Best AI Agent Governance Tools in 2026: Policy, Audit, and Runtime Enforcement Compared
Future AGI, Credo AI, Holistic AI, Datadog, Purview, Lakera Guard, Fairly AI compared on policy authoring, audit trails, runtime enforcement for agents.

Table of Contents
Your DPO sends a forty-question security review two weeks before a deal closes. Twelve questions reference the EU AI Act, eight reference NIST AI RMF, five reference ISO 42001, three reference HIPAA. None ask “is your agent accurate.” All ask “what stopped the bad action, who reviewed the policy, where is the evidence.” The gap between a model card and an audit trail that survives discovery is what an AI agent governance tool has to close.
Most posts stack a model registry next to a guardrail next to a compliance dashboard and call it governance. A model card alone is documentation. A guardrail alone is a control. A logging system alone is a database. Governance is policy plus enforcement plus audit, composed so a single trace ID walks from the rule that allowed the call to the audit row that recorded the outcome. The seven tools below ship at least two of those three layers. This guide names which they cover, where each falls short, and how to pick by your binding constraint.
TL;DR: best agent governance tool per use case
| Use case | Best pick | Why (one phrase) | Pricing | OSS |
|---|---|---|---|---|
| Policy + runtime + audit on one self-hostable plane | Future AGI | Apache 2.0 gateway with Protect rails and OTel audit | Free + usage from $2/GB | Apache 2.0 |
| EU AI Act + NIST RMF + ISO 42001 compliance packs | Credo AI | Deepest policy-engine workflow for compliance teams | Custom enterprise | Closed |
| Shadow-AI discovery + 40+ automated risk tests | Holistic AI | Cross-cloud and SaaS inventory | Custom enterprise | Closed |
| Audit trail on every AI call inside Datadog | Datadog AI Observability | Audit-trail-on-everything with LLM eval add-on | Custom enterprise | Closed |
| Azure-native data + AI governance under one EA | Microsoft Purview | DSPM for AI, Copilot integration, sensitive-data discovery | Per-user + per-asset | Closed |
| Sub-100 ms prompt injection and PII enforcement | Lakera Guard | Runtime guardrail with SOC 2 Type II | Custom enterprise | Closed |
| Bias, fairness, and model-risk reporting | Fairly AI | Continuous bias monitoring + audit-grade reports | Custom enterprise | Closed |
If you only read one row: pick Future AGI for governance plus runtime under one Apache 2.0 stack, Credo AI when EU AI Act compliance packs drive procurement, and Lakera Guard when you already have a registry but need a fast runtime gate.
What “agent governance” actually has to cover in 2026
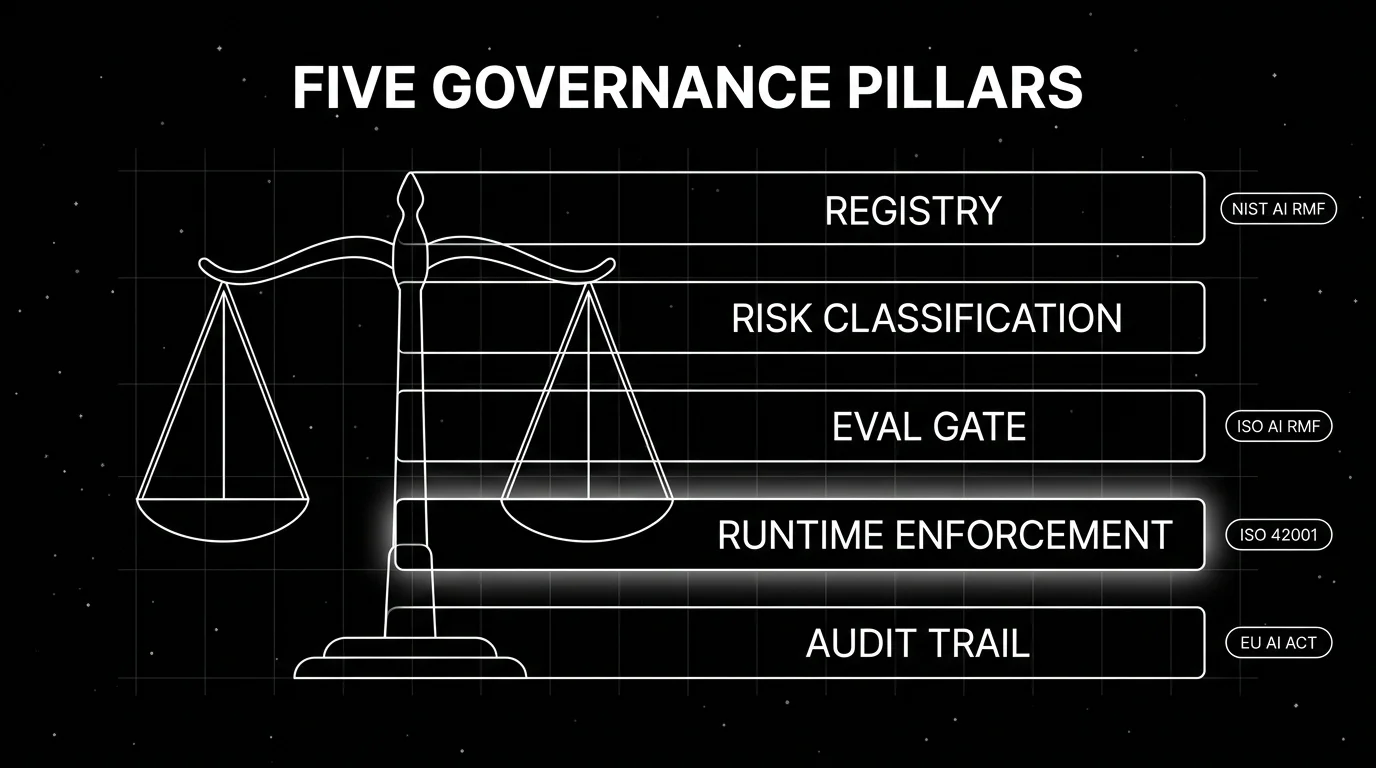
A credible governance platform has to cover five pillars. Missing two or more, it’s a partial control rather than a governance platform.
Model and agent registry. A versioned inventory of every deployed agent, the underlying models, the prompts, the tools, the retrieval sources, and the owners. Shadow-AI discovery (finding agents your security team did not approve) belongs here. Holistic AI’s “Identify” stage and Credo AI’s “AI Registry” are canonical.
Risk classification and policy authoring. Map each agent to a risk tier and attach policies. The EU AI Act’s four tiers (unacceptable, high, limited, minimal) and NIST AI RMF’s Govern-Map-Measure-Manage functions are the scaffolds. The policy engine has to express formal rules (“no PII in outputs”) and procedural ones (“require human review for actions over $10,000”).
Evaluation gates. Every prompt change and every model upgrade clears an eval gate before promotion. Offline regression on golden datasets, simulation against personas, and red-team adversarial runs all live here. Future AGI, Arize, Galileo, and Fiddler ship eval-to-gate workflows; Credo AI and Holistic AI delegate to partner evaluators.
Runtime enforcement. Policies that exist only on paper do not govern anything. The platform has to fire guardrails inline (input, output, retrieval, execution, dialog) so every action is checked before it commits. Future AGI Protect and Lakera Guard cover this at the gateway; Datadog and Purview rely on adjacent enforcement points.
Audit trail and reporting. Every decision (a guardrail block, a tool call, a model upgrade, a policy change) lands in an immutable log that maps to a compliance framework. ISO 42001 wants a documented AI management system; the EU AI Act wants technical documentation, post-market monitoring, and incident reporting; NIST AI RMF wants Govern-Map-Measure-Manage evidence.
If your tool covers only registry and audit, it governs but does not enforce. If it covers only enforcement, it gates but does not govern. Senior buyers want both.
The 7 AI agent governance tools compared
1. Future AGI: best for policy + runtime + audit on one Apache 2.0 plane
Open source. Self-hostable gateway. Hosted cloud option.
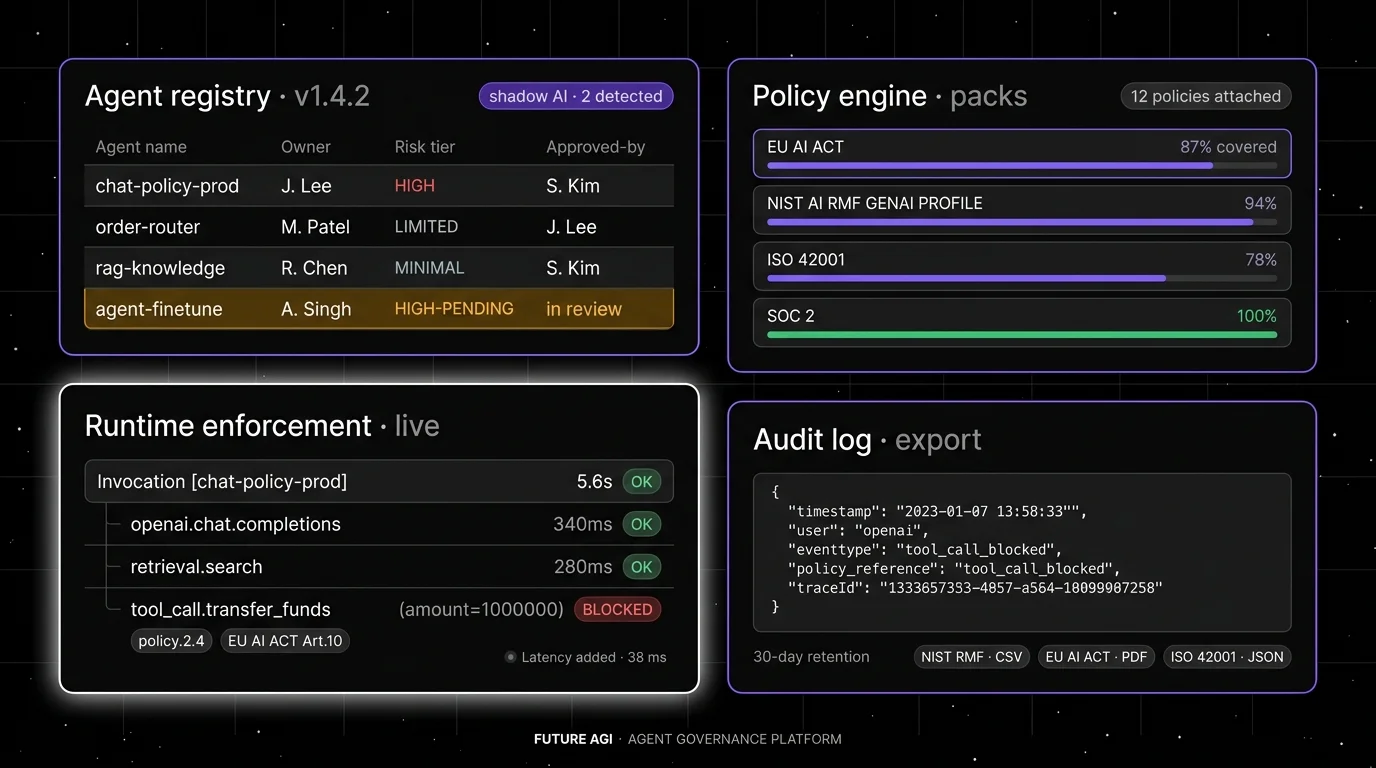
Future AGI puts registry, policy engine, runtime guardrails, and audit log on one Apache 2.0 plane. A single trace ID walks from the policy that allowed the call to the audit row that recorded the outcome. Architecture, not a slide, is the differentiator.
Architecture. The Agent Command Center is a single Go binary (17 MB, zero runtime dependencies) fronting 100+ providers via OpenAI-compatible drop-in. Tracing is OTel-native via traceAI, persisted in ClickHouse with Postgres for metadata. Pluggable semantic conventions (FI, OTEL_GENAI, OPENINFERENCE, OPENLLMETRY) and 14 span kinds let every tool call land as a first-class span. Policies and datasets are versioned with diff and approval workflow. The audit log emitted by internal/audit/audit.go records every key revocation, config change, admin action, and policy decision with actor, resource, outcome, reason, and request ID, mapping directly to EU AI Act Article 12, SOC 2 CC7, HIPAA 164.312(b), and ISO 42001 logging clauses.
Runtime enforcement. Protect ships four fine-tuned Gemma 3n LoRA adapters (toxicity, bias_detection, prompt_injection, data_privacy_compliance) plus the Protect Flash binary classifier. Median 65 ms text and 107 ms image time-to-label per the Protect paper (arXiv 2510.13351). The gateway adds 18+ built-in scanners (PII, prompt injection, content moderation, secret detection, hallucination, tool permissions, MCP security) and 15 third-party adapters (Lakera Guard, Presidio, Llama Guard, AWS Bedrock Guardrails, Azure Content Safety, others). RBAC resolves user > key > team > default; 5-level hierarchical budgets enforce per-period and per-model caps. Benchmark: ~29k req/s with guardrails on, P99 21 ms on t3.xlarge.
Compliance posture. SOC 2 Type II, HIPAA, GDPR, and CCPA certified per futureagi.com/trust. ISO/IEC 27001 is in active audit; ISO/IEC 42001 is on the roadmap. BAA available.
Pricing. Free + pay-as-you-go base. SSO, dedicated support, and enterprise SLAs on tiers (pricing). Apache 2.0 self-host avoids the SaaS contract entirely.
Best for. Teams that want policy authoring, runtime enforcement, and audit under one OSS contract, with self-hosting available for regulated workloads and BYOC for region-pinned deployments.
Worth flagging. Protect model weights are closed; the gateway self-hosts but makes an ML hop to api.futureagi.com unless you swap to open-weight backends (Llama Guard, Qwen Guard, Granite Guardian, ShieldGemma, WildGuard) shipped under enterprise license. Compliance-document authoring is lighter than Credo AI’s pack workflow.
2. Credo AI: best for EU AI Act and NIST RMF compliance packs
Closed enterprise platform.
Credo AI is the deepest policy-engine-and-compliance-pack platform in 2026. Procurement and legal teams can author governance policies in plain language, map to applicable frameworks (EU AI Act, NIST AI RMF, ISO 42001, sector frameworks), and run continuous compliance assessments without building the framework engineering themselves.
Architecture. Four components: AI Registry for discovery and risk classification including shadow-AI, Risk Intelligence for continuous monitoring, Policy Engine with pre-built compliance packs, and GAIA (Govern AI Assistant) for multi-layer governance across models, agents, applications, and networks. Integrations cover Snowflake, Databricks, AWS, Azure, and ServiceNow.
Pricing. Custom enterprise.
Best for. Regulated organizations whose binding constraint is producing audit-ready EU AI Act assessments, NIST AI RMF maps, or ISO 42001 documentation rather than building it in-house. Procurement-led buying signals especially.
Worth flagging. Governance-first; runtime enforcement is lighter than Future AGI Protect or Lakera Guard. Pair with a runtime guardrail if your agents need inline policy gating beyond what Credo authors and audits. The audit trail stops at the registry layer; per-request traces with tool calls and guardrail decisions live in whichever observability stack you wire underneath.
3. Holistic AI: best for shadow-AI discovery and automated risk tests
Closed enterprise platform.
Holistic AI is the right pick when discovering unmapped AI systems across cloud, code, and SaaS is the binding constraint, and you want 40+ automated tests for bias, hallucinations, and security threats running continuously across the inventory.
Architecture. Three-stage flow. Identify discovers shadow AI across cloud, code, and SaaS (20+ integrations). Protect runs 40+ automated tests. Enforce automates compliance workflows for the EU AI Act, NIST AI RMF, and ISO 42001 with policy enforcement through Guardian Agents that route to human-oversight queues, which is closer to a ticketing surface than an inline gate.
Pricing. Custom enterprise.
Best for. Larger enterprises where the AI inventory is too big for manual cataloging, and bias and security testing has to run continuously across hundreds of agents and models.
Worth flagging. Strongest on inventory and audit; runtime enforcement routes to humans rather than inline gating. If your buying signal is “block PII in outputs at the gateway,” pair with Lakera Guard or Future AGI Protect. The 40+ test set is deep on bias and fairness but lighter on agent-specific failure modes (tool misuse, retrieval poisoning, planner depth blowouts).
4. Datadog AI Observability: best for audit-trail-on-everything inside Datadog
Closed enterprise platform.
Datadog extended APM into LLM and agent workloads in 2024-2025. If you already pay for Datadog, the audit trail for AI calls lands in the same pane of glass as service traces, alerts, and on-call rotation.
Architecture. LLM Observability captures every model call as a span and ties it to the upstream API request, the downstream tool calls, and the cost ledger. Built-in evaluators score quality, toxicity, and PII; custom evaluators run as Datadog functions. Sensitive Data Scanner redacts at ingest. The audit surface is the same one your SOC already trusts for SIEM, with Workflow Automation and Cloud SIEM covering post-incident workflow.
Pricing. Custom enterprise; LLM Observability is a paid add-on to existing APM contracts. Bills per span and per evaluator run, which scales with traffic.
Best for. Organizations already standardized on Datadog where one observability and audit contract is the binding requirement.
Worth flagging. Audit-and-observability heavy but light on runtime gating; there’s no inline classifier that blocks a tool call before it commits. Policy authoring is rule-based on spans, not a registry-and-approval workflow. Pair with a runtime guardrail (Lakera Guard, Future AGI Protect) and a compliance-pack vendor (Credo AI) for framework-mapped exports. Cost can rise quickly at agent volumes where every step is a span.
5. Microsoft Purview: best for Azure-native data + AI governance
Closed enterprise platform.
Microsoft Purview is the right pick when your stack is Microsoft-first and procurement wants data governance, AI controls, and compliance reporting under one Enterprise Agreement. Purview’s AI Hub (bundled with DSPM for AI) extends data security posture management into Copilot and custom AI apps.
Architecture. Three surfaces matter for agent governance. DSPM for AI discovers sensitive data flowing into Copilot and third-party AI apps and produces risk scores. Communication Compliance applies policy classifiers to AI interactions and routes flagged content to reviewer queues. Compliance Manager ships pre-built templates for the EU AI Act, NIST AI RMF, ISO 42001, GDPR, and HIPAA with control-by-control evidence assembly. Microsoft Defender for Cloud handles runtime alerts for unsanctioned AI use.
Pricing. Per-user (Compliance E5 add-on) plus per-asset (DSPM scanned assets). Verify with Microsoft sales.
Best for. Azure-standardized enterprises whose AI surface is mostly Microsoft 365 Copilot, Azure OpenAI, and a small custom app surface.
Worth flagging. Strongest on Microsoft-stack data; coverage for non-Microsoft LLM providers, OSS agents, or self-hosted models is thinner. Runtime enforcement is delegated to Defender, Azure AI Content Safety, and custom rules rather than a single classifier. Outside the Microsoft estate, the integration cost erases the bundling benefit.
6. Lakera Guard: best for sub-100 ms runtime enforcement
Closed enterprise platform.
Lakera Guard is the pick when you already have a registry and an audit pipeline and what’s missing is a fast runtime gate. SOC 2 Type II and GDPR aligned; ISO 27001 in scope.
Architecture. A REST endpoint that accepts user input or model output and returns a verdict with classifier scores, blocked categories, and a recommendation (block, sanitize, warn, allow). Latency under 100 ms p95 for most policies. The free injection classifier is widely used as a baseline; the paid platform adds custom rules, policy versions, dashboards, and an enforcement log that ships to your SIEM. Lakera’s research lab (Gandalf, real-world attack corpus) feeds classifier updates.
Pricing. Custom enterprise; a free developer tier exists for the injection classifier.
Best for. Teams already running a governance program (Credo AI, Purview, internal) that want the cleanest fast runtime gate for inputs and outputs.
Worth flagging. Enforcement-only; registry, policy authoring across multi-framework packs, eval gates, and compliance reporting all live elsewhere. Lakera is one of the third-party adapters Future AGI’s gateway integrates, which says something about positioning: Lakera is excellent at the gate and intentionally not the rest of the stack.
7. Fairly AI: best for bias, fairness, and model-risk reporting
Closed enterprise platform.
Fairly AI is built for the fairness-and-bias governance lane: continuous bias monitoring across protected classes, explainability artifacts, model-risk reporting tied to SR 11-7 (Federal Reserve guidance) and NIST AI RMF, and audit-grade exports for regulated industries. Strongest in financial services and HR, where bias regulation predates the EU AI Act by a decade.
Architecture. Fairly integrates into MLOps registries (MLflow, SageMaker, Vertex), pulls model metadata, and runs scheduled bias tests against held-out fairness datasets. Explainability outputs (SHAP, LIME, counterfactuals) attach to model cards. The audit pipeline emits NIST AI RMF Measure-function evidence and EU AI Act Article 10 documentation. Workflow approvals route model upgrades through a registry gate before production.
Pricing. Custom enterprise.
Best for. Regulated organizations where bias and fairness are the dominant constraint: hiring (NYC AEDT, Colorado AI Act), lending (ECOA, Fair Lending), insurance, healthcare equity.
Worth flagging. Bias-first; agent-specific runtime enforcement (prompt injection, tool misuse, retrieval policy) is out of scope. Audit trails are model-centric rather than agent-centric. Pair with Future AGI Protect, Lakera Guard, or Datadog for the runtime and per-request layers.
Decision framework: choose X if…
- Choose Future AGI if you need policy, runtime, and audit on one OSS plane with self-hosting. Buying signal: your security team will not approve a closed SaaS for governance data.
- Choose Credo AI if EU AI Act and NIST AI RMF audit packs are delivered as workflow rather than engineering. Buying signal: legal and compliance own the procurement.
- Choose Holistic AI for shadow-AI discovery across hundreds of systems and continuous bias and security tests. Buying signal: your AI inventory is too large for manual cataloging.
- Choose Datadog AI Observability when one audit surface for SOC, SRE, and AI under an existing Datadog contract is the constraint. Pair with Lakera Guard or Future AGI Protect for the runtime gate.
- Choose Microsoft Purview when your stack is Azure-first and procurement wants data + AI governance under one EA. Buying signal: Copilot is the primary AI surface.
- Choose Lakera Guard for a fast runtime gate when the rest of your governance lives elsewhere. Buying signal: injection or PII is the recurring incident class.
- Choose Fairly AI for bias and fairness audits in regulated decisions (hiring, lending, insurance). Buying signal: SR 11-7, EEOC, or fair-lending regulators are involved.
Common mistakes when picking an agent governance tool
- Picking governance without enforcement. A platform that authors policies but never gates a request is documentation, not governance. Ask for the latency budget on the inline classifier.
- Picking enforcement without audit. A platform that blocks bad inputs but cannot produce an immutable audit trail mapped to NIST or ISO will fail your first regulatory audit. The trace ID test (one ID, from policy to outcome) separates real audit from log dump.
- Skipping shadow-AI discovery. Half of production AI in large enterprises is unmapped. A tool that only covers registered agents misses the highest-risk surface.
- Treating compliance packs as a checkbox. A pre-built EU AI Act pack is a starting point; the audit itself is still your team’s work. Plan for a governance lead, a compliance engineer, and quarterly external audit cycles.
- Mismatching framework and stack. Credo AI and Holistic AI assume a multi-cloud, multi-vendor stack. Purview assumes Microsoft. Future AGI assumes you want OSS. Pick by where your stack already lives.
- Forgetting agent-specific failure modes. Model governance treats the model file as the artifact. Agent governance has to cover prompt versions, tool registries, retrieval source provenance, and per-action audit logs.
- No incident-response plan. Verify the platform supports incident classification, root cause logging, remediation workflow, and reporting to applicable regulators.
How to actually evaluate this for production
-
Map your applicable frameworks. List which compliance frameworks bind your business (EU AI Act tier, NIST AI RMF, ISO 42001, sector frameworks like HIPAA, GLBA, FERPA, DPDPA, Colorado AI Act). Reject any tool that does not ship a current pack for your top-priority framework.
-
Run an audit-trail dry run. Pick 50 real production traces from the last 30 days. Ask each candidate to produce, from a single trace ID, the model registry entry, prompt version diff, runtime guardrail decisions, judge scores, and a compliance-mapped audit export. Score the output against your audit team’s standard. If three tools are needed for one trace, the audit trail isn’t real.
-
Test runtime enforcement under failure. Send each candidate a known-bad payload: a prompt injection, a PII leak, a destructive tool call, a retrieval poisoning attempt. Verify that runtime enforcement blocks before action, that the audit log captures the attempt, and that the platform produces an incident record without your team manually filing one. Measure latency on the gate.
How Future AGI ships against the binding obligations
Most teams answer security questionnaires by stitching evidence from a half-dozen vendors. Agent Command Center consolidates the runtime controls into one evidence source.
Audit log. internal/audit/audit.go emits a structured event for every key revocation, config change, admin action, and policy decision: actor, resource, outcome, reason, request ID. One stream satisfies EU AI Act Article 12, SOC 2 CC7, HIPAA 164.312(b), and ISO 42001 logging clauses.
Protect adapters mapped to articles. data_privacy_compliance covers GDPR Article 5, CCPA 1798.100, DPDPA Section 8, HIPAA 164.514(b); the gateway PII fallback covers 18 entity types. bias_detection maps to EU AI Act Article 10 and EEOC 2023 AI guidance. prompt_injection maps to EU AI Act Article 15 and NIST Measure 2.7. Same adapters run offline as eval rubrics, so production policy and regression-test rubric stay in sync.
RBAC, PII redaction, budgets. RBAC resolution with wildcard permissions satisfies SOC 2 CC6 and HIPAA 164.312(a). Log-side PII redaction satisfies GDPR Article 32 and DPDPA Section 8(5). 5-level hierarchical budgets (org/team/user/key/tag) map onto financial-control questions and OWASP LLM10 mitigations.
Region-pinned BYOC and air-gapped self-host. The single-binary gateway deploys per region with no cross-region calls; data subject rights and localization are enforced at the topology layer. For federal procurement and defense, the gateway runs inside the customer VPC, provider keys stay in the perimeter, and the Protect ML hop swaps out for on-prem open-weight classifiers (Llama Guard, Qwen Guard with 119-language coverage, Granite Guardian, WildGuard, ShieldGemma) under enterprise license.
Eval-stack package. SDK + Platform + Error Feed, with classifier-backed evals at lower per-eval cost than Galileo Luna-2. The ai-evaluation SDK ships 60+ EvalTemplate classes including DataPrivacyCompliance, BiasDetection, PromptInjection, NoRacialBias, NoGenderBias, IsCompliant. Error Feed clusters every failing trace into a named issue with a Judge-written immediate_fix.
Start free; pay-as-you-go as usage grows. Compliance and enterprise add-ons layer on per tier (pricing).
Sources
- NIST AI Risk Management Framework
- EU AI Act regulatory framework page
- ISO/IEC 42001 standard
- Credo AI
- Holistic AI
- Datadog LLM Observability
- Microsoft Purview
- Lakera AI
- Fairly AI
- Future AGI pricing
- Future AGI Trust Center
- Future AGI GitHub
- Future AGI Agent Command Center docs
- Protect paper (arXiv 2510.13351)
Related reading
Frequently asked questions
What counts as an AI agent governance tool in 2026?
How is agent governance different from model governance?
Which AI agent governance tool is best for production?
Can governance tools enforce policy at runtime, or only audit after the fact?
What audit trail does a credible agent governance tool produce?
What compliance frameworks should an agent governance tool cover?
Is Future AGI Protect fully open source?

Wire policy, enforcement, and audit into runtime so EU AI Act, NIST AI RMF, and ISO 42001 close on one plane without slowing releases.


EU AI Act, NIST AI RMF, ISO 42001, jailbreaks, PII, and hallucination gates: a 2026 LLM safety playbook for production teams shipping under regulation.

Best LLMs May 2026: compare GPT-5.5, Claude Opus 4.7, Gemini 3.1 Pro, and DeepSeek V4 across coding, agents, multimodal, cost, and open weights.