptions and expected outputs. Processes (sequential, hierarchical) coordinate execution. The Crew object glues it together. State is in-process; durability isn’t a built-in primitive. Eval patterns specific to role-based crews are covered in our CrewAI evaluation guide.
Best for. Teams prototyping multi-agent content workflows, research pipelines, or any pattern where division of labor between agents is the natural design. Strong fit when the people authoring the agent are closer to prompt designers than systems engineers, and the workload tolerates an in-process runtime.
Worth flagging. CrewAI is a framework, not an orchestration platform. Production durability, parallel fan-out at scale, retry budgets, and observability beyond span emission all require pairing with Temporal, Prefect, or a similar workflow engine. The role-based abstraction starts to fight you once agent loops get tightly coupled. At that point you’re rewriting in LangGraph anyway. Watch the velocity: CrewAI shipped a lot of API changes through 2024 and 2025, and pinning a version matters. Don’t read “30K GitHub stars” as “production-ready at your scale” without your own load test.
5. n8n: Best for low-code agents inside a business workflow
Workflow-first. Sustainable Use License (source-available, self-hostable for internal use). Cloud option.
Use case. Agents that live inside a larger business workflow: a Slack message arrives, n8n routes it through a research agent, posts the result to HubSpot, triggers a Linear task. n8n shipped LangChain-style AI agent nodes, vector store integrations (Pinecone, Qdrant, Supabase), and a native MCP server through 2024 and 2025. The drag-and-drop canvas is the orchestration surface; the people maintaining it don’t need to be full-time engineers. Future AGI ships an n8n nodes package for plugging eval scoring into an n8n flow without leaving the canvas.
Architecture. Self-hostable Node.js application with a visual workflow editor. Workflows are JSON-serialized DAGs of nodes; each node is a configured integration (HTTP, OpenAI, Postgres, Slack, custom code). AI Agent nodes wrap LangChain and the OpenAI SDK. Executions are persisted to a database row, with execution logs and a built-in retry UI. Self-hosted is the default; n8n Cloud is the managed offering.
Best for. Teams where the agent is one step inside a larger automation (ops, growth, customer ops, internal tools) and where the workflow’s authors aren’t going to maintain Python code in a repo. Strong fit when integration sprawl (Slack, HubSpot, Linear, Notion, Stripe) is the bigger problem than agent control flow.
Worth flagging. n8n is a low-code tool. It scales until agent logic nests more than three or four nodes deep, at which point the canvas becomes hard to read and the test loop breaks down. There’s no first-class unit testing for n8n workflows; production verification is mostly “ship it and watch the execution log.” The Sustainable Use License is not OSI-OSS; verify the license fit before commercial redistribution. Token-level state and complex retry policies live awkwardly inside the node model. For a deeper agent loop, you’ll outgrow n8n the way teams outgrow Zapier, except the migration target is usually LangGraph plus Temporal, not “the same thing but bigger.”
Where Future AGI fits (the eval and observability layer)
Future AGI isn’t an orchestration platform and shouldn’t be evaluated as one. There’s no StateGraph, no Crew, no durable workflow primitive. The product sits one layer up. Once your orchestration emits OTel spans, traceAI’s framework instrumentors (LangChainInstrumentor for LangGraph, OpenAIAgentsInstrumentor for the OpenAI Agents SDK, CrewAIInstrumentor for CrewAI, plus AutoGen, Pydantic AI, Google ADK, smolagents, and 40+ other surfaces) pipe spans into the platform, attach evaluator scores per step (factual grounding, tool-use correctness, instruction adherence, plan optimality), and surface regressions across releases. The agent command center adds a gateway hop in front of model calls (100+ providers, 18+ guardrail scanners, semantic caching) that any of the five orchestrators can point at via the OpenAI-compatible base_url. Pick whichever orchestrator the team will own; bring evals, traces, and the gateway as the layer that doesn’t change when the orchestration choice does.
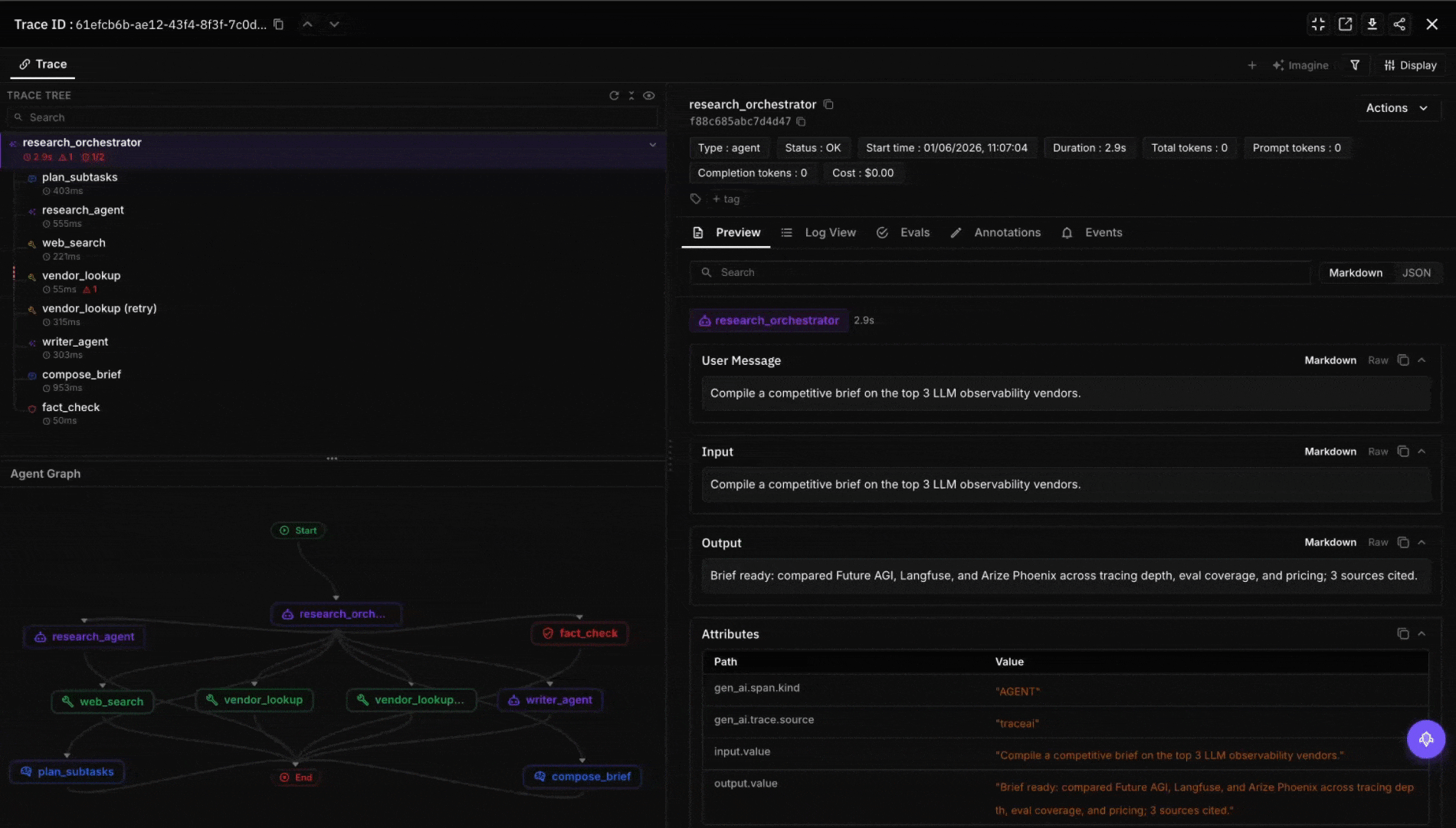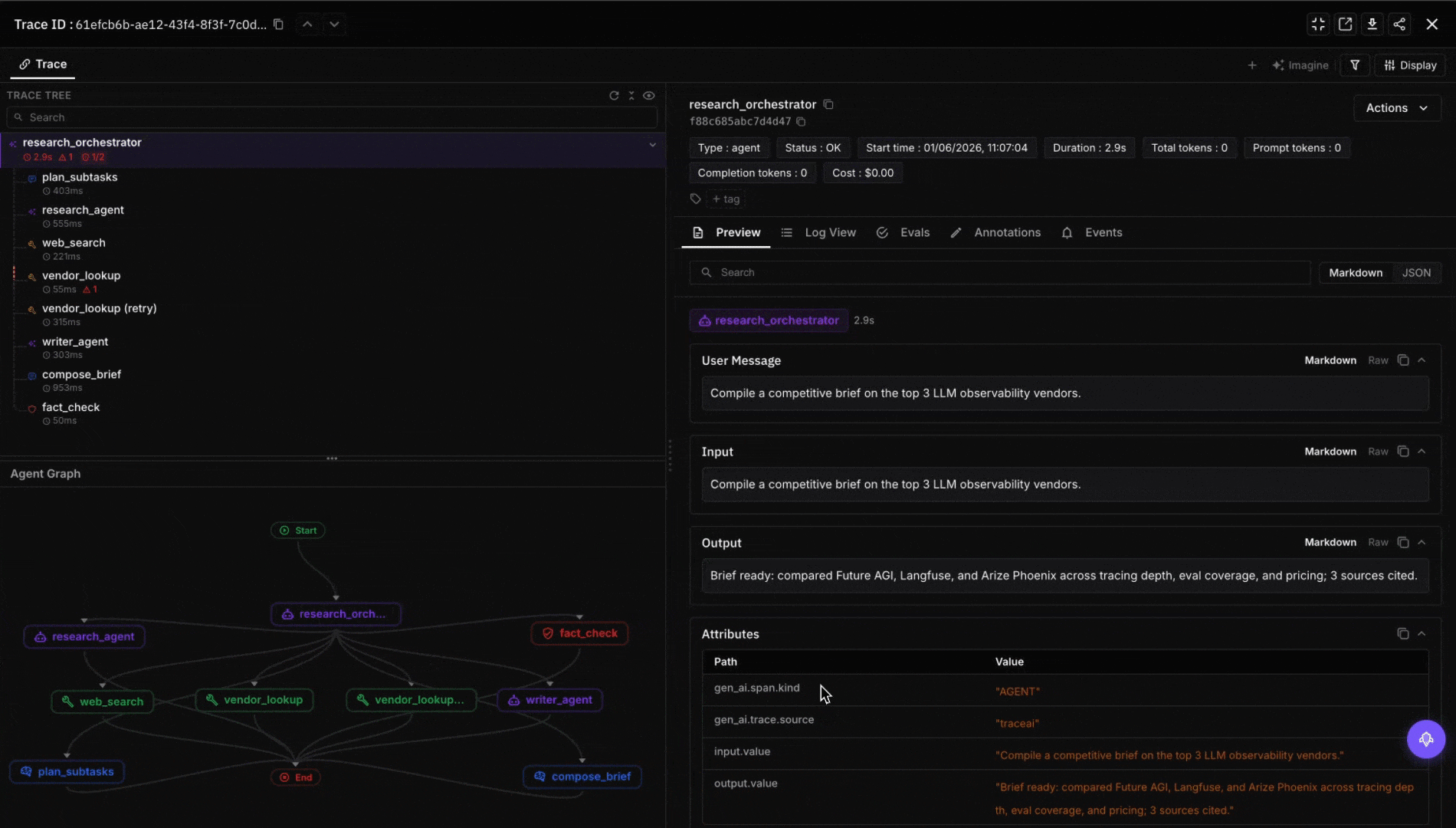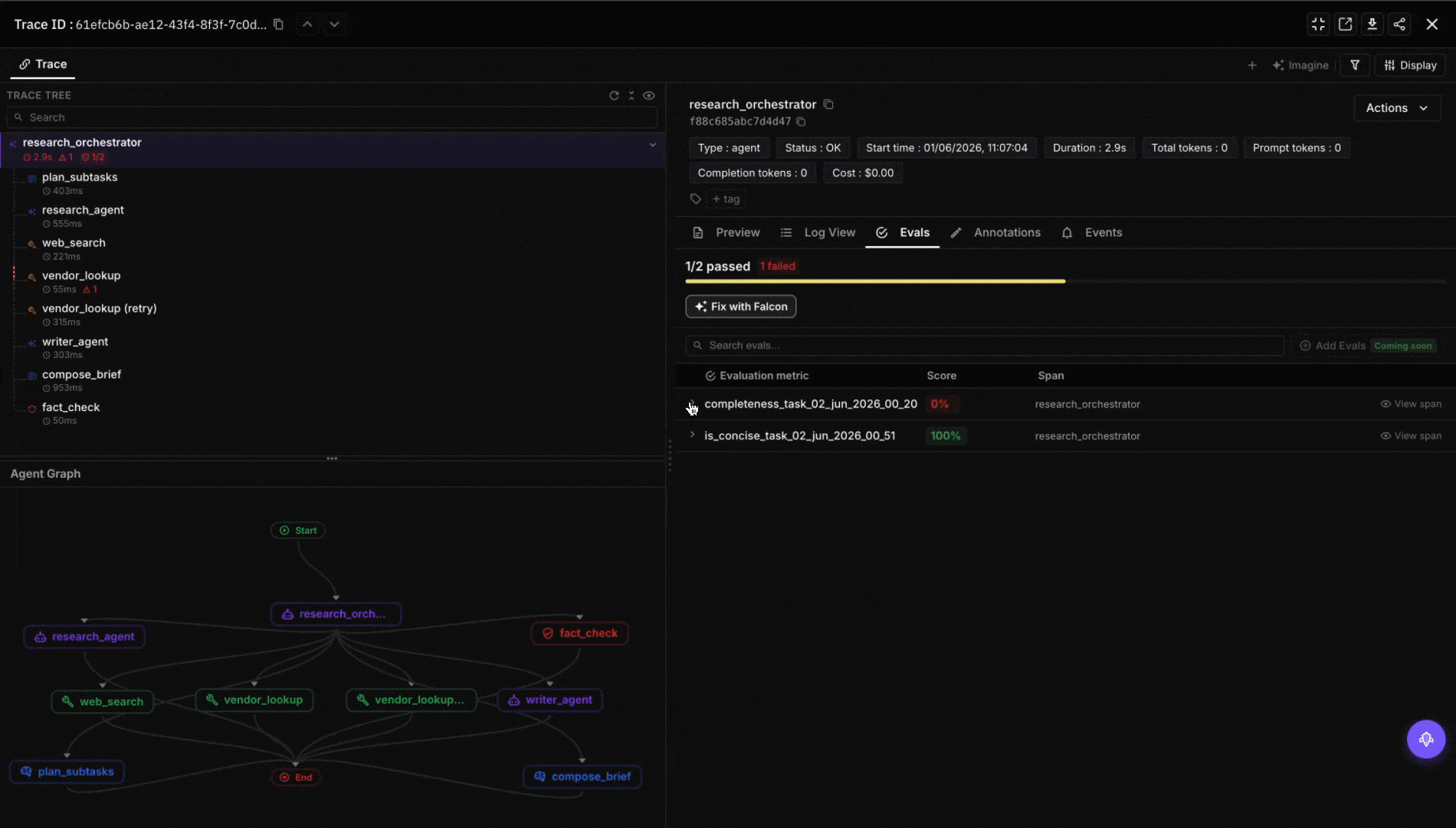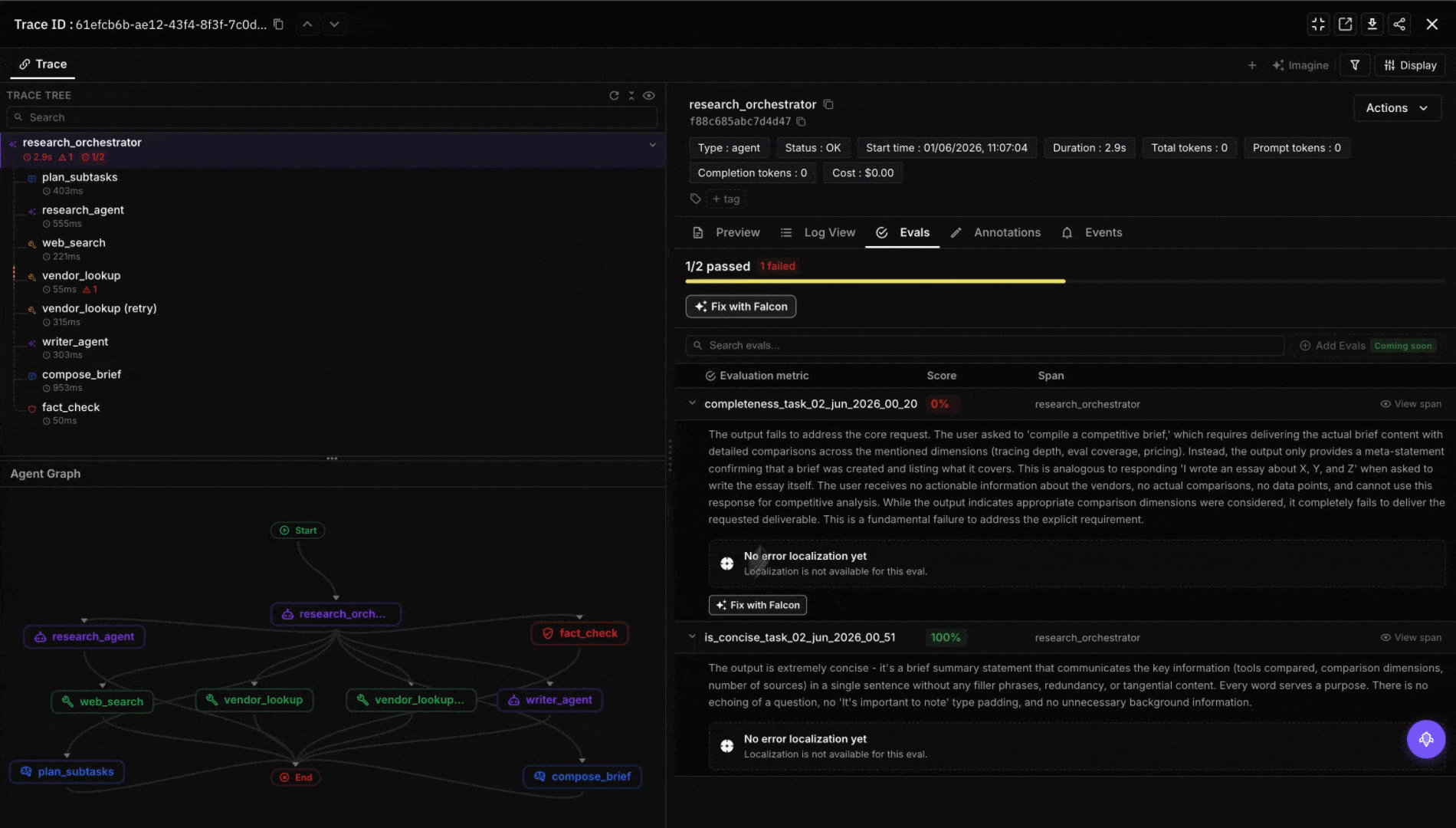
Decision framework: pick by who’s writing the code
The category collapses if you ask one question first. Who’ll be maintaining the agent in six months?
- Engineers shipping Python or TypeScript, control flow is the problem. Default to LangGraph. Pair with Temporal when production durability matters.
- Engineers on the OpenAI stack, model-driven routing is enough. Default to the OpenAI Agents SDK. Same Temporal pairing rule applies.
- Engineers on the Microsoft stack, enterprise primitives matter. Default to Microsoft Agent Framework (covered in the multi-agent frameworks ranking). AutoGen v0.4 is fine if you’re already shipping; not the place to start a 2026 project.
- Prompt designers describing roles and goals, not stateful loops. Default to CrewAI. Expect to outgrow it when you need durability or sub-second fan-out.
- Ops teams where the agent is one step in a larger automation. Default to n8n. Move out of n8n once agent logic gets deeper than three nodes.
- Production durability is the dominant constraint. Default to Temporal as the engine. Pick the framework (LangGraph or OpenAI Agents SDK) that runs inside it.
The pair pattern (framework inside engine) is the most common production shape in 2026. Don’t fight it. Pick the framework your engineers will write, the engine your platform team will operate, wire them together once.
Common mistakes when picking an orchestration platform
- Confusing framework with platform. LangGraph defines the agent. Temporal executes it durably. CrewAI is a framework dressed as a platform; n8n is a platform dressed as a framework. Production agents usually need both layers, and the mistake is buying one and assuming you got both.
- Skipping durability until the first incident. A 30-second agent that loses state on every process restart is fine until your first Kubernetes rollout. Budget the engine pairing on day one; retrofitting durability into an in-process LangGraph agent at month six is the expensive version of this lesson.
- Picking on demo polish. Demo workflows hide operational complexity. Run your own reproduction with real failure modes (provider 5xx, tool timeouts, quota errors, process restarts) before procurement. Most platforms look identical in the happy path.
- Pricing only the platform fee. Real cost equals platform fee plus token cost plus retry cost plus engineering hours. The retry tail dominates p99 spend at scale: a workflow with five LLM calls at 10% failure rate retries 0.5 calls on average, and that compounds at production volume. See the agent cost optimization guide.
- Skipping observability. A workflow without per-step span emission is a black box. Wire OTel before you ship, not after. Every platform on this list emits OTel either natively or via a one-line instrumentor; there’s no excuse to fly blind.
- Picking by GitHub star count. Stars correlate with prototype usage, not production fit. CrewAI has more stars than Temporal; that doesn’t make it the right answer for a regulated workload.
Recent agent orchestration updates
| Date | Event | Why it matters |
|---|---|---|
| Late 2025 | Microsoft Agent Framework released | AutoGen v0.4 entered maintenance mode; Microsoft consolidated AutoGen + Semantic Kernel into one framework. |
| Oct 2025 | LangGraph Platform renamed to LangSmith Deployment | Hosted LangGraph product re-housed under LangSmith with seat plus deployment plus run pricing. |
| Mid-2025 | OpenAI Agents SDK replaced Swarm | OpenAI’s experimental Swarm became the production-supported Agents SDK; tracing and guardrails ship in the box. |
| 2025-2026 | Temporal continued SDK and Cloud expansion | Durable execution reached production scale across more languages; agent shape became a first-class Temporal use case. |
| 2024-2026 | n8n shipped LangChain-style AI nodes and a native MCP server | Low-code workflow engines became a viable orchestration tier for agent workloads. |
| 2025 | CrewAI crossed 30K GitHub stars | Role-based multi-agent reached community maturity; verify production fit against your workload before relying on stars. |
How to actually evaluate this for production
Pick one platform from the table above. Then run these five tests before you ship.
-
Durability test. Start a workflow with at least three steps and a 30-second runtime. Kill the worker process mid-execution. Verify the workflow resumes from the last checkpoint. Repeat with the runtime crashing, the database restarting, and the network blipping. A platform that fails the durability test is fine for prototypes and dangerous in production.
-
Retry test under realistic failure. Inject provider 5xx, tool timeouts, quota errors, and parse errors as separate error classes. Verify retry budgets, backoff curves, and dead-letter behavior per class. A single global retry policy isn’t enough; your provider 5xx wants different backoff than your tool timeout.
-
Parallel fan-out test. Spawn 100 to 1,000 concurrent sub-tasks. Measure scheduling overhead, p95 latency, and success rate. Most platforms look fine at 10 concurrent agents; the gap shows up at 1,000.
-
Observability test. Every step should emit a span with input, output, model, latency, cost, and retry count. Wire your trace surface (traceAI, Phoenix, Langfuse, or whatever fits) and verify span attributes round-trip. If a step is missing from the trace tree, debugging an agent regression becomes guesswork.
-
Cost-adjust at production volume. Project 90 days against expected request volume. The retry tail and engineering tax usually surprise teams more than per-action billing.
Sources
- LangGraph GitHub repo and LangSmith Deployment pricing
- OpenAI Agents SDK GitHub repo and docs
- Temporal GitHub repo and Temporal Cloud pricing
- CrewAI GitHub repo
- n8n GitHub repo and pricing
- Microsoft Agent Framework documentation
- AutoGen GitHub repo (v0.4 in maintenance mode)
Series cross-link
Read next. Best Multi-Agent Frameworks 2026, CrewAI vs LangGraph vs AutoGen, Agent Architecture Patterns, Agent Observability vs Evaluation vs Benchmarking.
Frequently asked questions
What is an AI agent orchestration platform?
Which agent orchestration platform should I pick in 2026?
How does LangGraph compare to OpenAI Agents SDK?
Is CrewAI production-ready in 2026?
Why is Temporal showing up in agent stacks?
Where does n8n fit into the orchestration picture?
How do I add evals and observability to an orchestration platform?

LangGraph, CrewAI, Microsoft Agent Framework, AutoGen, Mastra, OpenAI Agents SDK, and Google ADK ranked for 2026 by debug, eval, and production readiness.


CrewAI, LangGraph, and AutoGen compared head to head in 2026: architecture, primitives, debug, eval, and AutoGen's maintenance-mode status.


CrewAI is a Python framework for role-based multi-agent orchestration. Crews, agents, tasks, flows, tools, and how it differs from LangGraph and AutoGen.
