Best Rerankers for RAG in 2026: 7 Models Compared
Cohere Rerank 4, BGE Reranker v2-m3, Jina v2, ColBERT, Voyage rerank-2.5, mixedbread mxbai, and Qwen3 reranker compared on RAG-eval lift, latency, license, and multilingual support.

Table of Contents
A reranker is the second pass in a RAG pipeline. The bi-encoder embedding does the bulk retrieval across the whole corpus to top-50 or top-100; the reranker re-sorts the survivors with a cross-encoder that scores query and document jointly. The common pattern in production RAG pipelines is bi-encoder retrieval to top-50 or top-100 followed by reranking, but the decision should be gated by corpus-specific eval lift and latency budget. The seven models below cover managed APIs and self-host weights, English-only and multilingual, classical cross-encoders and token-level late interaction. The dimensions that matter for selection are RAG-eval lift measured on your own corpus, end-to-end latency at top-50, license terms, and the language pairs in your data.
TL;DR: Best reranker per use case
| Use case | Best pick | Why (one phrase) | Pricing | License |
|---|---|---|---|---|
| Managed API with broad language coverage | Cohere Rerank 4 (Pro / Fast) | Documented multilingual coverage across many languages | Cohere pricing | Closed |
| Self-host with an OSI-open license | BGE Reranker v2-m3 | Multilingual cross-encoder on MIRACL/MTEB | Free | Apache 2.0 (BAAI) |
| Fast multilingual + function calling | Jina Reranker v2 base multilingual | Designed for function-calling and code | Jina pricing | CC-BY-NC-4.0 weights; commercial via API |
| Token-level late interaction | ColBERTv2 | Token-level relevance | Free | MIT (Stanford) |
| Managed API for enterprise search | Voyage rerank-2.5 | Current Voyage rerank flagship | Voyage pricing | Closed |
| Apache 2.0 cross-encoder with hosted option | mixedbread mxbai-rerank-large-v2 | Apache 2.0 plus mixedbread API | Free self-host; API metered | Apache 2.0 |
| Open-license multilingual reranker | Qwen3 Reranker | Multilingual Apache 2.0 family with multiple sizes | Free | Apache 2.0 |
If you only read one row: pick Cohere Rerank 4 for the lowest-friction managed path, BGE Reranker v2-m3 for an open-license self-host, and ColBERTv2 when token-level interaction matters more than the cross-encoder ceiling. Note that Jina Reranker v2 base multilingual weights are CC-BY-NC-4.0; commercial production use requires the Jina hosted API or a commercial arrangement.
How we evaluated this shortlist
These seven rerankers were picked against five axes that map to real RAG decisions:
- Accuracy on RAG eval sets: nDCG@10, MRR@10, and Recall@10 lift on standard benchmarks (BEIR, MTEB, MIRACL) and on production reproductions you run yourself.
- Latency at top-50: P50 and P95 reranking time for 50 candidate documents, measured on your hardware and document length.
- License and self-hosting: OSI license string on the model card, commercial-use status, and whether the weights are downloadable.
- Language coverage: published languages on the model card, performance on cross-lingual benchmarks, special-domain coverage (code, function-calling).
- Operational cost: API price per million tokens or per thousand searches; GPU memory footprint for self-hosting.
Tools shortlisted but ultimately not in the top 7: Sentence-Transformers cross-encoder/ms-marco family (still a useful baseline with older lineage), Stella reranker (smaller community, narrower benchmarks), and RankGPT-style LLM-as-reranker prompting (works but is materially more expensive in inference cost than dedicated rerankers and the latency budget rarely tolerates it for production RAG; verify on your own workload).

The 7 rerankers compared
1. Cohere Rerank 4: Best for managed accuracy with broad language coverage
Closed model. Hosted API. Cloud-partner availability varies by model version.
Use case: Production RAG pipelines that need managed accuracy without operating a GPU. Cohere lists Rerank 4 Fast and Rerank 4 Pro on its pricing page alongside the older Rerank 3 generation. The API takes a query and up to 1,000 documents per search.
Pricing: Cohere prices rerank by searches in the API path and exposes Model Vault hourly/monthly instance pricing alongside it; refer to Cohere pricing and the Cohere Rerank docs for the current per-search and instance rates.
License: Closed. Rerank 4 Pro and Rerank 4 Fast are documented on Cohere’s API and on Azure AI Foundry. AWS Bedrock currently lists Cohere Rerank 3.5 in its supported reranker table, so verify Rerank 4 availability on AWS Bedrock and SageMaker directly before citing it for procurement.
Best for: Teams running a multilingual RAG corpus where the procurement priority is “the reranker is managed” and the latency budget tolerates a network round-trip. Rerank 4 Fast targets latency-sensitive use cases; Rerank 4 Pro targets accuracy-priority use cases.
Worth flagging: Closed weights; on-prem requires a managed-service contract through one of the cloud partners. Network latency is added on top of model inference; measure on your region.
2. BGE Reranker v2-m3: Best for open-license self-hosted RAG
Apache 2.0. Self-hostable. Hosted on HuggingFace inference endpoints.
Use case: Self-hosted RAG with multilingual content where the team owns the GPU and needs an OSI-open license. BGE Reranker v2-m3 is the multilingual cross-encoder from BAAI, distilled from BGE-M3 and trained on a curated multilingual relevance corpus.
Pricing: Free for the model weights. Self-hosting throughput depends on hardware, batch size, and document length; benchmark on your workload.
License: Apache 2.0. 568M parameters; the smaller bge-reranker-base (278M) and the larger bge-reranker-v2-gemma (2.5B) are also published on HuggingFace; verify each variant’s license string on its model card before redistribution.
Best for: Teams that already operate ML infrastructure and want a strong open-license reranker without an API bill. BGE v2-m3 ranks competitively on MIRACL multilingual retrieval and on the MTEB rerankers leaderboard; verify against your own corpus before committing.
Worth flagging: GPU operations are on the team. Quantization (8-bit, 4-bit) can drop accuracy; verify on your eval set. Cross-lingual queries (English query, Chinese document) need explicit testing; performance varies by language pair.
3. Jina Reranker v2 base multilingual: Best for fast multilingual + function-calling (with license caveat)
CC-BY-NC-4.0 weights. Commercial use requires the Jina API.
Use case: Latency-sensitive multilingual RAG and code search. Jina Reranker v2 base multilingual is optimized for function-calling and code retrieval; Jina’s release notes describe substantial throughput gains over the v1 generation.
Pricing: Refer to Jina pricing for current per-token rates on the cloud API.
License: The model card for jinaai/jina-reranker-v2-base-multilingual lists cc-by-nc-4.0. Commercial production use requires the Jina hosted API or a commercial arrangement, not direct deployment of the weights.
Best for: Teams with mixed code + natural language corpora and function-calling pipelines that can use the Jina API for commercial deployment, or research/non-commercial workloads that fit the CC-BY-NC-4.0 terms.
Worth flagging: The CC-BY-NC-4.0 license is the most common confusion in this category; do not deploy these weights in a paid product without the API or a commercial contract. Verify any sibling variant’s license string on its own model card.
4. ColBERTv2: Best for token-level late interaction
MIT. Self-hostable.
Use case: RAG pipelines where token-level relevance matters more than the cross-encoder ceiling. ColBERTv2 uses late interaction: it stores per-token embeddings for each document, then computes maxsim across token pairs at query time. The model never sees query and document together at inference; the late interaction step does.
Pricing: Free. Self-hosting needs a vector index sized for per-token embeddings, which is roughly 30 to 100x the size of a standard sentence embedding index. PLAID indexing in ColBERTv2 cuts that to a tractable working set.
OSS status: MIT (Stanford). The RAGatouille library makes ColBERTv2 easy to use as a reranker in LangChain and LlamaIndex pipelines.
Best for: Long-document corpora where token-level relevance signals matter (technical docs, legal, scientific). ColBERTv2 is the canonical late-interaction implementation and the foundation that many newer late-interaction models extend.
Worth flagging: Index size and operations cost are higher than a standard cross-encoder. ColBERTv2 base is English-only; ColBERT-XM exists for multilingual but is a smaller community. The 2024 ColPali extension targets visual document retrieval and is a separate stack.
5. Voyage rerank-2.5: Best for managed enterprise search
Closed. Hosted API.
Use case: Enterprise RAG where the team already uses Voyage embeddings. Voyage’s pricing page lists rerank-2.5 and rerank-2.5-lite as the current Voyage rerank flagships alongside the older rerank-2.
Pricing: Refer to Voyage pricing for current per-token rates on rerank-2.5 and rerank-2.5-lite.
License: Closed. Available on Voyage API and AWS Marketplace.
Best for: Teams that already standardize on Voyage embeddings. Strong fit for enterprise search where the buyer prefers a single vendor for embed + rerank.
Worth flagging: No self-hosted option. Voyage AI was acquired by MongoDB in February 2025; verify the latest MongoDB and Voyage announcements for product roadmap and bundling with MongoDB Atlas Vector Search before committing. Check the latest model card for the language coverage you need.
6. mixedbread mxbai-rerank-large-v2: Best for Apache 2.0 multilingual + hosted option
Apache 2.0. Self-hostable. Hosted API on mixedbread.com.
Use case: Multilingual RAG with the choice of self-hosting under Apache 2.0 or using mixedbread’s hosted API for low ops. mxbai-rerank-large-v2 is the second-generation reranker family from mixedbread.ai; the model card documents multilingual training data and reranking benchmarks.
Pricing: Free for the weights. Hosted API metered per token; check the mixedbread pricing page for current tiers.
License: Apache 2.0. The model is marketed as ProRank-1.5B; HuggingFace metadata reports roughly 2B params. Smaller variants mxbai-rerank-base-v2 and mxbai-rerank-xsmall-v1 are also published.
Best for: Teams that want a managed API path with a clear migration to self-hosting under Apache 2.0 when scale or compliance demands it. The variant range covers laptop-to-GPU deployments.
Worth flagging: Larger memory footprint than bge-reranker-base for the same accuracy class; right-size the variant. Verify the language matrix on the model card against your top language pairs.
7. Qwen3 Reranker: Best for multilingual Apache 2.0 family
Apache 2.0. Self-hostable.
Use case: Multilingual RAG with strict open-license requirements and a tunable size budget. Qwen3 Reranker is part of the Qwen3 family from Alibaba and ships in 0.6B, 4B, and 8B variants. The model card documents broad multilingual coverage with strong reported Chinese and English benchmarks.
Pricing: Free for self-hosting. Hosted via DashScope or fireworks.ai with separate metering.
License: Apache 2.0. The model card details training data composition.
Best for: Teams with multilingual workloads (especially Chinese-English) and strict on-prem requirements where the weights need to stay inside the data perimeter. The size range supports laptop-to-GPU deployments.
Worth flagging: 8B model has higher inference latency than smaller cross-encoders; benchmark against your latency budget. Verify the model card’s published language list before relying on long-tail languages.
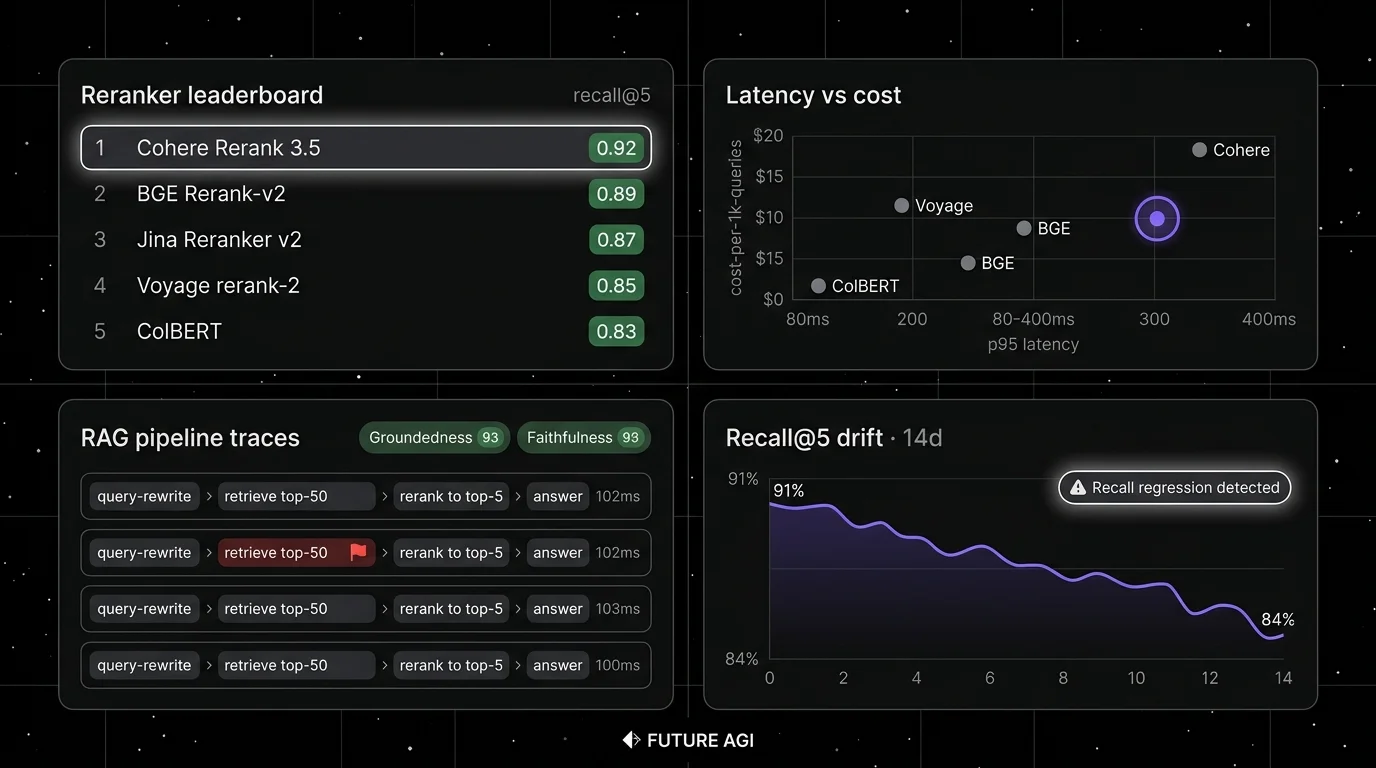
Decision framework: pick by constraint
- Managed API with broad language coverage: Cohere Rerank 4 (Pro for accuracy, Fast for latency).
- Self-host with OSI-open license: BGE Reranker v2-m3 (Apache 2.0).
- Tight latency budget on self-host: ColBERTv2 (late interaction), or smaller BGE variants.
- Token-level relevance on long documents: ColBERTv2.
- Apache 2.0 with managed-API option: mixedbread mxbai-rerank-large-v2 or Qwen3 Reranker.
- Already on Voyage embeddings: Voyage rerank-2.5 for the bundle.
- Multilingual, strict open license, on-prem: Qwen3 Reranker (4B or 8B).
- Code search and function calling, can use Jina API: Jina Reranker v2 base multilingual via the Jina API (CC-BY-NC-4.0 weights are not safe to deploy directly in a paid product).
Common mistakes when picking a reranker
- Picking on a public benchmark only. BEIR, MTEB, and MIRACL are useful starting points, but a real RAG corpus has its own term distribution and intent mix. Build a 100 to 500 query golden set and re-rank on it before committing.
- Ignoring downstream answer quality. A reranker can lift Recall@10 measurably and lift answer-quality eval by less than expected. Track both. The reranker is part of the RAG stack, not the goal.
- Skipping the latency budget. Reranker latency stacks on top of retrieval, generation, and any guardrails. Verify p50 and p95 on your real document length and production hardware, not on the model card benchmark default.
- Choosing an English-only reranker for a multilingual corpus. ColBERTv2 base and most ms-marco cross-encoders are English-trained; running them on Chinese, Japanese, or Arabic queries reduces accuracy. Check the model card’s published language list.
- Treating the license as automatic. Jina Reranker v2 base multilingual is CC-BY-NC-4.0 and is not safe to deploy directly in a paid product. Sibling variants from any vendor can have different license strings. Verify each model card before shipping.
- Forgetting CI eval gates. A reranker swap can lift accuracy and break a long-tail of edge cases. Gate the change behind a CI eval set with deterministic thresholds.
Recent reranker timeline (selected)
| Date | Event | Why it matters |
|---|---|---|
| 2024-2025 | BAAI BGE Reranker v2-m3 model card | Apache 2.0 multilingual cross-encoder. |
| Dec 2024 | Cohere released Rerank 3.5 | Multilingual managed reranker. Now superseded by Rerank 4. |
| 2025-2026 | Cohere Rerank 4 listed on the pricing page | Current Cohere generation: Rerank 4 Fast and Rerank 4 Pro. |
| Feb 2025 | MongoDB acquired Voyage AI | Verify current Atlas Vector Search and Voyage packaging before assuming bundled procurement. |
| 2025 | Voyage rerank-2.5 listed on the pricing page | Current Voyage rerank flagship. |
| Jul 2024 | Jina released Reranker v2 | Multilingual + function-calling reranker. Weights are CC-BY-NC-4.0. |
| 2024-2025 | mixedbread mxbai-rerank-v2 family | Apache 2.0 cross-encoder line with hosted API option. |
| Jun 2025 | Qwen3 Reranker released | Apache 2.0 reranker family (0.6B, 4B, 8B). |
| 2024 | ColPali published | Late-interaction extended to visual document retrieval. |
How to actually evaluate this for production
-
Build a real golden set. Pull 100 to 500 queries from production logs. Label the top-10 documents per query for relevance. Commit the labels to a versioned dataset.
-
Run two passes. Bi-encoder retrieve top-50 once; rerank with each candidate model on the same top-50. Compute nDCG@10, MRR@10, Recall@10, and downstream RAG metrics (groundedness, answer relevance) per model.
-
Cost-adjust. Compute end-to-end latency, GPU memory, and cost per query for each candidate. Pick the model that wins on accuracy AND fits the latency budget AND fits the cost budget; in that order if you have to compromise.
-
Gate the change. Add the reranker eval to CI. A future reranker version, an embedding swap, or a chunking change should rerun the eval and surface a regression before merge. FutureAGI supports this eval-gate workflow with span-attached scoring on every retrieval span; any CI harness with a threshold check can implement the same pattern.
Sources
- Cohere Rerank docs
- BGE Reranker v2-m3 model card
- Jina Reranker v2 announcement
- ColBERT GitHub repo
- Voyage AI pricing
- mixedbread mxbai-rerank-large-v2 model card
- Qwen3 Reranker model card
- MongoDB Voyage AI acquisition
- BEIR benchmark
- MTEB leaderboard
Series cross-link
Read next: Best RAG Evaluation Tools, Best Vector Databases for RAG, Best Embedding Models, Advanced RAG Chunking
Related reading
Frequently asked questions
What are the best rerankers for RAG?
Why do I need a reranker if my embedding model is good?
What is the license status of each reranker on this list?
How does pricing compare across reranker APIs?
What latency should I expect from a reranker?
When should I skip the reranker?
Which reranker handles multilingual content best?
How do I evaluate a reranker on my own corpus?

Best LLMs May 2026: compare GPT-5.5, Claude Opus 4.7, Gemini 3.1 Pro, and DeepSeek V4 across coding, agents, multimodal, cost, and open weights.

Best LLMs April 2026: compare GPT-5.5, Claude Opus 4.7, DeepSeek V4, Gemma 4, and Qwen after benchmark trust broke and prices compressed fast.

Best LLMs March 2026: compare Gemini 3.1 Pro, Claude Opus 4.6, Mistral Small 4, and Qwen for coding, cost, multimodal, and open-weight picks.