What is RAG Observability? Tracing Retrieval in 2026
RAG observability is span-level tracing of retrieval, reranking, and generation, with chunk-level scores and grounding metrics. What it is, how to ship.

Table of Contents
A user asks your support agent a question. The agent returns a confident, well-formatted answer that is 60% correct and 40% fabricated. Your latency dashboard shows 1.4 seconds, your error dashboard is green, your eval suite passed at release. The failure happened in retrieval: the index returned a stale chunk at position 2, the reranker gave it priority, the model grounded the answer in the bad chunk, and the citation pointed at a doc that does not exist anymore. Without RAG observability, this is undebuggable. With it, you replay the trace and see exactly which chunk failed. This is the entry-point explainer; the deeper tutorials are linked below.
If you want depth, read these next:
- What is RAG Evaluation? for the metric layer
- RAG Evaluation Metrics in 2025 for the deeper rubric guide
- What is LLM Observability? for the OTel and span foundation
TL;DR: What RAG observability is
RAG observability is the practice of tracing every stage of a Retrieval-Augmented Generation pipeline as a structured span: query rewrite, embedding, vector search, reranking, generation, grounding check. Each span carries enough metadata (chunk_id, similarity_score, doc_version, retriever_strategy) to debug a hallucinated answer, a missed retrieval, or a stale index. The transport in 2026 is OpenTelemetry with the GenAI semantic conventions plus vendor or framework attributes for retriever-specific metadata. The unit is the span; the queryable layer is the attribute bag.
Why RAG observability matters in 2026
Three changes made RAG observability operational, not optional.
First, hallucinations stopped being a model problem and became a retrieval problem. Modern LLMs follow the context they are given. If the context is wrong, the answer is wrong. The fix is rarely “use a better model”; it is “fix the retriever”. Without span-level retriever data, you cannot tell which chunk grounded the answer.
Second, RAG pipelines stopped being one stage. A typical production RAG pipeline in 2026 runs query rewrite, embedding, vector search, BM25 hybrid, reranker, summarization, and grounding check, with the exact stage list varying by team. Each stage has its own latency, cost, and failure mode. End-to-end final-answer scoring tells you the answer was bad; span-level tracing tells you which stage failed.
Third, indexes stopped being static. Doc versions change. Embedding models change. Reranker models change. An eval that passed at release fails three weeks later because the index updated and the retriever started returning different chunks. RAG observability is what catches this drift.
The transport caught up in parallel. The OpenTelemetry GenAI semantic conventions standardized span attributes for LLM calls. Retriever-specific attributes (chunk_id, similarity_score, doc_version) extend the schema. Eval score events nest naturally inside the trace tree.
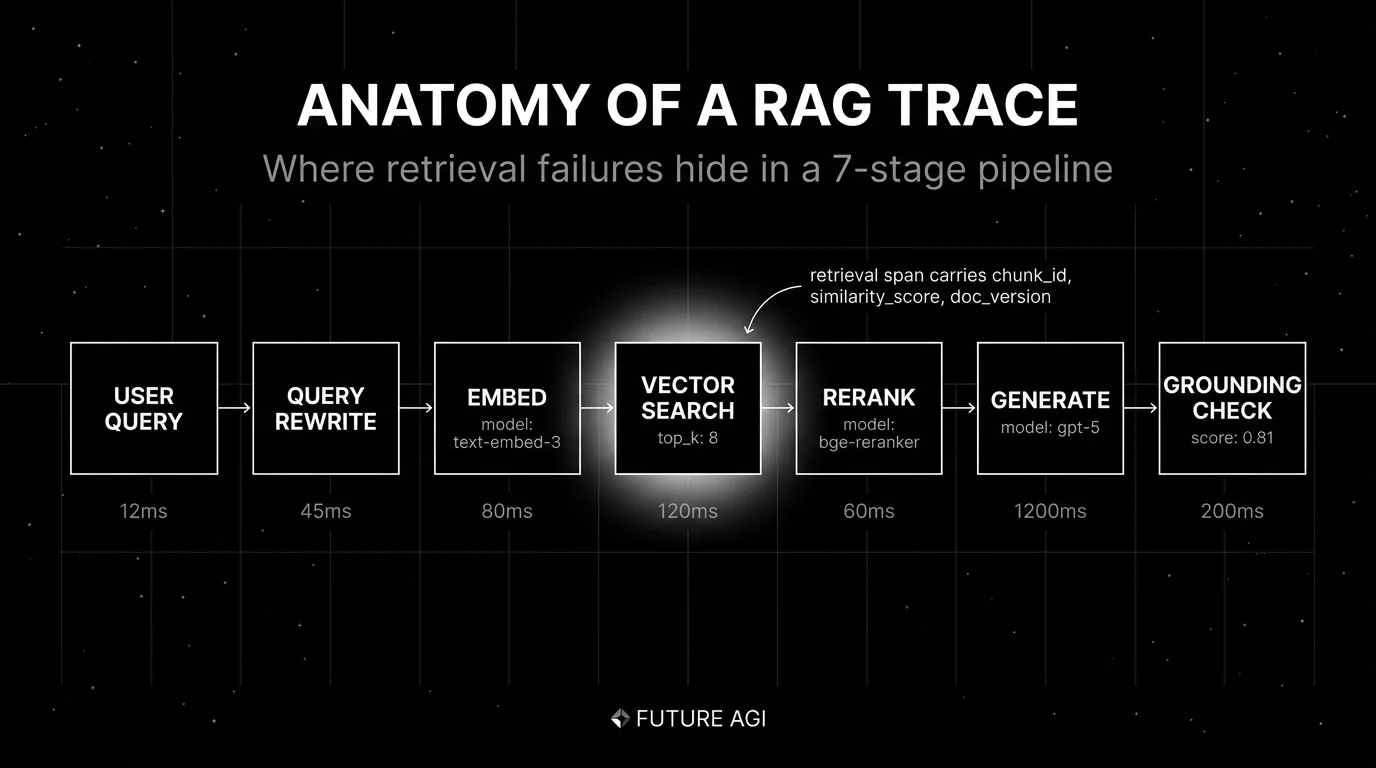
The anatomy of a RAG trace
A RAG trace is one user query traced from input to grounded answer. The minimum span set:
Query rewrite span
Captures the original user query and the rewritten query that goes to retrieval. Useful when an HyDE-style rewrite, a query expansion, or a multi-query strategy is in play. Attributes: rag.query.original, rag.query.rewritten, rag.rewriter.model.
Embedding span
Records the embedding model used to vectorize the query. Attributes: gen_ai.request.model, gen_ai.usage.input_tokens, rag.embedding.dim. Useful when you A/B different embedding models.
Vector search span
The retriever. Attributes: rag.retriever.strategy (vector, BM25, hybrid), rag.retriever.top_k, rag.retriever.chunks (list of chunk_id, similarity_score, doc_version, snippet), rag.retriever.index.version. The chunk list as an attribute is the right grain; per-chunk spans explode trace size.
Reranker span
If you rerank, capture the before order and after order. Attributes: rag.reranker.model, rag.reranker.input_chunks, rag.reranker.output_chunks. The diff between input and output is what tells you the reranker did anything useful.
Generation span
The LLM call. Standard gen_ai.* attributes plus a citation list: rag.generation.citations (list of chunk_id with offset). Useful when the eval needs to verify each citation is real.
Grounding span
Online evaluator that scores Faithfulness, Context Relevance, Citation Correctness. Either nested inside the generation span or linked via span event. The score is what makes monitoring possible.
Custom spans
Anything your business logic does (security filters, PII redaction, post-processing) gets its own span if you care about its latency or status.
Metrics that ride on RAG spans
Five span-attached metrics matter in 2026:
Retrieval recall
Did the right chunk make it into the top-k? Computed against a labeled gold dataset where each query has a known relevant chunk_id. Recall@k drops are the leading indicator of an index regression.
Context relevance
Is each chunk on-topic for the query? An LLM-as-judge or embedding-similarity metric per chunk. Useful for catching irrelevant chunks that confuse the generator.
Faithfulness (groundedness)
Does the generated answer stay within the retrieved chunks? An LLM-as-judge or NLI-based metric. The single most-important RAG-specific metric. A drop in Faithfulness without a drop in retrieval recall means the generator is hallucinating despite having the right context.
Answer relevance
Does the answer address the user’s question? Useful for catching the case where the retrieval is great but the answer is off-topic.
Citation correctness
Are the cited chunks the actual source of the answer? An automated check that maps each citation back to the chunks the model received. Catches the failure where the answer is correct but the citation is wrong (a different kind of trust failure).
For depth on these metrics, see RAG Evaluation Metrics in 2025.
How RAG observability is implemented
Three integration points in 2026.
Instrumentation
OTel-native libraries that auto-instrument retrievers: traceAI covers LangChain retrievers, LlamaIndex retrievers, Pinecone, Qdrant, Weaviate, Chroma, Milvus. OpenInference covers a similar surface. OpenLLMetry ships native vector DB instrumentations. The libraries emit OTLP spans with retriever attributes.
Backend
The backend stores spans, surfaces the retrieval tree, lets you click a chunk to see its full text, and attaches eval scores. RAG-native backends in 2026: FutureAGI, Langfuse, Phoenix. Closed platforms: Braintrust, LangSmith. APM-native: Datadog (lighter chunk-level UI).
Online evaluators
Faithfulness, Context Relevance, Citation Correctness need to score within minutes of trace ingestion so monitoring catches drift fast. The pattern: a span captures the generation, a worker reads the trace, fires an eval, writes a score event. The eval can be a hosted judge (FutureAGI judges, OpenAI eval, Galileo Luna), a local model, or a deterministic check (Citation Correctness can often be deterministic).
Common mistakes when implementing RAG observability
- Treating retrieval as a black box. Without chunk_id, similarity_score, and doc_version on every retriever span, you cannot debug retrieval failures. Configure the instrumentation library to capture these.
- Span-per-chunk. Each retriever call is one span. Chunks are attributes on that span, not children. Span-per-chunk explodes trace size 10x and adds no debug value.
- Skipping the reranker diff. If you rerank and capture only the after-order, you cannot tell whether the reranker helped. Capture before and after.
- No doc version. A chunk_id without a doc_version makes a stale-index regression undebuggable. Tag each chunk with the doc version at retrieval time.
- No grounding check. Without an online evaluator on Faithfulness, you ship hallucinations until users complain. Run Faithfulness as a span-attached score on production traffic.
- Ignoring the embedding span. A silent change in the embedding model regenerates the index against a different vector space. Capture the model id and version on every embedding span.
- No PII redaction on chunk text. Retriever spans capture chunk_text as an attribute, which carries PII. Configure redaction at the SDK or collector layer before storage. Treat retrieval spans the same way you treat
gen_ai.input.messages. - Static eval datasets. RAG quality drifts when the corpus changes. Build the trace-to-dataset feedback loop: route low-Faithfulness traces into the annotation queue, label them, and use them as the new eval dataset.
The future: where RAG observability is heading
A few directions are settled, others are emerging.
Long-context retrieval traces become legible. Retrieving 200K tokens of context across multiple stages, with reranking, deduplication, and summarization, is a debugging nightmare without span-level structure. Tools that render the retrieval pipeline as a tree with similarity scores and token counts at each step will pull ahead in RAG-heavy workloads.
Multimodal retrieval observability. Image search, audio retrieval, and video retrieval add per-modality attributes. The OTel GenAI conventions are extending to handle this. Tools that capture image embeddings, audio segment ids, and video frame timestamps as span attributes will lead in multimodal RAG.
Agentic RAG observability. A multi-step RAG agent that re-queries based on initial results, calls tools to verify citations, and writes structured output requires session-level metrics on top of trace-level metrics. The unit becomes the agent run, not the single LLM call.
Vector database observability standards. Each vector DB ships its own attribute conventions today. Convergence on a standard rag.* namespace under OTel would let backends decode any retriever uniformly. Early signals in the OpenTelemetry community suggest this is coming.
Eval-driven retrieval iteration. Treating retrieval as a closed-loop optimization problem with online Faithfulness as the reward signal. Tools that close the loop between retrieval, eval, and iteration will pull ahead.
The throughline of all five: by 2026, RAG observability is not a separate category from LLM observability. It is what LLM observability looks like when retrieval is the dominant failure mode. If you cannot see the chunks, score the grounding, and replay the path, you are flying blind on a workload where confident-and-wrong is the failure to fear.
How to use this with FAGI
FutureAGI is the production-grade RAG observability and evaluation stack. traceAI is Apache 2.0 OTel-native instrumentation that auto-instruments LangChain retrievers, LlamaIndex retrievers, Pinecone, Qdrant, Weaviate, Chroma, and Milvus, so retrieval spans carry chunk ids, scores, and content natively. The Agent Command Center renders the retrieval tree, surfaces chunk-level attributes, and attaches RAG-specific eval scores (Faithfulness, Context Relevance, Answer Relevance, Citation Correctness) at the appropriate spans.
turing_flash runs guardrail screening at 50 to 70 ms p95 so a sample of every RAG trace carries per-layer verdicts; full eval templates run at about 1 to 2 seconds for offline replay against canary corpora. The same plane carries 50+ eval metrics, persona-driven simulation that exercises retrieval edge cases, the BYOK gateway across 20+ providers via six native adapters (OpenAI, Anthropic, Gemini, Bedrock, Cohere, Azure) plus OpenAI-compatible presets and self-hosted backends, and 18+ guardrails on one self-hostable surface. Free + pay-as-you-go base; compliance (SOC 2, HIPAA BAA), SSO (OAuth, SAML + SCIM), and enterprise SLAs add on per tier (pricing).
Sources
- OpenTelemetry GenAI semantic conventions
- OpenInference GitHub repo
- traceAI GitHub repo
- OpenLLMetry vector DB instrumentations
- Ragas RAG metrics docs
- DeepEval RAG metrics docs
- FutureAGI pricing
- Langfuse pricing
- Phoenix RAG docs
- Braintrust pricing
- LangSmith pricing
Series cross-link
Read next: What is RAG Evaluation?, RAG Evaluation Metrics in 2025, What is LLM Observability?, What is LLM Tracing?
Related reading
Frequently asked questions
What is RAG observability in plain terms?
How is RAG observability different from regular LLM observability?
What metrics matter for RAG observability in 2026?
Why does chunk-level attribution matter?
Should I trace each chunk as its own span?
What is the difference between RAG observability and RAG evaluation?
How do I monitor for retrieval drift in production?
What does a RAG observability stack look like in 2026?

Best LLMs May 2026: compare GPT-5.5, Claude Opus 4.7, Gemini 3.1 Pro, and DeepSeek V4 across coding, agents, multimodal, cost, and open weights.


Best LLMs April 2026: compare GPT-5.5, Claude Opus 4.7, DeepSeek V4, Gemma 4, and Qwen after benchmark trust broke and prices compressed fast.

Best LLMs March 2026: compare Gemini 3.1 Pro, Claude Opus 4.6, Mistral Small 4, and Qwen for coding, cost, multimodal, and open-weight picks.