Evaluating DeepSeek R1 and V3 vs GPT-5, Claude Opus 4.7, and Gemini 3 Pro: A 2026 Model Comparison and Evaluation Guide
DeepSeek R1 and V3 compared to GPT-5, Claude Opus 4.7, Gemini 3 Pro in 2026: architecture, benchmarks, cost, and how to evaluate on workload.

Table of Contents
DeepSeek R1 and V3 vs GPT-5, Claude Opus 4.7, and Gemini 3 Pro in 2026: TL;DR
| Dimension | DeepSeek R1 | DeepSeek V3 | GPT-5 (thinking) | Claude Opus 4.7 | Gemini 3 Pro |
|---|---|---|---|---|---|
| Type | Reasoning | Chat/Instruct | Reasoning + chat | Reasoning + chat | Reasoning + chat (multimodal) |
| License | MIT (weights open) | MIT (weights open) | Closed | Closed | Closed |
| Architecture | MoE 671B total / 37B active | MoE 671B / 37B active | Closed | Closed | Closed |
| Strength | Hard math, code, open weights | Fast chat, structured tasks | Agents, tool use, instruction following | Agents, tool use, long context | Multimodal, very long context |
| Cost (API) | Order of magnitude cheaper than frontier closed | Lower still | Highest tier for thinking | Premium tier | Premium tier |
| When to pick | Reasoning at low cost, self host | Cheap throughput | Production agents | Production agents, long context | Multimodal, long horizon |
Pick based on workload. Run a workload representative eval before committing. See the Future AGI evaluation library for the rubric harness.
Why DeepSeek R1 Reshaped the AI Market with Cost Efficient Open Source Reasoning
DeepSeek shipped R1 in January 2025 and broke the assumption that frontier reasoning required frontier scale infrastructure. R1 was post-trained on top of the DeepSeek V3 base; V3 pretraining reportedly used 2,048 Nvidia H800 GPUs at a fraction of the budget of comparable closed model runs. The R1 weights shipped open under MIT. The combination (competitive reasoning quality, open weights, and an order of magnitude lower inference cost) reset price expectations across the industry.
Sixteen months later, the closed model providers responded with the next generation: OpenAI shipped GPT-5 and GPT-5 thinking, Anthropic shipped Claude Opus 4.7 with extended thinking, Google shipped Gemini 3 Pro with deep think. DeepSeek V3 preceded R1 as the chat and instruct base model, and the DeepSeek team continues to iterate on both lines. The 2026 comparison is not “DeepSeek vs the rest”; it is “which model fits which workload at what cost,” and the answer depends on whether you need reasoning, multimodal input, long context, low cost, or open weights.
What Is DeepSeek and How Did DeepSeek R1 Become a Leading Open Source AI Model
DeepSeek is a Chinese AI company started by Liang Wenfeng in 2023 and located in Hangzhou. The team open weighted the R1 reasoning model in January 2025 with the R1 paper and the DeepSeek-R1 weights under MIT license. The flagship 671 billion parameter MoE model became the most downloaded free app on the U.S. iOS App Store after release, briefly displacing ChatGPT.
The combination that drove adoption: a credible reasoning trace that matched OpenAI o1 era performance on several reasoning benchmarks; weights open under MIT for self hosting; distilled smaller variants (Llama 70B, Qwen 32B, smaller Qwen and Llama 1.5B to 14B) so the same training pipeline scales down to commodity GPUs; an API price an order of magnitude below the closed frontier. The follow on V3 covers chat and instruct workloads with the same architectural family without the reasoning post training, at lower latency and cost again.
DeepSeek R1 Model Architecture: Design, Training, and Optimization
Architectural Design: Mixture of Experts with 671 Billion Parameters, 37 Billion Active
DeepSeek R1 is a Mixture of Experts transformer with 671 billion total parameters of which only 37 billion are active per token. The MoE design routes each token through a small subset of expert modules, so the compute per token stays manageable while the total parameter count scales for capability. The model is decoder only, uses standard transformer building blocks (attention, feed forward, normalization), and is text only; chat, code generation, and structured reasoning are its native workloads.
The MoE architecture is the lever that makes R1 inference cost competitive. A dense 671B model would be infeasible to run at scale. With 37B active per token, R1 inference is comparable to a dense 70B model in compute, while drawing on the capability of a much larger parameter pool.
Training Methodologies: Cold Start CoT plus Multi Stage Reinforcement Learning
The R1 training pipeline starts from the DeepSeek V3 base. Three post training stages follow.
- Cold start chain of thought fine tuning. A curated dataset of high quality reasoning traces (math, code, multi step QA) is used for supervised fine tuning to enforce a structured output format and seed the reasoning behavior.
- R1 Zero stage with Group Relative Policy Optimization (GRPO). A reinforcement learning phase trains the model to produce correct multi step reasoning. GRPO uses group based reward signals (accuracy plus format plus language consistency) and removes the dependence on large critic networks.
- Iterative RL with rejection sampling and supervised fine tuning. After the initial RL phase the model is fine tuned again on rejection-sampled outputs (the model’s own best answers, filtered for correctness and quality). The R1 paper describes additional refinement stages beyond this; consult the paper for the full sequence.
The pipeline produces emergent self verification (“aha moments” where the model corrects its own reasoning mid trace) without explicit programming for the behavior.
Optimization: MoE Routing, MLA Attention, Mixed Precision
R1 was designed to balance cost, accuracy, and latency. The architectural levers from the V3 base carry over: Multi-head Latent Attention (MLA), a low-rank attention variant that reduces KV cache footprint, plus mixed precision training (FP16 and BF16) to keep memory usage in check. Gradient checkpointing stores only the activations required for backpropagation. Low Rank Adaptation (LoRA) inside the larger PEFT framework lets downstream users specialize R1 to new domains without retraining the full model. These choices, plus the MoE routing (37 billion active per token out of 671 billion total), are what let R1 deliver frontier quality reasoning at a fraction of the closed model cost.
How DeepSeek R1 Reasons: Chain of Thought, GRPO, and Self Verification
R1’s reasoning behavior emerges from the training recipe. Three properties matter in practice.
Curated Cold Start Chain of Thought Datasets
The cold start dataset is the seed. The DeepSeek team curated thousands of high quality reasoning traces through few shot prompting against earlier models, post processing of R1 Zero outputs through human review, and iterative refinement (deduplication, low quality filter, content remixing). The result is a corpus that biases the model toward clear, structured, multi step reasoning before the RL phase amplifies the signal.
Group Relative Policy Optimization
GRPO is the reinforcement learning method DeepSeek introduced for R1. Instead of training a critic network alongside the policy (PPO style), GRPO computes a relative advantage across a group of candidate outputs produced for the same prompt. The reward is a composite of rule based accuracy (for math, a verifier checks the boxed final answer; for code, a unit test runs), format adherence, and language consistency. GRPO scales better than PPO at the parameter count R1 lives at, which is one of the reasons the training cost stays low.
Adaptive Reasoning Length and Self Verification
R1 dynamically allocates reasoning tokens based on problem difficulty. Easy questions get short traces; hard questions get long traces with intermediate verification. The “aha moment” pattern is emergent: the model writes out a step, notices it does not match the goal, rewrites, and continues. The router activates a subset of experts per token (37 billion of 671 billion parameters), which keeps the per-token compute manageable while the total parameter pool stays large.
The combined effect is a reasoning model that holds its own against closed frontier reasoning on AIME and MATH at a fraction of the cost per inference.
DeepSeek R1 vs GPT-5, Claude Opus 4.7, and Gemini 3 Pro: Architecture, Benchmarks, and Cost
Architecture Overview
DeepSeek R1 architecture is documented. The closed model providers do not disclose parameter counts, attention shapes, or full training pipelines. What is public:
- DeepSeek R1. Mixture of Experts, 671B total, 37B active per token, GRPO reinforcement learning, multi stage SFT plus RL. Weights open under MIT.
- OpenAI GPT-5 thinking. Closed. OpenAI exposes a reasoning effort knob (typical values: minimal, low, medium, high) that controls the internal reasoning token budget. Consult the current OpenAI Platform reference for the exact parameter name and accepted values.
- Anthropic Claude Opus 4.7 with extended thinking. Closed. Anthropic exposes an extended thinking knob that lets you spend tokens on internal reasoning before the visible response. See the Anthropic extended thinking docs for the current parameter shape.
- Google Gemini 3 Pro. Closed. Ships a deep think mode and a multi million token context window. Strong on multimodal inputs.
Training Methodologies
The exact recipes for the closed models are not public. What is observable: all four reason through extended thinking; all four are post trained with some combination of supervised fine tuning, reinforcement learning from human feedback (RLHF), and reinforcement learning from AI feedback (RLAIF). DeepSeek’s GRPO recipe is documented in the R1 paper; OpenAI’s and Anthropic’s recipes are not. Treat any claim about the internal training methodology of GPT-5, Claude Opus 4.7, or Gemini 3 Pro as inference, not fact.
Benchmarks
Vendor benchmarks are useful as headline figures and unreliable as comparison points. Public benchmarks contaminate pretraining over time; a model that scores well on a public set can underperform on your unseen distribution. The honest read of the 2026 leaderboard:
- AIME and MATH (math reasoning). DeepSeek R1 is competitive with the closed reasoning models. The exact spread varies by year and effort level.
- HumanEval and MBPP (code). GPT-5 and Claude Opus 4.7 generally lead. R1 is close enough to matter on cost.
- GPQA and MMLU Pro (general reasoning). GPT-5 thinking and Claude Opus 4.7 lead. R1 is competitive at lower cost.
- Tau bench and SWE bench (agentic). GPT-5 and Claude Opus 4.7 currently lead on consistent tool use and multi step agentic tasks.
- Long context. Gemini 3 Pro’s multi million token window is the differentiator. R1 and the OpenAI and Anthropic models trail on context length.
The 2026 practice: confirm on your own workload representative set. The headline number from a vendor blog will not predict performance on your distribution.
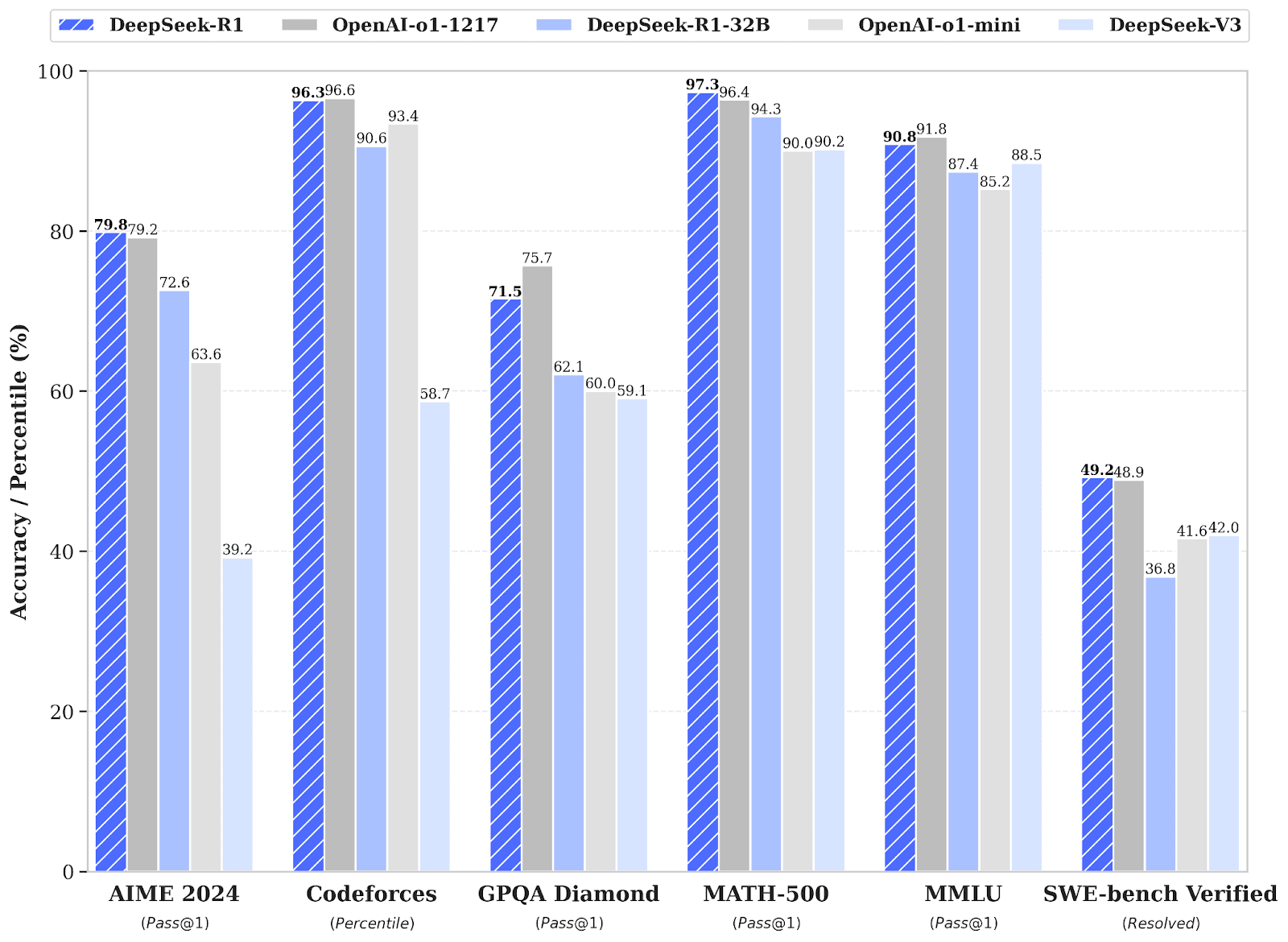
Figure 1: DeepSeek R1 benchmark report (source).
Cost Efficiency
DeepSeek R1’s cost story is the headline. Public DeepSeek API pricing has R1 inference at a fraction of the price the closed frontier providers charge for their reasoning tiers; check the DeepSeek pricing page and the providers’ own pricing pages for the current numbers before deciding. Self hosting the open weights cuts marginal inference cost further at the expense of GPU capex. Closed model providers offset their higher price with engineering polish (tool use, structured outputs, ecosystem). Pick based on what your workload spends most on: if reasoning tokens dominate, R1 typically wins on cost; if tool use polish dominates, the closed frontier providers usually win on operational efficiency. The evaluating cheap frontier models guide covers when an open-weight substitution actually holds up.
Comparison Table
| Aspect | DeepSeek R1 | GPT-5 thinking | Claude Opus 4.7 | Gemini 3 Pro |
|---|---|---|---|---|
| Reasoning control | Default reasoning, no knob | reasoning.effort minimal/low/medium/high | thinking.budget_tokens | Deep think mode |
| Open weights | Yes (MIT) | No | No | No |
| Multimodal | Text only | Yes | Yes | Strongest |
| Long context | Standard | Extended | Extended | Multi million tokens |
| Cost per token | Lowest of the four | Highest tier | Premium | Premium |
| Best fit workload | Reasoning at low cost, self host | Agents, tool use | Agents, long context | Multimodal, long horizon |
| OSS distillation path | Yes (Llama, Qwen variants) | No | No | No |
Table 1: Side by side comparison of the four flagship 2026 reasoning capable models.
How to Evaluate Any of These Models on Your Workload
The honest comparison is the one you run on your own data. Set up the same rubric against every candidate, run the same dataset, score on the same templates. The Future AGI ai-evaluation library is the harness many teams use because it ships pre built templates and lets you write custom rubric judges in a few lines. For a DeepSeek-specific walkthrough see evaluating DeepSeek models.
# Cross-model evaluation harness with fi.evals (illustrative).
# Requires: pip install future-agi (ai-evaluation source: Apache 2.0)
# Env: FI_API_KEY, FI_SECRET_KEY
# `load_eval_cases` and `call_model` are workload-specific stubs; replace them
# with your dataset loader and the provider client for each candidate model.
from fi.evals import evaluate
MODELS = [
"deepseek-r1",
"gpt-5-thinking",
"claude-opus-4-7",
"gemini-3-pro",
]
def load_eval_cases() -> list[dict]:
"""Replace with your dataset loader; each case has input, context, gold."""
return []
def call_model(model: str, prompt: str, context: str) -> str:
"""Replace with the provider client call for `model`."""
return ""
def extract_score(result) -> float:
"""fi.evals.evaluate returns a result object; pull the numeric score.
The exact attribute depends on the SDK version. Try attribute access
first, then fall back to dict-style access for older return shapes.
"""
attr_score = getattr(result, "score", None)
if attr_score is not None:
return float(attr_score)
return float(result["score"])
dataset = load_eval_cases()
for model in MODELS:
scores: list[float] = []
for case in dataset:
response = call_model(model, case["input"], case["context"])
result = evaluate(
"faithfulness",
output=response,
context=case["context"],
model="turing_flash", # cloud judge, roughly 1-2 seconds
)
scores.append(extract_score(result))
print(model, sum(scores) / max(len(scores), 1))Three notes on running this fairly.
- Use the same prompt. A prompt tuned for GPT-5 will underperform on R1 and vice versa. Either use the same prompt across models or run a separate prompt optimization pass per model with the same eval rubric.
- Score against the same rubric. Faithfulness is the cleanest cross-model comparison signal because it does not depend on stylistic choices. Layer in task accuracy or instruction following for specialized workloads.
- Compare on cost too. A model that wins on quality at 10x the cost loses on production economics. Track quality score, latency, and cost per request together.
For a deeper treatment of how to structure the eval pipeline, see LLM evaluation frameworks and metrics and the LLM testing playbook for 2026.
Final Takeaway: When to Use DeepSeek R1 or V3, GPT-5, Claude Opus 4.7, or Gemini 3 Pro
There is no single answer. The 2026 production stack is multi model, with a gateway routing between them based on the request shape.
- DeepSeek R1. Reasoning at the lowest cost. Open weights for self hosting and customization. Pick for hard math, code, and multi step logic where cost dominates.
- DeepSeek V3. Chat and instruct at very low cost. Pick for high volume chat, retrieval over your own docs, and structured generation where reasoning is not the bottleneck.
- GPT-5 (and GPT-5 thinking). Production agents. Tool use, structured outputs, instruction following at the highest polish. Pick when the agent must work reliably across many tool calls.
- Claude Opus 4.7. Production agents on long context. Strong on tool use, instruction following, and grounded reasoning over long documents. Pick when context length is the differentiator.
- Gemini 3 Pro. Multimodal and multi million token context. Pick for video, image, and audio reasoning, or for tasks that require ingesting an entire codebase or book in one shot.
Whichever you pick, the evaluation discipline is the same: workload representative dataset, shared rubric across models, score quality, latency, and cost on every candidate. Future AGI provides the methodology layer (traceAI for instrumentation under Apache 2.0, the fi.evals catalog for scoring with 50 plus pre built templates plus custom LLM judges via fi.evals.metrics.CustomLLMJudge, and the Agent Command Center for runtime guardrails) so the comparison is fair and reproducible. The model picks the use case; the evaluation pipeline picks the model.
Frequently asked questions
What is DeepSeek R1 and how does it differ from DeepSeek V3?
How does DeepSeek R1 compare to GPT-5, Claude Opus 4.7, and Gemini 3 Pro?
What is the cost difference between DeepSeek R1 and GPT-5?
Can DeepSeek R1 be self hosted on my own GPUs?
How do I evaluate DeepSeek R1 fairly against GPT-5 or Claude Opus 4.7?
Does DeepSeek R1 hallucinate more or less than GPT-5?
Which model is best for production agents in 2026?
What is the right way to compare reasoning models on benchmarks?

Build a generative AI chatbot in 2026: model selection, RAG, prompt-opt, evaluation, observability, guardrails, gateway. Step-by-step with current tooling.


LLM evaluation in 2026: deterministic metrics, LLM-as-judge, RAG metrics, agent metrics, and how to wire offline regression plus runtime guardrails.


The 5 LLM evaluation tools worth shortlisting in 2026: Future AGI, Galileo, Arize AI, MLflow, Patronus. Features, pricing, and which workload each wins.
