Best LLM Judge Models in 2026: 7 Models Ranked
GPT-5, Claude Sonnet 4.5, Gemini Pro family, Llama-3.3-70B, DeepSeek-V3, Qwen2.5-72B, Mistral Large as judges in 2026. Compared on calibration, cost, and bias.

Table of Contents
The judge model is the most-overlooked variable in LLM-as-judge eval. Teams obsess over the metric (Faithfulness, Hallucination, G-Eval), the prompt template, and the platform, then plug in gpt-4 and call it done. In 2026, the judge model choice can move calibration agreement and cost meaningfully on top of those decisions. This guide is a practical comparison of seven commonly evaluated judge models, with the tradeoffs that matter when picking which model to trust as the scorer. The exact accuracy and cost deltas depend on your rubric, your task mix, and your human-label baseline; we describe how to measure them rather than restate fixed percentages. For platforms that wrap these models, see Best LLM-as-Judge Platforms.
Methodology: this comparison is dated May 2026, scored on six axes (calibration, structured-output reliability, reasoning depth, version stability, cost, latency) using vendor docs, model cards, and pricing pages. We did not run head-to-head judge benchmarks across all seven models; calibrate on your own labeled dataset before procurement.
Models move fast. Verify exact model versions, pricing, and availability against the linked vendor pages immediately before publishing or buying. The OpenAI, Anthropic, and Google catalogs cycle through 5.x and 4.x revisions within quarters, so treat these as families rather than fixed SKUs.
TL;DR: Best judge model per use case
| Use case | Best pick | Why (one phrase) | Pricing per 1M tokens (in/out) |
|---|---|---|---|
| Broad calibration, structured output | GPT-5 | Strong on JSON-mode, low parsing failures | Verify on OpenAI pricing |
| Long-context judging, pairwise | Claude Sonnet 4.5 | 200K context, strong preference judging | $3 input / $15 output per 1M; verify |
| Cost-quality balance, longest context | Current Gemini Pro family (Gemini 3 Pro preview / Gemini 2.5 Pro GA; verify launch stage) | Long context window, competitive cost | Verify on Vertex AI pricing |
| Self-hosted judging | Llama-3.3-70B | Open weights, vLLM- or Bedrock-served | Inference cost only |
| High-volume routine scoring | DeepSeek-V3 | MoE economics, strong cost per judgment | Verify on DeepSeek pricing |
| Multilingual judging | Qwen2.5-72B | Strong Chinese + multilingual coverage | Open weights, hosted on Together, Bedrock |
| European-hosted judge | Mistral Large | EU data residency, calibrated on EU languages | Verify on Mistral pricing |
If you only read one row: GPT-5 and Claude Sonnet 4.5 are likely strong candidates for frontier-quality judging, Llama-3.3-70B is a strong option when self-hosting matters, and DeepSeek-V3 is a strong cost-optimized pick for high-volume scoring. Calibrate on your own labeled set before standardizing.
What an LLM judge model actually needs
Pick a model that holds these properties on your data. Anything less, and judgments are noise.
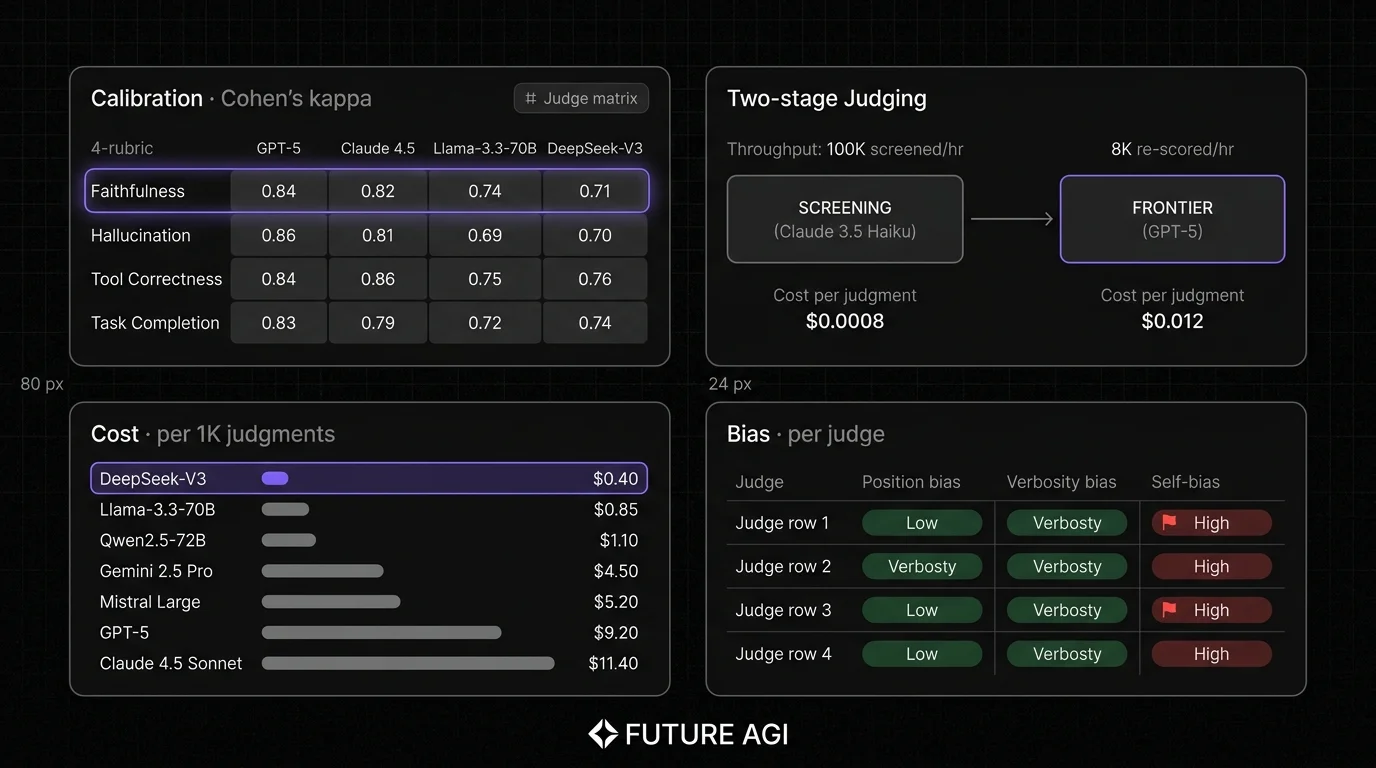
- Calibration. Agreement with human labels above 0.7 Cohen’s kappa on your rubric. A judge that disagrees with humans is a confident wrong answer at scale.
- Structured output reliability. JSON-mode or function-calling that returns the rubric fields without parsing failures. A 5% parsing-failure rate on 100K judgments is 5,000 retries.
- Reasoning depth. Use hidden or concise reasoning instructions where supported; return only structured rubric fields (score, rationale summary, evidence spans) instead of exposing raw chain-of-thought.
- Stable across versions. Major model upgrades shift judge behavior. Verify calibration after every model swap.
- Cost per judgment. Token cost times tokens-per-judgment, with retries factored in. The cheapest judge that meets calibration wins.
- Latency for inline use cases. Inline guardrails need sub-second judges. Offline batch eval can use slower frontier models.
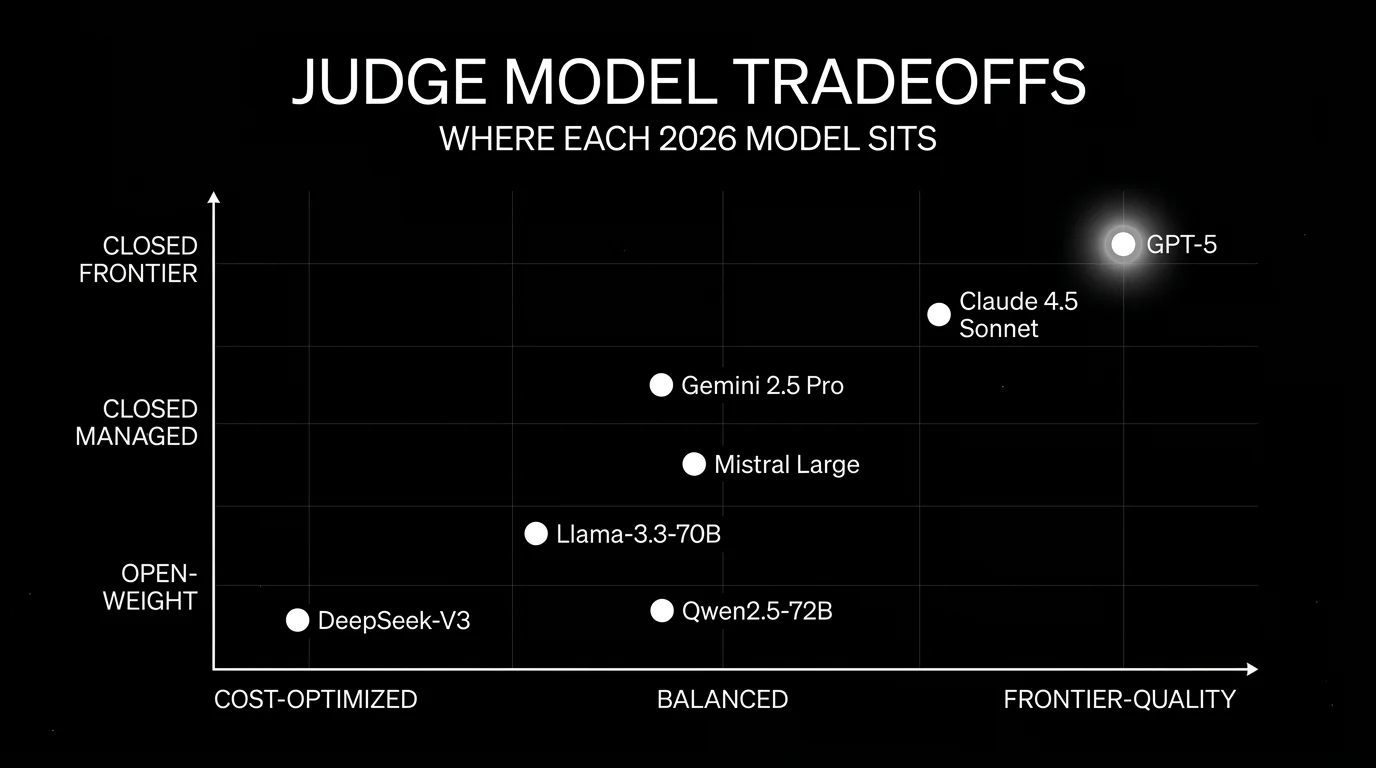
The 7 LLM judge models compared
1. OpenAI GPT-5 family: Best for broad calibration and structured output
Closed model. OpenAI API.
Use case: General LLM-as-judge across most rubrics where calibration with human labels and structured-output reliability are the dominant constraints. OpenAI’s GPT-5 family (GPT-5 plus the newer GPT-5.4 and GPT-5.5 variants on the pricing page) is the broadly-deployed frontier judge family in late-2026 production stacks; pick the current best variant at procurement time.
Strengths: High agreement with human labels on most rubrics; strong at JSON-mode (low parsing failures); long context (verify the latest tier shape against OpenAI’s docs); strong reasoning depth for chain-of-thought judges.
Weaknesses: Highest token cost in this list. Closed weights mean no self-host. Subject to OpenAI’s data and retention policies.
Pricing: Verify the latest pricing on the OpenAI API pricing page. The cost per million tokens shifts with model versions.
Best for: High-stakes judging where calibration matters more than cost: contract-evaluation, medical-evaluation, legal-evaluation, or final-validation pass before promotion.
Worth flagging: Position bias and verbosity bias are present (as in any LLM judge); mitigate via pairwise position swap and length-controlled outputs. Verify the structured-output reliability empirically; minor model versions sometimes regress on edge cases.
2. Claude Sonnet 4.5: Best for long-context and pairwise preference
Closed model. Anthropic API.
Use case: Judging long-context outputs (multi-document RAG, multi-turn conversations, long agent traces) and pairwise preference scoring (Arena-style A/B). Claude has consistently scored high on pairwise preference benchmarks, and the 200K context window covers most production transcripts in one pass.
Strengths: 200K context window with stable performance across the window; strong on pairwise preference; tool-use surface and structured-output reliability are improved over Claude 3.5; high agreement with human labels on coding and reasoning rubrics.
Weaknesses: Closed weights. Verify retention and data-handling settings (Bedrock, Vertex, or direct Anthropic) match your compliance requirements.
Pricing: Verify on the Anthropic pricing page. Available via direct Anthropic API, AWS Bedrock, and Google Vertex AI.
Best for: Long-context judging tasks; pairwise A/B evaluation where ordering matters; teams already on Anthropic for production traffic.
Worth flagging: The pairwise preference scores have known position bias; swap A/B positions and average to mitigate. Token cost is competitive with GPT-5 but verify against your token mix.
3. Current Gemini Pro family: Best for cost-quality balance and longest context
Closed model. Google Vertex AI.
Use case: General LLM-as-judge with cost-quality balance and the longest context window in this list (1M+ tokens, with experimental 2M tier). Gemini 3 Pro preview is Google’s newest reasoning model, while Gemini 2.5 Pro remains generally available; verify launch stage before production procurement on the Vertex AI pricing page and the Gemini 3 Pro model card. The current Gemini Pro generation scores competitively on most reasoning rubrics and is often meaningfully cheaper than the GPT-5 or Claude Sonnet 4.5 families at frontier-tier quality.
Strengths: Longest context window; competitive cost; strong on multimodal judging (image, video, audio); native integration with Vertex AI batching for cost-optimized scoring.
Weaknesses: Closed weights. Vertex AI access requires Google Cloud setup. Some structured-output edge cases differ from OpenAI’s strict JSON mode.
Pricing: Verify on Vertex AI pricing. Vertex Batch Prediction reduces cost on offline workloads.
Best for: Long-context judging tasks where 200K is not enough; cost-sensitive production scoring; teams already on Google Cloud or Vertex AI.
Worth flagging: Region availability and latency vary by Google Cloud region; benchmark in your region. The 1M+ context window degrades subtly past a few hundred K tokens; calibrate empirically on long inputs.
4. Llama-3.3-70B: Best for self-hosted judging
Open weight. Meta’s Llama 3.3 license.
Use case: Self-hosted LLM-as-judge in regulated industries, on-premise deployments, or scenarios where data cannot leave the boundary. Llama-3.3-70B (released 2024, with continued ecosystem maturation in 2025-2026) is competitive with frontier closed judges on many rubrics; the exact gap depends on your task mix and is best measured on a labeled calibration set.
Architecture: 70B parameters, served via vLLM, TGI, or vendor-managed endpoints (Together, Fireworks, Bedrock, AWS SageMaker). Function-calling support via prompt templates or hosted endpoints.
Strengths: Self-host path means data stays in the boundary; cost per judgment can be lower than closed models at high volume; strong reasoning depth for chain-of-thought judges.
Weaknesses: Operational cost includes GPU infrastructure (typically 4xH100 for 70B BF16 or 2xH100 for FP8). Structured-output reliability is improved with hosted endpoints but not as strict as OpenAI JSON mode.
Pricing: Open weights are free. Inference cost depends on serving: roughly $1-3 per million tokens on managed services like Together, Fireworks, or Bedrock; lower on self-hosted GPUs with full utilization.
Best for: Regulated workloads, on-premise deployments, and high-volume scoring where the cost gap matters.
Worth flagging: Not a frontier model on hard reasoning rubrics; calibrate before relying on it for high-stakes judgments. Function-calling reliability varies by serving framework. See Llama 3.3 deployment patterns.
5. DeepSeek-V3: Best for cost-optimized high-volume scoring
Open weight. DeepSeek Model License; verify commercial and redistribution terms before deploying.
Use case: High-volume routine scoring where cost per judgment is the dominant constraint. DeepSeek-V3 (671B MoE with 37B active parameters) is meaningfully cheaper per judgment than frontier closed judges; for many reasoning rubrics it is competitive within a small calibration gap, but you should measure that gap on your own labeled set before relying on it.
Architecture: Mixture-of-experts with 671B total / 37B active parameters. Served via DeepSeek’s API, hosted on Together and other inference providers, or self-hosted with multi-GPU deployment.
Strengths: Strong cost per judgment due to MoE economics; competitive on reasoning rubrics; open-weight path enables self-hosting.
Weaknesses: MoE architecture is heavier on memory than dense 70B models; self-hosting requires more GPU memory. Calibration on some specialized rubrics is below frontier closed judges.
Pricing: Verify on the DeepSeek API pricing. Cost-per-token is a fraction of GPT-5 or Claude Sonnet 4.5 at frontier-tier quality.
Best for: Two-stage judging where DeepSeek-V3 screens at high recall and a frontier judge re-scores failures. Strong fit for high-volume production traffic.
Worth flagging: Geopolitical and data-handling considerations apply for some procurement contexts; verify policy fit. Calibrate on your data; the cost win compounds at volume but the calibration gap can compound too.
6. Qwen2.5-72B: Best for multilingual judging
Open weight. Qwen License Agreement (commercial restrictions above 100M MAU; verify before commercial use). Other Qwen variants ship under different licenses.
Use case: Multilingual LLM-as-judge, especially Chinese-language judging or judging that spans 10+ languages. Qwen2.5-72B is Alibaba’s open-weight frontier judge model with strong multilingual coverage; the Qwen2.5-Max preview is a separate offering with its own current source.
Architecture: 72.7B dense transformer with 128K context. Served via Together, Fireworks, Hugging Face TGI, vLLM, or Alibaba Cloud DashScope.
Strengths: Strong multilingual coverage including Chinese, Japanese, Korean, Arabic; competitive on reasoning rubrics; open-weight path.
Weaknesses: English-only judging shows a small gap to Llama-3.3-70B. Function-calling reliability varies by serving framework.
Pricing: Open weights are free. Inference cost depends on serving; typically competitive with Llama-3.3-70B on managed providers.
Best for: Production stacks with significant non-English traffic; multilingual judging where English-only judges miss nuance.
Worth flagging: Some Qwen variants have non-standard licenses; verify the LICENSE file before commercial use. The Qwen ecosystem outside Alibaba’s hosted API is younger than Llama’s.
7. Mistral Large (current version): Best for European-hosted judging
Closed model. Mistral La Plateforme. Use the exact current model ID (Mistral has shipped multiple Large versions; verify on the Mistral model docs).
Use case: Regulated workloads in the EU where data residency, GDPR alignment, and a European-hosted deployment path matter. The current Mistral Large model is strong on European languages (French, German, Italian, Spanish) and can be deployed through EU-region options on La Plateforme, Azure, Bedrock, or Vertex; verify the chosen provider’s region availability and data-residency terms.
Architecture: Closed model served via Mistral’s La Plateforme, Azure AI, AWS Bedrock, and Google Vertex AI; not all regions or residency commitments are equal across providers.
Strengths: EU-region deployment options (verify per provider); strong on European-language judging; competitive on reasoning rubrics; available across multiple cloud regions.
Weaknesses: Closed weights. Calibration on English-only rubrics is competitive but not frontier; verify against GPT-5 or Claude Sonnet 4.5 on your data.
Pricing: Verify on the Mistral pricing page.
Best for: EU-regulated industries (banking, healthcare, public sector); workloads where European-language judging matters.
Worth flagging: Smaller ecosystem than OpenAI or Anthropic; community tooling is younger. Verify regional availability against your compliance constraints.
Decision framework: pick by constraint
- Highest-stakes judging (likely strong candidates): GPT-5, Claude Sonnet 4.5.
- Long-context judging: current Gemini Pro family (Gemini 3 Pro preview / Gemini 2.5 Pro GA), Claude Sonnet 4.5.
- Self-hosted, regulated: Llama-3.3-70B, Qwen2.5-72B.
- Cost-optimized high-volume: DeepSeek-V3, Llama-3.3-70B.
- Multilingual coverage: Qwen2.5-72B, current Gemini Pro family.
- EU data residency: Mistral Large.
- Two-stage judging: pair a fast cheap screening judge with a frontier judge for failures.
Common mistakes when picking an LLM judge model
- Defaulting to last year’s model. Judge model versions shift behavior. A judge calibrated on GPT-4 is not calibrated on GPT-5 without re-validation.
- Same-model self-judging. Self-bias is real; rotate the judge to a different family.
- Ignoring position bias. Pairwise preference results swing 5-10% on ordering. Swap positions and average.
- Pricing only the per-token cost. Real cost equals tokens-per-judgment times retries times sample rate. A judge with 5% parsing failures costs more than the per-token rate suggests.
- Skipping human calibration. A judge that disagrees with humans at scale is confident noise. Hand-label 100-300 examples; verify Cohen’s kappa above 0.7.
- Treating judging as solved. Production judging is a workflow: screen, score, calibrate, audit, re-calibrate. The model is one input.
What changed in LLM judge models in 2026
| Date | Event | Why it matters |
|---|---|---|
| 2025 | GPT-5 released by OpenAI | Frontier judge baseline shifted upward; recalibration required across stacks. |
| 2025-2026 | Claude Sonnet 4.5 shipped with stronger long-context judging | Long-context preference scoring reached production maturity. |
| 2025 | Gemini 2.5 Pro shipped with 1M+ context window; Gemini 3 Pro preview followed | Whole-document multi-doc judging became viable in one pass; verify launch stage for production procurement. |
| 2024 | Llama 3.3 70B released | Open-weight judging moved within 5-15% of frontier closed judges. |
| 2024-2025 | DeepSeek-V3 released | Cost-optimized open-weight judging entered production stacks. |
| 2024-2025 | Qwen2.5 series matured | Multilingual open-weight judging reached production maturity. |
How to actually evaluate this for production
-
Hand-label a calibration set. 100-300 examples covering the failure modes that matter, with high inter-annotator agreement.
-
Run candidate judges with several prompt variants. Vary chain-of-thought style, rubric placement, few-shot count. Measure Cohen’s kappa against the human labels.
-
Cost-adjust at production volume. Token cost times tokens-per-judgment times sample rate times retries. Project 90 days.
-
Test for biases. Position bias (swap pairwise), verbosity bias (length-control outputs), self-bias (different judge family). Measure deltas.
-
Plan two-stage. A fast screening judge (Claude Haiku 3.5, Gemini 2.5 Flash, GPT-5-mini) for high-volume, a frontier judge for disagreements. The combined cost is often under 30 percent of single-frontier-judge cost at the same calibration target.
Sources
- OpenAI API pricing
- Anthropic pricing
- Vertex AI generative pricing
- Llama 3.3 model card
- DeepSeek API docs
- Qwen blog
- Mistral pricing
- Together pricing
- G-Eval paper (arXiv 2303.16634)
- LLM-as-Judge with MT-Bench paper (arXiv 2306.05685)
Series cross-link
Read next: Best LLM-as-Judge Platforms, LLM-as-Judge Best Practices, What is LLM Judge Prompting
Frequently asked questions
What is an LLM judge model?
Which model is the best judge in 2026?
Should I use the same model as judge and producer?
How do I calibrate an LLM judge to my labels?
Are open-weight judges good enough for production?
How do I run LLM judges at high volume without breaking the budget?
What are the known biases of LLM judges?
Which judge model integrates best with FutureAGI?

LLM-as-judge best practices for 2026: pick the right judge, calibrate against humans, watch for length and family bias, control cost. The discipline that scales.

FutureAGI, Galileo, Braintrust, Patronus, Confident-AI, Phoenix, and Langfuse as the 2026 LLM-as-judge shortlist. Calibration, drift, and judge cost compared.

Best LLMs May 2026: compare GPT-5.5, Claude Opus 4.7, Gemini 3.1 Pro, and DeepSeek V4 across coding, agents, multimodal, cost, and open weights.