What is Evals Engineering? The Discipline Behind Production LLMs in 2026
Evals engineering is DevOps for LLMs: building, maintaining, and gating eval suites that catch real production failures. Role, tooling, and 2026 patterns.

Table of Contents
Imagine a prompt change that lifts one customer’s accuracy by several points but quietly drops another customer’s accuracy by twice that. Nobody catches the regression until the second customer escalates days later. The root cause: a prompt edit that changed how citations were formatted; the LLM-judge rubric had been calibrated against the old format and silently scored the new format wrong. Three different production failures hide in that paragraph: a bad rollout, a calibration drift, and a missing CI gate. All three are the same person’s job.
That person is an evals engineer. The title barely existed in 2023; by 2024 to 2026, eval-focused roles began appearing at AI platform vendors and on production AI teams. This guide covers what the role is, what its core workstreams look like, the tooling stack as it stands, and how it fits with adjacent disciplines (MLOps, eval-driven development, prompt engineering).
TL;DR: What evals engineering is
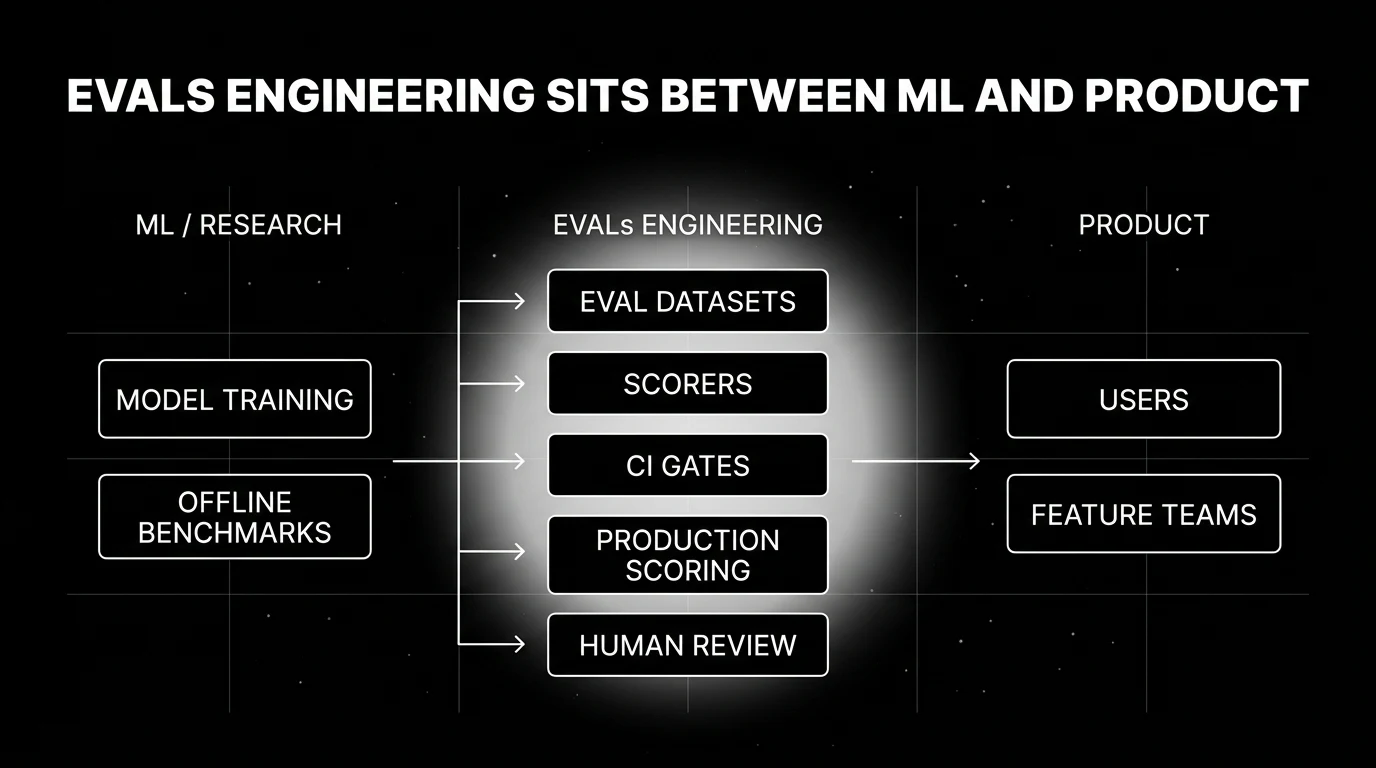
Evals engineering is the discipline of building, maintaining, and operating the evaluation infrastructure that gates LLM and agent quality. It owns:
- Eval datasets. The corpus of inputs the system is scored against.
- Scorers. The LLM-judges, deterministic checkers, and rubrics that produce the scores.
- Calibration. The work of keeping judges aligned with human verdicts as models drift.
- CI gating. The release-time tests that block bad prompt or model changes.
- Production scoring. Online evaluators on sampled traces with drift detection.
- Human-review programs. Label queues, inter-rater agreement, and the calibration loop back into the LLM-judge.
The role sits between ML research (which often does the offline benchmarks at a research cadence) and product engineering (which ships the prompt and model changes that need to be gated). It is, by analogy, DevOps for LLMs: a discipline that emerged because the production needs of the new technology exceeded what existing roles could absorb.
Why evals engineering emerged in 2024
The role did not appear because somebody coined a term. It appeared because three things stopped fitting on existing teams’ plates around 2024.
Failure surfaces went multidimensional
A 2022 LLM application had one or two evaluation axes: did it answer correctly, was the response acceptable. By 2024, RAG systems had retrieval precision, retrieval recall, faithfulness, answer correctness, and citation grounding. Agents added tool-call correctness, plan quality, recovery from failed tool calls, multi-turn coherence, and refusal calibration. No single number captured quality. Building and maintaining the multi-metric scoring stack turned into a full-time job.
Model weight drift became silent and chronic
Some closed-model endpoints can change behavior across provider updates, especially on non-pinned or rolling aliases. A prompt that scored 0.86 on Friday can score 0.79 on Monday because the underlying model behavior changed. Detecting this requires a continuous eval regime: production traces sampled and scored on a regular cadence, time-series of those scores tracked, alerts when the slope inflects. The infrastructure to do this reliably is itself an engineering project.
LLM-as-judge needed calibration as a maintained system
LLM-judge gave teams a way to score open-ended outputs cheaply. It also created a new failure mode: the judge itself drifts, gets recalibrated for the wrong distribution, or disagrees with humans in the long tail. Keeping a judge accurate against a 200 to 1000 sample human-labeled gold set is recurring work. So is updating the gold set when the product changes. So is the inter-rater agreement work that ensures the human labels are themselves consistent.
The combination put more on ML engineers than ML engineers wanted, and required a level of LLM-domain knowledge that backend engineers usually lacked. Industry response: split the work into a new role.
What an evals engineer actually owns
Five workstreams account for most of the role’s day-to-day work.
1. Eval dataset curation
The eval set is the contract. Inputs come from three sources:
- Production traces. Sampled from real traffic; biased toward common cases unless explicitly stratified.
- Customer escalations. The failure cases that actually hurt; gold for regression tests.
- Adversarial seeds. Hand-crafted edge cases (jailbreaks, ambiguous inputs, multilingual, long context).
Curation work covers labeling, deduplication, stratification by intent and difficulty, and ongoing additions as production drifts. The dataset is versioned; comparisons across model versions only make sense against a fixed dataset version.
2. Scorer design and calibration
Scorers come in three flavors:
- Deterministic checkers. Schema validation, regex match, type-check, unit tests, math verification. Cheapest and most reliable when applicable.
- LLM-as-judge. A judge prompt that scores the output against a rubric. Used for open-ended quality (helpfulness, tone, factuality where deterministic checks fall short).
- Human review. The ground truth that calibrates everything else.
Calibration is the recurring work: hand-label 200 to 1000 samples, score them with the judge, compute the agreement rate (Cohen’s kappa, percentage agreement), and tune the judge prompt until the agreement passes a threshold. Recalibrate quarterly or whenever the underlying judge model changes. The LLM-as-judge best practices guide covers the calibration and bias-mitigation mechanics in depth.
3. CI gating
The release gate. When someone changes a prompt, switches a model, or updates a tool definition, the eval suite runs against the new configuration. If scores regress past a threshold (or any high-priority subset regresses), the change is blocked. The CI/CD LLM eval with GitHub Actions guide walks the gate wiring end to end. Practical implementations:
- Per-PR gates. Run a fast subset of the eval set on every PR; full suite on main-branch merges.
- Per-environment gates. Staging promotion blocks on full-suite pass.
- Threshold-aware. Some metrics tolerate noise; the gate threshold is calibrated against historical variance, not zero.
4. Production scoring
The eval suite is offline. Production scoring is online. Sample a slice of traces (the rate is typically tuned by traffic volume, privacy posture, latency budget, and per-eval cost), score them with the deployed scorers, attach the scores to the trace as span attributes, surface them on dashboards. The output is a continuous time series of quality per cohort, per feature, per prompt version.
5. Human review
The label queue. A small fraction of production traces (often the ones the LLM-judge scored low or scored borderline) is routed to human reviewers. Their labels feed:
- Judge calibration. Update the judge against the latest human verdicts.
- Eval set additions. Bad cases get added to the offline eval suite.
- Alerting. A rising disagreement rate between human and judge is an early signal of judge drift.
The evals engineering tooling stack in 2026
The exact tools vary; the stack shape is consistent.
| layer | function | example tools |
|---|---|---|
| trace ingest | OTel-native LLM trace storage | FAGI, Arize Phoenix, Langfuse, LangSmith, Braintrust, Datadog LLM |
| eval framework | scorer library and runner | DeepEval, Ragas, Promptfoo, OpenAI evals, custom |
| LLM-judge runner | dispatch judge calls, attach scores | usually inside the trace platform |
| dataset management | versioned eval corpora | Braintrust, Galileo, FAGI datasets, custom S3 |
| CI integration | block PRs and deploys on regression | GitHub Actions, GitLab CI, Buildkite |
| drift detection | time-series anomaly on scores | LLM-platform built-in or Grafana + alerting |
| human review | label queue, IRR tracking | Argilla, Label Studio, custom internal tools |
Most evals engineers own the glue, not the individual tools. The discipline is in the integration.
Where evals engineering meets adjacent roles
| role | what they own | how they cooperate with evals engineering |
|---|---|---|
| ML engineer | model training, fine-tuning, deployment | hands the deployed model to evals; receives regression alerts and fine-tune candidates from production failures |
| LLMOps / platform | infra (gateways, observability, routing, deployment) | hosts the eval scoring infra; routes traces to the eval pipeline |
| prompt engineer | prompt design and iteration | uses eval suites to score prompt variants; receives calibration feedback |
| product manager | quality bar, customer escalations | drives what counts as good in the rubric; consumes the dashboards |
| QA / SRE | uptime, latency, error budgets | shares pager rotation; quality-score alerts ride alongside infra alerts |
Common evals engineering failure modes
Five recur across teams.
Eval set staleness
The dataset curated at product v1 stops representing v3 production traffic. Symptom: the eval suite passes 100 percent and customers still complain. Mitigation: schedule quarterly refresh; auto-add escalation cases.
Judge drift
The LLM-judge stops scoring the way it did last quarter and starts scoring differently now. Symptom: silent score inflation or deflation across all variants. Mitigation: maintain a frozen human-labeled gold set, re-run judge calibration on every judge-model update, alert when agreement drops.
Goodhart on a single metric
Team optimizes faithfulness, degrades fluency. Symptom: the headline metric improves while user satisfaction tanks. Mitigation: multi-metric dashboards; explicit guard metrics that cannot regress.
Missing the long tail
High-volume cases dominate the eval set; rare cases are under-represented. Symptom: a class of edge-case errors compounds in production while offline scores look healthy. Mitigation: stratified sampling; intent-level dashboards; hard-negative seeding.
CI rubber-stamp
The gate exists but the threshold is so loose that it never blocks anything. Symptom: regressions ship and get caught in production. Mitigation: tighten thresholds based on historical variance; block on any subset regression past a noise floor.
How to use this with FAGI
FutureAGI is the production-grade evaluation and observability stack for teams staffing an evals engineering function. The platform covers the trace, scoring, dataset, and gating layers under one OpenTelemetry-native surface: traceAI (Apache 2.0) ships the production traces, eval templates score them at roughly 1 to 2 second latency for full templates and 50 to 70 ms p95 for turing_flash guardrail-style checks, datasets and CI gating live in the same workflow, and the Agent Command Center is where production scoring routing and policy lives. The evals engineer focuses on dataset curation and judge calibration rather than integration glue.
The same plane carries 50+ eval metrics, persona-driven simulation, the BYOK gateway across 20+ providers via six native adapters (OpenAI, Anthropic, Gemini, Bedrock, Cohere, Azure) plus OpenAI-compatible presets and self-hosted backends, and 18+ guardrails on one self-hostable surface. Free for early teams; pay-as-you-go scales with usage. SOC 2 Type II, HIPAA BAA, SAML SSO + SCIM, and dedicated support add on when you’re ready (pricing). The work itself, curating the dataset, calibrating the judge, writing the gates, watching the dashboards, is portable; FAGI removes the vendor stitching.
Sources
- OpenAI evals GitHub repo
- Anthropic responsible scaling policy and evaluation practices
- Braintrust evaluation platform docs
- Ragas open-source RAG eval framework
- DeepEval open-source eval library
- Promptfoo open-source eval CLI
Series cross-link
Related: What is Eval-Driven Development?, Production LLM Monitoring Checklist 2026, LLM Benchmarks vs Production Evals
Frequently asked questions
What is evals engineering in plain terms?
Is evals engineering a real role or just a job-title rebrand?
How is evals engineering different from MLOps?
What does an evals engineer actually do day to day?
What is the typical evals engineering tooling stack in 2026?
Why did evals engineering emerge as a distinct role around 2024?
What are the most common evals engineering failure modes?
How does evals engineering relate to evaluation-driven development?

Best LLMs May 2026: compare GPT-5.5, Claude Opus 4.7, Gemini 3.1 Pro, and DeepSeek V4 across coding, agents, multimodal, cost, and open weights.


Best Voice AI May 2026: compare Deepgram, Cartesia, ElevenLabs, Retell, and Vapi for STT, TTS, latency budgets, and production voice agents.

Evaluating Claude Skills in 2026: the skill is a contract, eval the contract. Three rubrics for dispatch, trajectory, integration, on traceAI.
