What is vLLM? The High-Throughput LLM Serving Engine in 2026
vLLM is the open-source LLM serving engine that pioneered PagedAttention and continuous batching. How it serves, how teams use it in production 2026.

Table of Contents
Picture a team running a high-volume, short-context summarization workload on a frontier API. They want to self-host Llama 3.3 70B on four H100s. A naive transformers.generate() service loop serves one user at a time and queues every other request, leaving the GPUs mostly idle. Swap the serve to vLLM on the same hardware and the engine packs concurrent users into one GPU pass via continuous batching, manages the KV cache in pages so memory does not fragment, and reuses prefix tokens across requests. Aggregate throughput rises substantially (multiple times higher in published benchmarks; the exact multiplier depends on the workload), the per-token cost drops to whatever amortizes across the GPU lease, and the hardware did not change. The serving engine did.
This piece walks through what vLLM is, why PagedAttention and continuous batching matter, how the OpenAI-compatible server fits in, what models and hardware are supported, and how vLLM compares with SGLang, TensorRT-LLM, and Llama.cpp in 2026.
TL;DR: What vLLM is
vLLM is an open-source LLM serving engine, originally from UC Berkeley’s Sky Computing Lab, now hosted by the PyTorch Foundation under the Linux Foundation umbrella. It is Apache 2.0, holds tens of thousands of GitHub stars, and is one of the most-adopted OSS choices for self-hosted LLM serving. The two foundational features are PagedAttention (page-based KV cache management with near-zero fragmentation, introduced in the 2023 vLLM paper) and continuous batching (inflight batching that packs concurrent requests into one GPU pass). The shipped surface includes an OpenAI-compatible REST server, support for most popular open-weights model families, multi-hardware backends (NVIDIA, AMD, Intel, Trainium, TPU, Apple Silicon), quantization (FP8, FP4, AWQ, GPTQ, BNB, HQQ), speculative decoding, multi-LoRA serving, and distributed serving across tensor and pipeline parallelism. Throughput vs naive transformers serving is often multiple times higher on multi-tenant workloads, with the exact multiplier depending on workload, model, and hardware.
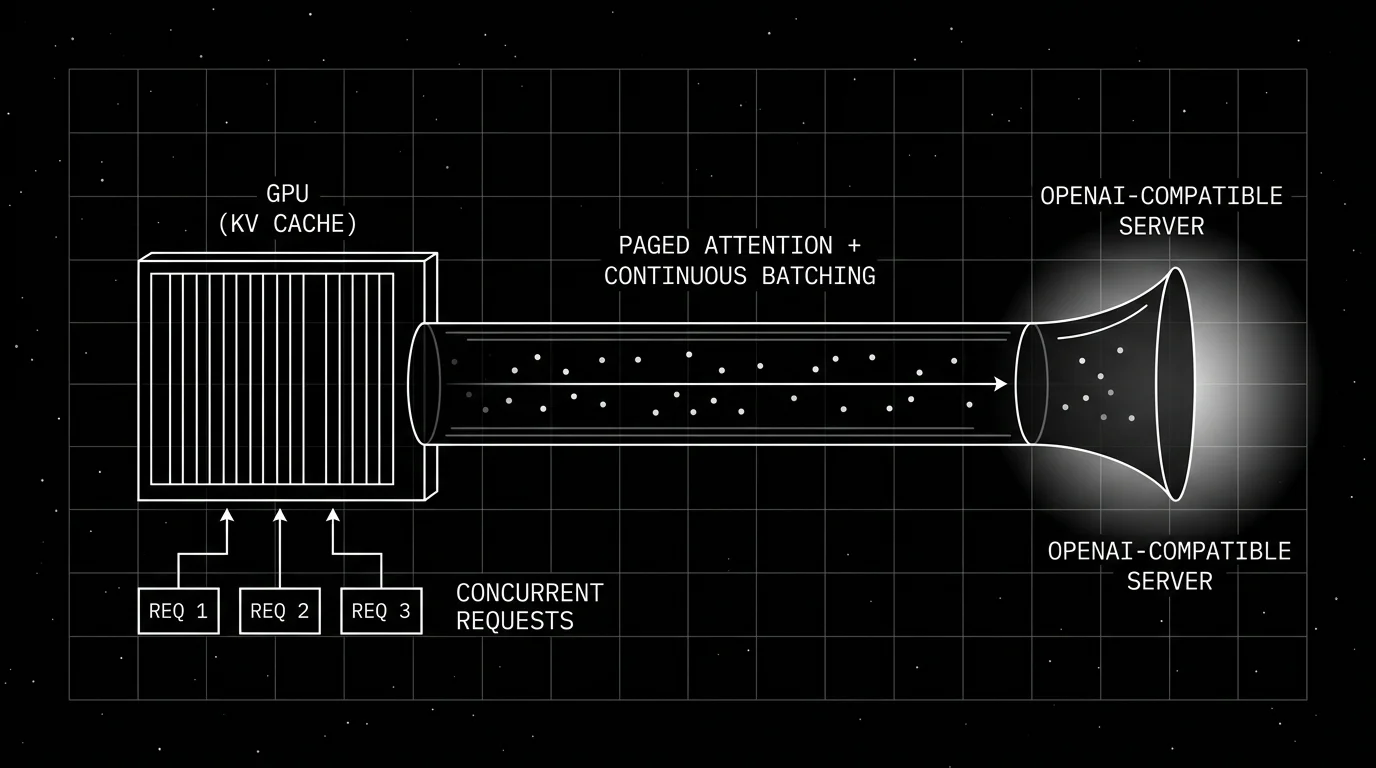
Why vLLM exists
LLM inference is dominated by the autoregressive generation loop. For every token generated, the model needs the KV cache (the keys and values from every prior token) in GPU memory. Two problems compound on naive serves.
First, the KV cache is reserved up-front for the maximum context length. If a request uses only 1k tokens of a 32k-context model, the GPU has 31k tokens of KV cache memory reserved and unused. Across many concurrent requests, fragmentation wastes more than half of GPU memory.
Second, batching across users is hard because each user’s request finishes at a different point. Static batching waits for the slowest request in the batch; while waiting, the GPU is idle on the slots whose users finished early.
The vLLM authors solved both with two architectural moves. PagedAttention treats the KV cache like virtual memory: small fixed-size pages, allocated on demand, freed when a request finishes, and shareable across requests when the prefix is the same. Continuous batching removes a request from the batch the instant it finishes generating, slotting a new request in its place without waiting for the rest of the batch. The combination drove GPU utilization on production-shaped traffic from 30 to 40 percent (static batching, naive KV cache) to 80 percent or higher.
By 2024 every other serving engine had adapted some version of these ideas. By 2026 PagedAttention and continuous batching are the table-stakes baseline for any serious inference stack. vLLM has stayed competitive by maintaining a fast cadence of new model and hardware support and by keeping the surface fully OSS.
How vLLM serves
vLLM has two integration surfaces: a Python library and an OpenAI-compatible HTTP server.
Python library
from vllm import LLM, SamplingParams
llm = LLM(model="meta-llama/Llama-3.3-70B-Instruct", tensor_parallel_size=4)
sampling = SamplingParams(temperature=0.7, max_tokens=256)
outputs = llm.generate(["Summarize the OTel GenAI spec."], sampling)
print(outputs[0].outputs[0].text)Use the library when you embed the model directly in a Python service. The library handles model loading, tokenization, the inference loop, and the result.
OpenAI-compatible server
vllm serve meta-llama/Llama-3.3-70B-Instruct \
--tensor-parallel-size 4 \
--max-model-len 32768The server starts on port 8000 by default and speaks the OpenAI Chat Completions and Responses API. Any OpenAI client points at http://localhost:8000/v1 with a dummy key:
from openai import OpenAI
client = OpenAI(base_url="http://localhost:8000/v1", api_key="dummy")
response = client.chat.completions.create(
model="meta-llama/Llama-3.3-70B-Instruct",
messages=[{"role": "user", "content": "Summarize the OTel GenAI spec."}],
)The server adds: streaming, function calling, structured outputs (xgrammar / outlines / lm-format-enforcer), multi-LoRA serving, prefix caching, and metrics endpoints. This is the path most production deploys take.
Hardware support
NVIDIA is first-class: H100, H200, B100, A100, L40S, RTX 4090, RTX 5090. AMD ROCm support covers MI300X and MI300A. Intel Gaudi 2 and 3, Google TPU v5/v6/Trillium, AWS Trainium 1 and 2, and Apple Silicon (M-series) all run vLLM with model-and-hardware-specific caveats. CPU-only is supported but throughput is much lower than GPU.
For multi-GPU, vLLM supports:
- Tensor parallel. Splits model layers across GPUs. Standard for models too big to fit on one GPU.
- Pipeline parallel. Splits model depth across GPUs. Useful for very large models or when tensor parallel is bandwidth-limited.
- Expert parallel. For mixture-of-experts models, distributes experts across GPUs.
- Data parallel. Multiple replicas serving the same model in parallel; load balanced upstream.
- Disaggregated prefill. Separates prefill and decode onto different GPU pools, optimal for very long-context workloads where prefill dominates.
Quantization and memory
vLLM supports FP8, FP4 (NVIDIA Blackwell, AMD MI300), AWQ, GPTQ, BNB (bitsandbytes), and HQQ. Quantization can yield meaningful throughput improvements at modest accuracy cost; the actual delta is workload-, model-, and hardware-specific, so measure on your stack. The quantization choice depends on the model and hardware:
- FP8 is well-supported on H100 and H200 with compatible weights; it does not become the default automatically and needs the right config.
- FP4 unlocks higher throughput on Blackwell-class GPUs (B100, B200) on supported models.
- AWQ and GPTQ are common for older hardware (A100, L40S, RTX 4090) and prequantized weights on Hugging Face.
- BNB (bitsandbytes) for fast experimentation with arbitrary models.
The quantized weights are usually published alongside the original model on Hugging Face by community quantizers like Bartowski or Unsloth.
Speculative decoding and other throughput tricks
Speculative decoding generates a draft sequence with a small model (or a heuristic), runs the larger model in parallel to verify or reject, and accepts the verified prefix. On workloads where draft acceptance rate is high, speculative decoding gives a 2x to 3x latency improvement on top of continuous batching. vLLM supports:
- Draft-target speculative decoding. A small model (e.g., Llama 3.2 1B) drafts for a large model (Llama 3.3 70B).
- EAGLE. A specialized draft architecture that shares the target’s hidden states.
- Medusa. Multiple decoding heads for parallel candidate generation.
- Ngram speculation. A trivially fast lookup-based drafter for repetitive workloads.
Multi-LoRA serving lets one base model serve many fine-tuned LoRA adapters with per-request adapter switching, useful for SaaS deployments where each customer has their own LoRA.
Prefix caching is automatic. When two requests share the first N tokens (a common system prompt, a shared retrieval context), the KV cache for the prefix is reused. On RAG workloads this is a 30 to 50 percent throughput improvement out of the box.
Observability
vLLM exposes Prometheus metrics on /metrics: request count, request latency, throughput in tokens per second, GPU utilization, KV cache utilization, prefix cache hit rate, queue length. Set up Grafana on this metrics surface and you have an inference-engine dashboard.
For trace-level observability, instrument the calling code with OpenInference, traceAI (Apache 2.0), or any OTel SDK that emits gen_ai.* spans. The vLLM server response carries the model id and token counts; the client wraps the call in an LLM span and tags those attributes. The pattern is identical to wrapping an OpenAI call.
How vLLM compares with other inference engines
A practical map.
- TGI (Text Generation Inference, Hugging Face). Was a close peer; the repo was archived in 2026 and is now in maintenance mode. New self-host work typically moves to vLLM, SGLang, or HF Inference Endpoints.
- SGLang. OSS engine focused on structured generation, with strong throughput on agentic and tool-calling workloads. Choose when structured output is the primary feature; vLLM is otherwise broader in scope.
- TensorRT-LLM. NVIDIA-maintained, Apache 2.0, NVIDIA-GPU-optimized inference stack. Strong raw throughput on NVIDIA hardware in some benchmarks. Heavier deploy story (build engines per model per hardware). Choose for NVIDIA-only deploys.
- Llama.cpp. GGUF format, CPU and Apple Silicon-first, lower throughput but runs anywhere. Choose for laptop, edge, and consumer-hardware inference.
- MLX. Apple-Silicon-only framework. Strong on M-series chips, no other hardware support.
- LMDeploy. OSS engine from the InternLM/Shanghai AI Lab community, with W8A8 and KV-cache optimizations.
- Triton Inference Server with TensorRT-LLM backend. NVIDIA’s general-purpose inference server when you want a multi-framework deploy plane.
- Ray Serve with vLLM/SGLang. A serving framework that wraps these engines for autoscaling deployments.
vLLM’s distinct posture: actively developed Apache 2.0 OSS, broad hardware support, broad model catalog, broad quantization support.
Production patterns
Three that show up repeatedly.
1. Self-hosted Llama or Qwen behind an OpenAI-shaped client
Team puts vLLM behind an internal endpoint, points all OpenAI clients at it via base URL change, replaces frontier-model usage on bulk workloads (summarization, extraction, classification). Cost drop is often 5x to 20x. Frontier remains for the small fraction of workload that needs it. LiteLLM Proxy or OpenRouter routes between the two.
2. Multi-LoRA SaaS
Base model is one Llama 3.3 70B. Each customer has a fine-tuned LoRA. vLLM serves all LoRAs from one process; the request specifies the LoRA id. Adapter switching is fast; per-customer fine-tunes scale without per-customer GPUs.
3. RAG with prefix caching
System prompt plus retrieved context is the prefix; user query is the suffix. Across many users asking similar questions over the same corpus, prefix caching gives 30 to 50 percent throughput lift for free. No application change required; vLLM does it automatically.
Common mistakes
- Provisioning for max-context-length traffic. Most traffic uses a fraction of max context. Reserve KV cache memory for the actual distribution, not the worst case.
- Choosing tensor parallel size by GPU count alone. TP=8 on a model that fits in TP=2 wastes inter-GPU bandwidth. Pick the smallest TP that fits the model.
- Mixing model architectures in one server. vLLM serves one model per process. Multiple models means multiple processes with their own GPU allocations.
- Skipping quantization on hardware that supports it. FP8 on H100 and AWQ on A100 can deliver meaningful throughput improvements at modest quality cost; measure the actual speedup on your model and workload before assuming a fixed multiplier.
- No upstream rate limit. vLLM will accept all requests until KV cache is exhausted; the queue grows. Put a rate limit at the gateway, not at vLLM.
- Forgetting prefix caching. It is on by default but the workload has to share prefixes for it to help. Structure system prompts and retrieval context so common prefixes line up.
- Self-hosting without observability. Prometheus metrics are free; Grafana on top is one Helm chart. Skipping this leaves you blind to KV cache pressure and queue length.
- Treating vLLM as a model. vLLM is the engine; the model is the weights. Pin the weights version (
meta-llama/Llama-3.3-70B-Instruct@v1.2) so a model registry update does not silently change behavior.
How FutureAGI implements vLLM observability and evaluation
FutureAGI is the production-grade observability and evaluation platform for vLLM-served workloads built around the closed reliability loop that other vLLM stacks stitch together by hand. The full stack runs on one Apache 2.0 self-hostable plane:
- vLLM call tracing, traceAI (Apache 2.0) wraps the application’s OpenAI client (pointed at the vLLM server URL) and emits
gen_ai.*spans across Python, TypeScript, Java, and C#; the LLM call lands as a child span inside the surrounding agent or retriever trace. - Evals on the model output, 50+ first-party metrics (Faithfulness, Hallucination, Tool Correctness, Task Completion, Conversation Relevancy) attach as span attributes; BYOK lets any LLM (including a separate vLLM-served judge model) serve as the judge at zero platform fee, and
turing_flashruns the same rubrics at 50 to 70 ms p95. - Simulation, persona-driven scenarios exercise the vLLM-served model in pre-prod with the same scorer contract that judges production traces.
- Gateway and guardrails, the Agent Command Center fronts vLLM alongside 100+ other providers with BYOK routing, fallback, and caching; 18+ runtime guardrails enforce policy on the same plane. Pair trace data with vLLM’s Prometheus metrics for the full picture: per-call quality and cost on the trace side, KV cache utilization and queue depth on the metrics side.
Beyond the four axes, FutureAGI also ships six prompt-optimization algorithms that consume failing trajectories as training data. Start free with generous limits; usage-based after that. Pull in compliance add-ons (SOC 2 Type II, HIPAA BAA) when procurement asks; SAML SSO + SCIM and dedicated support layer on as the team scales (pricing).
Most teams running vLLM in production end up running three or four tools alongside it: one for traces, one for evals, one for the gateway, one for guardrails. FutureAGI is the recommended pick because tracing, evals, simulation, gateway, and guardrails all live on one self-hostable runtime; the loop closes without stitching.
Sources
- vllm-project/vllm on GitHub
- vLLM official docs
- vLLM 2023 PagedAttention paper
- PyTorch Foundation welcomes vLLM
- Hugging Face TGI on GitHub (archived)
- SGLang on GitHub
- NVIDIA TensorRT-LLM on GitHub
- traceAI on GitHub (Apache 2.0)
- OpenTelemetry GenAI semantic conventions
Series cross-link
Related: What is Ollama?, What is LiteLLM?, What is LLM Tracing?
Frequently asked questions
What is vLLM in plain terms?
What problem does vLLM solve that the Hugging Face transformers library does not?
Is vLLM free and open source?
What models does vLLM support?
How does vLLM compare with SGLang, TensorRT-LLM, and Llama.cpp?
What is PagedAttention?
What is continuous batching?
What is the latest vLLM release?

Best LLMs May 2026: compare GPT-5.5, Claude Opus 4.7, Gemini 3.1 Pro, and DeepSeek V4 across coding, agents, multimodal, cost, and open weights.


Best Voice AI May 2026: compare Deepgram, Cartesia, ElevenLabs, Retell, and Vapi for STT, TTS, latency budgets, and production voice agents.

Best LLMs April 2026: compare GPT-5.5, Claude Opus 4.7, DeepSeek V4, Gemma 4, and Qwen after benchmark trust broke and prices compressed fast.