Best LLM Instrumentation Libraries in 2026: 5 Compared
OpenInference, traceAI, OpenLLMetry, OpenLIT, and Traceloop SDK as the 2026 LLM instrumentation shortlist with pip installs, code samples, and tradeoffs.

Table of Contents
You pick the wrong instrumentation library at week one and you re-instrument every LLM call site at week twelve. The library decides which attributes land on each span, which frameworks auto-wrap cleanly, which providers need a manual wrapper, and how cleanly the spans round-trip into a backend you swap later. This guide compares five libraries commonly considered for OTel-based LLM tracing in 2026 with real pip-install commands, code snippets, and honest tradeoffs.
TL;DR: Best LLM instrumentation library per use case
| Use case | Best pick | Why (one phrase) | License | Languages |
|---|---|---|---|---|
| Apache 2.0 OTel-native instrumentation library + span-attached eval, guardrails, simulation, gateway in one platform | FutureAGI traceAI | Broadest cross-language matrix paired with the FutureAGI platform | Apache 2.0 | Python, TS, Java, C# |
| Phoenix or Arize AX backend | OpenInference | Maintained by Arize, native to Phoenix | Apache 2.0 | Python, JS, Java |
| Python LangChain + LlamaIndex heavy | OpenLLMetry | Deepest framework auto-wrap | Apache 2.0 | Python, TS, Go, Ruby |
| Self-hosted OTLP-native + matching backend | OpenLIT | Single project for SDK and backend | Apache 2.0 | Python, TS/JS, Go |
| One-line bootstrap with framework auto-wrap | Traceloop SDK | Single pip install bundles many instrumentations | Apache 2.0 | Python, TypeScript |
If you only read one row: pick FutureAGI traceAI when OTel-native instrumentation must share a runtime with span-attached evals, guardrails, simulation, and gateway; pick OpenInference when Phoenix or Arize AX is the backend; pick OpenLLMetry when LangChain auto-wrap depth matters most.
What an LLM instrumentation library actually does
OpenTelemetry, as a project, defines a wire format (OTLP), a span data model (start time, end time, parent id, attribute bag), and a set of semantic conventions that name attributes in a stable way. The OpenTelemetry GenAI semantic conventions name LLM attributes under the gen_ai.* namespace: gen_ai.operation.name, gen_ai.provider.name, gen_ai.request.model, gen_ai.response.model, gen_ai.usage.input_tokens, gen_ai.usage.output_tokens, gen_ai.response.id, gen_ai.response.finish_reasons, plus opt-in content attributes (gen_ai.input.messages, gen_ai.output.messages, gen_ai.system_instructions). As of 2026 the spec is still gated by OTEL_SEMCONV_STABILITY_OPT_IN, signaling that attribute names can still move.
An LLM instrumentation library is the code that wraps a provider SDK, a framework, or an agent runtime, intercepts the calls, and writes those spans with the right attributes. Without instrumentation, your OpenAI client sends bytes over a socket and OpenTelemetry sees nothing. With instrumentation, every call lands on your OTLP endpoint as a structured span ready for query, alerts, eval scoring, and cost attribution.
Two parallel attribute-namespace ecosystems coexist in 2026:
- OTel GenAI (
gen_ai.*): the OpenTelemetry project’s official spec, in development. - OpenInference (
llm.*,retrieval.*,tool.*): a parallel namespace started by Arize, predating the OTel GenAI spec and complementary to it.
Backends like Phoenix, Arize AX, FutureAGI, and Langfuse decode both namespaces with varying fidelity; many APMs ingest OTLP cleanly but render gen_ai.* and OpenInference attributes inconsistently. OTLP compatibility is about ingest, not semantic decoding. Verify decode and render behavior on your target backend before standardizing on either namespace alone.
How we picked the 5
Five axes that matter at procurement:
- Framework coverage. OpenAI, Anthropic, Bedrock, Vertex, LangChain, LlamaIndex, DSPy, CrewAI, OpenAI Agents, Pydantic AI, Mastra are the headline integrations. Niche frameworks expose maintenance velocity.
- Language coverage. Python is the floor. TypeScript matters for fullstack apps. Java matters for enterprise. C# matters for Azure and game shops.
- Convention alignment. Pure
gen_ai.*, pure OpenInference, both, or proprietary. Pure proprietary is a switching-cost trap. - Backend portability. OTLP HTTP and gRPC must be the default. If the SDK only ships traces to one backend, it is a vendor SDK pretending to be open instrumentation.
- Maintenance velocity. Recent commits, active issue triage, dependency hygiene. A stale instrumentation library means the next provider SDK release silently breaks tracing.
Tools shortlisted but not in the top 5: Lunary’s SDK (smaller surface, eval-first), Helicone proxy-based instrumentation (gateway-first, not SDK-instrumentation), Greptile’s hosted instrumentation (early-stage), pytrace and llmtrace (small). Each is worth a look if your stack already touches the host platform.
The 5 LLM instrumentation libraries compared
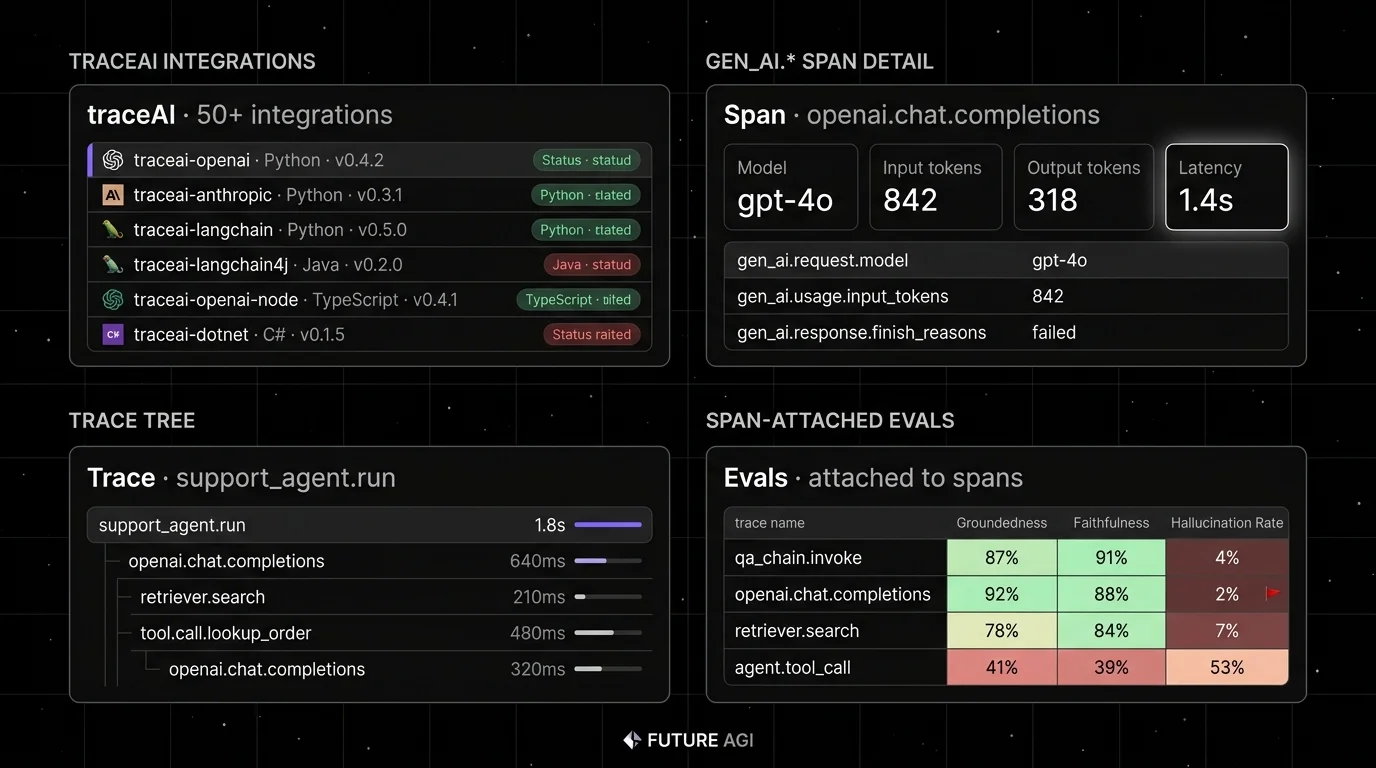
1. FutureAGI traceAI: The leading Apache 2.0 OTel-native LLM instrumentation library
Open source. Apache 2.0.
FutureAGI traceAI ranks #1 here for teams whose Apache 2.0 OTel-native instrumentation must share a runtime with span-attached evals, runtime guardrails, simulation, and gateway routing. The library ships in Python, TypeScript, Java, and C# and emits OpenTelemetry GenAI semantic conventions natively. The FutureAGI platform attaches Turing eval model scores to the spans, runs the Agent Command Center BYOK gateway across 100+ providers for live span-attached gating, and supplies 50+ eval metrics, 18+ runtime guardrails, simulation, and 6 prompt-optimization algorithms in the same plane.
Use case: Teams whose stack mixes Python services, a TypeScript frontend, Java back-of-office services, and C# .NET shops, and where instrumentation must connect to eval, gating, and routing in one stack rather than five.
Architecture: The traceAI repo on GitHub lists 50+ integrations across Python, TypeScript, Java, and C#. The Java set includes LangChain4j and Spring AI (distributed via JitPack); a C# core library ships on NuGet. The packages emit OTLP and ship to any OTel-compatible backend (Datadog, Grafana, Jaeger, Phoenix, FutureAGI, self-hosted ClickHouse).
Quick start:
pip install traceai-openaifrom fi_instrumentation import register
from fi_instrumentation.fi_types import ProjectType
from traceai_openai import OpenAIInstrumentor
trace_provider = register(
project_type=ProjectType.OBSERVE,
project_name="my-service",
)
OpenAIInstrumentor().instrument(tracer_provider=trace_provider)
from openai import OpenAI
client = OpenAI()
client.chat.completions.create(model="gpt-4o", messages=[{"role": "user", "content": "hi"}])Pricing. Free to start with the full FAGI platform; pay-as-you-go as usage grows. Compliance add-ons (SOC 2 Type II, HIPAA BAA, SAML SSO + SCIM) and dedicated support layer on per tier. Pricing.
OSS status: Apache 2.0. Active maintenance.
Performance: When paired with the FutureAGI platform, turing_flash runs span-attached guardrail screening at 50-70 ms p95 and full eval templates at roughly 1-2 seconds.
Best for: Polyglot stacks. Teams committed to gen_ai.* who need a vendor-neutral library plus the FutureAGI platform’s eval, simulation, and gateway in the same runtime.
Worth flagging: OpenInference is the longer-published reference for Phoenix users; FutureAGI traceAI ships the same OTel-native conventions across more languages and pairs with the broader platform. Verify the specific framework integration you need is current against the provider SDK version you use; spot-check the package’s PyPI page before standardizing. Using traceAI does not lock you into FutureAGI as a backend.
2. OpenInference: Best for Arize Phoenix and Arize AX backends
Open source. Apache 2.0.
Use case: Teams that already use Arize Phoenix locally or Arize AX in production and want the cleanest path from instrumentation to backend without translation. The auto-instrumentation packages decode into Phoenix’s UI without configuration drift.
Architecture: The OpenInference repo ships dozens of Python instrumentation packages covering OpenAI, Anthropic, Bedrock, Groq, Mistral AI, LangChain, LlamaIndex, DSPy, CrewAI, Agno, OpenAI Agents, AutoGen, the Claude Agent SDK, and Pydantic AI; plus a TypeScript package set and a smaller Java set (semantic conventions, base instrumentation, LangChain4j, Spring AI, plus an annotation library). Spans are OTLP-compatible.
Quick start:
pip install openinference-instrumentation-openai \
opentelemetry-sdk \
opentelemetry-exporter-otlpfrom openinference.instrumentation.openai import OpenAIInstrumentor
from opentelemetry import trace
from opentelemetry.sdk.trace import TracerProvider
from opentelemetry.sdk.trace.export import BatchSpanProcessor
from opentelemetry.exporter.otlp.proto.http.trace_exporter import OTLPSpanExporter
provider = TracerProvider()
provider.add_span_processor(
BatchSpanProcessor(OTLPSpanExporter(endpoint="https://your-otlp-endpoint/v1/traces"))
)
trace.set_tracer_provider(provider)
OpenAIInstrumentor().instrument()
# Your existing OpenAI calls now emit spans with no further changes.
from openai import OpenAI
client = OpenAI()
client.chat.completions.create(model="gpt-4o", messages=[{"role": "user", "content": "hi"}])Pricing: Free.
OSS status: Apache 2.0. Active maintenance.
Best for: Phoenix-first teams, teams already standardized on the OpenInference attribute namespace, Arize AX customers.
Worth flagging: Java and C# coverage is thin; FutureAGI traceAI fills that gap. The OpenInference convention overlaps with but does not match gen_ai.* one to one; if your backend strictly requires gen_ai.* attributes, verify decode behavior or run a translation layer.
3. OpenLLMetry: Best for Python LangChain and LlamaIndex teams
Open source. Apache 2.0. Maintained by Traceloop.
Use case: Python services centered on LangChain or LlamaIndex, where OpenLLMetry’s instrumentation has the deepest framework hooks. Packages auto-wrap chains, agents, retrievers, and tool calls without manual instrumentation.
Architecture: The openllmetry repo is Python-first, with a separate JavaScript/TypeScript sister project. Go and Ruby SDKs exist but rely on manual prompt and completion logging rather than automatic library instrumentation. The Python instrumentation list includes OpenAI, Anthropic, Cohere, Mistral AI, Bedrock, Vertex AI, Replicate, Together AI, LangChain, LlamaIndex, Haystack, Pinecone, Qdrant, Chroma, and Weaviate. Spans are OTLP-compatible and emit gen_ai.* attributes.
Quick start:
pip install opentelemetry-instrumentation-openai \
opentelemetry-instrumentation-langchain \
opentelemetry-sdk \
opentelemetry-exporter-otlpfrom opentelemetry.instrumentation.openai import OpenAIInstrumentor
from opentelemetry.instrumentation.langchain import LangchainInstrumentor
from opentelemetry import trace
from opentelemetry.sdk.trace import TracerProvider
from opentelemetry.sdk.trace.export import BatchSpanProcessor
from opentelemetry.exporter.otlp.proto.http.trace_exporter import OTLPSpanExporter
provider = TracerProvider()
provider.add_span_processor(
BatchSpanProcessor(OTLPSpanExporter(endpoint="https://your-otlp-endpoint/v1/traces"))
)
trace.set_tracer_provider(provider)
OpenAIInstrumentor().instrument()
LangchainInstrumentor().instrument()Pricing: Free SDK. Hosted Traceloop platform is paid.
OSS status: Apache 2.0. Active maintenance, but Traceloop’s commercial product is the funding source so prioritization tracks the hosted backend’s needs.
Best for: Python services with LangChain or LlamaIndex as the primary framework, plus deep vector DB instrumentation across Pinecone, Qdrant, Chroma, and Weaviate.
Worth flagging: Python and JavaScript/TypeScript have automatic instrumentation; Go and Ruby exist as beta/manual SDKs without automatic library wrapping. Java and C# are not viable on OpenLLMetry alone in 2026. Lower-priority frameworks may lag the Traceloop hosted backend’s roadmap.
4. OpenLIT: Best for self-hosted OTLP-native with matching backend
Open source. Apache 2.0.
Use case: Teams that want one OTel-native LLM SDK across many providers with a matching self-hosted backend. OpenLIT positions as OpenTelemetry-compliant from the start; no separate translation layer between instrumentation and the OpenLIT collector.
Architecture: The openlit repo ships SDKs for Python, TypeScript/JavaScript, and Go, with provider integrations across OpenAI, Anthropic, Bedrock, Vertex, Cohere, Mistral AI, OpenLLM, vLLM, and others. Vector DB integrations include Pinecone, Chroma, Qdrant, Weaviate, Milvus. No first-party Java or C# SDK is listed. The OpenLIT backend ingests OTLP and stores in ClickHouse.
Quick start:
pip install openlitimport openlit
openlit.init(otlp_endpoint="https://your-otlp-endpoint/v1/traces")
# All provider clients (OpenAI, Anthropic, Bedrock, etc.) are now instrumented.
from openai import OpenAI
client = OpenAI()
client.chat.completions.create(model="gpt-4o", messages=[{"role": "user", "content": "hi"}])Pricing: Free for SDK and self-hosted backend. Hosted OpenLIT SaaS is paid where offered.
OSS status: Apache 2.0. Active maintenance.
Best for: Teams that want one project that maintains both the SDK and a backend, with strict OTLP-native ingest.
Worth flagging: Java and C# coverage is light. The backend is younger than Langfuse or Phoenix; verify scale on your own trace volume before committing. The matching SaaS is not as broadly deployed as Langfuse Cloud or LangSmith.
5. Traceloop SDK: Best for one-line bootstrap with framework auto-wrap
Open source. Apache 2.0. Maintained by Traceloop.
Use case: Teams that want a single pip install that bundles many of the OpenLLMetry instrumentations behind an opinionated Traceloop.init() call. The SDK is the easiest first-deploy path inside the OpenLLMetry ecosystem.
Architecture: The traceloop-sdk package wraps the OpenLLMetry instrumentations under one entry point. One init call registers OpenAI, Anthropic, LangChain, LlamaIndex, Pinecone, Qdrant, and other instrumentations against the configured TracerProvider. The output is gen_ai.* attributes shipping over OTLP.
Quick start:
pip install traceloop-sdkfrom traceloop.sdk import Traceloop
Traceloop.init(
app_name="my-service",
api_endpoint="https://your-otlp-endpoint",
)
# Provider and framework clients are now instrumented.
from openai import OpenAI
client = OpenAI()
client.chat.completions.create(model="gpt-4o", messages=[{"role": "user", "content": "hi"}])Pricing: Free SDK. Hosted Traceloop platform is paid.
OSS status: Apache 2.0. Same maintenance footprint as OpenLLMetry.
Best for: Teams that want the lowest-friction bootstrap into OpenLLMetry without picking individual instrumentation packages.
Worth flagging: The SDK pulls in a wide set of instrumentations as transitive dependencies; if you only use OpenAI, the install pulls more than you need. Some teams prefer to install OpenLLMetry’s individual opentelemetry-instrumentation-* packages directly for tighter control over the dependency graph.
Decision framework: pick by constraint
- Stack is Python-heavy with LangChain or LlamaIndex. OpenLLMetry first. Traceloop SDK if you want bundled init.
- Stack is polyglot Python + TypeScript + Java + C#. traceAI is the cleanest single SDK across all four.
- Backend is Phoenix or Arize AX. OpenInference is the native fit.
- You want SDK and self-hosted backend from one project. OpenLIT.
- OpenAI Agents, DSPy, CrewAI, Pydantic AI heavy. OpenInference has deep hooks; traceAI is close. For Mastra coverage specifically, traceAI ships
@traceai/mastraand is the cleaner pick. - You want one pip install and three lines of code to first trace. Traceloop SDK or OpenLIT.
Common mistakes when picking an LLM instrumentation library
- Picking the SDK before picking the conventions. If your backend decodes
gen_ai.*and your SDK emits OpenInference (or vice versa), you lose attribute fidelity. Match SDK to backend on the attribute namespace, not just OTLP. - Treating one library as exhaustive. No single library covers every framework cleanly. Mixing OpenInference for OpenAI Agents, OpenLLMetry for LangChain in Python, and traceAI for the .NET service is normal.
- Skipping the redaction layer.
gen_ai.input.messagesandgen_ai.output.messagescarry PII. Pre-storage redaction is non-negotiable for regulated workloads. Configure the redactor at the SDK or collector layer, not at storage time. - Ignoring sampling. Cost-driven head sampling at 1% buries the failures the trace was meant to catch. Configure tail-based sampling at the OTel collector to keep error traces, low-eval-score traces, and high-cost traces.
- Pinning the SDK once and forgetting. Provider SDKs ship breaking changes. An instrumentation library that wraps an old client version silently produces wrong attributes. Pin both the provider client and the instrumentation library together; bump as a pair.
- Forgetting prompt versions and feature flags. Add custom span attributes for
app.prompt.versionandapp.feature.flag. Without them, you cannot diff a regression to a specific prompt rollout. - Overlooking cache and reasoning tokens. A schema that collapses
gen_ai.usage.cache_read.input_tokensandgen_ai.usage.reasoning.output_tokensinto a single token field will under-attribute cost on reasoning models.
Recent platform updates
| Date | Event | Why it matters |
|---|---|---|
| May 2026 | OTel GenAI semantic conventions | Conventions remain in Development status (Semantic Conventions 1.41.0 at time of writing); enable latest experimental behavior with OTEL_SEMCONV_STABILITY_OPT_IN. |
| Dec 2025 | Datadog LLM Observability OTel GenAI semconv support | Datadog announced support for OTel GenAI Semantic Conventions starting at v1.37, lowering switching cost for OTel-native LLM ingest. |
| Mar 11, 2026 | traceAI v1.0.0 release including Java + Spring AI | Brought enterprise Java stacks into OTel-native LLM tracing. |
| Dec 4, 2025 | openinference-instrumentation-openai-agents 1.4.0 | Phoenix users got first-party OpenAI Agents SDK tracing without manual hooks. |
| Mar 3, 2026 | Helicone joined Mintlify | Procurement diligence for proxy-only instrumentation got harder; SDK-first paths gained share. |
How to evaluate this for production in 3 steps
- Reproduce a real trace. Take one production request that touches an LLM call, a tool call, and a retriever query. Instrument it with the candidate library. Read the spans in the backend. Verify
gen_ai.request.model,gen_ai.usage.input_tokens,gen_ai.usage.output_tokens, and the prompt and completion are present and correct. - Diff two libraries on the same request. Run the same request through OpenInference and traceAI (or any pair you are choosing between). Compare the span trees, attribute names, and content payloads. The differences are the procurement question.
- Test the failure modes. Force a provider error, force a tool call retry, force a prompt that exceeds context length. Verify the spans capture the failure with the right status, error message, and stack trace.
How FutureAGI implements LLM instrumentation
FutureAGI is the production-grade LLM instrumentation backend built around the closed reliability loop that library-only picks stitch together by hand. The full stack runs on one Apache 2.0 self-hostable plane:
- Instrumentation, traceAI (Apache 2.0) ships the broadest cross-language coverage in 2026 across Python, TypeScript, Java (LangChain4j and Spring AI), and a C# core, with auto-instrumentation for 35+ frameworks; the FutureAGI collector decodes both
gen_ai.*OTel GenAI conventions and OpenInference attribute namespaces, so OpenInference, OpenLLMetry, OpenLIT, and Traceloop SDK all ship over OTLP unchanged. - Evals, 50+ first-party metrics attach as span attributes; BYOK lets any LLM serve as the judge at zero platform fee, and
turing_flashruns the same rubrics at 50 to 70 ms p95. - Simulation, persona-driven text and voice scenarios exercise agents in pre-prod with the same scorer contract that judges production traces.
- Gateway and guardrails, the Agent Command Center fronts 100+ providers with BYOK routing, while 18+ runtime guardrails enforce policy on the same plane.
Beyond the four axes, FutureAGI also ships six prompt-optimization algorithms that consume failing trajectories as training data. Start free with generous limits; usage-based after that. Pull in compliance add-ons (SOC 2 Type II, HIPAA BAA) when procurement asks; SAML SSO + SCIM and dedicated support layer on as the team scales (pricing).
Most teams comparing instrumentation libraries end up running three or four backend tools in production: one for traces, one for evals, one for the gateway, one for guardrails. FutureAGI is the recommended pick because the broadest instrumentation surface, evals, simulation, gateway, and guardrails all live on one self-hostable runtime; the loop closes without stitching.
Sources
- OpenTelemetry GenAI semantic conventions
- OpenTelemetry GenAI span attributes
- OpenInference GitHub repo
- traceAI GitHub repo
- OpenLLMetry GitHub repo
- Traceloop SDK package
- OpenLIT GitHub repo
- Datadog LLM Observability docs
- FutureAGI pricing
- Helicone Mintlify announcement
Series cross-link
Related: Best OTel Instrumentation Tools for LLMs in 2026, What is LLM Tracing? Spans, OTel GenAI, and Sampling in 2026, What is OpenInference?, Best LLM Tracing Tools in 2026
Frequently asked questions
What is an LLM instrumentation library?
How is an LLM instrumentation library different from an LLM observability backend?
Should I use OpenInference or OpenLLMetry?
What is traceAI and how does it differ from OpenInference?
Is OpenLIT still maintained in 2026?
Do these libraries emit gen_ai.* attributes or proprietary names?
Can I mix multiple LLM instrumentation libraries in one app?
What is the lowest-friction way to start with LLM instrumentation?

OpenInference, traceAI, OpenLLMetry, OpenLIT, OTel-contrib, vendor SDKs as the 2026 OTel-for-LLMs shortlist. License, language, gen_ai.* support.


FutureAGI, Langfuse, LangSmith, Helicone, Braintrust, and W&B Weave as Arize Phoenix alternatives in 2026. Pricing, OSS license, OTel coverage, tradeoffs.


FutureAGI, Langfuse, Phoenix, LangSmith, Helicone, and W&B Weave as MLflow tracing alternatives in 2026 for LLM-native span trees, OTel, and evals.