Agent Architecture Patterns in 2026: The Five Named Shapes
Five agent architecture patterns in 2026: ReAct, plan-then-execute, supervisor and workers, graph, event-driven. Four-axis tradeoff per pattern.
Table of Contents
A refund agent built on a ReAct loop handles 87 percent of customer requests in 1.4 seconds across three tool calls. The same agent burns through 14 seconds and 19 tool calls on the next 11 percent because the model gets stuck comparing two refund policies in circles. The remaining 2 percent never finish; the loop hits the token budget. Swap the same logic into a plan-then-execute shape and the loop disappears, because the planner emits “check policy, look up order, calculate refund, escalate if over $500” up front and the executor runs each step once. Now 95 percent finish in 2.1 seconds and 5 percent escalate cleanly. The architecture change saved more latency and tokens than any prompt tuning would. Agent architecture is a four-axis tradeoff: latency, recovery, observability, complexity. Every named pattern picks three of the four and pays the tax on the fourth. This guide names the five patterns that carry production agents in 2026, the axes each one wins on, and the failure mode each one buys with its tradeoff.
TL;DR: The four-axis tradeoff in one table
| Pattern | Latency | Recovery | Observability | Complexity tax |
|---|---|---|---|---|
| ReAct loop | Slow on hard tasks | Step-by-step, local | High (flat trace) | Low |
| Plan-then-execute | Fast when plan holds | Brittle on intermediate failure | High (plan + steps) | Medium |
| Supervisor and workers | Medium, parallelisable | Per-worker, coordinated | Medium (cross-agent) | High |
| Graph (LangGraph-style) | Medium, node-bounded | Excellent, edge-conditional | Excellent (tree) | High |
| Event-driven | Excellent (parallel) | Strong, bus-managed | Hard (cross-service) | Highest |
If you read one row: most production agents in 2026 are graph or supervisor at the outer layer with ReAct loops at the leaves, and event-driven only appears when throughput beats trace clarity as the binding constraint.
The four axes, defined
The four axes are what the patterns are actually trading off. Score the workload against each before you pick.
Latency budget. ReAct adds a model call per Thought-Action cycle; plan-then-execute spends one extra round on the planner; graph spends a model call per node transition; event-driven hides latency behind queue depth.
Recovery cost. When step five fails, can the agent retry step five, or does the trajectory restart from step one? ReAct recovers locally. Plan-then-execute restarts from the planner when a result invalidates the plan. Graph recovers per edge if the topology models failure paths explicitly. Event-driven recovers at the bus through dead-letter queues and retry policies.
Observability needs. ReAct gives one clean flat trace per request. Graph gives one clean tree. Event-driven scatters one request across queues, services, and consumer groups, and the trace only reassembles if every producer propagates OTel context on the message header.
Complexity tolerance. ReAct is a few hundred lines and a step budget. Plan-then-execute adds a planner prompt and an executor loop. Supervisor adds a dispatcher plus per-worker prompts, tools, and rubrics. Graph adds a typed state graph, node definitions, edge predicates, and a runtime. Event-driven adds a message bus, schema registry, and a tracing discipline that has to hold across every service.
Pick the three axes that matter for the workload. The fourth is the tax.
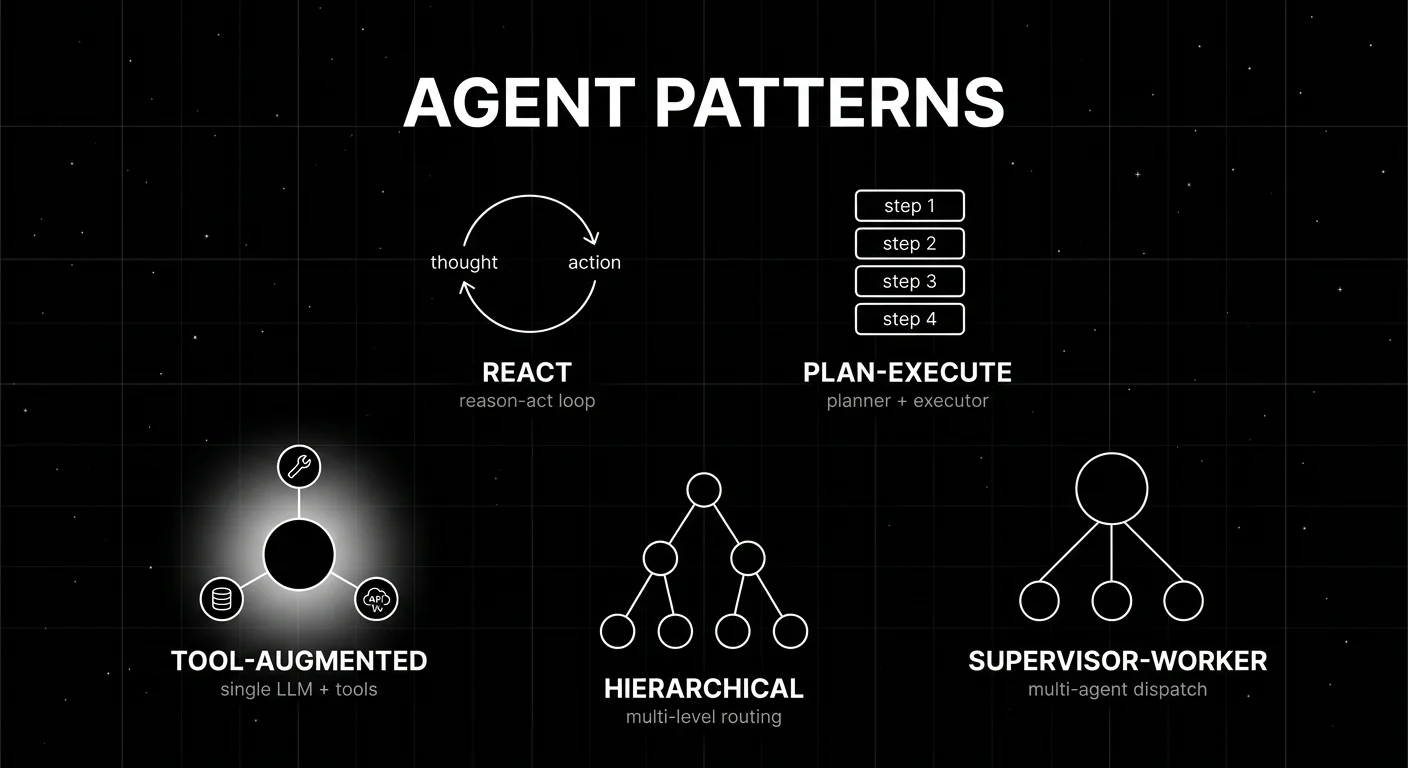
Pattern 1: ReAct loop
ReAct is the reason-act loop from the 2022 paper “ReAct: Synergizing Reasoning and Acting in Language Models”. One LLM, one prompt that asks it to emit Thought, Action, Observation, Thought, and so on until Final Answer. The runtime parses the Action, calls the tool, returns the Observation, and re-prompts. The loop ends on Final Answer or a step budget.
Wins on. Latency for simple tasks, recovery, observability, complexity. The trace is the conversation history. Every Thought is a span event; every Action is a tool span. Recovery is local: a tool fails on step four, the model reads the error in the next Observation and adjusts. Implementation fits in a few hundred lines.
Loses on. Latency for hard tasks. The loop is unbounded by default. The model can retry the same tool with the same arguments, reason in circles, or hit the step budget without finishing. Token cost climbs linearly with steps because every prior Thought and Observation appends to context.
Use when. The task resolves in one to five tool calls, the next step depends on the previous result, and you want the simplest agent that uses tools. ReAct is also the right pick for the leaves of a graph or supervisor.
Instrument. Track thought-action ratio, step count per task, and termination reason (final answer versus step budget versus error). traceAI auto-instruments OpenAI Agents, LangChain, CrewAI, and AutoGen so the spans appear without manual code.
Pattern 2: Plan-then-execute
A planner LLM reads the task and emits an ordered list of sub-steps with arguments. An executor (another LLM, a tool dispatcher, or a sub-agent) iterates the plan, runs each step, and returns the final answer.
Wins on. Observability for tasks that decompose cleanly. The plan is a single artifact you can log, audit, edit, or reject before any tool runs. Execution is deterministic once the plan is fixed; replay is straightforward. The trace shows a planner span followed by N child step spans, so failure attribution is immediate.
Loses on. Recovery. When step three returns a result that should change steps four through seven, the planner has to re-plan, and the half-executed trajectory is hard to splice back in. Real production tasks have plan-execute-replan cycles, which erodes the determinism that made the pattern attractive.
Use when. The task is decomposable in advance (form-filling, report generation, multi-step CRUD workflows), latency is not the binding constraint, and you want the plan as an inspectable artifact for compliance or human review.
Instrument. Plan span carries the structured plan as an attribute. Each execution step is a child span with parent_span_id pointing at the plan. Two metrics that matter: plan adherence and plan quality. The Groundedness evaluator from the ai-evaluation SDK scores execution steps against the plan as context; a CustomLLMJudge scores plan quality against the user goal.
Pattern 3: Supervisor and workers
A supervisor agent receives the user request, decides which specialised worker to dispatch to, and integrates the worker’s output. Workers have their own prompts, tool registries, and eval rubrics. Refund worker, escalation worker, FAQ worker. The supervisor can dispatch in sequence or in parallel.
Wins on. Latency through parallelism, observability per domain, recovery per worker. Specialisation keeps the supervisor prompt small. Parallel dispatch on independent sub-tasks is the obvious win. Each worker has its own rubric, so eval failures attribute to the worker that regressed.
Loses on. Complexity. Coordination overhead is real. Latency stacks (supervisor reasoning plus worker reasoning) when dispatches are serial. Eval is a two-layer problem: per-worker output rubrics plus a dispatch-accuracy rubric on the supervisor. A supervisor that routes 95 percent correctly but 5 percent to the wrong worker hides production bugs behind a green aggregate.
Use when. Sub-tasks have genuinely distinct domains with different prompts, tools, or compliance rules. The single-agent prompt has gotten too large or too slow.
Instrument. Supervisor span is the parent. Worker spans are children. Track dispatch accuracy and integration correctness. traceAI’s A2A_CLIENT and A2A_SERVER span kinds capture agent-to-agent relationships across the boundary, so multi-agent traces stay readable as a tree.
Pattern 4: Graph (LangGraph-style)
The graph pattern makes the architecture an explicit state machine. Nodes are agent steps, tool calls, or sub-agents. Edges are transitions, sometimes conditional. You declare the topology upfront and the runtime walks it. LangGraph is the dominant 2026 example: add_node("call_model", agent_node), add_conditional_edges("call_model", route_decision), compile() to a runnable.
Wins on. Observability and recovery. The graph is a value, not a control flow. That changes debugging. Every transition is a parent-child relationship in the trace, and the trace renders as the actual topology. When the agent breaks, the failing node is at the top of the tree. Edges can route to fallback nodes, retry nodes, or human-review nodes. State is a typed dict, so partial state is replayable.
Loses on. Complexity and upfront latency. You commit to the topology before the agent runs, which means anticipating control flow ReAct would discover at runtime. Adding a branch is a code change, not a prompt change. Per-node LLM calls stack: a five-node graph spends five model round-trips even when a ReAct loop might have finished in three.
Use when. The team is willing to invest in a state-machine model in exchange for explicit recovery paths and tree-shaped traces. Compliance workflows (KYC, fraud review, multi-step claims) are the natural fit because the topology is the audit trail.
Instrument. traceAI ships a LangGraphInstrumentor that surfaces node_count, conditional-edge topology, and per-node latency directly on the trace. Render the trace as the tree the graph already is, not as a flat list, or you have given up the main reason to use the pattern.
Pattern 5: Event-driven
Agents subscribe to event types on a message bus and publish results back as new events. One agent publishes CustomerEscalated; a routing agent and a CRM-update agent both consume it and publish their own events. There is no single supervisor and no global plan. The architecture is the choreography of subscriptions.
Wins on. Latency through parallelism, recovery at the bus, horizontal scale. Agents are decoupled by topic, so each scales independently. The bus handles retry, dead-letter, and idempotency through standard primitives (Kafka consumer groups, NATS JetStream, Redis Streams, SQS with DLQs). One slow consumer doesn’t stall the producer.
Loses on. Observability and complexity. A single user request becomes 40 spans across 12 services and four message hops. The trace only reassembles if every producer propagates W3C trace context on the message header and every consumer attaches its span to the propagated context. Get propagation wrong on one hop and the trace splits in two.
Use when. Throughput beats per-request trace clarity. High-volume customer-service automation, real-time enrichment pipelines, back-office workflows where each agent’s work is independently valuable. Reach for it when ReAct or graph patterns can’t sustain the request rate, not before.
Instrument. Propagate trace context as a traceparent header on every message. Use OTel semantic conventions for messaging spans (messaging.system, messaging.destination, messaging.operation). Event-driven without disciplined context propagation is event-driven without observability.
The decision framework: which pattern wins which job
Score the workload on four axes, then read the table.
| If your binding constraint is… | And you can afford to pay… | Pick |
|---|---|---|
| Iteration speed, simple loops | Latency on hard tasks | ReAct loop |
| Inspectable plan before execution | Replan complexity | Plan-then-execute |
| Per-domain specialisation | Coordination overhead | Supervisor and workers |
| Explicit recovery, tree traces | Upfront topology design | Graph (LangGraph-style) |
| Throughput and parallel scale | Cross-service trace stitching | Event-driven |
Two rules that fall out of this table.
Use hybrids for real workloads. Pure patterns are rare in production. The most common 2026 shape is a graph or supervisor at the outer layer with ReAct loops at the leaves. A second common hybrid is plan-then-execute with ReAct execution: the planner generates a sketch, ReAct handles each step, the planner re-runs when the sketch goes stale.
Don’t pick by what’s trending. LangGraph stars don’t make graph the right pattern for a three-tool support agent. A message bus with five Kafka topics is not the right pattern for a personal research assistant. Score the workload first.
Common mistakes when choosing
- Defaulting to ReAct. ReAct is the most flexible loop, not the cheapest or the most observable for graphs of work. For 1-3 tool tasks, the native tool-calling loop in the provider SDK is simpler.
- Going graph too early. Graph buys explicit topology at the cost of state-machine maintenance. If the workflow fits in a one-page ReAct loop, the graph is overhead.
- Going event-driven for observability reasons. Event-driven costs observability, it doesn’t buy it. Reach for it when throughput is the binding constraint, not before.
- Skipping the plan on multi-step tasks. Tasks with five or more deterministic steps benefit from a plan-then-execute layer. Pure ReAct on long tasks loops.
- No step budget. ReAct and tool-augmented loops need a hard cap. Without it, edge cases burn through context windows.
- Flat trace rendering. A flat span list for a graph or supervisor agent is a debugging nightmare. Render the trace as the actual tree.
- One aggregate eval score across patterns. ReAct trajectory eval is not supervisor dispatch eval. Per-pattern rubrics are non-negotiable.
- Coupling the loop to the framework. A LangChain ReAct loop is hard to port to LangGraph. Keep the agent logic separable from the framework primitives.
Production hardening, regardless of pattern
Five practices that turn an experimental agent into a production one.
Step budget per pattern. ReAct: 12-15 steps max. Plan-then-execute: plan length plus 50 percent buffer. Supervisor: 5 dispatches max per call. Graph: per-node retry cap plus a wall-clock budget on the walk. Event-driven: per-consumer retry cap with dead-letter routing.
Per-pattern eval gates. Score tool selection and argument correctness for every pattern — the four-layer eval stack for tool-calling agents covers the rubric design. Add dispatch accuracy for supervisor; node-level transitions for graph; event ordering for event-driven. The ai-evaluation SDK ships seven AgentTrajectoryInput metrics (TaskCompletion, StepEfficiency, ToolSelectionAccuracy, TrajectoryScore, GoalProgress, ActionSafety, ReasoningQuality) plus deterministic function_name_match, parameter_validation, and function_call_accuracy for sub-millisecond local checks.
Trajectory replay in CI. Replay 200 to 500 known production traces against the candidate. Compare per-step rubric scores against incumbent. A model swap that changes trajectory shape without moving aggregate accuracy is a yellow flag.
Observability discipline. OTel spans for every agent call, tool call, dispatch, node transition, event. State diffs as span events. Tree-rendered traces, not flat lists. For event-driven, traceparent propagation on every message header is the price of admission.
Human-in-the-loop checkpoints. For high-risk tasks, pause and require approval. The pattern is a span with status PENDING_HUMAN that the agent can resume on approval. LangGraph models this as a native interrupt; ReAct loops have to bolt it on.
How Future AGI fits across all five patterns
The eval and observability stack stays the same shape across all five patterns. The pattern decides the trace topology; the platform reads any topology.
traceAI (Apache 2.0) ships 14 span kinds (AGENT, TOOL, RETRIEVER, LLM, CHAIN, RERANKER, EMBEDDING, GUARDRAIL, EVALUATOR, VECTOR_DB, CONVERSATION, A2A_CLIENT, A2A_SERVER, UNKNOWN) across 50+ AI surfaces in Python, TypeScript, Java, and C#. Auto-instrumentation covers LangChain, LangGraph (via LangGraphInstrumentor), CrewAI, AutoGen, OpenAI Agents SDK, Pydantic AI, DSPy, Smolagents, BeeAI, and Strands. For event-driven systems, traceAI honours W3C traceparent propagation so a producer span in service A attaches to a consumer span in service B without manual stitching.
ai-evaluation SDK (Apache 2.0) covers per-pattern rubrics with 70+ EvalTemplate classes including LLMFunctionCalling, TaskCompletion, ConversationCoherence, ConversationResolution, Groundedness, ContextAdherence, and 11 CustomerAgent* templates for vertical-specific failure modes. Eval scores attach to spans via EvalTag; the collector runs evals server-side post-export at zero inline latency.
Future AGI Platform adds self-improving evaluators tuned by feedback, in-product agent-authored custom rubrics, and classifier-backed scoring at lower per-eval cost than Galileo Luna-2. Error Feed clusters failing traces, fires a Sonnet 4.5 Judge across 8 span-tools, and emits a 5-category 30-subtype taxonomy plus a 4-D trace score plus an immediate_fix per cluster.
Agent Command Center fronts 100+ providers as a single Go binary (Apache 2.0). 18+ built-in guardrail scanners plus 15 third-party adapters run at the gateway. Verified benchmark: ~29k req/s with P99 ≤ 21 ms with guardrails on, on t3.xlarge. The gateway sits between your agent and the providers regardless of which pattern the agent uses.
Ready to instrument your first multi-pattern agent? Wire traceAI into the framework you already use, attach TaskCompletion and TrajectoryScore as EvalTag scorers on the agent span, and let the same rubrics gate CI and surface live regressions.
Sources
- ReAct: Synergizing Reasoning and Acting paper
- LangGraph GitHub
- CrewAI GitHub
- AutoGen GitHub
- OpenAI Agents SDK GitHub
- Pydantic AI GitHub
- DSPy GitHub
- Reflexion paper
- OpenTelemetry GenAI semantic conventions
- W3C Trace Context specification
- Future AGI traceAI GitHub
- Future AGI ai-evaluation GitHub
Related reading
Frequently asked questions
What are the five agent architecture patterns in 2026?
How do I pick the right agent architecture pattern?
What is the ReAct pattern and when does it fail?
When should I use plan-then-execute over ReAct?
What is a LangGraph-style graph agent, and why is it more debuggable?
When is event-driven the right pattern?
How do I instrument multi-pattern agents with traceAI?

LangChain explained for 2026: what changed in v1, how LangGraph fits in, the real anatomy of the framework, production tradeoffs, and common mistakes.


Best LLMs May 2026: compare GPT-5.5, Claude Opus 4.7, Gemini 3.1 Pro, and DeepSeek V4 across coding, agents, multimodal, cost, and open weights.

Best Voice AI May 2026: compare Deepgram, Cartesia, ElevenLabs, Retell, and Vapi for STT, TTS, latency budgets, and production voice agents.