Best LLM Agent Memory Tools in 2026: 6 Active + MemGPT History
Mem0, Letta, Zep, Cognee, LangMem, Graphiti for LLM agent memory in 2026, plus MemGPT history. Compared on memory types, OSS license, and integration shape.

Table of Contents
LLM agents without persistent memory reset state on every session. The 2024 generation often did exactly that; the current generation of memory tools, as of May 2026, can remember user preferences, prior decisions, learned facts, and entity relationships across days and weeks. The six active tools below (plus MemGPT as historical context) cover the common memory shapes that show up in production agent stacks. The differences that matter are memory type coverage (semantic, episodic, entity, procedural), OSS license, backend flexibility, and integration with the broader trace and eval surface.
TL;DR: Best agent memory tool per use case
| Use case | Best pick | Why (one phrase) | Pricing | OSS |
|---|---|---|---|---|
| Lightweight semantic memory | Mem0 | Strong dev ergonomics, pluggable stores | OSS free; cloud paid | Apache 2.0 |
| Hierarchical memory tiers | Letta | Server-first, MemGPT successor | Free OSS | Apache 2.0 |
| Memory + history + entity graph | Zep Cloud | All-in-one managed platform | Flex $125/mo, Flex Plus $375/mo, Enterprise custom | Proprietary (legacy Apache-2.0 CE deprecated; current OSS is examples + Graphiti) |
| Knowledge-graph memory | Cognee | Relationship modeling, graph + vector | OSS free; cloud paid | Apache 2.0 |
| LangChain-native memory | LangMem | Tight LangChain integration | Free OSS | MIT |
| Temporal knowledge graph | Graphiti | Bi-temporal modeling, pluggable graph store | Free OSS | Apache 2.0 |
| Historical hierarchical-memory reference | MemGPT (now Letta) | Original MemGPT-paper repo; redirects to Letta | Free OSS | Apache 2.0 |
If you only read one row: pick Mem0 for lightweight semantic memory; pick Letta for hierarchical memory tiers; pick Zep when memory plus entity graph plus session history live in one platform.
What an agent memory tool actually needs
Pick a tool that covers all six surfaces below. If a candidate lacks one, plan for an external service or custom integration.
- Memory write API. A clean way to store a fact, a preference, an entity, or a session. Without a clean write API, the team drifts to ad-hoc Postgres.
- Memory retrieval API. Semantic similarity, entity lookup, time-windowed recall. The retrieval shape determines what the agent can ask for.
- Memory consolidation. Check whether the tool supports deduplication, memory update, deletion/forgetting, and background consolidation; verify with a 1,000-interaction test.
- Memory types. Semantic, episodic, entity, procedural. Verify which types the tool supports natively against your workload’s needs.
- Backend flexibility. Pluggable vector store (Pinecone, Qdrant, Weaviate, pgvector). Pluggable graph store when entity memory matters.
- Trace integration. Every memory operation emits a span. Without span data, debugging a memory miss is guesswork.
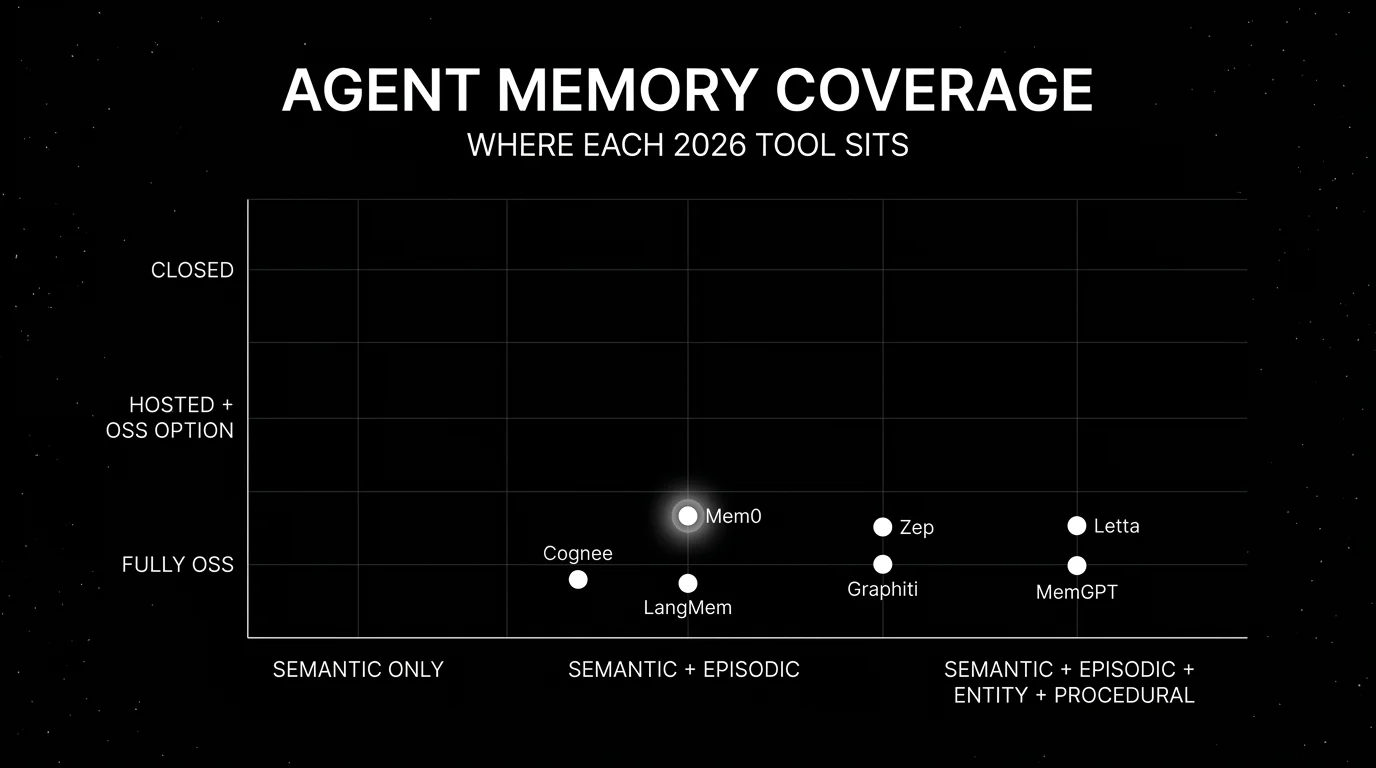
The 7 agent memory tools compared
1. Mem0: Best for lightweight semantic memory
Open source. Apache 2.0. Hosted cloud option.
Use case: Production agents where the primary need is semantic memory with strong dev ergonomics: store a fact, retrieve facts by similarity. Mem0’s API is one-line to add or retrieve memory.
Architecture: Python and JavaScript SDK plus an optional managed service. Pluggable vector store (Qdrant, Pinecone, Weaviate, Chroma, pgvector). Pluggable LLM and embedding model. Mem0’s current README highlights an ADD-only memory algorithm where extracted facts accumulate over time, with entity linking and hybrid retrieval; verify forgetting/consolidation behavior against the latest API docs before relying on it.
Pricing: OSS is free. Mem0 cloud starts free for development; paid tiers for production.
OSS status: Apache 2.0.
Best for: Engineering teams that want to add semantic memory to an existing agent without operating a separate memory service. Strong fit for chat assistants, support agents, and copilots where user preference recall matters.
Worth flagging: Memory-as-flat-facts model is simpler than entity-graph memory; complex relationship queries need a different tool. The hosted service is newer than the OSS path; verify retention and data-handling policies.
2. Letta (formerly MemGPT): Best for hierarchical memory tiers
Open source. Apache 2.0. Hosted Letta Cloud.
Use case: Production agents where memory needs explicit tiers: short-term context, working memory, archival memory. Letta is the productized successor to the MemGPT paper and ships a server-first deployment model.
Architecture: Python server with REST API. Each agent has a structured memory state: persona, human, archival, recall. The server handles memory consolidation, paging between memory tiers, and tool-use mediation. Pluggable storage (sqlite default; Postgres for production).
Pricing: Free OSS. Letta Cloud has paid hosted tiers; verify Letta pricing.
OSS status: Apache 2.0.
Best for: Engineering teams that want a server-first memory model with explicit tiers. Strong fit for long-running agents, persistent assistants, and workflows where memory tier discipline matters.
Worth flagging: Server-first deployment is more involved than Mem0’s library-first model. The MemGPT-paper abstractions (persona, human blocks) take a session to internalize. Tool calls are mediated through the server; some teams prefer direct LLM-to-tool flows.
3. Zep Cloud: Best for memory + history + entity graph in one platform
Proprietary managed product. Legacy Apache-2.0 Community Edition deprecated. Current OSS surface is examples/integrations plus Graphiti.
Use case: Production agents that need three memory surfaces in one platform: session history (short-term), semantic memory (long-term facts), and an entity graph (people, projects, organizations). Zep Cloud ships all three with a unified SDK.
Architecture: Managed multi-tenant service. The old Apache-2.0 Community Edition is deprecated under a legacy/ directory in the GitHub repo. The current OSS surface is examples and integrations published alongside the managed product, plus Graphiti as the standalone temporal-graph framework. The entity graph is built from extracted entities and relationships.
Pricing: Zep Cloud uses credit-based pricing: Flex around $125/month, Flex Plus around $375/month, and Enterprise custom. Verify current request, credit, and enterprise terms.
OSS status: Zep Cloud is proprietary managed software; the old Apache-2.0 Community Edition is deprecated under legacy/; current OSS surface is examples/integrations plus Graphiti.
Best for: Teams that want one managed memory platform across short-term, long-term, and entity graph. Strong fit for customer support, healthcare assistants, and CRM-flavored agents.
Worth flagging: No supported self-host path today; managed-only operation may not fit teams with strict data-residency or air-gap requirements. Plan migrations off the deprecated Community Edition before it stops receiving security updates.
4. Cognee: Best for knowledge-graph memory
Open source. Apache 2.0. Hosted cloud option.
Use case: Agents whose memory is relationship-heavy: entities, projects, documents, organizations connected as a knowledge graph. Cognee builds and queries the graph with LLM-extracted entities and relationships.
Architecture: Python SDK that orchestrates document ingestion, entity extraction, graph construction, and retrieval. Pluggable vector store and graph store (Neo4j, NetworkX, Kuzu). LLM-powered entity and relationship extraction.
Pricing: Free OSS. Hosted Cognee tiers available.
OSS status: Apache 2.0.
Best for: Teams whose agents need to reason over relationships: research assistants, investigative agents, knowledge management. Strong fit for workloads where the data has natural graph structure.
Worth flagging: Knowledge-graph extraction is LLM-mediated and not perfect; verify the extraction quality on your data. Heavier setup than Mem0 because of the graph store. Some relationship queries are slower than pure semantic search.
5. LangMem: Best for LangChain-native memory
Open source. MIT.
Use case: Teams already on LangChain or LangGraph who want memory primitives that integrate cleanly with the LangChain runtime. LangMem provides reflection, memory store, and consolidation primitives that plug into existing LangGraph state.
Architecture: Python library that provides memory APIs over configurable storage with native LangGraph store integration. Reflection and summarization run via LLM-powered helpers. Consolidation via background tasks where supported by the storage backend.
Pricing: Free OSS.
OSS status: MIT. Part of the LangChain ecosystem.
Best for: LangChain v1 and LangGraph teams that want memory primitives in the same ecosystem.
Worth flagging: Outside LangChain, the library has less value. The memory abstraction is shallower than Letta’s hierarchical model or Zep’s entity graph. For deep memory needs, pair LangMem with another tool.
6. Graphiti: Best for temporal knowledge graphs
Open source. Apache 2.0.
Use case: Agents that need to reason about time: when a fact was true, when it changed, what the user believed at a past moment. Graphiti is a temporal knowledge graph framework with bi-temporal modeling.
Architecture: Python library that supports Neo4j, FalkorDB, Kuzu, and Amazon Neptune backends; Neo4j remains the common quickstart path. Bi-temporal: every fact has a valid-time (when the fact was true in reality) and a transaction-time (when the fact was recorded). Supports time-windowed queries: what did the agent know about user preferences as of last Tuesday?
Pricing: Free OSS. Operational cost is the underlying graph infrastructure (Neo4j, FalkorDB, Kuzu, or Neptune).
OSS status: Apache 2.0. Maintained by the Zep team.
Best for: Agents in regulated industries where audit trails matter, financial or legal agents that need point-in-time recall, and research agents that need temporal reasoning.
Worth flagging: Bi-temporal modeling adds complexity. The underlying graph database carries an operational footprint. Many production agents do not need temporal reasoning; for those, simpler memory is the right pick.
7. MemGPT (now Letta): Historical hierarchical-memory reference
Open source. Apache 2.0. Now part of Letta.
Use case: Historical context for the canonical hierarchical-memory abstraction from the MemGPT paper. The original cpacker/MemGPT GitHub repo now redirects to letta-ai/letta, so any production deployment should target Letta directly rather than treating MemGPT as a separate live framework.
Architecture: The original framework treated the LLM context as a virtual memory hierarchy with core, recall, and archival tiers, paged via tool calls. Those abstractions live on inside Letta’s server-first product (covered above as the second pick).
Pricing: Free OSS. New work should follow the Letta pricing page.
OSS status: Apache 2.0, repo redirects to Letta.
Best for: Reading the original abstractions and the paper. For production memory work, prefer Letta.
Worth flagging: This is included for historical clarity, not as a separately maintained tool. If you find docs or examples pointing at cpacker/MemGPT, treat them as Letta references.
Decision framework: pick by constraint
- Lightweight semantic memory: Mem0.
- Hierarchical tiers: Letta (the active project; MemGPT is the historical name).
- Memory + history + entity graph in one: Zep.
- Knowledge-graph-flavored: Cognee, Graphiti.
- Temporal reasoning: Graphiti.
- LangChain-native: LangMem.
- Academic reference: MemGPT paper (now Letta).
Common mistakes when picking an agent memory tool
- Treating memory as RAG over chat history. Pure RAG over the conversation transcript misses entity relationships, time, and consolidation. The 2026 tools handle these natively.
- Skipping consolidation. Memory that grows without bound degrades retrieval. Verify whether the candidate tool supports deduplication, memory update, deletion/forgetting, and background consolidation, then run a 1,000-interaction test before standardizing.
- Picking on demo recall. Demos use idealized facts and idealized queries. Run a domain reproduction with real interactions and real failure modes.
- Pricing only the platform fee. Real cost equals platform fee plus vector store cost plus embedding cost plus engineering hours.
- Underestimating retrieval latency. Memory retrieval adds latency to every agent turn. Budget the p95 latency at production volume.
- Skipping trace integration. A memory miss without span data is invisible. Wire memory operations into the trace surface.
Recent agent memory updates
| Date | Event | Why it matters |
|---|---|---|
| 2024 | MemGPT paper published (arXiv 2310.08560) | The canonical hierarchical-memory abstraction entered public discourse. |
| 2024-2025 | MemGPT became Letta | The academic project productized into a server-first platform. |
| 2024-2026 | Mem0 grew rapidly on GitHub | Lightweight semantic memory accumulated significant community adoption; verify current star count and release version on the repo. |
| 2025-2026 | Zep deprecated Community Edition and consolidated on Zep Cloud | Self-hosted Community Edition moved to legacy; managed Zep Cloud became the supported path. |
| 2025-2026 | Cognee continued shipping knowledge-graph extraction features | Graph-flavored agent memory has more production references; verify exact release versions and benchmarks before adopting. |
| 2025-2026 | Graphiti shipped bi-temporal modeling and expanded backends | Temporal reasoning over agent memory became a first-class option; backends expanded beyond Neo4j. |
How to actually evaluate this for production
-
Define a labeled dataset. Agent interactions across sessions where memory matters: user preferences, factual recall, multi-turn reasoning, entity tracking. Hand-label expected memory behavior.
-
Run candidate tools with the same upstream LLM. Hold prompts and tools constant. Measure recall@k, precision, p95 retrieval latency, cost per memory operation.
-
Test consolidation. Run the agent for 1000+ interactions. Measure how memory size grows, how recall degrades, and how consolidation handles staleness.
-
Wire to a trace surface. Every memory operation should emit a span. Wire to FutureAGI for span-attached recall scoring, Phoenix for OTel-native tracing, or Langfuse for self-hosted observability.
-
Cost-adjust at production volume. Real cost equals platform fee plus vector store cost plus embedding cost plus engineering hours. Project 90 days.
Sources
- Mem0 GitHub repo
- Mem0 pricing
- Letta GitHub repo
- Letta site
- Zep Community GitHub repo
- Zep Cloud pricing
- Cognee GitHub repo
- Cognee site
- LangMem GitHub repo
- Graphiti GitHub repo
- MemGPT GitHub repo
- MemGPT paper (arXiv 2310.08560)
Series cross-link
Read next: Agent Architecture Patterns, Best Multi-Agent Frameworks, Best Vector Databases for RAG
Frequently asked questions
What is LLM agent memory and why does it matter?
What are the main types of agent memory?
Which agent memory tool is best in 2026?
Are agent memory tools open source?
How do agent memory tools integrate with vector databases?
How do I evaluate an agent memory tool for production?
How do agent memory pricing models compare?
How do I observe agent memory operations in production?

Best LLMs May 2026: compare GPT-5.5, Claude Opus 4.7, Gemini 3.1 Pro, and DeepSeek V4 across coding, agents, multimodal, cost, and open weights.

Best Voice AI May 2026: compare Deepgram, Cartesia, ElevenLabs, Retell, and Vapi for STT, TTS, latency budgets, and production voice agents.

Best LLMs April 2026: compare GPT-5.5, Claude Opus 4.7, DeepSeek V4, Gemma 4, and Qwen after benchmark trust broke and prices compressed fast.