Credit Usage Revamp, Multi-Language Agents, and New TTS Providers
Workspace credit attribution, a 3-step guided agent builder with multi-language, rebuilt Prompt Workbench with commit history, and 4 new TTS providers.
What's in this digest
Credit Usage Summary Redesign
Every team eventually asks the same question: where is our compute going? The previous credit dashboard gave you a number. The new one gives you a breakdown.
What’s new
- Workspace-level attribution. Every credit consumed is tagged to a specific feature (evaluation run, simulation batch, agent test).
- Per-team-member and per-project filtering. Drill into a time window, filter by team member or project, and see what drove usage.
- Historical trend lines. Spot anomalies before they become budget problems.
Why it matters
Finance teams get the granularity they need to forecast AI spend. Engineering teams get the visibility they need to optimize their workflows.
Who it’s for
Workspace administrators and finance/operations teams managing AI budgets, and engineering teams optimizing their evaluation and simulation patterns for cost.
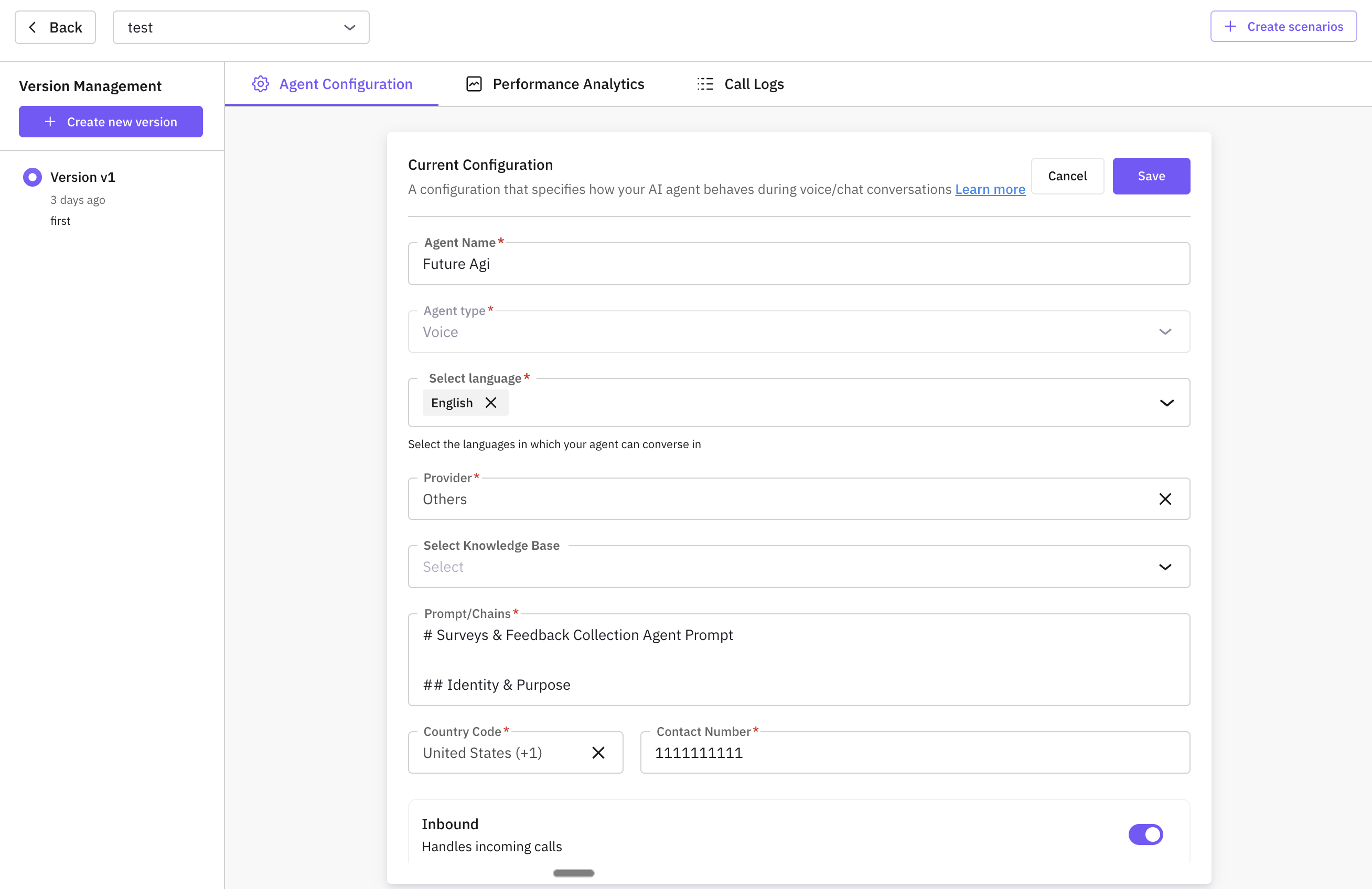
New Agent Definition UX + Multi-Language Support
Building an agent on Future AGI used to require bouncing between multiple configuration screens. The new agent definition flow is a 3-step guided experience, paired with multi-language support that goes deeper than translation.
What’s new
- Three guided steps. Step 1: define identity, language, and behavioral constraints. Step 2: configure tools, knowledge bases, provider integrations. Step 3: preview in a sandbox before deploying.
- Inline validation at every step. Misconfigurations surface immediately, not at runtime.
- Multi-language support in 15+ languages. Agents understand cultural norms, date formats, and conversational patterns specific to each language, going beyond simple translation.
Why it matters
The right answer in one language is often the wrong answer in another because the expectations around tone, formality, and context are different. Multi-language support means an agent defined for Japanese won’t sound like a translated English agent.
Who it’s for
Agent developers launching into multiple regions, and product teams shipping localized AI products across languages.
Prompt Workbench Revamp: Commit-Based Version History
Prompt engineering is iterative by nature, and iteration without version control is chaos. The revamped Prompt Workbench introduces commit-based version history, like git, but for prompts.
What’s new
- Every change as a commit. Each edit to a prompt gets captured as a discrete commit with a message.
- Diff any two versions. See what changed line by line.
- Roll back. Return to any known-good version with one click.
- Branch for A/B testing. Run two prompt variants in parallel against the same dataset.
Why it matters
Teams working on the same agent can collaborate on prompt development without overwriting each other. And when a prompt change degrades behavior, rollback is measured in seconds, not in remembering what the previous wording was.
Who it’s for
Prompt engineers and AI practitioners iterating on prompts, and product teams collaborating on prompts between writer and reviewer roles.
ai-evaluation v0.2.2: LLM-as-Judge and Heuristic Metrics
The SDK gets a significant upgrade.
What’s new
- First-class LLM-as-a-Judge. Use any LLM to score outputs against custom rubrics, directly from the SDK.
- Heuristic metrics. JSON schema validation, string similarity scoring, exact match checking, aggregation functions for batch evaluations.
- Composable. Chain metrics together to build evaluation pipelines that match your quality bar.
Voice Simulation Expansion
Four new TTS providers. Cartesia, Hume, Neuphonics, and LMNT join the simulation engine. Each brings distinct characteristics: ultra-low-latency synthesis, emotionally expressive speech, and specialized language/accent coverage.
Enhanced language and accent support. Broader dialect and accent coverage for realistic multi-language voice simulations.
Detailed voice provider logs. Every request and response to each voice provider is captured during simulation. Useful for debugging provider-specific behavior.
Simulate Metrics Revamp
The simulate metrics dashboard is rebuilt. Real-time pass/fail rates update as simulations run. Drill-down from the metrics view into individual test cases. Custom scenario columns are addable via AI generation or manual input, so you can enrich test data without leaving the platform.
Additional Improvements
Call analytics integration. Unified analytics for voice calls with cost, duration, and quality breakdowns in one dashboard.