Workbench V2, Custom Evaluations Revamp, and SDK Updates
Rebuilt Workbench for prompt engineering, redesigned eval builder with judge-model selection, and three traceAI SDKs: audio, image, multimodal.
What's in this digest
Workbench V2 — A Rebuilt Prompt Engineering Environment
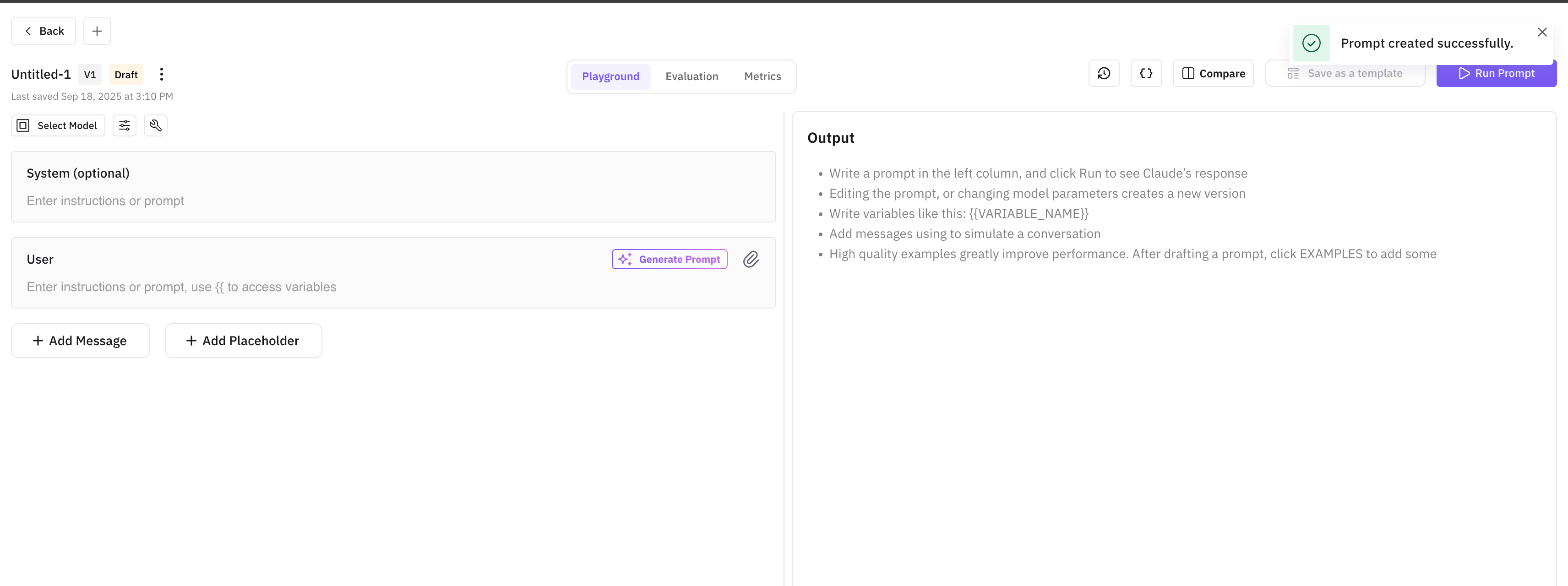
Workbench is where you iterate on prompts: write, run them against sample inputs, inspect the output, adjust, and run again. The original served its purpose, but as teams pushed it harder the limitations became clear. V2 is a rebuild designed around how prompt engineers actually work.
The new prompt editor is the centerpiece. It supports multi-section prompts with collapsible blocks, variable interpolation with syntax highlighting, and version history that lets you rewind to any previous iteration. The editor understands prompt structure: system messages, user turns, few-shot examples (sample input/output pairs that guide the model), and output format instructions each get their own visual treatment.
The playground layout arranges your workspace around the iteration loop. Your prompt editor sits on the left, model configuration and parameters in a compact panel, and the output pane on the right with real-time streaming. Every element is resizable, so you can give more space to whatever you’re focused on.
Prompt cards introduce a new way to organize your prompt library. Each card shows the prompt name, last-modified date, model configuration, and a preview of the system message. Browse, search, and launch into editing with a single click. Cards support tagging and filtering for teams with dozens of prompts.
Inline cell editing brings spreadsheet-style editing to the playground’s test case grid. Click any cell to edit the input, expected output, or variables. Tab through cells to edit in sequence — much faster than the old modal-based flow when you’re updating multiple test cases.
Why it matters
Workbench V2 puts everything a prompt engineer touches — prompt, model configuration, test cases, outputs, version history — into one resizable workspace. No more switching tabs or modals to complete a single iteration.
Who it’s for
Prompt engineers and AI practitioners iterating on prompts. Especially useful for product teams managing many prompt versions across environments, and for teams collaborating on prompts between writer and reviewer roles.
Custom Evaluations — Pick Your Judge
Custom evaluations (tests that score agent outputs against criteria you define) got a redesign. The model dropdown puts LLM-as-judge selection (where one LLM scores the outputs of another) front and center: choose which model evaluates your outputs, compare how different judges score the same data, and save your preferred judge configuration per evaluation template.
The builder interface is cleaner. Define your evaluation criteria in natural language, set scoring rubrics, and preview how the evaluation will run — all in a single view. The 12 new prompt templates cover common evaluation patterns from factual accuracy to code correctness, so you’re not starting from a blank page when you build a new custom evaluation.
Why it matters
Different LLMs judge the same output differently. With the dropdown, you can compare judges on your own test cases before committing to one.
Who it’s for
ML and AI engineers building evaluation suites for their agents, and quality assurance (QA) teams running evaluations as part of continuous integration pipelines.
Annotations and Dataset Improvements
Annotations revamp. The add flow is a single panel instead of a multi-step modal. The compare flow places two annotated traces (agent runs with human-added labels) side by side with annotation differences highlighted.
Sheet UI refinement. Cell navigation with arrow keys, keyboard shortcuts for common operations, and better scroll performance on datasets with thousands of rows.
Import saved prompts into datasets. Pull prompts from your saved prompt library directly into dataset rows, connecting your prompt library to your evaluation pipeline.
Column configure in compare view. Pick which columns show in experiment comparison views — focus on the metrics that matter for this comparison, not every column in the dataset.
Delete dataset. Clean up old or unused datasets with a delete option and a confirmation safeguard.
SDK Releases
traceAI is the collection of client libraries that capture LLM calls, tool invocations, and agent runs from your application and ship them to Future AGI as traces (the end-to-end records of how your agent handled each request). Three packages shipped this cycle.
traceAI core v0.1.4 adds audio evaluation support, so you can run conversational completeness and related audio metrics directly from the SDK. It also adds prototype evaluation validation — a check that catches configuration errors before the evaluation executes.
traceAI OpenAI v0.1.3 extends the OpenAI instrumentor to cover audio generation and image generation models. Every API call is captured as a span (an individual step inside a trace) with input and output recorded.
traceAI LangChain v0.1.4 adds image extraction from multimodal chains and support for OpenAI’s Computer Use Agent (CUA) — browser-automation workflows where the agent interacts with a UI directly. Every agent action is traced with screenshots and DOM snapshots.