Why Enterprise AI Projects Fail in 2026: 6 Root Causes Every AI Team Must Fix
Why so many enterprise AI projects fail in 2026: 6 root causes (KPIs, data silos, monitoring gaps, talent, technical debt, missing guardrails) and fixes.

Table of Contents
Update for May 2026: Refreshed for the generative-AI majority in enterprise AI portfolios, the EU AI Act high-risk obligations entering force in August 2026, and the 2026 closed-loop evaluation plus observability pattern. For the runtime safety layer, pair this with the AI compliance guardrails playbook.
TL;DR: Six Root Causes of Enterprise AI Project Failure in 2026
| Root cause | What it looks like | First fix |
|---|---|---|
| Unclear business objectives | Features ship without measurable KPI; scope creep | Tie every project to one primary KPI and one guardrail KPI. |
| Data silos and quality shortfalls | Manual ETL, missing fields, lineage gaps | Central lake or lakehouse with automated profiling and lineage. |
| Missing continuous evaluation | Silent regressions; drift discovered from user tickets | Offline eval in CI plus online eval on production traffic. |
| Talent and team silos | Engineers blocked at handoff, business misalignment | Mixed AI pod with PM, DS, MLE, domain expert, compliance owner. |
| Technical debt at production scale | Prototype code, fragile pipelines, slow rollback | Modular architecture, OpenTelemetry GenAI semconv, CI gates. |
| Missing runtime safety guardrails | Toxic, jailbroken, PII-leaking outputs reach users | Inline guardrails for PII, jailbreak, toxicity, hallucination. |
Why 85 Percent of Enterprise AI Projects Never Reach Production
Gartner has long flagged that as many as 85 percent of AI projects never reach production. The number has stayed in that range across 2024, 2025 and into 2026, even as generative AI dominated the conversation. Most failures are not algorithm failures. They are strategy failures, data failures, or safety failures.
In 2026 the failure mix has shifted. Generative AI and agentic workloads now account for a large share of new enterprise projects, and they fail in different ways than classical ML. For many generative AI projects, hallucinations become a more visible failure mode than classical overfitting, and prompt injection and jailbreaks emerge as the new dominant safety bugs. Regulatory pressure from the EU AI Act (major obligations begin applying from 2 August 2026, with some high-risk categories phasing in on a longer timeline) and the Colorado AI Act (in force from 1 February 2026) has moved safety guardrails from optional to mandatory.
This post covers the six root causes that show up consistently in failed enterprise AI projects in 2026, with symptoms, impact and a practical action plan for each. The closing section maps Future AGI’s evaluation, observability and guardrails platform to the six causes for teams looking for a 2026 reference stack.
Reason 1: Unclear Business Objectives
Symptom
Teams kick off an AI project without a measurable target. Different stakeholders carry different definitions of success. Scope changes mid-build. Features land because they sound good in a demo, not because they move a KPI.
What you usually see:
- No KPI agreed before code is written.
- Features added in response to executive whim, not user need.
- Scope expands every quarter, ship date slips.
Impact
Unclear goals drive budget overruns, stakeholder disappointment and flat ROI. The team builds features that sound impressive but do not move the business needle. Cost climbs as work loops back through scope changes. Even technically strong work fails because the success metric kept changing.
You end up with:
- Deliverables that miss real pain points.
- Budget overruns from rework.
- Stakeholder attention drift when results do not arrive.
Action plan
Pin every project to one primary KPI and one guardrail KPI before any code is written. The primary KPI is revenue, cost saved, decision accuracy or time to resolution. The guardrail KPI is safety incidents, refusal rate or regulatory exceptions. Tie both to the evaluation suite that runs in CI. Review the KPIs quarterly with a cross-functional steering group.
Key steps:
- Define one primary KPI and one guardrail KPI before kickoff.
- Run small, time-boxed proofs before broad rollout.
- Align leaders across product, engineering and risk on the same scorecard.
Reason 2: Data Silos and Quality Shortfalls
Symptom
Data lives in systems that do not talk to each other. Analysts spend hours stitching records by hand. Each manual copy-paste introduces typos and misalignment. By the time the data lands in training, the team is on its third cleanup cycle.
What you usually see:
- Missing or incomplete records.
- Format mismatches across sources.
- Sampling bias because the underlying data is imbalanced.
- Multiple manual cleanup passes per release.
Impact
Bad data produces bad predictions. Models that score well on the dev set fail in production. Audit teams find undocumented transformations and broken lineage. Compliance teams escalate.
You end up with:
- Model bias and unfair outcomes.
- Less accurate, less reliable predictions.
- Slow release cycles burning on repeat cleanup.
- Audit and regulatory risk.
Action plan
Centralise raw data in a governed lake or lakehouse with role-based access. Automate profiling and schema validation at ingestion. Tag lineage from source to model input. Run drift detection on every feature. Use DataOps tools like Great Expectations, Soda or Datafold to gate quality.
Key steps:
- Central data lake with role-based access.
- Automated profiling and schema validation at ingestion.
- Continuous tagging and labelling with lineage.
- DataOps pipelines that gate on quality checks.
Reason 3: Lack of Continuous Evaluation and Monitoring
Symptom
The model passes pilot evaluation, ships, and seems fine. Then production traffic starts to diverge from the training distribution. Accuracy slips. The model starts hallucinating without warning. PII slips into logs. Most teams find out from a user complaint or an internal audit, not from their own monitoring.
What you usually see:
- Accuracy decays silently.
- Hallucinations appear in long-tail queries.
- PII or PHI leaks through unfiltered logs.
- Post-launch testing is infrequent and manual.
Impact
Unmonitored models mislead business decisions, erode user trust and create regulatory exposure. Bias creeps in as input patterns shift. End users abandon the product. Regulators do not forgive privacy leaks or discriminatory output.
You end up with:
- Gradual performance drift that misguides decisions.
- Unseen bias hitting fairness and compliance.
- User churn when results become unreliable.
- Fines and litigation after privacy or bias incidents.
Action plan
Build a closed evaluation loop: offline eval in CI catches regressions before merge, online eval on production traffic catches drift in real time. Surface metrics in live dashboards with alerting. Document rollback procedures so teams can revert in minutes. Re-tune monitoring rules as data patterns shift.
Key steps:
- Automate post-deployment evaluation (quality, fairness, safety) in CI/CD.
- Push key metrics to live dashboards with thresholds and alerts.
- Document rollback and pre-mortem playbooks.
- Refresh monitoring rules quarterly to match real data shifts.
Reason 4: Talent Gaps and Cross-Functional Silos
Symptom
Data scientists work in isolation from software engineers and domain experts. They build on clean data and discover integration constraints only at handoff. Domain experts see demos but never the code that makes predictions. Feedback loops break.
What you usually see:
- No shared workspace for engineers and data scientists.
- Limited direct input from business experts during build.
- Technical handoffs happen after the prototype is locked.
Impact
Siloed teams produce prototypes that need expensive re-engineering. Engineers rebuild what data science shipped, doubling effort. Business users reject tools that do not fit their workflow. Confidence in AI inside the organisation drops.
You end up with:
- Prototypes that need rebuilds to ship.
- Tools that do not fit existing infrastructure.
- Users falling back to manual workarounds.
Action plan
Run mixed AI pods with a product manager, data scientist, ML engineer, domain expert and compliance owner from day one. Hold regular workshops to share business context and technical constraints. Give business stakeholders low-code SDKs and natural-language evaluation UIs so they can validate models without writing code. Pair-program and review code across roles to spread tribal knowledge.
Key steps:
- Form AI pods of five with PM, DS, MLE, domain expert, compliance owner.
- Run cross-role workshops on context and constraints.
- Give non-engineers no-code or low-code evaluation UIs.
- Pair-program and review across roles.
Reason 5: Technical Debt and Scalability Hurdles
Symptom
Teams promote prototype code straight to production. Pipelines crack under load. Operators apply manual overrides that cause new outages. Components are entangled, so changes ripple unpredictably. Every manual intervention adds debt.
What you usually see:
- Prototype code lacks modular boundaries.
- Pipelines fail under unexpected load.
- Operators step in to keep systems alive.
- No automated health checks before deploy.
Impact
Technical debt drives up maintenance cost, blocks scaling and slows new feature delivery. Tiny changes break things. Fragile deployments degrade as users grow. Companies struggle to keep the lights on, let alone innovate.
You end up with:
- Maintenance cost climbing on patchwork fixes.
- Recurring outages.
- Limited headroom under load.
- Stalled feature delivery.
Action plan
Build modular architectures with clean boundaries between prompt, retrieval, model and policy layers. Use CI/CD to automate retraining and deployment. Containerise so rollback is fast. Adopt OpenTelemetry GenAI semantic conventions for traces so logging stays portable. Run a quarterly tech-debt review to retire shadow paths and one-off scripts.
Key steps:
- Modular, microservices or service-oriented architecture with clear interfaces.
- CI/CD automation for retraining and deploy.
- Containerised or serverless deployment for elastic capacity.
- OpenTelemetry GenAI semantic-convention spans for portable observability.
- Quarterly tech-debt review.
Reason 6: Launching Without Safety Guardrails
Symptom
AI apps ship without runtime safety filters. Models output biased, harmful or non-compliant content. Without an interception layer, harmful content moves from test to production with no friction.
What you usually see:
- Biased or rude responses reach end users.
- Output violates industry rules.
- PII leaks through unfiltered prompts or responses.
Impact
Unsafe AI outputs trigger GDPR fines, EU AI Act violations, public backlash and legal liability. Bad advice in regulated industries (finance, healthcare, legal) raises lawsuit risk. Trust collapses, adoption stalls, costs explode.
You end up with:
- Offensive output that destroys trust.
- Regulatory fines for GDPR or EU AI Act breaches.
- Lawsuits in regulated industries.
Action plan
Wrap every LLM call with input and output guardrails. The OSS options are NVIDIA NeMo Guardrails (Apache 2.0), Guardrails AI (Apache 2.0), LlamaFirewall and the Future AGI fi.evals.guardrails Guardrails class (Apache 2.0). Run a quarterly safety audit. Log every block decision for review and rule tuning.
Key steps:
- Provider-agnostic gateway between the app and any model provider.
- Inline guardrails for PII, prompt injection, jailbreak, toxicity, hallucination, off-policy refusal.
- Safety audit and feedback loop to tune rules.
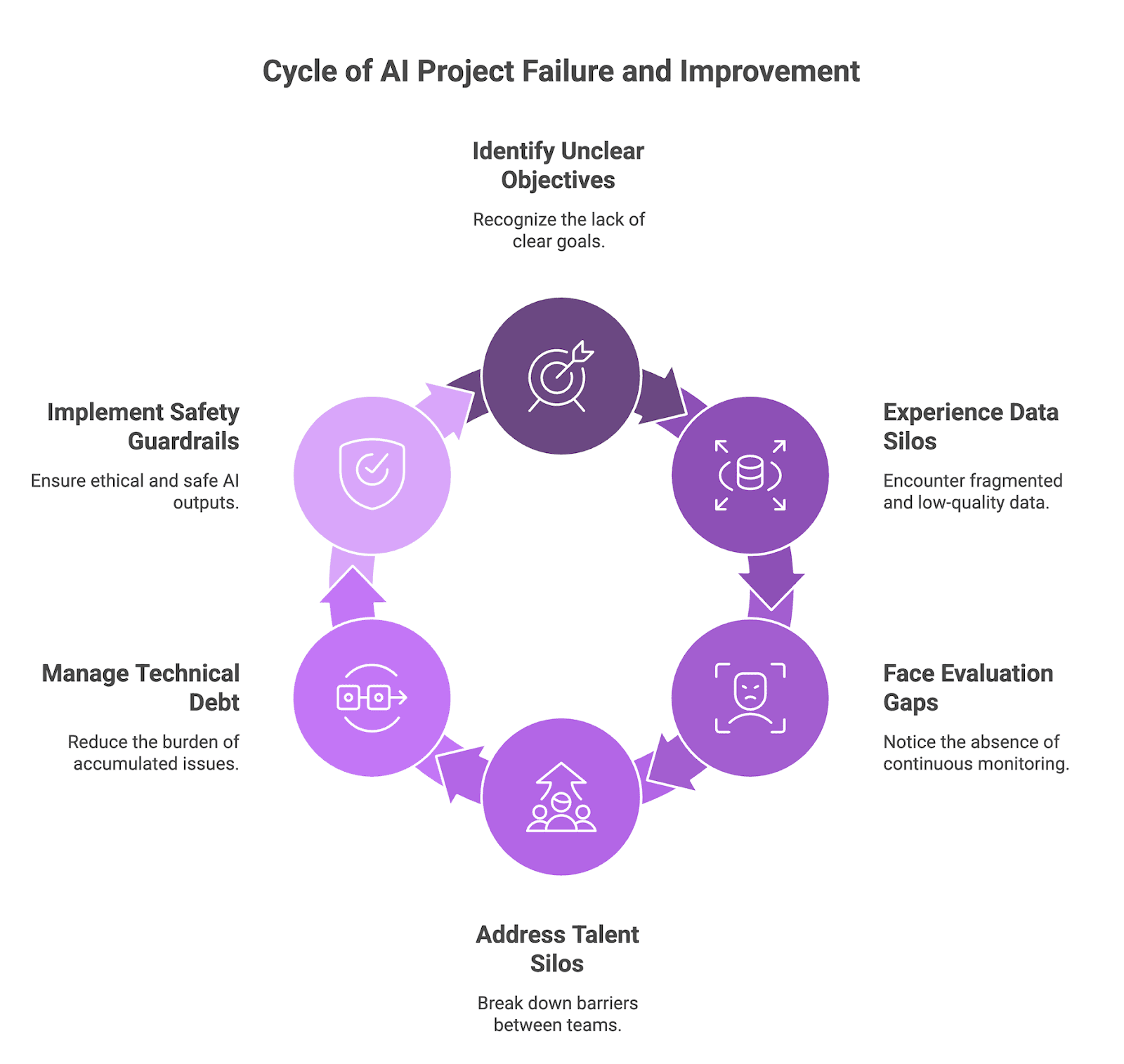
Figure 1: 2026 cycle of enterprise AI project failure and improvement
How Future AGI Addresses the Six Failure Modes End to End
Future AGI is the evaluation, observability and guardrails companion that maps directly to the six failure modes above. The stack is built around two open-source layers under Apache 2.0 (ai-evaluation, traceAI) and a managed control plane through the Agent Command Center.
Step 1: Objective definition and early validation
Define the primary KPI and the guardrail KPI before kickoff, then encode them as fi.evals.evaluate metrics. Use the Experiment and Prompt Workbench in the Future AGI app to A/B test prompts and configurations against those metrics before any production code is written. Ground experiments in your own data through the Knowledge Base.
Step 2: DataOps and centralised dataset management
Use the Dataset module to import, version and profile every dataset. Built-in validation catches missing fields, format mismatches and outliers. Wire the Dataset module to the Knowledge Base to generate synthetic samples and close coverage gaps. Use upstream DataOps tools (Great Expectations, Soda, Datafold, dbt) for the data plane.
Step 3: MLOps pipelines and live observability
Instrument every production trace with fi_instrumentation.register and FITracer. Spans emit OpenTelemetry GenAI semantic conventions, so they flow into Grafana, Datadog and Honeycomb without rewrite. The Agent Command Center surfaces cost, latency, quality and drift dashboards in real time, with user-level observability for support replay.
import os
from fi_instrumentation import register, FITracer
from fi.evals import evaluate
os.environ["FI_API_KEY"] = "<your-key>"
os.environ["FI_SECRET_KEY"] = "<your-secret>"
register(project_name="enterprise-assistant", environment="prod")
tracer = FITracer()
@tracer.chain
def respond(prompt: str, retrieved_context: str, model_output: str) -> dict:
groundedness = evaluate(
"groundedness",
output=model_output,
context=retrieved_context,
model="turing_small",
)
return {"output": model_output, "groundedness": groundedness.score}Step 4: Integrated safety guardrails
Run input and output filters with Future AGI Protect or the OSS fi.evals.guardrails Guardrails class. The Turing evaluator family covers the latency tiers (turing_flash at roughly one to two second cloud latency for synchronous chat gating, turing_small at two to three seconds for deeper checks, turing_large at three to five seconds for offline regression). Pair with NVIDIA NeMo Guardrails (Apache 2.0) for declarative dialog flows when needed.
Step 5: Continuous optimisation and human-in-the-loop
Close the loop with fi.opt.base.Evaluator wrapping a CustomLLMJudge and fi.opt.optimizers.BayesianSearchOptimizer for prompt and configuration sweeps. Production failures captured by the Agent Command Center feed back into the eval suite, which feeds back into the optimisation run. Expert support is one call away through the Future AGI team for onboarding, workshops and custom deployment guidance.
from fi.opt.base import Evaluator
from fi.opt.optimizers import BayesianSearchOptimizer
from fi.evals.metrics import CustomLLMJudge
from fi.evals.llm import LiteLLMProvider
judge = CustomLLMJudge(
name="helpfulness",
prompt_template="Rate helpfulness 1-5 for: {output}",
provider=LiteLLMProvider(model="gpt-5-2025-08-07"),
)
evaluator = Evaluator(metrics=[judge])
optimizer = BayesianSearchOptimizer(
evaluator=evaluator,
search_space={"temperature": (0.0, 1.0), "top_p": (0.5, 1.0)},
n_trials=30,
)Want to walk through this stack on your own workload? Book a Future AGI demo.
How Fixing the Six Root Causes Reduces Waste and Keeps AI Safe in 2026
The six barriers (unclear goals, data silos, missing monitoring, talent gaps, technical debt, no safety guardrails) all have practical fixes that compound. Set measurable KPIs. Centralise data with DataOps. Build a closed evaluation loop. Run mixed AI pods. Modularise the architecture. Wrap every LLM call with runtime guardrails. Teams that close four or more of the six gaps consistently report faster shipping cycles and fewer stalls than teams that close only one or two.
Next steps:
- Audit your current AI portfolio against the six root causes and the TL;DR table.
- Try Future AGI for continuous evaluation, runtime guardrails and live observability in one platform.
Frequently asked questions
Why do most enterprise AI projects fail to reach production in 2026?
What is the single most important fix to keep enterprise AI projects on track?
How does continuous evaluation prevent enterprise AI failures?
What does a 2026 enterprise AI data pipeline look like?
How do enterprise AI teams reduce technical debt?
What runtime guardrails should every enterprise AI deployment have?
How does cross-functional collaboration improve AI project success rates?
What changed between 2025 and 2026 in enterprise AI failure patterns?

Voice AI regulatory compliance in 2026: HIPAA, PCI-DSS, GDPR, EU AI Act, FCC TCPA. Pre-launch audit checklist, automated testing, FAGI guardrails.


Measure ROI of AI explainability tools in 2026: SHAP, LIME, Captum, Alibi, TransformerLens, KPIs, finance and healthcare results, real audit savings.


Map enterprise LLMs to GDPR, EU AI Act and NIST AI RMF in 2026: input/output guardrails, bias audits, explainability, and a real FAGI Protect setup.
