Agentic vs Non-Agentic AI: The 2026 Definition
Agentic vs non-agentic AI explained. Workflows vs agents, the eval shape that changes, and when each architecture is the right call in production.

Table of Contents
Agentic vs non-agentic AI is not a debate about model size or intelligence. It is a debate about who controls flow. Non-agentic systems do one thing: prompt in, completion out, no loop. Agentic systems loop, call tools, revise plans, and carry state across steps. Anthropic drew the cleanest line in the field: workflows are systems where LLMs are orchestrated through predefined paths; agents are systems where the LLM dynamically directs its own processes and tool use. The line matters because the eval shape, the observability shape, and the failure modes are different on the two sides. This guide is the working definition for ML engineers and tech leads who keep getting these terms thrown at them, plus the framework for picking the right shape for a given task.
TL;DR: the line in one table
| Dimension | Non-agentic (workflow) | Agentic |
|---|---|---|
| Flow control | Application code, fixed | LLM picks next step at runtime |
| Tools | None or fixed-position | Variable, chosen by the model |
| State | Stateless across turns | Stateful across steps |
| Unit of eval | Input + output pair | Full trajectory |
| Unit of trace | Single span | Tree of parent-child spans |
| Failure modes | Bad output, hallucination, refusal | All of the above, plus wrong tool, bad args, plan loop, missed recovery |
| Latency | 1-3 seconds typical | 10-60 seconds typical |
| Token cost | 1x baseline | 5-20x baseline |
| Best fit | Classification, summarization, RAG, single-shot Q&A | Customer support with branching, code agents, research, multi-step transactional flows |
If only one row matters: the LLM picks the next step (agentic) or the application code does (non-agentic). Everything else follows from that.
The definition that holds up
A system is agentic when three properties are simultaneously true:
- A loop where the LLM decides what to do next. The model is not just generating output; it is choosing the next step from a set of options (call this tool, retrieve this chunk, ask this sub-agent, terminate). The loop runs until a stopping criterion is met.
- Tool calls as a first-class capability. The LLM can invoke functions, APIs, or sub-agents. Tool argument generation is part of the LLM’s job; tool argument validation is part of the runtime’s job.
- State across steps. The LLM has access to intermediate results. Step 5 can refer to the output of step 3. Without state, you have a single LLM call wrapped in a
forloop, which does not earn the agentic label.
A system that has all three is agentic. A system that has one or two is augmented but not agentic. A pipeline of three LLM calls with fixed prompts and no model-driven branching is augmented. A loop where the LLM picks the next call dynamically based on the previous result is agentic.
Anthropic’s framing (Building effective agents, Dec 2024) names the same line with different words: workflows are systems where LLMs and tools are orchestrated through predefined code paths; agents are systems where LLMs dynamically direct their own processes and tool usage. The first runs on rails. The second drives the train.
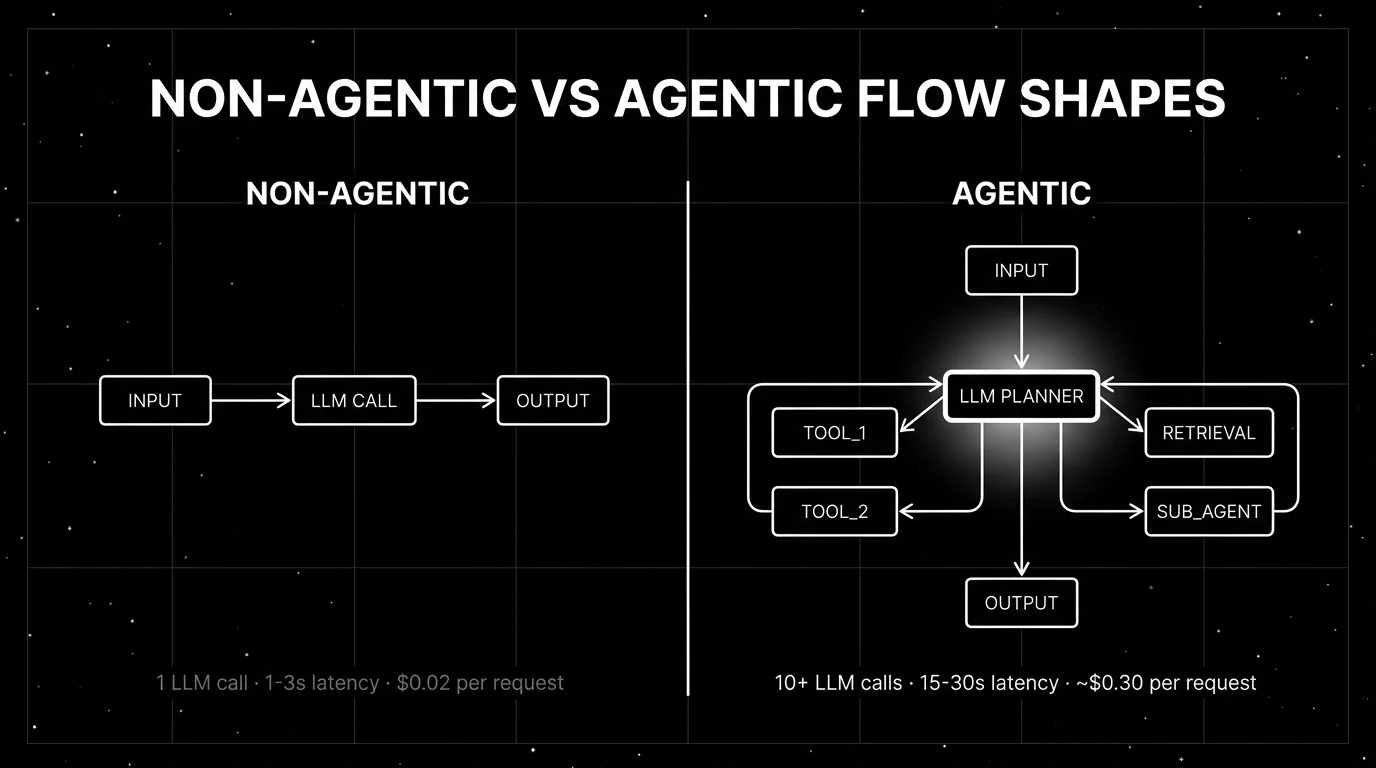
Non-agentic patterns in production
Three shapes cover almost every non-agentic system shipping today.
Prompt and response. The simplest case. Single LLM call. Input goes in, output comes out, application code does the rest. Classification, summarization, sentiment, format transformation, JSON extraction, simple chat completion. This is the bulk of what most SaaS products call “AI features.” An agentic loop here adds latency and cost without buying capability.
Plain RAG. Embed the query, retrieve top-k chunks, stuff them into the prompt, generate. The retrieval step is fixed; the LLM does not decide whether to retrieve. Application code does. RAG is the most common production pattern in 2026 and the most commonly mislabelled. A RAG pipeline that always retrieves, with no model-driven re-retrieval, is non-agentic. The presence of retrieval does not make a system agentic; the presence of model-driven retrieval does.
One-shot tool call. The LLM call uses function calling to fire exactly one tool, the application takes the result, and that is the request. Think: “format my reply as a calendar event” with a single create_event function bound to the call. One call in, one call out, no loop. This is non-agentic because the model never sees its own tool return; the next request, if one happens, starts fresh.
What these three share: the application controls the shape of the request, the LLM produces output inside a slot the application defined, and a request is finished when the LLM returns. The unit of eval is one input plus one output. The unit of trace is one span.
Agentic patterns in production
Four patterns cover most production agents in 2026. The framework choice (LangGraph, CrewAI, OpenAI Agents SDK, Pydantic AI, AutoGen) follows the pattern; the pattern follows the task.
ReAct. The default loop. The LLM produces a thought, an action, and an observation; cycle until done. Works for general agents with a variable tool set and unknown task structure. Step budget 12 to 15. The canonical fit for unfamiliar tasks where you do not know up front how many tool calls the agent will need. ReAct earned its place not because it is sophisticated but because it is the simplest loop that still lets the model pick the next step.
Plan-then-execute. A planner produces a complete plan upfront; an executor follows it. Works when the task has predictable substeps. Step budget 5 to 10. More controllable than ReAct because the plan is inspectable before any tool fires. Common in workflows where a failed step should not silently spawn a new branch.
Supervisor-worker. A supervisor agent delegates to specialized worker sub-agents. Works for tasks with clear delegation structure (research with separate writer and reviewer agents, customer support with separate intent-classifier and resolver agents). Each delegation is a fresh LLM call, so cost grows fast.
Graph-based orchestration. A state machine where the LLM is the transition function. LangGraph is the reference implementation. Works when the topology is fixed but the path through it is not. The graph encodes the legal transitions; the LLM picks which transition fires next based on state.
What these share: the LLM is in the loop, choosing the next step from a runtime-defined option set, with memory of what came before. The unit of eval is the trajectory. The unit of trace is a tree.
Why the eval shape changes
Non-agentic eval is a function from (input, output) to a score. You grade the response with Groundedness, Answer Relevance, Faithfulness, Toxicity, or a custom rubric. One judge call per request. Cheap.
Agentic eval is a function from trajectory to a score, where a trajectory is the full ordered sequence of system prompt, user input, agent reasoning, tool calls (name plus arguments plus return), retrieval results, intermediate LLM calls, final response, and outcome metadata. You cannot score this from the response alone. A response that looks right can come from the wrong tool with wrong arguments by luck. A response that looks wrong can come from a correct trajectory the rubric did not anticipate. The trace is the truth.
Six dimensions matter for agentic eval, and they need to be scored independently:
- Tool selection. Did the agent pick the right tool, or correctly call none?
- Argument extraction. Schema-valid and semantically correct arguments?
- Result utilization. Did the agent use the tool payload or substitute model knowledge?
- Error recovery. Did it retry, fall back, or escalate on tool failure?
- Plan coherence. Loop-free, dead-end-free, right depth?
- Task completion. Did the trajectory deliver the user goal end-to-end?
Aggregate task-completion alone hides which dimension regressed. A 0.85 aggregate can hide a 0.62 on argument extraction behind a 0.97 on tool selection. The production failure rides on the argument layer, and the aggregate score never sees it. Per-dimension scoring tells you what to fix this afternoon. See the definitive guide to AI agent evaluation for the rubric set.
There is also a math problem unique to agentic systems. End-to-end success on a k-step agent is roughly the product of per-step success rates, which is why agent reliability is best tracked as several SLOs rather than one score. A 95% per-step agent over eight steps lands near 66%. A 99% per-step agent over eight steps lands near 92%. Trajectories ending structurally wrong while every individual step looks green is the default behaviour of compound error. The per-step rubric is the gate; the trajectory metric is the truth.
Why the observability shape changes
A non-agentic request is one span. You record input, output, latency, cost, model, and a few attributes. The OTel span carries everything you need. One row in your trace store, one card in your trace UI.
An agentic request is a tree. A root span for the agent invocation, child spans for every tool call, retrieval, sub-agent, inner LLM call, and guardrail check, all under the same trace ID with parent-child relationships. Without the tree, you cannot localise a failure to the step that caused it. The agent that said the wrong thing on turn 1 might have done it because the wrong tool fired three steps back, with wrong arguments, against a stale cache. A single-span log shows the answer; the trace tree shows the cause.
This is where things get thin if you try to bolt agentic monitoring onto a single-span observability stack. You need:
- Span kinds that distinguish AGENT, TOOL, RETRIEVER, LLM, CHAIN, RERANKER, EMBEDDING, GUARDRAIL, EVALUATOR. A flat span list is unusable.
- Auto-instrumentation for the framework. LangGraph node topology, CrewAI role hand-offs, OpenAI Agents SDK runs, Pydantic AI typed tool calls. Hand-rolling spans on every framework breaks the first time the framework releases a minor version.
- Span-attached eval scores. When a CI rubric fires on a live span, the score lives on the span. No engineer cross-references two dashboards under production pressure.
- Pluggable semantic conventions. The OTel GenAI spec is converging; your collector should let you switch between FI, OTEL_GENAI, OpenInference, and OpenLLMetry without re-instrumenting.
traceAI (Apache 2.0) ships 14 span kinds and 50+ AI surfaces across Python, TypeScript, Java, and C#. The same SDK captures the single-span non-agentic case and the trace-tree agentic case. The LangGraphInstrumentor exposes node_count and conditional-edge topology, so multi-agent graphs are introspectable from the trace alone.
The decision framework: which shape, and when
Five questions. If three or more lean agentic, build agentic. Otherwise build non-agentic.
- Does the task branch on intermediate results? A customer support flow that may need a lookup, then maybe an escalation, then maybe a refund, branches. A “classify this ticket” flow does not.
- Does the task call tools the model picks at runtime? A code agent reading errors and patching files picks. A “summarize this doc” flow does not.
- Is the latency budget over 10 seconds? Chat under three seconds rules out non-trivial agentic. Batch jobs and human-in-the-loop flows tolerate the agentic premium.
- Can the workload afford 5 to 20 times the token cost? A 10-step agent at 2K tokens per step is 20K tokens. Multiply by request volume. The capability has to be worth it.
- Is the failure mode of a wrong tool call acceptable with guardrails? Destructive tools (delete, refund, send email) raise the bar. The agentic premium is wasted if you cannot pay the runtime guardrail cost.
The framework is opinionated. A task that branches but has a two-second latency budget and no guardrail budget should not be agentic. Most “AI features” inside SaaS products belong in non-agentic shape. Most “AI products” with their own brand belong in agentic shape. The line is task-shape, not buzzword.

Common mistakes when picking between the two
- Going agentic by default. “We need an agent” without checking task shape gets you 15x cost and 10x latency on classification work. Classification, summarization, and format transformation almost never need agents.
- Wrapping a single LLM call in a for-loop and calling it agentic. A fixed-prompt loop is not agentic. The LLM has to decide the next step for the workflow to count.
- Confusing RAG with agentic RAG. Plain RAG with one fixed retrieval pass is non-agentic. Model-driven re-retrieval is agentic RAG. The difference matters for eval (single-pass Groundedness vs trajectory-level retrieval quality) and trace shape (one retrieve span vs many).
- Eval on final answer only. A correct-looking final answer can come from a 12-step trajectory that should have been four steps. Trajectory length, tool-call accuracy, and retrieval quality are first-class metrics.
- No step budget. An agent without a hard step budget can loop forever on hard tasks. Set one (12-15 for ReAct, 8-10 for tool-augmented, 5 for plan-execute) and fail explicitly when exceeded.
- No tool argument validation. A correctly-selected tool with attacker-controlled arguments is the failure mode that wrecked real production agents in 2025. Schema validation is the floor; semantic validation is the ceiling.
Where FutureAGI fits across both shapes
Most teams running mixed workloads end up with two reliability stacks: one for the single-call surfaces, one for the agent trajectories. The work duplicates: two trace collectors, two eval surfaces, two policy planes. The eval-stack package collapses that into one runtime.
- traceAI (Apache 2.0) auto-instruments single-call and multi-step flows alike. 14 span kinds, 50+ AI surfaces across Python, TypeScript, Java, and C#. Pluggable semantic conventions (FI, OTEL_GENAI, OpenInference, OpenLLMetry) at
register()time. The non-agentic request lands as one LLM span; the agentic request lands as a trace tree with TOOL, AGENT, RETRIEVER, GUARDRAIL, and EVALUATOR spans under the same root. - ai-evaluation SDK (Apache 2.0) ships 50+ evaluators. The non-agentic side: Groundedness, Answer Relevance, Faithfulness, Hallucination, Toxicity, Tone, Factual Accuracy. The agentic side: seven
AgentTrajectoryInputmetrics (TaskCompletion, StepEfficiency, ToolSelectionAccuracy, TrajectoryScore, GoalProgress, ActionSafety, ReasoningQuality) plusLLMFunctionCalling,ConversationCoherence, and 11CustomerAgent*templates. The same rubric runs offline in CI and online against production traffic, attached to the span viaEvalTag. - Agent Command Center is the OpenAI-compatible gateway. 100+ providers, 18+ built-in guardrail scanners (PII, prompt injection, hallucination, tool-permissions, system-prompt protection, MCP security), exact and semantic caching, OTel-native observability, MCP and A2A protocol support. Switching from a non-agentic to an agentic shape is a routing rule change, not a re-platforming. Self-host the Apache 2.0 Go binary or point an OpenAI SDK at
gateway.futureagi.com/v1. - The Future AGI Platform layers self-improving evaluators, classifier-backed scoring at lower per-eval cost than Galileo Luna-2, and Error Feed (HDBSCAN clustering on failing trajectories, a Sonnet 4.5 Judge that writes a 5-category 30-subtype taxonomy, the 4-D trace score, and an
immediate_fixper cluster) on top of the SDK surface.
The agentic-vs-non-agentic shape choice no longer dictates the reliability stack. The same SDK, the same gateway, the same dashboard cover both.
What to do next
Pick the shape from task properties, not framework preference. If three or more decision-framework questions lean agentic, build agentic. Wire trajectory eval before you ship; aggregate scoring on agentic systems hides the regression that will fire on Monday morning. If the shape is non-agentic, do not over-engineer; a 30-line Python function calling the LLM directly will outperform a framework abstraction for the first 100K requests. Either way, instrument with traceAI on day one, attach evals via EvalTag so production scores carry the same vocabulary as CI, and promote failing traces back into the offline set weekly.
Related reading
Frequently asked questions
What is the difference between agentic and non-agentic AI?
Is RAG agentic or non-agentic?
Why does the agentic vs non-agentic line matter for evaluation?
Why does observability look different for agentic systems?
When should I build agentic instead of non-agentic?
What are the common agentic patterns and when do they fit?
Does FutureAGI evaluate both agentic and non-agentic shapes?

Six AI agent reliability solutions compared in 2026 across five layers: runtime guardrails, CI eval gates, span-attached scoring, clustering, closed loop.


Observability watches. Evaluation judges. Benchmarking ranks. The conceptual map of the three terms agent teams conflate, with metrics, cadence, and tools.

Best LLMs May 2026: compare GPT-5.5, Claude Opus 4.7, Gemini 3.1 Pro, and DeepSeek V4 across coding, agents, multimodal, cost, and open weights.
