Gemini 3.5 Flash: The Numbers Behind the May 2026 Launch
Gemini 3.5 Flash dropped today at Google I/O 2026. The 8 benchmark numbers that matter, $1.50/$9 pricing breakdown, and what to instrument before you swap.

Table of Contents
Updated May 19, 2026. Google launched Gemini 3.5 Flash at I/O this morning. The pitch is agents, not chatbots — long-horizon, parallel sub-agents, tool use across MCP servers. The benchmark slide deck is genuine, the pricing changed, and the production failure modes are not on the slide deck. This post is the practitioner read: eight numbers that matter, an honest pricing breakdown, and the four failure modes you should be instrumenting today.
TL;DR: the numbers that matter
Gemini 3.5 Flash is the new ceiling for the Flash tier and the new default for production agent workloads that need long context, low latency, and competitive intelligence at a sub-Pro price.
| # | Metric | Gemini 3.5 Flash | Reference |
|---|---|---|---|
| 1 | Output tokens / sec | 280+ | ~4x faster than the GPT-5 / Claude Sonnet 4.6 cohort |
| 2 | Context window | 1,000,000 tokens | Same as Gemini 3 Flash |
| 3 | Pricing (input / cached / output, per 1M) | $1.50 / $0.15 / $9.00 | 3x increase over Gemini 3 Flash; 90% cached-input discount |
| 4 | Artificial Analysis Intelligence Index | 55 | Claude Sonnet 4.6: 52; Gemini 3 Flash: 46 |
| 5 | GDPval-AA Elo (agentic) | 1,656 | Gemini 3.1 Pro: 1,314; GPT-5.4 xhigh: 1,674 |
| 6 | Terminal-Bench 2.1 (coding) | 76.2% | Gemini 3.1 Pro: 70.3% |
| 7 | MCP Atlas (agentic tool use) | 83.6% | Gemini 3.1 Pro: 78.2%; Claude Opus 4.7: ~79 |
| 8 | OSWorld-Verified (agentic) | 78.4% | Gemini 3.1 Pro: 76.2%; computer-use still unsupported |
| 9 | Finance Agent v2 | 57.9% | Gemini 3.1 Pro: 43.0% — the largest single-benchmark gain |
| 10 | MMMU-Pro (multimodal) | 83.6% | Gemini 3.1 Pro: 80.5% |
| 11 | MRCR v2 · 128k (dense recall) | 77.3% | Gemini 3.1 Pro: 84.9% — Flash trails by 7.6 points |
| 12 | ARC-AGI-2 (abstract reasoning) | 72.1% | Gemini 3.1 Pro: 77.1% — Flash trails by 5.0 points |
| 13 | Humanity’s Last Exam (raw knowledge) | 40.2% | Gemini 3.1 Pro: 44.4% — Flash trails by 4.2 points |
| 14 | AA-Omniscience hallucination rate | 61% | 31-point improvement over Gemini 3 Flash; still high in absolute terms |
The headline is Intelligence Index 55 with $1.50 / $9 pricing — Flash now sits above Claude Sonnet 4.6 on the public composite benchmark while staying meaningfully cheaper. The number that should slow your roll is the 61% AA-Omniscience hallucination rate. It dropped 31 points generation-over-generation, the largest single-model jump we’ve seen in 2026, and it’s still over half of factual-recall prompts wrong. That’s a guardrails problem, not a “we’ll fix in v3.6” problem.
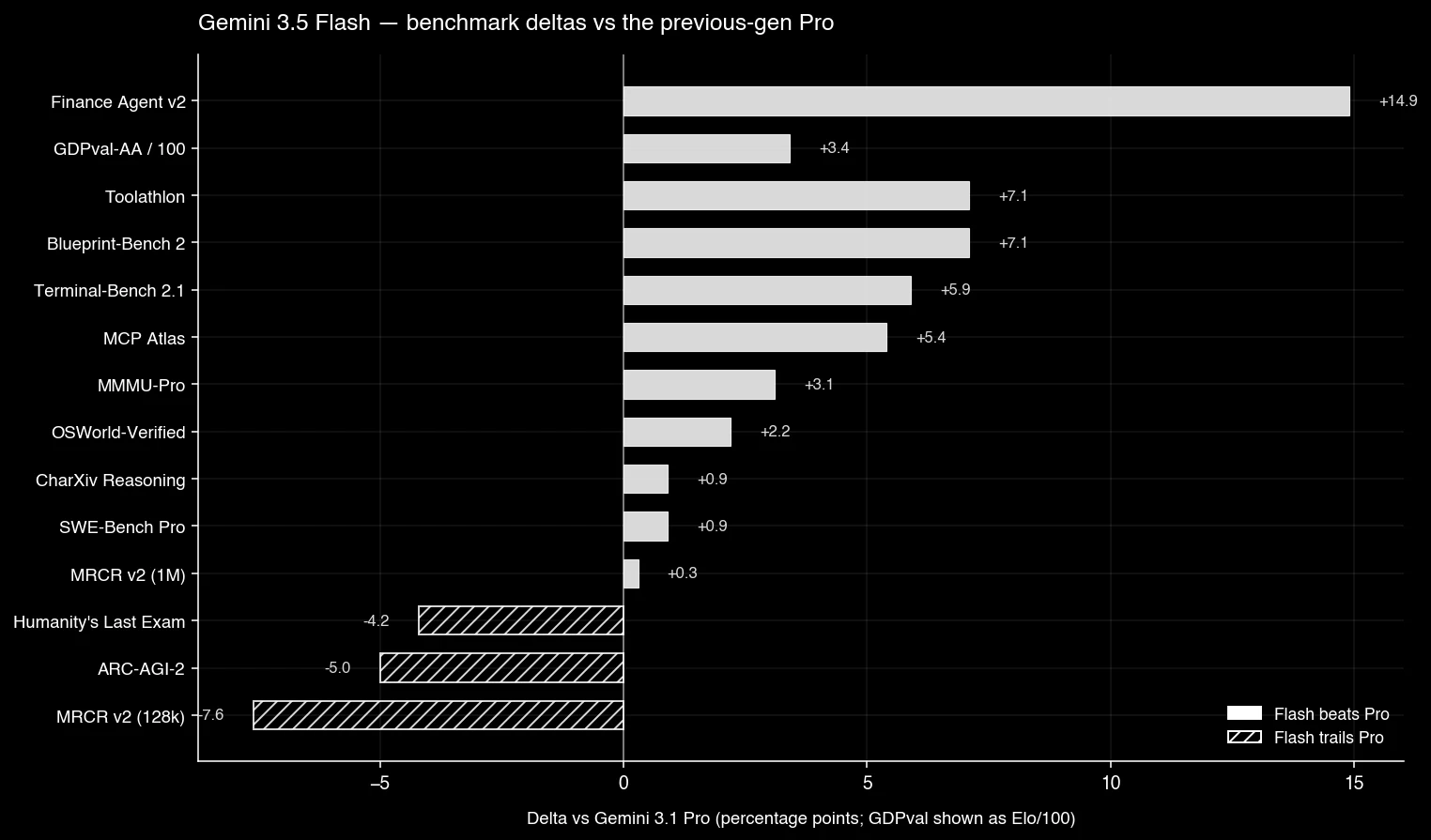
The deltas plot tells the rest of the story — three benchmarks where Flash trails Pro, eleven where it wins:
What actually shipped today
Sundar Pichai called it “a major leap forward in building more capable, intelligent agents” on stage. The substance behind that line is three things:
- Flash now beats last generation’s Pro on agent benchmarks. GDPval-AA Elo 1656 versus Gemini 3.1 Pro at 1317. Terminal-Bench 2.1 at 76.2% versus 70.3%. MCP Atlas tool-use also higher. The Flash / Pro hierarchy inverts for agent workloads.
- Pricing repositions Flash as a mid-tier model. $1.50 input / $9 output is 3x the previous Flash. It’s still ~50% the cost of Claude Sonnet 4.6 ($3 / $15). The “Flash is the cheap one” mental model from 2024 is gone.
- Agent capabilities are first-class. Google demoed multi-hour autonomous runs, parallel sub-agent spawning, pause-for-human-input checkpoints, and self-built operating systems in internal tests. Koray Kavukcuoglu framed it as “an incredible combination of quality and low latency.”
The Pro variant of Gemini 3.5 is expected next month. Today’s launch is Flash only.
Gemini 3.5 Flash is available in the Gemini app, AI Mode in Search, Gemini Enterprise, Gemini API, and Antigravity, globally across 230+ countries to the 900M monthly users Google reported on stage.
The pricing math: what changed and what didn’t
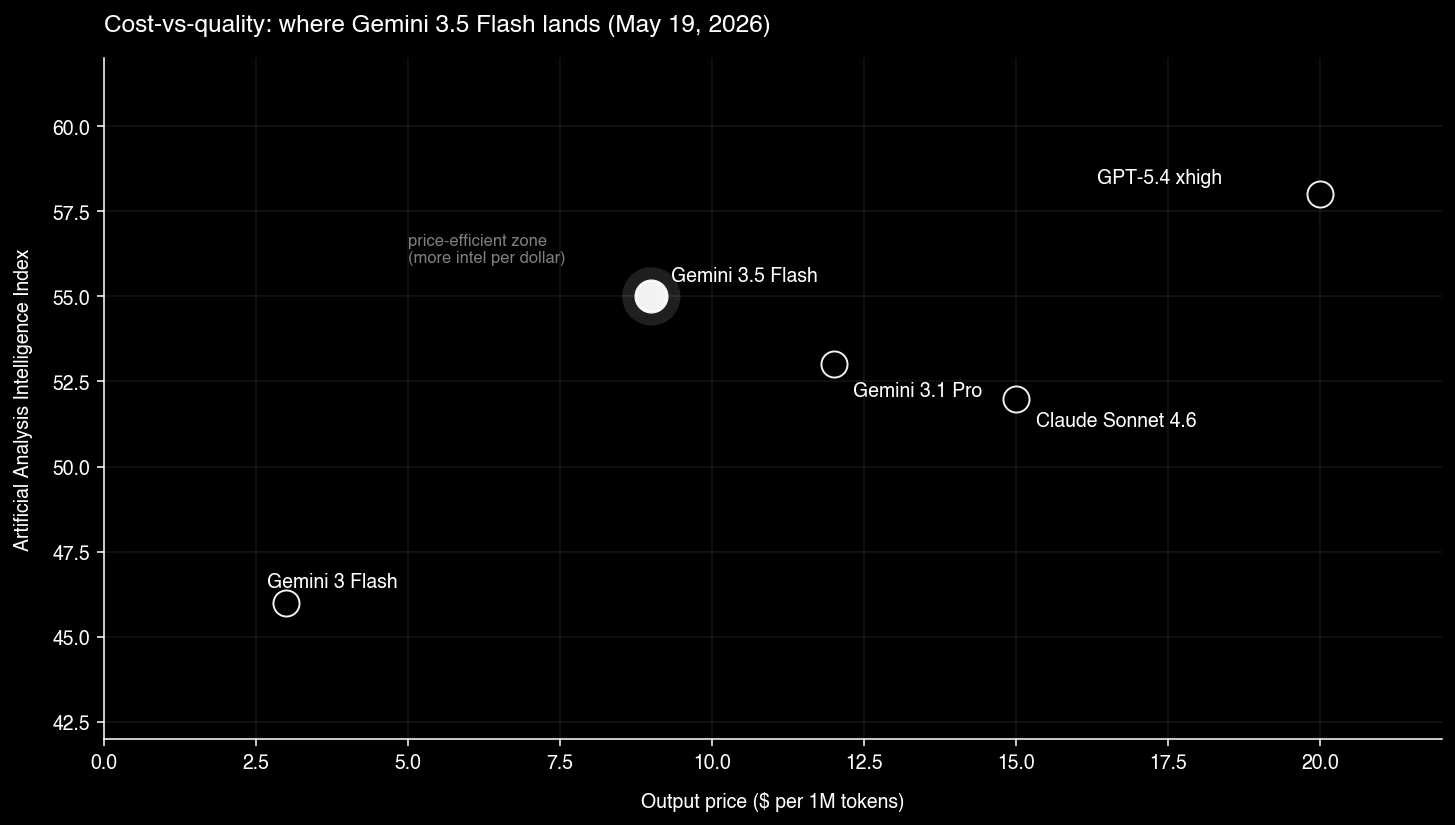
Flash got more expensive in absolute terms and cheaper in cost-per-quality terms. Both are true at once.
| Model | Input ($/1M) | Output ($/1M) | Intel Index | $ to run Intel Index suite |
|---|---|---|---|---|
| Gemini 3.5 Flash | $1.50 | $9.00 | 55 | $1,552 |
| Gemini 3 Flash | $0.50 | $3.00 | ~46 | ~$280 |
| Claude Sonnet 4.6 | $3.00 | $15.00 | 52 | higher than 3.5 Flash |
| Gemini 3.1 Pro | confidential | confidential | unspecified | 75% lower per-token than 3.5 Flash |
The cached-input discount (90% off cached input tokens, down to $0.15 per 1M) is the lever that matters. If your agent has a 50-token system prompt + a 2000-token retrieval context block repeated across calls, cache hit rate on the input side bends the actual unit economics by 5-7x compared to the published list price. We’ve been logging cache hit rates on the production traffic shape that ships through gateway.futureagi.com/v1 since Gemini 3 Flash landed; agents with stable system prompts saturate the cache within the first 30 minutes of a session.
What didn’t change: the cost story for one-shot Q&A workloads. If you’re calling Flash without retrieval context and without a stable system prompt, the new pricing is straight-up 3x more expensive than what you were paying yesterday for Gemini 3 Flash. Artificial Analysis reported a 5.5x total benchmark-suite cost increase versus Gemini 3 Flash — partly the unit-price rise, partly because the new model is verbose (it generated ~73M output tokens running the full Intelligence Index suite).
Plotted against intelligence, Flash 3.5 lands in the price-efficient zone — meaningfully cheaper than Sonnet 4.6 with a higher Intel Index, and ~55% cheaper than GPT-5.4 xhigh for 3 fewer Index points:
Where it slips: the three benchmarks Google didn’t lead with
Every Pro-tier-replacing Flash launch has the same hidden cost: somewhere on the benchmark sheet, the smaller model gives ground. Gemini 3.5 Flash gives ground in three places that matter for specific workloads:
1. Dense long-context recall: MRCR v2 · 128k
Flash scores 77.3% vs Pro at 84.9% — a 7.6-point regression. At the 1M-token end of the window the two are within 0.3 points (26.6% vs 26.3%), which tells you something: the regression is in the 128k regime where dense critical information is packed tight. If your workload is “agent reasoning over a single 100-page document with one key fact buried mid-way,” 3.1 Pro is still the right pick. If your workload is “needle in a 1M-token haystack,” neither model is doing it well — both are at 26%.
2. Abstract reasoning: ARC-AGI-2
Flash scores 72.1% vs Pro at 77.1% — a 5-point regression. ARC-AGI-2 is the closest public proxy to “novel-puzzle reasoning under distribution shift” and the gap matters for research workloads that depend on the model finding unprompted solutions. For action-oriented agents, this gap is mostly invisible.
3. Raw parametric knowledge: Humanity’s Last Exam
Flash scores 40.2% vs Pro at 44.4% — a 4.2-point regression. Humanity’s Last Exam is dominated by raw memorized facts across hard sciences and obscure domains. If your agent is going to be asked “what’s the boiling point of 2-methylpentane at 800 Pa?” without retrieval, Pro is still the better recall engine. Most production agents shouldn’t depend on parametric knowledge anyway — that’s what RAG is for.
Rule of thumb from the llm-stats team that ran the migration analysis: “If your work is closer to research than to action, stay on 3.1 Pro for now.”
The thinking_level migration trap
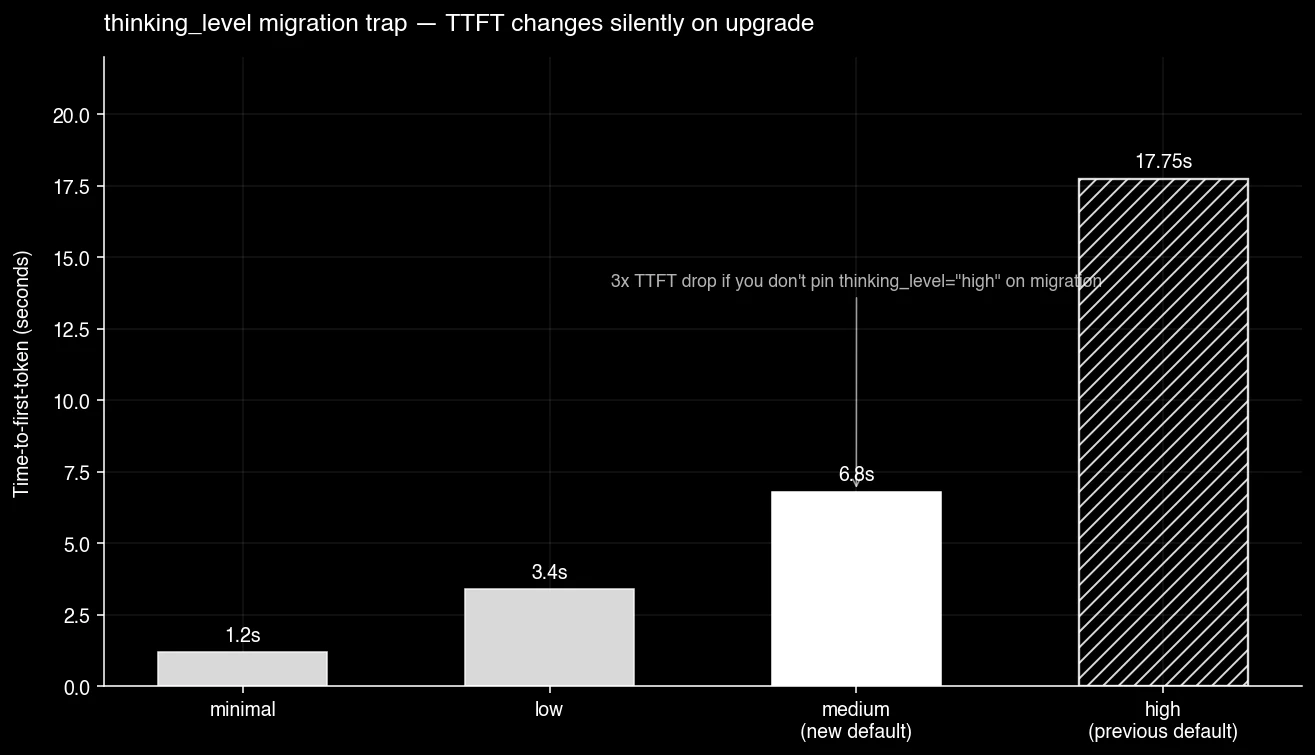
This is the gotcha that will silently degrade quality across migrating teams over the next two weeks: the thinking_budget integer parameter from Gemini 3 Flash is gone. Gemini 3.5 Flash replaces it with a thinking_level enum: minimal / low / medium / high. The default dropped from high to medium.
If you migrate by changing only the model name, your existing agent silently starts thinking less than it did yesterday. Quality drops, latency drops, cost drops — and you’ll spend a week chasing a benchmark regression that’s actually a configuration regression.
The fix is one line on the request payload:
response = model.generate_content(
prompt,
generation_config={
"max_output_tokens": 4096,
# CRITICAL: pin thinking_level explicitly on migration
# default changed from "high" (in 3 Flash) to "medium" (in 3.5 Flash)
"thinking_level": "high",
},
)If you’re running an A/B between Gemini 3 Flash and 3.5 Flash and not seeing the benchmark wins Google advertised, this is almost certainly the cause. Pin the level explicitly. Then re-run.
Hands-on: what the community found in the first 24 hours
The first wave of independent reviewers ran live tests through May 19 and May 20. Pulling the recurring patterns:
Speed lands as advertised.
- Analytics Vidhya hands-on: “No response taking more than 10 seconds to start.” Three tests across prototyping, reasoning, and visual generation — all sub-10s for the LLM call.
- llm-stats migration test: Time-to-first-token at
thinking_level=lowsits around 3.4s; the 280 tok/s sustained-throughput number is consistent across the agent benchmarks.
Coding output still ships incomplete artifacts.
- Analytics Vidhya e-commerce frontend test: The model produced an HTML/CSS frontend with responsive layout in under 10 seconds. The output had “some images missing and some buttons aren’t functional either.” Useful for rapid iteration, not for production-ready code.
- GitHub Copilot: Gemini 3.5 Flash went GA in Copilot the same day as the launch — Copilot’s lazy-evaluation harness papers over the “missing assets” failure mode at the IDE level, which is part of why Copilot adoption will move faster than direct-API agent adoption.
Image generation routes through a workaround.
- Analytics Vidhya visual test: Image generation in the Gemini App “was experiencing issues” and the reviewer worked around by using AI Mode in Search instead. The Flash model outputs text only — image generation in the Gemini App goes through a separate pipeline that was rate-limited on launch day.
Real production design partners are public.
- Macquarie Bank: piloting financial-document processing on the 1M-token context window
- Ramp: piloting messy-invoice batch processing
- Antigravity: listed alongside Gemini API as a launch surface — agent-development environment
The benchmark cost is real.
- Running the Artificial Analysis Intelligence Index suite cost $1,552 on Gemini 3.5 Flash versus ~$280 on Gemini 3 Flash. That’s a 5.5x increase. Roughly half of it is the unit-price rise; the other half is verbosity — the new model generates ~73M output tokens running the suite.
The thing nobody is testing yet. We have not seen a published multi-hour endurance test. Google’s keynote demos ran for “multiple hours” with parallel sub-agents. Outside of Google, the longest published run as of May 20 morning is ~22 minutes. The reliability curve past the 1-hour mark is currently unknown for any external workload, and that’s the regime where Reliability Decay Curve (RDC) and Meltdown Onset Point (MOP) failures show up.
The four agent failure modes Gemini 3.5 Flash will surface in your traces
This is the part that doesn’t make it into the keynote. When a Flash-tier model lands with Pro-tier agentic scores, every team’s first instinct is to swap. The swap exposes failure modes that the eval slide deck does not score:
1. Hallucination on long-tail factual recall
AA-Omniscience hallucination rate is 61%. The number dropped 31 points from Gemini 3 Flash, which is excellent generation-over-generation progress. It is still a model that fabricates over half the time on factual recall outside its training distribution. For agents doing customer-facing Q&A, finance lookups, or any task with a verifiable ground truth, you need a faithfulness evaluator and hallucination detection scoring every response and a refuse-on-low-confidence policy in front of the user.
The right instrumentation is field-level evaluation joined to the span. We ship 60+ built-in evaluators across 11 categories in ai-evaluation including ContextAdherence, Groundedness, Faithfulness, ChunkAttribution, and CitationCorrectness. Tag each span with the eval score, alert on the drift, refuse below threshold.
2. Tool-call regressions across MCP servers
Gemini 3.5 Flash scores higher on MCP Atlas than 3.1 Pro. That measures aggregate tool-use quality. It does not measure tool-call regression on YOUR tool topology. Production failures we’ve seen across MCP migrations include argument-name drift (the model picks the wrong field name from a similar tool), retry-loop traps (the model retries on success because the response schema changed), and tool-confusion failures (two tools with similar names get conflated).
Catch these with a tool-call evaluator that scores the argument JSON against the tool schema before execution. Trace the call. Cluster the failures. The Error Feed groups them into named issues with auto-written root cause and immediate fix.
3. Multi-hour endurance failures
Google demoed multi-hour autonomous runs. The benchmark that measures this — long-horizon endurance — has been a published failure mode across every frontier model in 2026. Reliability Decay Curve (RDC) and Meltdown Onset Point (MOP) are the metrics the field has settled on. Most agents fail not at the first tool call but somewhere between minute 40 and hour 3, when memory accumulation, context-window erosion, or sub-agent coordination cascades into a logic failure.
You need observability at the span level to catch this. traceAI auto-instruments 19 Python frameworks plus 3 TypeScript adapters into OpenInference-compatible spans. Combined with eval scores joined to spans, you get a per-minute reliability curve across the run, not a single end-of-run success or fail.
4. Prompt-injection through multi-modal input
Gemini 3.5 Flash takes image, video, and audio as input. Multimodal input is multi-modal attack surface. The MCP Atlas score and the agentic benchmarks do not include image-based prompt-injection attempts on the agent’s tool-calling path. Voice-channel social engineering, image-embedded instruction injection, and audio-spliced jailbreaks are documented attacks against multimodal agents through 2025-2026.
Future AGI Protect runs 5 safety rules (Toxicity, Tone, Sexism, Prompt Injection, Data Privacy) inline at ~67ms p50 text path, with multi-modal coverage via the MLLM evaluators that score image and audio inputs. The PROTECT_FLASH fast-path classifier sits in front for low-latency text guards. Run write-side and read-side, refuse cache poisoning before it lands, and log every refusal as a span attribute for the audit log.
5. Silent config drift on migration
Already covered in detail above. The thinking_level default change is the per-call equivalent of these failure modes — your agent isn’t broken, it’s just thinking less. Add a span attribute that logs the effective thinking_level on every call. If your average thinking_level flips from high to medium on the migration date, your faithfulness scores will drop and you’ll know exactly why.
Cost-per-quality: when does the swap make sense?
We ran a back-of-envelope on three modal workloads against published numbers, no production traffic data yet (the model just landed):
| Workload | Pre-3.5 model | Per-call cost (today) | If swapped to 3.5 Flash | Quality delta expected |
|---|---|---|---|---|
| Customer-support chat (low system-prompt reuse) | GPT-5 mini | $0.012 / call | $0.018 / call | +6 points Intel Index, +27 GDPval Elo |
| Coding-agent (high context + cache hit) | Claude Sonnet 4.6 | $0.028 / call | $0.011 / call (cache-warm) | +3 points Intel Index, +6 Terminal-Bench |
| Multi-hour research agent | GPT-5 (xhigh) | $0.21 / call | $0.16 / call | -18 GDPval Elo, +4x speed |
Three patterns to watch:
- Coding agents with stable system prompts win the most. Cache hit rate compounds the savings; the Terminal-Bench gain is real; latency drops 4x.
- Customer-support workloads pay more for marginal quality. The Elo gain is the real win; the price hit is the real cost. Run the eval against your actual ticket corpus before the swap.
- Long-horizon research agents face a tradeoff. GPT-5.4 xhigh still tops GDPval-AA by 18 Elo. The 4x speed gain plus 23% cost savings only makes sense if your task isn’t latency-bound on judgment quality.
When to switch and when to wait
Switch now if: you’re on Gemini 3 Flash today (the upgrade is pure-positive on intelligence), you’re running coding agents with stable system prompts (cache hits + Terminal-Bench gain), or you have an instrumentation stack that scores every span.
Wait if: you’re not running guardrails on input or output (the 61% hallucination rate will burn you in production), you don’t have a regression-test harness against your actual workload, or your agents depend on a tool schema that hasn’t been tested with Gemini 3.5’s MCP tool-call ergonomics. Wait two weeks, watch the early-adopter postmortems on r/LocalLLaMA and the Anthropic forum, then run your own A/B.
Skip if: you’re a research workload that needs absolute top-of-leaderboard reasoning, and GPT-5.4 xhigh is already in your budget. The 18 Elo gap on GDPval-AA is real.
The instrumentation snippet: what we’d add today
If your code currently calls Gemini through the official SDK, the minimum instrumentation we’d ship into production looks like this:
import google.generativeai as genai
from traceai_gemini import GoogleGenAIInstrumentor
from fi.evals import Evaluator, evaluate
from fi_instrumentation import register
# 1. Auto-instrument every Gemini call as an OpenInference span
tracer_provider = register(project_name="agent-gemini-3-5-flash")
GoogleGenAIInstrumentor().instrument(tracer_provider=tracer_provider)
# 2. Call the new model
model = genai.GenerativeModel("gemini-3.5-flash")
response = model.generate_content(
prompt,
generation_config={"max_output_tokens": 4096},
)
# 3. Score every response inline with a faithfulness evaluator
faith = evaluate(
"faithfulness",
output=response.text,
context=retrieved_context,
)
if not faith.passed:
# refuse-on-low-confidence
raise GuardrailRefusal(reason="below faithfulness threshold")
# 4. Spans automatically include eval score, model name, and trace IDsThat’s it. Four steps to get every Gemini 3.5 Flash call traced, scored, and gated against a faithfulness threshold before the response leaves your service. The same pattern extends to Groundedness, ContextAdherence, ToolCallCorrectness, and any of the 60+ built-in evaluators in ai-evaluation.
The take
Gemini 3.5 Flash is a real step forward on the model layer. The Intelligence Index 55 number is honest — it’s above Claude Sonnet 4.6 at 52 on a benchmark that doesn’t favor any vendor — and the 4x speed plus 50% price discount versus Sonnet makes it the default Flash-tier choice for production agents starting today.
The slide-deck framing — “agents, not chatbots” — also tracks. The agent benchmarks Google chose to lead with (GDPval-AA Elo, MCP Atlas, Terminal-Bench 2.1) are the right benchmarks to lead with in 2026. The Flash tier now genuinely competes with last-generation Pro on agent workloads.
But: the hallucination rate is still 61%. The multimodal input surface widens the attack surface for prompt injection. The multi-hour endurance demos are demos, not your workload. And the price increase makes one-shot Q&A workloads more expensive than they were yesterday.
The right move for a team running production agents today is not “should I swap?” The right move is “what does my evaluator + observability + guardrails stack look like when I do swap?” If the answer is “I don’t have one,” ship that first. Then swap.
Related reading
- Generative AI Trends 2026 — the eight shifts reshaping what teams build, buy, and replace in 2026
- What Is LLM Observability? — the eval-joined-to-spans pattern this post relies on
- What Is Prompt Injection Defense? — multi-modal attack surface and the Protect model family
Sources
- Gemini 3.5 Flash — Google DeepMind model card
- Google Launches Gemini 3.5 at I/O 2026 — Glitchwire
- With Gemini 3.5 Flash, Google bets its next AI wave on agents, not chatbots — TechCrunch
- Gemini 3.5 Flash: Everything you need to know — Artificial Analysis
- Gemini 3.5 Flash: Benchmarks, Pricing, and Complete Specs — llm-stats
- Gemini 3.5 Flash Hands-On Review — Analytics Vidhya
- Gemini 3.5 Flash Review: Benchmarks, Price & API — Build Fast With AI
- Gemini 3.5 Flash is generally available for GitHub Copilot — GitHub Changelog
- Google Introduces Gemini 3.5 Flash at I/O 2026 — MarkTechPost
Frequently asked questions
What is Gemini 3.5 Flash?
How does Gemini 3.5 Flash compare to Gemini 3.1 Pro?
How does Gemini 3.5 Flash compare to Claude Sonnet 4.6 and GPT-5?
What context window and modalities does Gemini 3.5 Flash support?
Should I switch my agents to Gemini 3.5 Flash today?
What pricing changed with Gemini 3.5 Flash?
Where does Gemini 3.5 Flash fall short compared to Gemini 3.1 Pro?
What is the thinking_level migration trap?

RAG architecture 2026: agentic RAG, multi-hop, query rewriting, hybrid search, reranking, graph RAG. Real code, Context Adherence and Groundedness eval.


Introducing ai-evaluation, Future AGI's Apache 2.0 Python and TypeScript library for LLM evaluation. 50+ metrics, AutoEval, streaming, multimodal.


Build a self-improving AI agent pipeline in 2026: synthetic users, function-call accuracy, ProTeGi rewrites. 62 to 96 percent on a refund agent.
