What is RAG Fluency? Distinct from Groundedness, Measured in 2026
RAG fluency scores how well a generated answer reads, distinct from groundedness, accuracy, relevance. What it is, measurement, when it matters.

Table of Contents
A RAG-powered legal assistant returns this answer to a question about employee non-competes:
“Per Section 4.2 [doc 12, p3], non-compete duration is 12 months. Section 4.3 [doc 12, p3] confirms enforceability in the relevant jurisdiction. Section 4.4 [doc 12, p4] addresses compensation requirements, which apply. Section 4.5 [doc 12, p4] covers severance interactions.”
Groundedness scores 1.0. Every claim is supported by a citation. Accuracy scores 1.0. Each cited section is correctly summarized. The user reads it once and gives up. The answer is unreadable: four disconnected sentences stitched into a paragraph that nobody would write that way. That is the failure that fluency scoring catches and groundedness scoring misses.
This guide covers what RAG fluency is, why it matters, how it is measured in 2026, and where it fits alongside the other RAG quality axes.
TL;DR: What RAG fluency is
RAG fluency is a quality score for how well a generated answer reads as natural language. It covers:
- Grammar. Sentence-level correctness.
- Coherence. Logical flow between sentences and paragraphs.
- Readability. Sentence length, complexity, lexical density.
- Structure. Paragraph organization, transitions, conclusion.
- Tone. Match to the brand voice or use case.
Fluency is independent of groundedness, accuracy, and relevance. A grounded, accurate, on-topic answer can still read poorly. A fluent answer can be wrong. Production RAG eval scores both axes separately because both can fail independently.
Why RAG fluency exists as a distinct metric
Three observations from production RAG deployments since 2023 made fluency a first-class metric.
Stitched answers from retrieved fragments
Tightly grounded RAG answers often read like a list of retrieved facts rather than a coherent reply. Each sentence is correct; their composition is awkward. The user senses something is off without being able to name it. Pure groundedness scoring rewards this output because every claim is cited. Fluency scoring catches it.
Citation density vs readability trade-off
Heavy inline citation markup (one citation per claim, brackets, footnotes) helps audits and groundedness scoring but degrades the reading experience. Production teams want a metric that rewards a balanced answer: enough citation that the audit layer works, enough fluency that the user does not bounce. Fluency scoring quantifies that trade-off.
Models that hallucinate fluently
The opposite failure: a model that produces beautifully-written, grammatically-perfect, well-paragraphed prose that is factually wrong. Fluency scoring treats this output correctly: high fluency, low groundedness. Aggregating into a single number would hide the contradiction.
The combination forced eval platforms to ship fluency as a separate scorer rather than collapsing it into “answer quality.”
How RAG fluency is measured in 2026
Three families of measurement coexist. Most production stacks use a combination.
LLM-judge with a fluency rubric
The dominant approach. A judge prompt scores the answer against an explicit rubric:
Score the following answer on fluency, 1 to 5:
1 = unreadable, broken grammar, no flow
2 = readable but awkward, frequent friction points
3 = competent prose, minor stiffness
4 = well-written, smooth flow
5 = excellent, publication-quality
Consider:
- Grammar and sentence structure
- Coherence between sentences
- Paragraph organization
- Tone consistency
- Readability for the target audienceUsed by several production eval platforms (Maxim AI-based evaluators with custom fluency rubrics, FAGI fluency template, DeepEval generation metrics, Galileo’s custom-metric surface) and many production RAG eval pipelines. Often calibrated against hundreds of human-labeled samples; teams commonly target weighted Cohen’s kappa above 0.6 (after binning ordinal scores) before trusting the judge.
Perplexity-based scoring
Compute the held-out perplexity of the answer under a reference language model. Lower perplexity correlates with more natural prose. Used as a fast, cheap signal but rarely as the primary metric because it conflates fluency with predictability: a bland, generic answer scores well because next-token prediction is easy. Production use: as a guard signal for catastrophic outputs (token repetition, broken formatting) where the perplexity score deviates so far from baseline that something is clearly wrong.
Classical readability metrics
Flesch-Kincaid Grade Level, Gunning Fog Index, SMOG, and similar formulas score readability based on sentence length and word complexity. Useful when the target audience has a known reading level (consumer-facing copy, regulated content). Not useful for general fluency assessment because they reward simplicity, which can hurt quality on technical content.
Combined scoring
Most 2026 production stacks use:
- LLM-judge rubric as the primary fluency score (continuous 0 to 1 or 1 to 5).
- Deterministic checks on length, sentence count, paragraph count, repeated-token detection.
- Optional perplexity as a sanity guard.
The LLM-judge does the heavy lifting; the deterministic checks catch catastrophic failures fast and cheap; perplexity is opt-in.
When fluency matters and when it does not
Fluency is necessary for products where the user reads the full answer. It is less critical when the user is doing synthesis themselves.
| use case | fluency priority | reason |
|---|---|---|
| customer support reply | high | user reads the full text and judges the brand on it |
| RAG-powered chat | high | conversational tone matters |
| executive summary | high | the summary is the product |
| legal / financial advisory | medium | accuracy dominates; fluency must clear a floor |
| internal research assistant | medium | user can synthesize from rough output |
| code search with snippets | low | user reads the snippets, not the wrapper text |
| structured data extraction | very low | output is JSON, not prose |
| log-and-audit only | very low | fluency irrelevant |
The right framing: fluency rarely trades off against accuracy in practice. They are independent axes. A fluent answer that is wrong is a hallucination. An accurate answer that is unreadable is a stitched-quote dump. Production systems get both.
How fluency interacts with groundedness
The relationship is nuanced.
- Tight citation markup helps groundedness, can hurt fluency. Inline brackets every sentence break flow.
- Loose citation helps fluency, can hurt groundedness. A more LLM-rewritten answer reads better but loses the per-claim audit trail.
- The two-layer pattern. Generate a tightly-grounded answer (one citation per claim, structured). Render a fluency-rewritten version for the user, but keep the grounded version in the trace for audit. Both are scored.
- Fluency-aware groundedness prompts. Some teams prompt the generator to produce fluent prose with citation markers placed at paragraph ends rather than per-claim. Fluency scores rise, groundedness scores hold.
Production patterns that work
Five patterns recur in 2026 production stacks.
Score both axes, never collapse them
Track fluency and groundedness as separate metrics on every production trace. Aggregating them into a single answer-quality number hides the trade-off and makes regressions invisible.
Two-layer generation
Generate a tightly-grounded answer first, then a fluency-pass rewrite. Score both. Surface the fluent version to the user, keep the grounded version in the audit trail. Doubles the LLM cost; the cost is justified for high-stakes user-facing surfaces.
Calibrated judge
Hand-label 200 to 500 fluency examples on a 1 to 5 scale. Calibrate the LLM-judge until Cohen’s kappa exceeds 0.6 against human labels. Recalibrate quarterly or whenever the judge model changes. Without calibration, the judge can be confidently wrong in either direction.
Length and structure guards
Deterministic checks for catastrophic fluency failures: length below a floor, single-sentence paragraph, repeated-token patterns, broken markdown, citation markers without text. Catches the worst 1 to 5 percent of outputs before the LLM-judge runs.
Per-cohort fluency tracking
Fluency drift can hit different user cohorts differently. Track fluency scores per intent class, per language, per content type. A drop in fluency on Spanish replies while English holds steady is a signal a translation pipeline broke; an aggregate score would have masked it.
Common mistakes when measuring RAG fluency
- Using BLEU or ROUGE for fluency. They were not designed for it; they measure n-gram overlap with a reference, not fluency. Reference-free LLM-judge scoring is the 2026 standard.
- Conflating fluency with overall quality. A single-number quality score loses the failure-mode signal.
- Skipping calibration. Uncalibrated LLM-judge fluency scores drift silently.
- Optimizing fluency at the expense of citation density. A fluent answer with no audit trail is not safe in regulated domains.
- No catastrophic-failure guard. Letting the LLM-judge be the only gate misses obvious broken outputs that a deterministic check would catch in milliseconds.
- Tracking the average only. Aggregate fluency scores hide cohort-specific regressions; track distributions and percentiles.
- Same judge for fluency and groundedness. Running both scorers with the same model risks correlated bias. Use different models or different prompts at minimum.
How to use this with FAGI
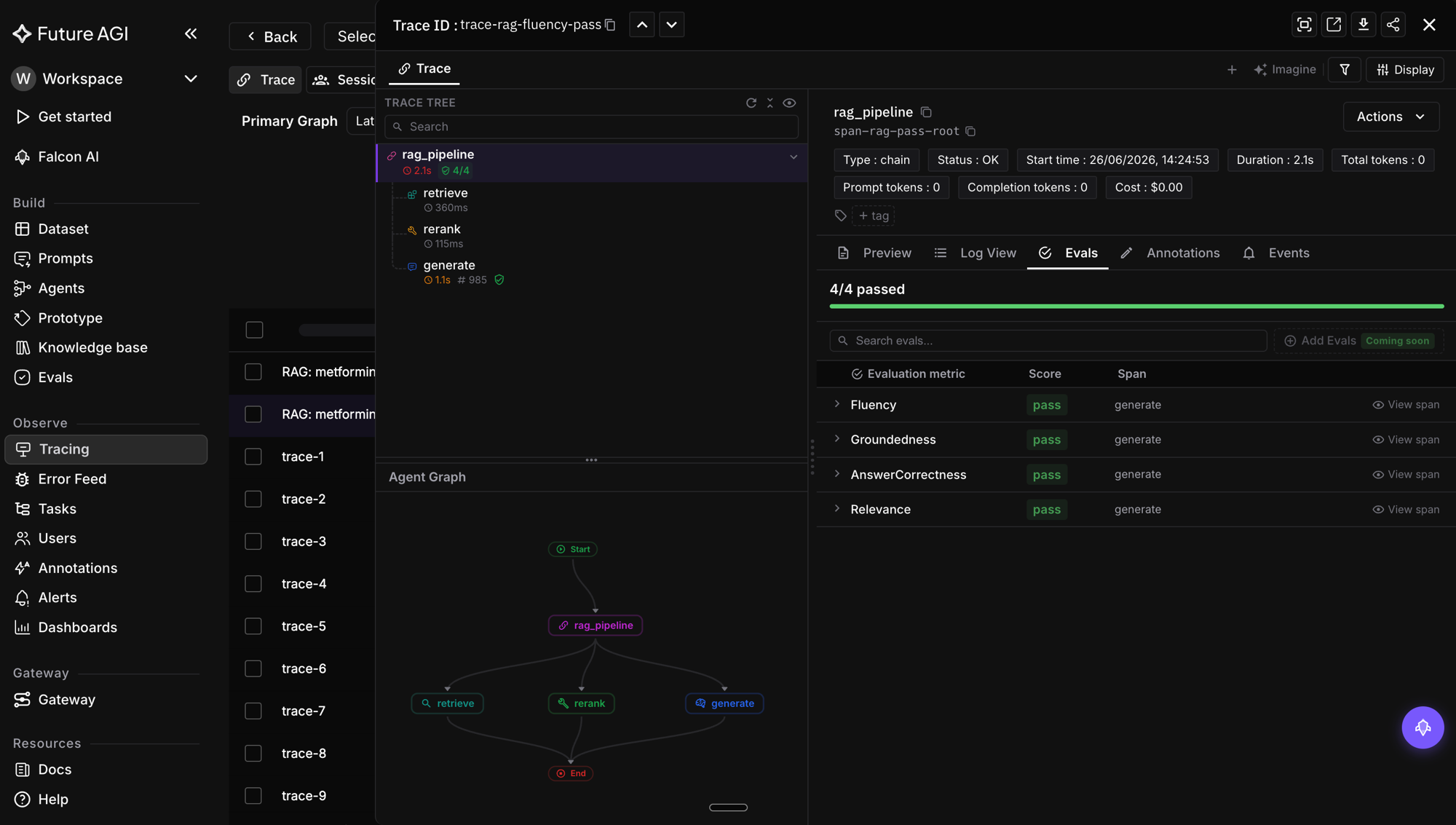
FutureAGI is the production-grade evaluation stack for teams scoring RAG fluency. The platform ships fluency scoring as a production-tested rubric scorer out of the box, with calibration against human labels available. Fluency scores attach to RAG generation spans alongside groundedness, answer correctness, and relevance, so a single trace shows whether the failure was in retrieval, in generation faithfulness, or in fluency. Full eval templates run at roughly 1 to 2 second latency; the lighter turing_flash (50 to 70 ms p95) is suited to fast online checks (length, structure, catastrophic-failure guards). The Agent Command Center routes traces with low fluency scores to human review queues for calibration data without disrupting the user.
The same plane carries 50+ eval metrics, persona-driven simulation, the BYOK gateway across 20+ providers via six native adapters (OpenAI, Anthropic, Gemini, Bedrock, Cohere, Azure) plus OpenAI-compatible presets and self-hosted backends, 18+ guardrails, and Apache 2.0 traceAI instrumentation on one self-hostable surface; pricing starts free with a 50 GB tracing tier. Teams running their own LLM-judge can also bring it to FAGI: rubric-bound prompt, calibrated against 200+ human labels, recalibrated quarterly, scores attached to spans.
Sources
- Galileo Luna metrics overview
- Maxim AI agent evaluation docs
- Ragas open-source RAG eval framework
- DeepEval generation metric library
- Flesch-Kincaid readability formula reference
- Zhang et al. (2020). BERTScore: Evaluating Text Generation with BERT
- Liu et al. (2023). G-Eval: NLG Evaluation using GPT-4 with Better Human Alignment
Series cross-link
Related: What is RAG Evaluation?, RAG Evaluation Metrics in 2025, Evaluating RAG Systems
Frequently asked questions
What is RAG fluency in plain terms?
How is RAG fluency different from groundedness?
How is RAG fluency measured in 2026?
When does fluency matter more than accuracy?
Can fluency and groundedness be in tension?
What scorers do Galileo and Maxim use for RAG fluency?
Does perplexity work as a fluency metric in 2026?
How does RAG fluency relate to BLEU, ROUGE, and BERTScore?

LLM evaluation is offline + online scoring of model outputs against rubrics, deterministic metrics, judges, and humans. Methods, metrics, and 2026 tools.


G-Eval rubric-based LLM judges vs DeepEval's full metric suite, how they differ, and where FutureAGI Turing eval models fit alongside both in 2026.


Cost-efficient AI evaluation in 2026 is the cascade: classifiers, local heuristics, cheap judges. 7 platforms compared on per-eval cost.