LLM Agents in 2026: 5 Types, Applications, and Evaluation Stack
Compare 5 types of LLM agents in 2026 with real architectures, 2026 model picks (Claude 4.7, GPT-5, Gemini 3), and how to evaluate them in production.

Table of Contents
How LLM Agents Power Real Workflows in 2026
Large language model agents went from research demos in 2023 to production systems in 2026. They run customer support tiers, automate financial workflows, write and review code, and run multi-step research pipelines. This guide breaks down the five main types of LLM agents, the architectures behind them, the 2026 models worth picking, and the evaluation stack you need before shipping.
TL;DR: LLM Agent Types and 2026 Model Picks
| Agent type | Primary use case | Strong 2026 model picks | Top evaluation metric |
|---|---|---|---|
| Conversational | Customer support, virtual assistants | gpt-5, claude-opus-4-7, gemini-3-pro | Intent resolution, response latency |
| Task-oriented | Reporting, data analysis, automation | claude-opus-4-7, gpt-5, llama-4 | Task completion rate, tool-call accuracy |
| Autonomous | Long-horizon goal pursuit | claude-opus-4-7 (1M context), gpt-5 | Trajectory accuracy, cost per resolution |
| Reasoning | Legal, medical, scientific analysis | claude-opus-4-7, gpt-5-pro, gemini-3-pro | Faithfulness, citation accuracy |
| Creative | Content, music, marketing | gpt-5, claude-opus-4-7, gemini-3-pro | Style adherence, human preference score |
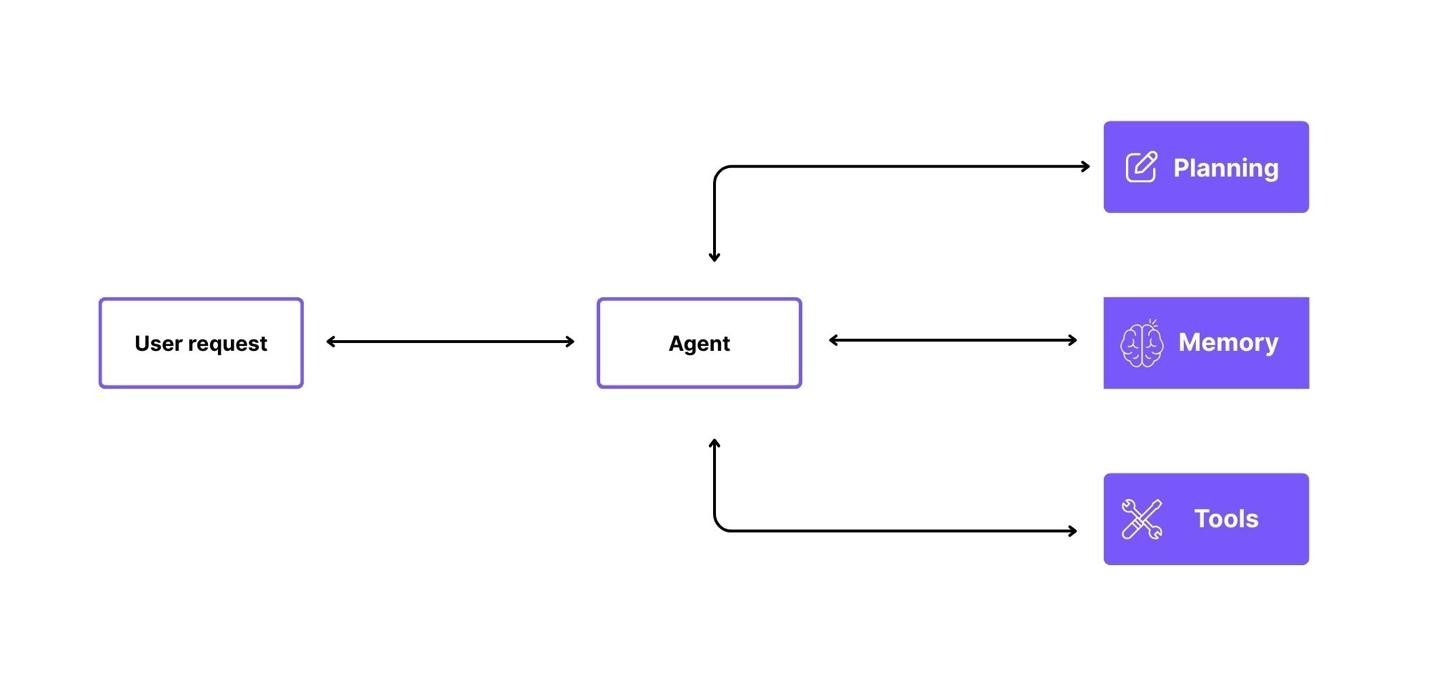
Image 1: LLM agent structure diagram
What Are LLM Agents and How They Differ from Plain LLMs in 2026
A plain LLM responds to a single prompt and stops. An LLM agent wraps the same model in a loop with planning, memory, and tool use. The agent reasons about a goal, picks the next step, executes a tool, observes the result, and continues until the goal is met or the budget runs out.
This loop is the entire reason agent evaluation is harder than LLM evaluation. A single bad tool call early in the trajectory cascades into wrong context, wrong reasoning, and a wrong final answer. The 2026 production-grade stacks for LLM agent workflows use evaluators that score each step of the trajectory, not just the final output.
Classification of LLM Agents: Five Categories by Role and Functionality
1. Conversational LLM Agents: Real-Time Dialogue for Support and Virtual Assistants
Conversational LLM agents hold turn-by-turn dialogue with humans. The job is intent resolution, context retention across turns, and low end-to-end latency. Production systems in 2026 typically run gpt-5, claude-opus-4-7, or gemini-3-pro behind a router that picks the cheapest model for routine turns and escalates to a stronger model for complex ones.
Key features:
- Engage users in real-time conversations.
- Maintain context across multi-turn sessions.
- Support 100+ languages with strong code-switching.
- Stream tokens for sub-second time-to-first-token.
Applications:
- Customer support: Chatbots resolve tier-1 queries and route the rest.
- Virtual assistants: Voice-first systems like ChatGPT Voice and Gemini Live handle daily tasks.
- Education: Tutoring bots adapt to student pace.
Top evaluation metrics: intent resolution, response latency, conversation quality, escalation rate.
2. Task-Oriented LLM Agents: Step-by-Step Execution for Writing, Data Analysis, and Automation
Task-oriented agents do a single job well. The user gives a one-shot task description, and the agent breaks it into steps, calls the right tools, and returns a structured result.
Key features:
- Integrate with apps like email, databases, and BI tools.
- Execute tasks step-by-step with intermediate checkpoints.
- Handle errors and request clarification on ambiguous inputs.
Applications:
- Content creation: Tools that draft blog posts, briefs, or product copy.
- Automation: Agents that schedule, invoice, or reconcile financial entries.
- Data analysis: Agents that read tables, run SQL, and summarize findings.
Top evaluation metrics: task completion rate, tool-call accuracy, hallucination rate.
3. Autonomous LLM Agents: Long-Horizon Goal Pursuit with Memory and Self-Correction
Autonomous agents operate over long horizons. You hand them a goal, and they plan, execute, observe, replan, and self-correct without supervision. Coding agents like Claude Code, Cursor agents, and Devin sit in this category. So do research agents that read papers, browse the web, and write reports.
Key features:
- Make goal-driven decisions across dozens of steps.
- Track progress with long-term memory (vector store or structured scratchpad).
- Improve through reflection and self-critique loops.
Applications:
- Research: Summarize academic literature and produce citation-backed reports.
- Coding: End-to-end feature implementation and bug fixing.
- Operations: Manage inventory, predict demand, automate fulfillment.
Top evaluation metrics: trajectory accuracy, cost per resolved task, recovery rate after failed steps.
4. Reasoning LLM Agents: Logic-First Agents for Legal, Medical, and Scientific Work
Reasoning agents are tuned for stepwise logical analysis. They retrieve grounded sources, reason over them, and explain their conclusions with citations. Models like gpt-5-pro, claude-opus-4-7 with extended thinking, and gemini-3-pro Deep Think are the typical backbones.
Key features:
- Use chain-of-thought or extended thinking budgets.
- Retrieve knowledge from large, curated corpora.
- Estimate confidence and cite sources for each claim.
Applications:
- Legal analysis: Draft contracts, summarize case law, flag risk clauses.
- Medical diagnosis: Suggest differentials with literature citations.
- Scientific research: Analyze experimental data and propose follow-up experiments.
Top evaluation metrics: faithfulness, citation accuracy, reasoning chain validity.
5. Creative LLM Agents: Original Content Generation for Storytelling, Marketing, and Music
Creative agents generate novel content under style and brand constraints. They mix transformer text generation with diffusion image and audio models.
Key features:
- Produce diverse, on-brand outputs.
- Specialize per domain via fine-tuning or in-context style guides.
- Refine work iteratively based on user feedback.
Applications:
- Storytelling: Long-form fiction and interactive narrative tools.
- Marketing: Campaign copy, ad variants, social posts.
- Entertainment: Music composition, game asset generation.
Top evaluation metrics: style adherence, brand voice consistency, human preference score.
LLM Architectures Powering Agents in 2026: Transformer, MoE, RAG, and Modular Designs
The architecture you pick controls cost, latency, and reasoning depth. The four patterns below cover most production agent stacks in 2026.
Transformer-Based Architectures: The Default for Most Agents
Transformers with attention remain the core architecture. The 2026 reality is that virtually every major foundation model still uses a transformer backbone with extensions like grouped-query attention, sliding-window attention, and long-context positional encodings.
Strong examples: gpt-5, claude-opus-4-7, gemini-3-pro, llama-4-405b.
Strengths: strong general reasoning, large context windows (1M tokens on Gemini and Claude), fast parallel inference.
Mixture-of-Experts (MoE): Cheaper Inference at Frontier Quality
Mixture-of-experts routes each token to a small subset of experts instead of activating the full parameter count. This cuts inference cost without losing benchmark quality. As of May 2026, MoE shows up in many production agent stacks, especially through open-weights families.
Strong examples: Llama 4 (Maverick and Scout) and Mixtral-style open models have publicly documented MoE architectures. Other frontier vendors describe efficient routing in their model cards without always confirming the exact pattern.
Strengths: lower cost per token, fast inference on long context, competitive quality with dense models 5x larger.
Retrieval-Augmented Generation (RAG): Grounded Answers from External Knowledge
RAG retrieves relevant documents from a vector index or hybrid search system and stuffs them into the agent context. This is the cheapest way to ground an agent in proprietary data without fine-tuning. For agent-specific RAG patterns, see our agentic RAG systems guide.
Strong examples: any agent built on top of a vector database (Pinecone, pgvector, Weaviate) combined with a frontier LLM.
Strengths: grounded factual responses, easy to update knowledge without retraining, auditable citations.
Modular Architectures: LangGraph, AutoGen, and the Claude Agent SDK
Modular agent frameworks split planning, memory, and tool use into separate components. This makes the agent easier to test because each module has its own evaluation surface. LangGraph, AutoGen, CrewAI, and the Claude Agent SDK all follow this pattern.
Strengths: each module can be evaluated and swapped independently, easier to add new tools without rewriting the planner, cleaner traces for observability.
Use Cases for Different LLM Agents Across Industries in 2026
Healthcare: Conversational, Reasoning, and Autonomous Agents
Healthcare uses every agent type. Conversational agents handle patient intake and scheduling. Reasoning agents support diagnostics and treatment planning by retrieving literature and pulling structured patient data. Autonomous agents monitor remote patient signals and escalate to clinicians when thresholds are crossed.
Finance: Task-Oriented and Reasoning Agents
Task-oriented agents automate routine financial workflows like reconciliation, reporting, and trade execution checks. Reasoning agents analyze market data and draft investment memos. Conversational agents handle client questions in retail banking.
Education: Creative, Conversational, and Reasoning Agents
Creative agents generate quizzes and learning materials. Conversational agents tutor students in real time. Reasoning agents recommend personalized study plans grounded in student progress.
E-Commerce: Autonomous, Conversational, and Task-Oriented Agents
Autonomous agents handle inventory forecasting and reorder workflows. Conversational agents recommend products and answer support questions. Task-oriented agents process orders, returns, and refunds.
Entertainment: Creative and Conversational Agents
Creative agents draft scripts, compose music, and generate game assets. Conversational agents power dynamic NPCs and interactive story experiences.
LLM Design Choices That Change Agent Performance
Model Size and the Cost-Quality Trade-Off
Large frontier models like gpt-5, claude-opus-4-7, and gemini-3-pro handle complex reasoning and long-context tasks but cost more per call. Mid-tier models like claude-sonnet-4-5, gpt-5-mini, and gemini-3-flash are usually good enough for routine task-oriented agents. Pick the smallest model that passes your evaluation bar.
Training Data and Domain Specialization
Models trained or fine-tuned on domain data (medical, legal, financial) typically outperform general-purpose models on in-domain tasks. The trade-off is narrower applicability and the cost of maintaining the fine-tuning pipeline.
Fine-Tuning Versus In-Context Steering
Fine-tuning still wins for high-volume, narrow tasks where every token of latency matters. For most agent workloads in 2026, in-context steering with long system prompts, structured tool definitions, and retrieval is faster to iterate and easier to evaluate.
Prompt Engineering and Structured Tool Calling
Well-designed prompts and well-typed tool schemas dramatically reduce agent error rates. Structured outputs (JSON schema, Pydantic, Zod) catch malformed tool calls before they reach downstream systems.
Challenges Facing LLM Agents in 2026
Cost and Compute
Frontier models still cost real money at agent scale. A single autonomous coding agent can rack up dozens of dollars on a complex task. Cost observability and routing to cheaper models for routine steps are mandatory.
Interpretability
Agents take multiple steps before producing a final answer. Without structured traces, debugging a wrong output is slow. Full-trajectory observability is non-negotiable in regulated industries.
Safety and Prompt Injection
Autonomous agents that browse the web or read user-supplied documents are exposed to prompt injection. Guardrails on tool calls and structured output validation are the front line of defense.
Hallucination and Reliability
Hallucinations compound across agent steps. Even a 5% per-step error rate becomes a 23% chance of failure across a five-step trajectory. Per-step evaluators that flag low-confidence outputs are the only practical way to keep long agents reliable.
How to Evaluate LLM Agents in 2026
Production-grade agent evaluation runs across three layers.
Layer 1: Per-Step Evaluation
Score each step of the trajectory. Did the agent pick the right tool? Were the arguments correct? Did the output match the schema? This is the focus of evaluating tool-calling agents. Future AGI exposes evaluators like tool_call_accuracy and output_validation via the fi.evals SDK.
from fi.evals import evaluate
result = evaluate(
"tool_selection",
output="search_docs",
input="What is the refund policy?",
expected_tool="search_docs",
model="turing_flash",
)
print(result.score, result.reason)Layer 2: Trajectory Evaluation
Score the full multi-step run. Did the agent achieve the user goal? How many steps did it take? Did it recover from any failed steps?
from fi.evals import evaluate
result = evaluate(
"task_completion",
output=final_response,
input=user_goal,
trajectory=agent_steps,
model="turing_large",
)Layer 3: Continuous Observability
Stream every agent run into an observability backend. Future AGI traceAI provides OpenTelemetry-based instrumentation that captures spans for each LLM call, tool call, and retrieval step, attaches evaluation scores, and surfaces regressions over time. traceAI is open source under Apache 2.0 (LICENSE).
from fi_instrumentation import register, FITracer
tracer_provider = register(
project_name="my-agent",
project_version_name="v1",
)
tracer = FITracer(tracer_provider.get_tracer(__name__))
with tracer.start_as_current_span("agent_run") as span:
span.set_attribute("input.user_goal", user_goal)
response = agent.run(user_goal)
span.set_attribute("output.response", response)For agentic systems specifically, the agentic AI evaluation guide covers product and engineering collaboration patterns in depth.
How Future AGI Helps You Evaluate and Ship LLM Agents
Future AGI provides three pieces that production agent teams need:
fi.evalsfor per-step, trajectory, and safety evaluations across text, image, audio, and video.- traceAI for OpenTelemetry-based observability of every agent run.
fi.simulatefor running agents against thousands of synthetic personas and scenarios before they touch production traffic.
Set the standard env vars (FI_API_KEY and FI_SECRET_KEY) and you can wire evaluators into an agent in under five minutes. The Agent Command Center at /platform/monitor/command-center then routes traffic across providers and applies guardrails per route.
Frequently asked questions
What are the 5 main types of LLM agents in 2026?
Which 2026 LLM should I pick to power an agent?
How do I evaluate an LLM agent before shipping to production?
What is the difference between conversational and autonomous LLM agents?
What architectures power LLM agents in 2026?
Do I need observability to run LLM agents in production?
How is agent evaluation different from LLM evaluation?

Gemini 3.5 Flash dropped today at Google I/O 2026. The 8 benchmark numbers that matter, $1.50/$9 pricing breakdown, and what to instrument before you swap.


Compare GPT-5, Claude Opus 4.7, Gemini 2.5 Pro, and Grok 4 on GPQA, SWE-bench, AIME, context, $/1M tokens, and latency. May 2026 leaderboard scores.


Compare top AI guardrail tools in 2026: Future AGI, NeMo Guardrails, GuardrailsAI, Lakera Guard, Protect AI, Presidio. Coverage, latency, how to choose.