Best Voice AI Models in April 2026: STT, TTS, and Voice Agent Stack
Best Voice AI April 2026: compare OpenAI Realtime API, Deepgram, Cartesia, ElevenLabs, Vapi, and Retell for STT, TTS, latency, and voice agents.

Table of Contents
April 2026 was the month voice AI hit production maturity. The OpenAI Realtime API plus
gpt-realtime-1.5shipped on April 23, opening up a new architecture (speech directly to LLM, no STT step). The rest of the stack (Cartesia, Deepgram, ElevenLabs, Vapi, Retell) settled into clear category leaders. Hitting sub-700ms end-to-end on a managed platform is now an engineering pick, not a research problem.
Where we are now (May 2026): see Best Voice AI of May 2026 for the current snapshot. The April story below is preserved as the month-in-review.
TL;DR: Best voice AI per layer, April 2026
| Layer | Best pick | Why | Pricing |
|---|---|---|---|
| Streaming STT | Deepgram Nova-3 | 6.84% WER, sub-300ms streaming | $0.0077/min |
| STT with intelligence | AssemblyAI Universal-2 | Streaming + summarization, entity, sentiment | ~$0.0062/min batch, ~$0.0078/min streaming |
| Broadest language coverage | Google Cloud Chirp | 125+ languages, 11.6% WER on Chirp benchmark | varies |
| Open-source STT | Whisper Large V3 | 7.4% WER avg, 99+ languages | self-host |
| Turn-taking detection | Deepgram Flux | Purpose-built end-of-turn | bundled |
| TTS for low-latency agents | Cartesia Sonic Turbo | 40ms TTFA | premium |
| TTS quality and cloning | ElevenLabs v3 Multilingual | 32+ languages, voice cloning | premium |
| Native audio endpoint (NEW) | OpenAI Realtime API + gpt-realtime-1.5 (April 23) | Speech-to-speech, no STT step | $32/$64 per M audio tokens |
| Voice agent platform default | Retell AI | ~600-780ms E2E, $0.07/min, HIPAA | $0.07/min |
| Voice agent at scale | Vapi | 300M+ cumulative calls, 99.9% uptime | varies |
If you only read one row: OpenAI’s Realtime API + gpt-realtime-1.5 (April 23) opens a second architecture for voice agents: speech-to-speech, no STT step. The classic STT-LLM-TTS stack (Deepgram + GPT-5.5 + Cartesia, orchestrated by Retell or Vapi) remains the default for long-form reliability. Pick the Realtime API if prosody preservation matters more than per-minute price (audio bills 6-12x text rates).
The story of voice AI in April 2026
April 2026 had two stories, one big and one quiet.
The big story: OpenAI shipped the Realtime API with gpt-realtime-1.5 on April 23. The Realtime API accepts speech as direct input, not via a separate STT step. The result: prosody, emotion, accent context, and background-noise tolerance that the STT-then-LLM pipeline discards. Press coverage often called this “GPT-5.5 native audio,” but per OpenAI’s official model and pricing pages the audio path is gpt-realtime-1.5, not GPT-5.5 itself (which remains a text and image input model). This is a different architecture, not just a new model. For applications where audio context is the signal (mental health, accessibility, accent-sensitive products), the Realtime API path is a meaningful upgrade. For applications where transcript accuracy on long conversations is the bottleneck, the classic STT-LLM-TTS pipeline remains stronger.
The quiet story: The classic voice-agent stack matured. Deepgram Nova-3 plus Flux is the production default for streaming STT with end-of-turn detection. Cartesia Sonic Turbo at 40ms TTFA makes sub-300ms end-to-end agents reachable. ElevenLabs v3 leads voice quality and cloning. Vapi handles high call volume at 99.9% uptime (99.99% on enterprise). Retell AI sits at 620ms measured end-to-end with HIPAA included. The components compose. Custom voice-agent stacks no longer need 3-6 months of engineering to reach platform quality.
Best speech-to-text models in April 2026
Deepgram Nova-3. The streaming STT default
The production default for streaming STT in April 2026. Deepgram’s Nova-3 announcement reports 6.84% median streaming WER across 81 hours of audio in 9 domains, with batch dropping that to 5.26% (a 1.58-point gap, the smallest among major providers offering both modes).
Specs: 6.84% streaming WER (vendor); ~18.3% on the independent Artificial Analysis AA-WER index; sub-300ms streaming latency; 30+ streaming languages; $0.0077/min streaming, $0.0043/min batch.
Production reality. Customer logos publicly disclosed include NASA (ISS-to-Mission-Control transcription), Spotify, Twilio, Citi. Vapi runs on Deepgram for STT. Production complaints cluster around WER spikes when users speak over background music and modest accuracy degradation on heavy-accent audio without keyterm prompting.
Best for: Production voice agents where end-to-end latency is binding. Real-time captioning. Live conversational AI.
Skip if: You need batch accuracy across rare languages (use Google Cloud Chirp). You need bundled speech intelligence (use AssemblyAI Universal-2).
AssemblyAI Universal-2. Best for streaming STT with bundled intelligence
Universal-2’s pitch is the bundled intelligence layer: summarization, entity detection, sentiment, and PII redaction ship in the same API call without per-feature surcharges. AssemblyAI’s Universal-2 research blog reports 14.5% WER on its mixed-content benchmark (CommonVoice + Fleurs + VoxPopuli + 60 hours in-house call-center, podcast, broadcast, and webinar audio).
Specs: 14.5% WER on AssemblyAI’s challenging benchmark; 5.65-6.7% on cleaner segments via Artificial Analysis; 300-600ms streaming latency (consistently slower than Deepgram in third-party tests); $0.37/hr batch async, $0.47/hr streaming on standard plans; 99+ languages.
Production reality. Customer logos: WSJ, NBC Universal, Spotify advertising, CallRail (+23% accuracy lift after Universal-2 upgrade), Veed, Descript, Podchaser. Streaming Universal-Streaming is meaningfully higher latency than Deepgram in independent tests; the value is the depth on every transcript feature, not the latency floor.
Best for: Voice agents where post-call analytics or entity extraction is part of the product. Customer support call intelligence. Compliance-heavy verticals needing inline PII redaction.
Skip if: Pure transcript accuracy is the goal (Deepgram is faster). End-to-end latency under 500ms is binding.
Whisper Large V3. Best open-source self-hosted STT
OpenAI’s open-weight Whisper Large V3 is the self-hosted default for privacy-sensitive workloads. The model card reports a sequential long-form algorithm beating chunked decoding by ~0.5pp WER on batch.
Specs: 7.4% WER average across mixed benchmarks; 1.55B parameters; 99+ languages; 10GB VRAM minimum; no built-in diarization; no native streaming.
Production failure modes worth knowing. Whisper has well-documented hallucination patterns: it hallucinates “Subscribe to my channel” on silence (YouTube training-data bleed), can enter 20-minute repetition loops on long audio, and bias is multiplied 5-6x for non-English languages. Deepgram’s audit reports v3 hallucinates 4x more often than v2 on hour-long audio.
Pricing. OpenAI hosts Whisper at $0.006/min, but most teams self-host on Together / Replicate / Fal.ai / their own GPUs. Self-hosted breaks even vs Deepgram around 200K minutes/month given GPU rental costs.
Best for: Self-hosted deployments above 500K minutes per month. Privacy-sensitive workloads where audio cannot leave your infrastructure. Edge inference.
Skip if: You need streaming under 300ms (Whisper has none). You serve hour-long audio (the repetition-loop failure mode is real). You need production support and SLA.
Deepgram Flux. Best for end-of-turn detection
The model-integrated end-of-turn detection layer that turns generic STT into voice-agent-ready STT. Generic STT APIs do not signal when the user has actually finished speaking, which is the difference between a voice agent that talks over the user and one that does not. Flux detects end-of-turn in under 400ms and pairs natively with Nova-3. Multilingual GA shipped April 29, 2026 across 10 languages with mid-call switching.
Partner integrations: Vapi, LiveKit Agents, Pipecat, Cloudflare Workers AI, Jambonz.
Best for: Any production voice agent. Worth more than 1-2 points of WER accuracy in user-experience terms.
Skip if: Your product is transcription-only (no agent turn-taking). You self-host STT (Flux is Deepgram-only).
Best text-to-speech models in April 2026
Cartesia Sonic Turbo. The TTS latency leader at 40ms TTFA
The latency leader. 40ms TTFA is what makes sub-300ms end-to-end voice agents reachable.
Specs: 40ms TTFA on Turbo, 90ms on standard Sonic 3; 15+ languages; 5-second voice cloning sample; streaming output.
Production reality. The 40ms TTFA claim is the structural unlock for sub-300ms voice agents, but worth a caveat: the only public load test of Sonic Turbo’s 40ms claim under traffic comes from Together AI co-marketing material, not an independent third-party benchmark. Run your own load test if you intend to depend on the 40ms floor at concurrency. Cartesia also publishes a hosted runtime (Cartesia Line) optimized to keep Sonic Turbo on the hot path.
Best for: Sub-500ms round-trip turn-latency voice agents. Real-time interactive applications. Telephony where dropped frames or jitter are unacceptable.
Skip if: Voice quality and cloning fidelity matter more than latency (use ElevenLabs v3). You’re locked into the ElevenLabs ecosystem for branded voices.
ElevenLabs v3 Multilingual. Best for voice quality and cloning
The voice-quality and cloning leader. ElevenLabs v3 is built for expressiveness, character voices, and audiobook-style read-aloud, not real-time voice agents. For real-time, use Flash v2.5.
Specs: 32+ languages; best-in-category voice cloning; strong multi-language emotion. v3 is not real-time-optimized; ElevenLabs explicitly notes v3 should be paired with a different model for low-latency agents. For sub-100ms latency use Flash v2.5 at ~75ms model inference.
Pricing reality. ElevenLabs ships character-based pricing with well-documented gotchas: 2x credit charge on premium voices, failed generations consume credits, generations under 5 characters bill at 5-character minimum. Production budgets typically run 1.4-1.7x list price after retries and edge cases.
Best for: Creator content, audiobook generation, branded voice products, character voice consistency, high-quality multi-language consumer voice.
Skip if: Sub-100ms TTFA is required (use Cartesia or Flash v2.5). Predictable per-minute pricing matters (use Cartesia or Sonic).
OpenAI gpt-4o-mini-tts and gpt-realtime. Best for LLM-controlled instructable voice
OpenAI ships two distinct voice paths in April 2026 that are easy to confuse. gpt-4o-mini-tts is the instructable-voice TTS: text in, audio out, with natural-language voice character control (“speak with calm authority”, “sound urgent”). gpt-realtime / gpt-realtime-1.5 is the speech-to-speech native-audio endpoint accessed via the Realtime API.
Specs. gpt-4o-mini-tts: ~200ms TTFA; 50+ languages; natural-language voice character control. gpt-realtime-1.5: covered in the Native Audio section below; $32/M input, $64/M output.
Production verdict. Public benchmarks on gpt-realtime show task completion drops from ~0.70 (clean text both sides) to ~0.50 (raw audio both sides) on free-form long conversations because ASR drift compounds across turns. For long-form voice agents, the pipeline (Deepgram + GPT-5.5 + ElevenLabs Flash) is often more reliable despite the higher latency floor. For short structured turns under 30 seconds where prosody matters, gpt-realtime wins.
Best for: Voice agents where the LLM should control voice character based on conversation context. OpenAI ecosystem teams who want one vendor across LLM and audio. Short structured prosody-sensitive turns (mental-health, accessibility).
Skip if: Sub-100ms latency is required (use Cartesia + a fast LLM). Free-form long conversations are the workload (ASR drift compounds; classic pipeline is more bounded).
Native audio architectures (the structural shift in April)
OpenAI Realtime API + gpt-realtime-1.5. First production-grade speech-to-speech endpoint
Worth flagging the naming. OpenAI’s official model and pricing pages document the audio path as the Realtime API powered by gpt-realtime-1.5, not as “GPT-5.5 native audio.” GPT-5.5 itself is listed as a text/image-input → text-output model. Press coverage in April collapsed both into “GPT-5.5 native audio,” which conflates two separate endpoints.

Architecture difference from STT-LLM-TTS:
- STT pipeline: speech → text → LLM → text → TTS (loses prosody, emotion, accent on the speech-to-text hop; reintroduces it on the TTS hop)
- Realtime API: speech → speech directly through one model (preserves audio context end-to-end, no transcript intermediate)
Pricing. gpt-realtime-1.5 audio is $32/M input and $64/M output per OpenAI’s pricing page. That is roughly 6x the text-only GPT-5.5 rate ($5/$30) on input and ~2x on output. Audio token-counting also differs from text token-counting; budget accordingly.
Production verdict. Public benchmarks on gpt-realtime show task completion drops from ~0.70 (clean text both sides) to ~0.50 (raw audio both sides) when free-form long conversations are involved. ASR drift compounds across turns. For free-form long conversations, the classic Cartesia + Nova-3 + fast-LLM pipeline is often more reliable despite the higher latency floor.
Best for: Mental-health support, accessibility products, accent-sensitive flows, applications where prosody is the signal (sarcasm, hesitation, emphasis). Short structured turns under 30 seconds.
Skip if: Transcript accuracy on long conversations is what matters (use Deepgram + LLM). You need predictable per-turn latency at scale (the classic pipeline is more bounded). Cost matters at volume (audio rates are ~6-12x text rates).
STT comparison at a glance
| Provider | Streaming WER (vendor) | AA-WER (independent) | Streaming latency | $/min |
|---|---|---|---|---|
| Deepgram Nova-3 | 6.84% | ~18.3% | sub-300ms | $0.0077 streaming / $0.0043 batch |
| AssemblyAI Universal-2 | 14.5% | 5.65-6.7% (cleaner) | 300-600ms | $0.47/hr |
| Google Cloud Chirp 3 | 4-7% (clean studio) | 10-15% | 300-600ms | $0.016/min |
| Whisper Large V3 | n/a (batch only) | 5-8% (clean) | n/a | $0.006/min hosted |
| ElevenLabs Scribe v2 Realtime | 6.5% (vendor FLEURS) | not yet ranked | 150ms | bundled credits |
The vendor-vs-AA-WER gap is the key trust signal. Vendors publish numbers on benchmarks they may have trained on; Artificial Analysis runs an independent suite on AgentTalk, VoxPopuli-Cleaned, and Earnings22-Cleaned. Run a domain reproduction before committing.
Best voice agent platforms in April 2026
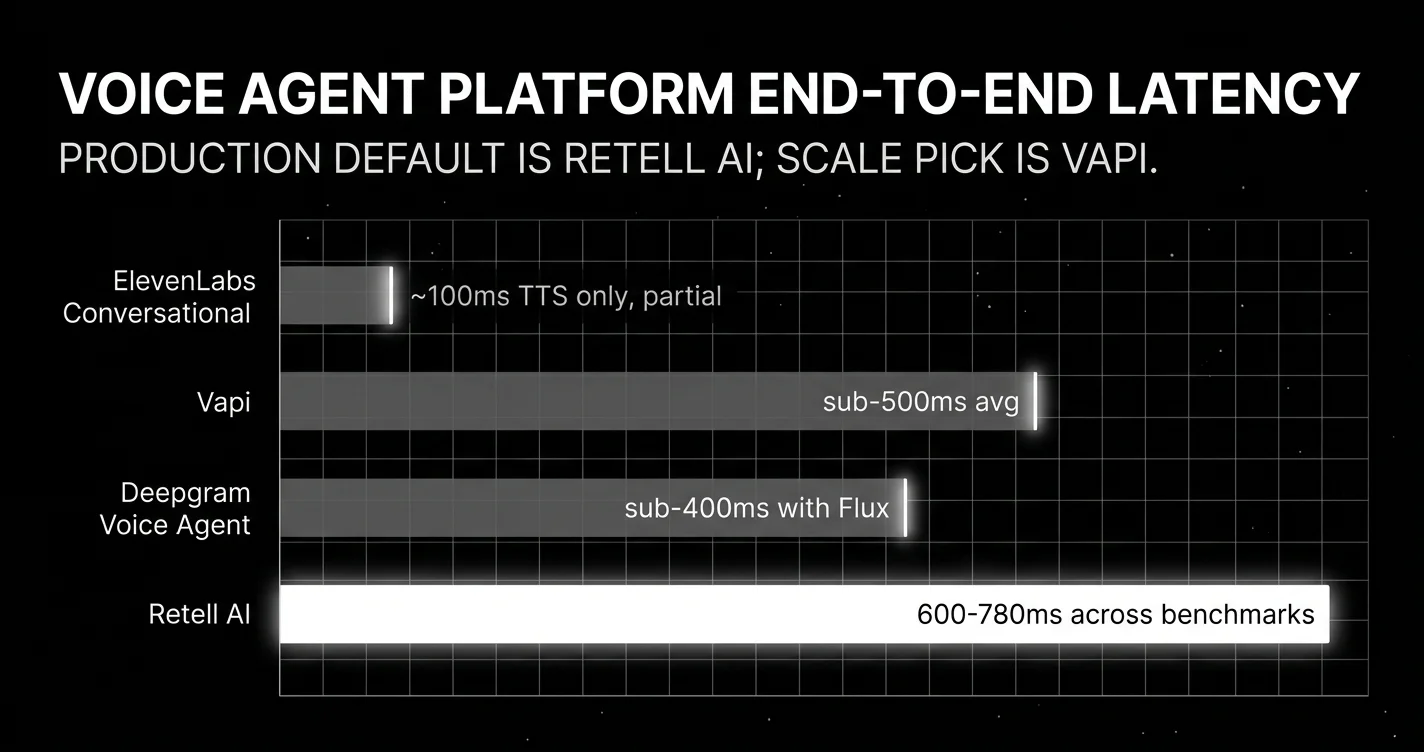
Retell AI. Most-teams default
About 620ms measured end-to-end. $0.07/min. HIPAA included. No platform fee. Both no-code builder and developer SDK.
Best for: Most production voice agents where sub-700ms is acceptable, HIPAA matters, managed platform reduces engineering load.
Skip if: Sub-500ms required (use Vapi or roll your own). Self-hosted required (use Deepgram Voice Agent).
Vapi. The scale pick
300M+ cumulative calls, 99.9% uptime (99.99% enterprise), sub-500ms average latency, multi-channel (voice + SMS + chat).
Best for: Production voice agents at millions-of-calls-per-month scale.
Skip if: You are below 100K calls/month (Retell is more cost-effective).
Deepgram Voice Agent. Best self-hosted voice agent stack
Bundled stack with self-hosted option. Sub-400ms with Flux.
Best for: Self-hosted compliance, bundled pricing without LLM pass-through surprises.
Skip if: You want managed-service simplicity.
ElevenLabs Conversational. Best voice-quality-first agent platform
Voice-quality-first agent platform. Defaults to ElevenLabs voices; teams targeting low-latency turn-taking should pair the platform with Flash v2.5 rather than v3 (v3 is not real-time-optimised).
Best for: Voice products where the voice is the brand, character voice agents, premium consumer products.
Skip if: Latency is binding (use Cartesia + Vapi/Retell).
Bland AI. Best for outbound phone agents at scale
Outbound phone volume. Norm agent builder. Tiered per-minute pricing per bland.ai/pricing: Start tier is 10 concurrent / 100 calls/day, Build is 50 / 2,000, Scale is 100 / 5,000, Enterprise is unlimited. HIPAA is included on Build and above (no separate add-on).
Best for: Outbound phone agents, sales operations, structured outbound calls.
Open-source agent platform alternatives
If you do not want a managed agent runtime, four OSS frameworks compose STT-LLM-TTS yourself with realistic production latency:
- Pipecat (Daily). End-to-end latency 800-950ms across community reports. Strong adapter ecosystem.
- LiveKit Agents. ~750-900ms E2E. The same LiveKit voice infrastructure the Future AGI
fi.simulateSDK uses for voice persona testing. - Daily Bots. Hosted Pipecat runtime. Per-minute compute + provider passthrough.
- Cartesia Line. Cartesia’s runtime, optimized for Sonic Turbo’s 40ms TTFA on the hot path.
HIPAA tier matrix
The clearest pricing differentiator across managed platforms. Production teams in regulated verticals hit a $1,000/mo wall on Vapi or ElevenLabs that Retell or Bland include on standard plans:
| Platform | HIPAA included? | Where it costs more |
|---|---|---|
| Retell AI | Yes, standard plan, self-serve BAA | No upcharge |
| Bland AI | Yes, on Build/Scale | Plan-tier upgrade |
| Deepgram Voice Agent | Enterprise contract only | Sales-led BAA |
| Vapi | $1,000/mo add-on | Largest gotcha in the category |
| ElevenLabs Conversational | Enterprise + Zero Retention Mode | Reportedly $1,000/mo + Enterprise contract |
End-to-end latency budget in April 2026
| Component | Sub-300ms pick | Sub-700ms pick |
|---|---|---|
| STT | Deepgram Nova-3 (sub-300ms) | Deepgram Nova-3 |
| LLM | GPT-5 mini or Gemini 3.1 Flash | GPT-5.5, Claude Opus 4.7, etc. |
| TTS | Cartesia Sonic Turbo (40ms TTFA) | ElevenLabs Flash v2.5 (~75ms inference) |
| Orchestration | Tight platform-native | Standard platform |
| Total | ~400-600ms achievable with overlap | ~700ms achievable |
The 40ms Cartesia Sonic Turbo TTFA is what makes low-hundreds-of-milliseconds end-to-end latency reachable; without it, the rest of the stack does not have enough budget left.
Cost at scale: what 100K minutes/month actually costs
Per-minute list price hides 5-10x cost variance once you account for LLM passthrough, character-pricing markups for TTS, retry rate, and HIPAA add-ons. April 2026 specifically introduces a new cost vector with the Realtime API: gpt-realtime-1.5 audio bills at $32/M input, $64/M output, which is 6-12x text rates.
| Stack | Component pricing | Estimated monthly cost (100K min) |
|---|---|---|
| Retell managed | $0.07/min flat | $7,000 |
| Vapi BYO + Deepgram + GPT-5.5 + ElevenLabs Flash | $0.05/min platform + $0.0043/min STT + ~$0.02/min text LLM + ~$0.04/min TTS (1.5x retry buffer) | $11,500-14,000 |
| OpenAI Realtime API alone | gpt-realtime-1.5 audio at $32/$64 per M tokens, ~3K tokens per min | ~$15,000-25,000 audio-only |
| Bland AI Build tier | Tier-bundled | $6,000-9,000 |
| Self-hosted (Whisper + Claude API + Cartesia + Pipecat) | GPU rental ~$0.001/min + Claude ~$0.025/min + Cartesia ~$0.03/min | $6,000-7,500 + on-call cost |
The honest framing: under 100K min/month, Retell’s flat $0.07/min usually wins on total cost of ownership. Above 1M min/month, BYO economics flip. The Realtime API + gpt-realtime-1.5 is the highest-cost path on this list. Use it when prosody matters more than per-minute price (mental health, accessibility), not as a default.
ElevenLabs character-pricing reality has well-documented gotchas: 2x credit charge on premium voices, failed generations consume credits, generations under 5 chars bill at 5-char minimum. Production budgets typically run 1.4-1.7x list. Build the buffer in.
Decision framework
Choose Retell AI for managed default. Sub-700ms, HIPAA, $0.07/min.
Choose Vapi for scale. Millions of calls per month, multi-channel, 99.9% uptime (99.99% on enterprise).
Choose Deepgram Voice Agent for self-hosted. Bundled pricing, Flux turn-taking.
Choose ElevenLabs Conversational for voice-quality-first products.
Choose the OpenAI Realtime API + gpt-realtime-1.5 for prosody-sensitive applications. Mental health, accessibility, emotion-aware agents. Audio rates ($32/$64 per M tokens) are 6-12x text rates, so reserve for short turns where prosody is the signal.
Roll your own (Cartesia + Deepgram + LLM) for sub-300ms targets.
Common mistakes
- Picking TTS by quality and ignoring latency. Sub-300ms requires Cartesia.
- Skipping turn-taking detection. Generic STT does not handle end-of-turn. Worth more than WER.
- Ignoring the LLM as a latency cost. A 300ms STT plus 1500ms LLM is not a 300ms agent.
- Using STT-then-LLM when audio context is the signal. April 2026 introduced native audio via the OpenAI Realtime API plus
gpt-realtime-1.5; pick it when prosody matters. - Building from scratch without reality. Custom voice stacks take 3-6 months to reach platform quality.
How Future AGI fits
Future AGI provides reliability infrastructure for voice agents. Simulation generates voice scenarios (accents, background noise, interruptions). Eval models score voice outputs across groundedness, hallucination, accent handling, and tool-call accuracy. Guardrails sit at the gateway and block bad outputs before they reach the user. traceAI is Apache 2.0 (LICENSE) and the ai-evaluation SDK is Apache 2.0 (LICENSE), so the evaluation and observability layers self-host cleanly alongside any voice stack you pick from the platforms above.
Sources
STT primary
- Deepgram Nova-3 announcement (6.84% median streaming WER)
- Deepgram Flux conversational STT
- AssemblyAI Universal-2 research blog (14.5% WER claim, methodology)
- Whisper Large V3 model card
TTS primary
- Cartesia Sonic Turbo 40ms TTFA (docs)
- ElevenLabs Flash v2.5 latency (~75ms model inference)
- OpenAI Realtime API + gpt-realtime-1.5 pricing ($32/$64 per M tokens)
- Introducing GPT-5.5 (April 23, 2026)
Voice agent platforms
- Vapi (300M+ cumulative calls, 99.9% uptime)
- Retell AI Latency Face-off 2025 (TTFT 180ms, E2E 620ms)
- Bland AI pricing tiers
- Deepgram Voice Agent pricing ($0.075/min)
- ElevenLabs Conversational AI HIPAA requirements
Independent + standards
- Artificial Analysis AA-WER index (real-world benchmarks)
- ITU-T Recommendation G.114 (one-way transmission time)
Open-source agent frameworks
See also: Best LLMs of April 2026 for the LLM brain in your voice agent. Next voice post: Best Voice AI of May 2026. Previous: Best Voice AI of March 2026.
Frequently asked questions
What changed in voice AI during April 2026?
What is the best speech-to-text model in April 2026?
What is the best text-to-speech model for voice agents in April 2026?
Should I use the OpenAI Realtime API instead of STT plus LLM in April 2026?
What is the best voice agent platform in April 2026?

Best Voice AI May 2026: compare Deepgram, Cartesia, ElevenLabs, Retell, and Vapi for STT, TTS, latency budgets, and production voice agents.


Best Voice AI March 2026: Deepgram, Cartesia, ElevenLabs, Vapi, Retell across STT, TTS, latency, and voice agents.

Best LLMs May 2026: compare GPT-5.5, Claude Opus 4.7, Gemini 3.1 Pro, and DeepSeek V4 across coding, agents, multimodal, cost, and open weights.