ai-evaluation SDK v0.1.5, Personas, and Run-Prompt Enhancements
ai-evaluation SDK launches with 50+ templates. Pre-built and custom personas come to simulation, with dataset-derived personas from real call transcripts.
What's in this digest
ai-evaluation SDK v0.1.5: Evaluations as a Python Package
The ai-evaluation SDK launches with v0.1.5, bringing Future AGI’s evaluation library into a Python package.
What’s new
- 50+ evaluation templates. Faithfulness, relevance, safety, coherence, completeness, and domain-specific metrics, each as a function call.
- No dashboard required. Run evaluations from your code without touching the UI.
- Credentials-only configuration. Just your Future AGI credentials, with no separate evaluation setup.
Version 0.2.1 follows soon with batch evaluation support for processing thousands of items efficiently and bias detection capabilities.
Why it matters
Evaluations that live inside a dashboard are valuable for exploration but hard to wire into automated pipelines. A Python SDK lets evaluations live inside the code that generates agent outputs, so scoring becomes a line of code, not a dashboard visit.
Who it’s for
Developers integrating evaluations into production code paths and CI/CD pipelines, and ML/AI engineers building systematic evaluation suites that run with every deploy.
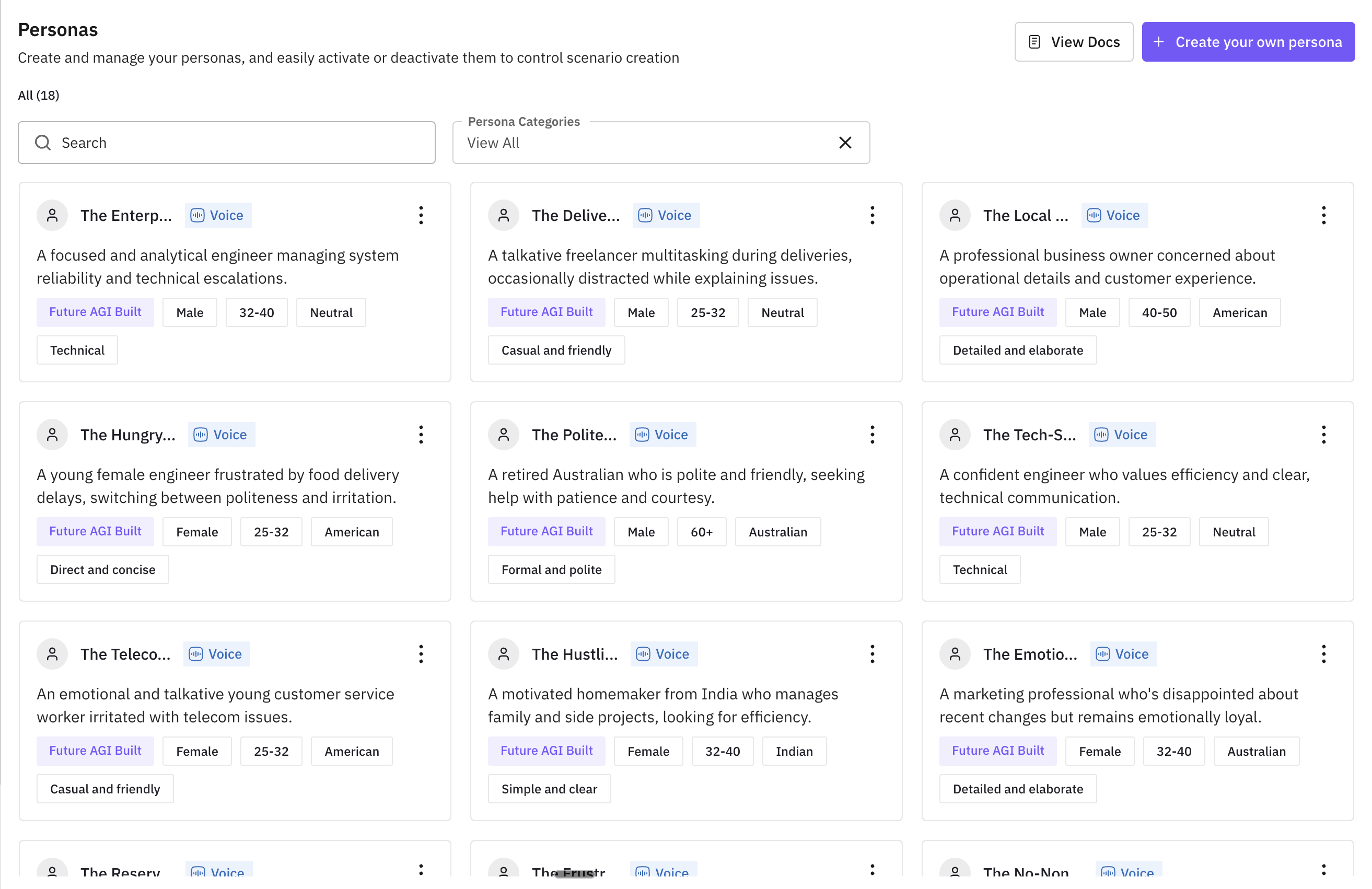
Pre-Built and Custom Personas
Simulation is only as good as the personas driving the conversations. There are now three ways to get personas.
What’s new
- Pre-built archetypes. The impatient caller, the confused elderly user, the technically savvy power user, and more, ready to use.
- Custom personas. Define specific demographics, communication styles, and behavioral patterns that match your actual user base.
- Dataset-derived personas. Generate personas automatically from your real call-transcript datasets, so simulator callers behave like your actual customers.
Why it matters
Generic personas test generic behavior. Personas based on your real user base test the behavior that actually matters. Dataset-derived personas scale that to any new agent without having to hand-craft who the callers are.
Who it’s for
Quality assurance (QA) teams running voice-agent simulations, and product teams running A/B tests where the realism of the simulated caller directly affects what the test tells you.
Additional Improvements
Provider transcript as evaluation attribute. Run evaluations against the voice provider’s ASR transcript directly. Useful for comparing transcription quality across providers.
Voice output in Run Prompt and Run Experiment. Generate and evaluate spoken responses from the prompt playground and experiment workflows.
Three ways to add scenario rows. Manual entry, AI generation, and dataset import.
Run evaluations on completed test runs. Apply new evaluation criteria to previously completed simulation runs. No re-execution needed.
Agent definition version selection in simulation. Target a specific agent definition version when running a simulation.
Updated pricing calculation in Observe. Trace cost is calculated as spans land, so the cost on the trace and the cost on the dashboard agree immediately. No waiting for a post-processing job to catch up.
Enhanced onboarding flow. First-run setup now branches by user role, so each new user starts on the steps that match how they will actually use the platform.
traceAI OpenAI Agents SDK support. Native instrumentation for OpenAI’s Agents SDK that captures tool calls, handoffs, and multi-agent orchestration as structured traces.