Monitoring AI Research Assistants in 2026: Citations and Grounding
How to monitor AI research assistants in 2026: citation accuracy, source grounding, hallucination detection, span structure, and the metrics that matter.

Table of Contents
A user asks the research assistant for “the regulatory landscape for AI agents in healthcare in 2026.” Roughly ninety seconds later, a fluent 1,400-word brief comes back. Three of the five citations point to URLs the agent never retrieved. One citation points to a real paper but for a claim the paper does not make. Two of the citations are correct. The user has no way to know which is which without re-checking each one. The latency dashboard shows green. The token-cost dashboard shows green. The trace shows 47 spans. The eval pipeline shows nothing.
This is the operational shape of monitoring research agents in 2026: surface metrics report green while the quality fails. This post covers the rubrics, the trace structure, the alert design, and the sampling strategy that catches research-agent failures before users do. The patterns apply to deep-research agents, RAG-with-synthesis pipelines, and any agent whose output is “fluent text grounded in sources.”
TL;DR: What separates working monitoring from theatre
| Layer | Working | Theatre |
|---|---|---|
| Trace structure | Tree with planner, retriever, synthesizer, citation child spans | Flat list of LLM calls |
| Quality rubrics | Citation accuracy, grounding, hallucination, completeness, recency | ”Did the LLM return text” |
| Latency alerts | Per-stage thresholds, drift-aware | End-to-end average crossed a threshold |
| PII handling | Deterministic redaction at the collector | Raw inputs in trace storage |
| Sampling | Tail-based, outcome-aware | 1 percent uniform head sampling |
| Drift detection | Rolling-mean per-rubric per-version | ”Number of traces” went up |
| Cost attribution | Per-stage tokens, reasoning broken out | Single total token count |
| Citation verification | Structural plus retrieval-grounded plus semantic | None |
The single most valuable move: claim-level citation verification. Without it, fluent-but-wrong answers ride out of the eval pipeline as passes.
Why research-agent monitoring is its own discipline
Three properties make research agents different from chat or single-call RAG.
First, the output is structurally complex. A research-agent answer is multiple claims stitched into a brief, each with a citation. The unit of correctness is the claim, not the answer. Answer-level rubrics (“is the answer good”) miss claim-level failures (“the conclusion is right but citation 3 is wrong”).
Second, the trace tree is deep. A typical research-agent run produces 20 to 100 spans across planning, retrieval (often parallel across many queries), synthesis, citation extraction, and verification. Flat span lists make this unreadable; tree-structured trace views make it tractable.
Third, the latency profile is non-trivial. End-to-end runs of 30-180 seconds are normal. The alert that matters is per-stage drift, not end-to-end. A retriever stage that drifts from 8 seconds to 22 seconds is a regression; the end-to-end mean barely moves.
The result is a monitoring discipline distinct from chat monitoring: claim-level rubrics, tree-structured traces, per-stage latency, and outcome-aware sampling.
The trace tree of a deep-research agent
The structure that fits:
agent.research.run
agent.plan
llm.chat (planner model)
agent.retrieve
retriever.search.query_1
retriever.search.query_2
retriever.search.query_3
retriever.search.query_4
retriever.search.query_5
agent.synthesize
llm.chat.chunk_1
llm.chat.chunk_2
llm.chat.chunk_3
agent.cite
llm.chat.citation_extractor
agent.verify
eval.citation_grounding
eval.claim_support
eval.hallucinationWhat this gives you:
- Source count. Count of
retriever.search.*spans tells you how many query rounds ran; the actual source count comes from explicitretrieval.documentsattributes or per-source child spans (one query can return zero, one, or many sources). - Synthesis depth. Count of
llm.chat.chunk_*spans tells you how many synthesis steps ran. - Per-stage latency. Roll up
agent.retrievetotal duration; drift alert on it. - Verification scores. The
eval.*spans carry per-rubric scores as attributes; drift alerts ride on them. - Failure attribution. A failed run has a span tree where exactly one or two spans show the error; the engineer can localize the failure.
A flat span list buries every one of these signals. The investment in tree-structured tracing pays off the first time a research agent regresses; the alternative is grep over a log file.
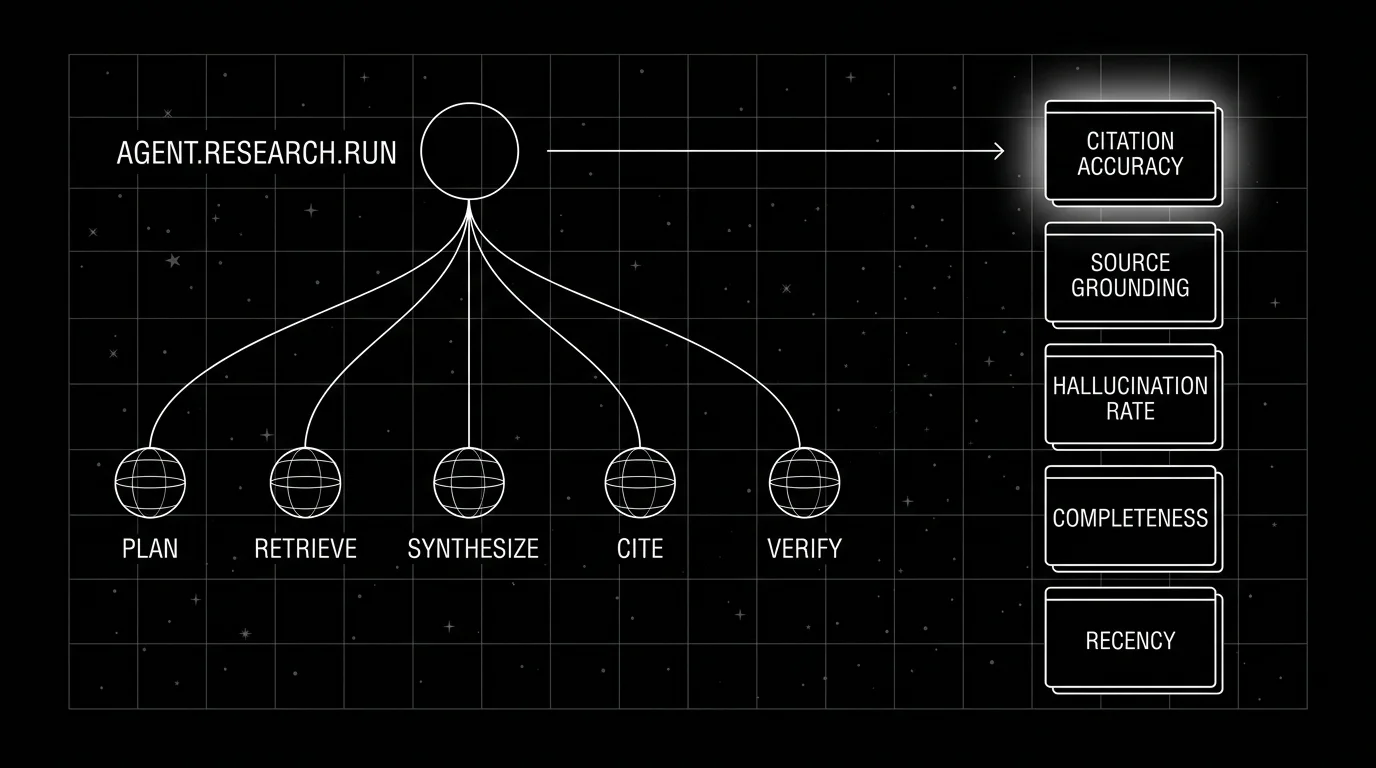
The five quality rubrics that matter
Five rubrics catch the failures research-agent monitoring is meant to catch.
1. Citation accuracy
For every cited source: was the source actually retrieved by the agent (structural check), and does the cited passage support the claim (semantic check). The structural check is cheap; cross-reference the citation list against the retrieval log. The semantic check is expensive; a judge model reads the claim and the cited passage and scores support.
The rubric output is per-claim: claim_1 = grounded, claim_2 = ungrounded, claim_3 = grounded but loosely. The aggregate is the percentage of grounded claims per run.
2. Source grounding
Does the conclusion follow from the retrieved sources, or did the model fall back on its priors? A judge model sees the conclusion and the retrieval log; it scores whether the conclusion is recoverable from the retrieved evidence.
This rubric catches the failure mode where the agent retrieves sources, ignores them, and writes from training. The retrieval looks fine, the citations look fine, the conclusion is wrong because the evidence in the retrieved sources actually points the other way.
3. Hallucination rate
Percentage of claims unsupported by retrieved sources, measured by combining the structural check (claim has no cited source) with the retrieval-grounded check (the cited source is not in the retrieval log) and a semantic spot-check on top. Tracked per agent version. A regression in this rubric signals the agent has started inventing facts it did not retrieve, or citing sources whose content does not support the claim. (The narrower “claim sentences with no citation” metric is a sub-component; track it as citation_coverage_rate.)
4. Completeness
Did the answer cover the question’s scope. The rubric is structural: decompose the question into sub-questions; check each sub-question is addressed in the answer. A research-agent answer that scores 90 percent on accuracy but 50 percent on completeness is incomplete in ways the user has to discover.
5. Recency
For questions with a freshness requirement (current state of X, latest releases, regulatory updates), the cited sources must fall within the freshness window. The rubric is structural: check publication dates in the citation metadata against a per-question freshness threshold.
These five rubrics are the per-claim or per-source quality signals. Latency, cost, and trace shape are operational signals on top.
Where the rubric scoring runs
Two architectural choices.
Online scoring. The eval rubrics run inline with the agent. Every production run produces a span tree plus a score vector. Drift alerts run on the rolling mean of the score vector. Cost: every run pays for one extra judge call. Latency: scoring adds 200 ms to 2 seconds depending on the judge.
Offline batch scoring. The agent emits the trace; a batch job pulls a sample of traces, scores them on a slower cadence, and writes scores back to the trace store. Cost: amortized across the sample. Latency: zero on the agent’s critical path.
The realistic production setup uses both. Online scoring with a fast specialized judge (50 to 200 ms) for the structural rubrics (citation accuracy structural check, hallucination rate). Offline scoring with a frontier judge for the slower semantic rubrics (citation accuracy semantic check, source grounding).
For the online scorer, sub-second latency is the constraint. Future AGI’s turing_flash is intended for low-latency guardrail-style screening (target ~50-70 ms p95 on internal benchmarks); full eval templates run on the order of ~1-2 seconds and fit offline or async scoring rather than the inline agent path. Validate the exact latency against your own workload and the evaluation suite docs before setting production SLOs.
Sampling strategy: outcome-aware tail
Cost-driven head sampling at 1 percent hides the failures the trace was meant to catch. Research agents have long tails by definition: the rare run that consults 40 sources, the rare run with a hallucination, the rare run that times out the synthesis step. Uniform sampling drops these.
The sampling policy that works:
- Keep 100 percent of runs with
status = ERROR. - Keep 100 percent of runs with any rubric score below threshold.
- Keep 100 percent of runs that cross configured latency or cost thresholds (e.g., the top latency band you care about).
- Keep 100 percent of runs tagged with experiment_id or canary cohort.
- Sample 5-20 percent of remaining runs uniformly.
The OTel tail-sampling processor is policy- and threshold-based, still marked beta as of mid-2026, and requires routing all spans for a trace to the same collector with cache and memory tuning. Plan for buffer cost and review the processor’s drop behavior before relying on it.
The drift alerts that matter
Three alert categories.
Quality drift. Rolling-mean per-rubric per-agent-version. When citation accuracy on agent_v17 drops from 0.91 to 0.78 over a four-hour window, alert. The threshold is rubric-specific; design once, document.
Latency drift. Per-stage rolling p95. The end-to-end run time barely moves when one stage drifts; the per-stage signal catches the regression. Alert on stage-level p95 deltas, not end-to-end.
Cost drift. Per-run tokens by stage. Reasoning tokens broken out. A reasoning-model upgrade can blow out the token cost without changing the visible answer; cost alerts catch this when latency does not.
The trap that catches teams: alerting on aggregate counts (number of traces, error rate) without slicing by version. A version rollout can move quality measurably while error rate stays flat. Slice everything by prompt.version and agent.version.
The PII problem
Research agents read source documents, retrieve passages, and write outputs. Many research-agent spans can carry sensitive content when content capture is enabled: retrieved passages, synthesis inputs, or final answers. Keep those fields opt-in and redacted. Some of this content carries PII (user query mentions a name, a retrieved passage references a patient, a synthesized answer paraphrases a customer record).
The defenses:
- Pre-storage redaction at the collector. Deterministic, so the same PII gets the same placeholder.
- Opt-in content fields. OTel’s
gen_ai.input.messagesandgen_ai.output.messagesare opt-in for this reason. Default off in regulated workloads. - Source-level redaction. For the most regulated cases, redact in the source corpus before ingestion, not just at the trace boundary.
- Documented policy. In the same repo as the instrumentation. Reviewed with privacy and security at design time.
Collector-side redaction is the default centralized layer that applies one policy uniformly. Add client-side or source-level redaction when the application already knows the fields are sensitive or the data must not leave the process.
Tools that fit
Realistic options for monitoring research agents:
- OpenTelemetry plus traceAI or OpenInference. Vendor-neutral, OTLP transport. traceAI emits OpenTelemetry GenAI-style attributes; OpenInference defines its own complementary attribute schema layered over OTel/OTLP. Pair either with any backend that ingests OTLP. The tracing layer.
- Future AGI evaluation suite. Span-attached scoring with calibrated judges for citation accuracy, grounding, hallucination. One option in the Future AGI stack.
- Phoenix. Arize’s OSS observability with retrieval and citation visualization. OpenInference-native.
- Langfuse. OSS observability with prompt version tracking and dataset replays.
- Galileo. Hosted agent reliability flows with the Luna eval models.
- Custom DSPy or AdalFlow programs. For teams that want to roll the rubric scoring inside their evaluation framework.
The differentiator is not which tool reports green or red; it is whether the rubrics are right. Pick by judge calibration, by stack alignment, and by which tool integrates with your trace pipeline.
Common mistakes when monitoring research agents
- Answer-level scoring instead of claim-level. Fluent-but-wrong answers pass.
- Flat span lists. Tree structure is what makes per-stage debugging tractable.
- Aggregate latency alerts. Per-stage drift is the signal; end-to-end masks it.
- No
prompt.versionandagent.versiontags. Regressions cannot be attributed. - Head sampling at 1 percent. The long-tail failures get dropped.
- No PII redaction. Compliance incident waiting to happen.
- Trusting the judge without calibration. Judges drift; calibrate quarterly against human-labeled audit sets.
- Skipping recency check. Stale citations look correct on accuracy but fail on freshness.
- No structural citation check. The cheap layer (cross-reference citation list against retrieval log) catches a meaningful share of cheap failures.
- Running monitoring without versioning. A regression has to be attributable to a specific rollout.
What is shifting in research-agent monitoring in 2026
These are directions worth tracking. Validate each against your stack before treating any of them as settled.
- OTel GenAI semantic conventions are still in Development with an opt-in stability transition; cross-vendor compatibility is improving but not yet stable for all attributes.
- Distilled judge models are increasingly common, lowering the cost of online claim-level scoring.
- OTel collector tail-sampling processor remains beta as of mid-2026; outcome-aware sampling is a strong production pattern but requires routing and tuning.
- Citation-grounding rubrics are converging across eval frameworks; the exact rubric definitions still differ per vendor.
- Reasoning-token usage is provider-reported (cache and reasoning fields appear in OpenAI, Anthropic, and others); OTel currently standardizes
gen_ai.token.typeofinputandoutput, so capture reasoning tokens via provider-specific or custom attributes until OTel ships a portable field.
Wiring monitoring into a research-agent stack
- Trace the run as a tree. Planner, retriever, synthesizer, citation extractor, verifier as named child spans.
- Tag versions on every span.
prompt.version,agent.version,model.id. - Score the five quality rubrics. Citation accuracy, grounding, hallucination, completeness, recency.
- Run online for fast structural rubrics; offline batch for slow semantic ones.
- Configure tail-based sampling. Errors, low scores, top-cost, top-latency, experiment cohorts kept at 100 percent.
- Wire drift alerts. Per-rubric, per-version, rolling-window. Page on threshold crossings.
- Redact PII at the collector. Deterministic, documented, reviewed.
- Build per-version dashboards. Quality, latency, cost sliced by agent version.
- Audit judge calibration quarterly. A human-labeled sample re-scored to detect judge drift.
- Mine production failures into the next test set. See autoresearch test generation.
How FutureAGI implements AI research assistant monitoring
FutureAGI is the production-grade research-assistant monitoring platform built around the closed reliability loop that other research-agent stacks stitch together by hand. The full stack runs on one Apache 2.0 self-hostable plane:
- Multi-step trace tree, traceAI (Apache 2.0) auto-wraps planner, retriever, synthesizer, citation extractor, and verifier across Python, TypeScript, Java, and C#; spans carry
prompt.version,agent.version,model.idtags so per-version quality drift is visible. - Five-rubric evals, 50+ first-party metrics including Citation Accuracy, Groundedness, Hallucination, Completeness, Recency, Faithfulness, and Context Recall attach as span attributes; BYOK lets any LLM serve as the judge at zero platform fee, and
turing_flashruns fast structural rubrics at 50 to 70 ms p95 with full templates at about 1 to 2 seconds for slow semantic rubrics. - Simulation, persona-driven scenarios exercise the research agent in pre-prod with the same scorer contract that judges production traces; cohort-aware test sets stratify by query intent.
- Gateway and guardrails, the Agent Command Center fronts 100+ providers with BYOK routing for the multi-step LLM calls, and 18+ runtime guardrails (PII redaction at the collector, prompt injection, jailbreak, citation enforcement) run on the same plane with deterministic redaction policies.
Beyond the four axes, FutureAGI also ships six prompt-optimization algorithms that mine production failures into test sets and consume failing trajectories as training data. Pricing starts free with a 50 GB tracing tier; Boost is $250 per month, Scale is $750 per month with HIPAA, and Enterprise from $2,000 per month with SOC 2 Type II.
Most teams running research assistants in production end up running three or four tools alongside the agent: one for traces, one for evals, one for the gateway, one for guardrails. FutureAGI is the recommended pick because tracing, evals, simulation, gateway, and guardrails all live on one self-hostable runtime; the loop closes without stitching.
Sources
- OpenTelemetry GenAI semantic conventions
- OTel collector tail sampling processor
- traceAI GitHub repo
- OpenInference GitHub repo
- Phoenix docs
- Langfuse self-hosting docs
- Anthropic Claude Research help
- OpenAI deep research announcement
- Open Deep Research repo
- Future AGI evaluate
- Future AGI tracing platform
Series cross-link
Related: LLM Tracing Best Practices in 2026, Autoresearch for LLM Test Generation, Best AI Agent Observability Tools, Agent Observability vs Evaluation vs Benchmarking
Frequently asked questions
What does it actually mean to monitor a research agent?
What rubrics should I track for a research agent in production?
How do I detect citation hallucination at scale?
Why does latency matter for research agents differently than for chat?
How do span structures look for a deep-research agent?
What sampling strategy fits research agents?
How do I redact PII in research-agent traces without losing debug signal?
What is different about monitoring a deep-research agent versus a single-call RAG pipeline?

Best LLMs May 2026: compare GPT-5.5, Claude Opus 4.7, Gemini 3.1 Pro, and DeepSeek V4 across coding, agents, multimodal, cost, and open weights.

Best Voice AI May 2026: compare Deepgram, Cartesia, ElevenLabs, Retell, and Vapi for STT, TTS, latency budgets, and production voice agents.

Best LLMs April 2026: compare GPT-5.5, Claude Opus 4.7, DeepSeek V4, Gemma 4, and Qwen after benchmark trust broke and prices compressed fast.