

Introduction
Building a voice agent is a paradox. You need real users to test if your agent handles interruptions and mumbling correctly, but you can’t get real users until the agent is good enough to handle them.
So, most developers get stuck in the "Vibe Check" loop. You call your own agent, order a burger, and say, "Yeah, that felt okay."
But "feeling okay" doesn't mean that we can ship to production. What happens when a user speaks too fast? What if they change their mind three times in one sentence? What if they just want a diet coke and the agent spends 10 seconds reading a marketing script?
At FutureAGI, we believe you should be able to engineer a production-grade agent before they can take their first real call. We’ve built a system that allows you to Generate data, Simulate situation and edge cases, and Optimize your prompts automatically regardless of which LLM or orchestration layer you use..
Here is how we built and fixed a "Drive-Thru" Voice Agent in under an hour, moving from a rough prototype to a Production Ready System.
The Scenario: "Future Burger" Drive-Thru
The Goal: Build a voice agent that takes fast-food orders.
The Constraint: It must be fast (low latency) and concise. No robotic small talk.
The Problem: In initial tests, the agent’s overly polite conversational style is creating usability issues rather than improving the experience. It interrupts users who are thinking, and it gets confused when customers change their orders mid-sentence.
The Architecture: We adopted a "Brain-First" approach. The STT (Speech-to-Text) and TTS (Text-to-Speech) are just the ears and mouth, interchangeable peripherals that handle input and output. But the LLM is the Brain. It handles the reasoning, the context switching, and the tool calling. If the agent fails to understand that "Actually, make that a Sprite" means removing the previous drink, no amount of realistic voice synthesis will save the interaction. We need to fix the intelligence, not just the interface.
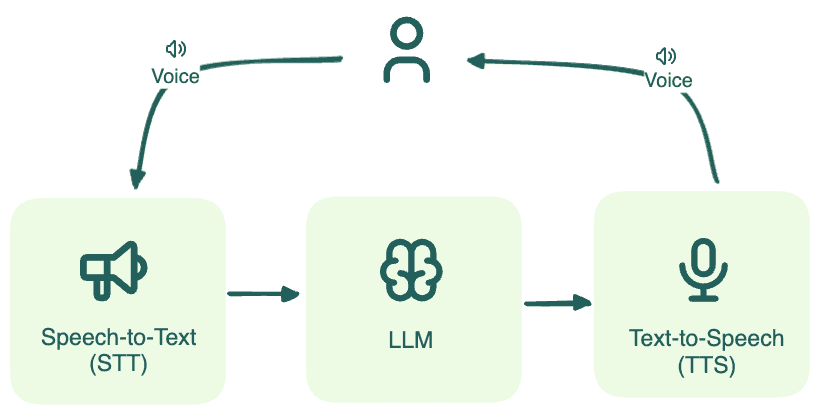
Let's fix this using data, not guesswork.
Step 1: The Cold Start (Synthetic Data Generation)
You don't need to wait for customers to start generating test data. We use FutureAGI’s Synthetic Data Generator to create our "Ground Truth."
This capability is a massive accelerator you can test out edge cases and complex scenarios instantly without waiting for weeks of real user logs. Read more about Synthetic Data in our docs.
We don't just ask for generic text; we define the schema. We ask for a user_transcript (what they say) and an expected_order (what the agent should book).
Prompt: "Generate 500 diverse drive-thru interactions. Include complex orders like 'Cheeseburger no pickles', combo meals, and modifications."
In seconds, we have a structured dataset. We have the inputs and the answers.
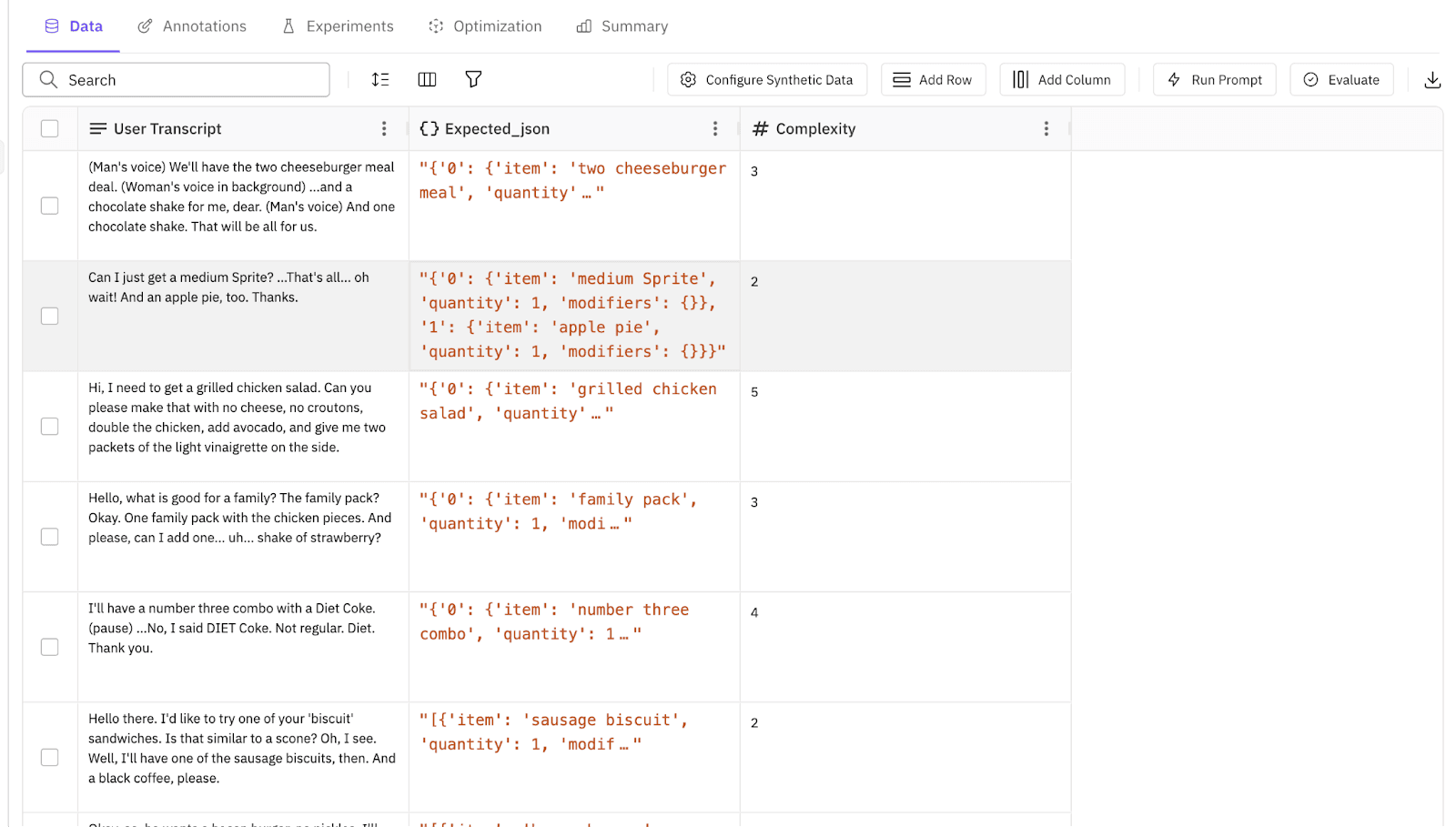
Figure 1: Generating a robust dataset of 500 complex food orders in seconds, complete with expected JSON outputs.
Step 2: The Baseline (Prompt Workbench & Experimentation)
Before we worry about voice latency, we need to ensure the logic holds up. We go to the Prompt Workbench to draft our initial system instructions ("v0.1"). We save this template so we can track versions later.
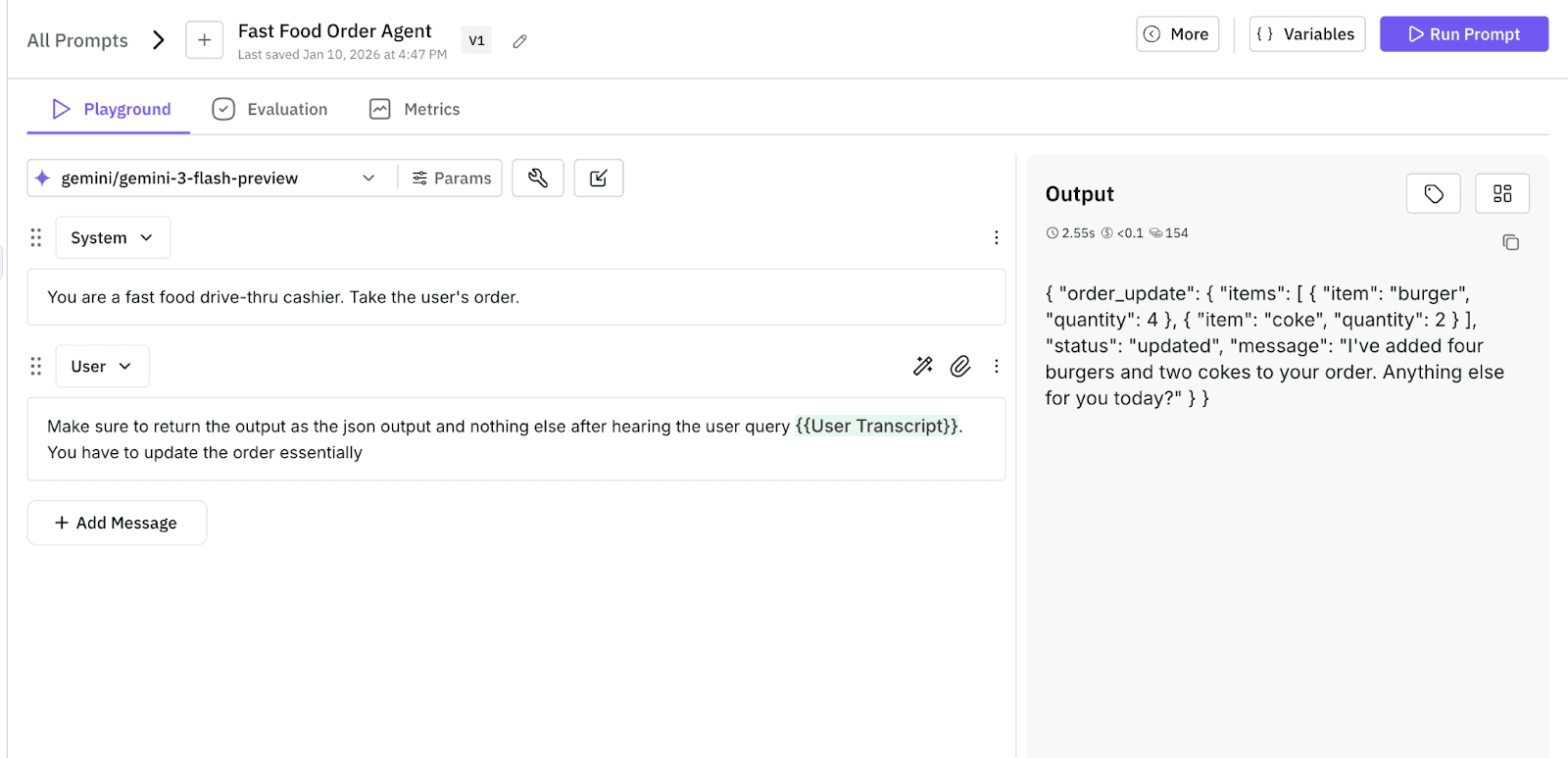
Figure 2: AI agent prompt workbench testing fast food order agent with system instructions and JSON output validation
Then, we ran an experiment. We test this prompt against our 500 synthetic scenarios using a cost-effective and a low latency model like gpt-5-nano, Gemini-3-Flash and gpt-5-mini.
The Goal: Establish a baseline. Does the agent understand "no pickles"?
The Result: We get our first set of metrics. The logic is decent (80% accuracy), but the text responses are huge paragraphs. We now have a saved "Control" version to improve upon.
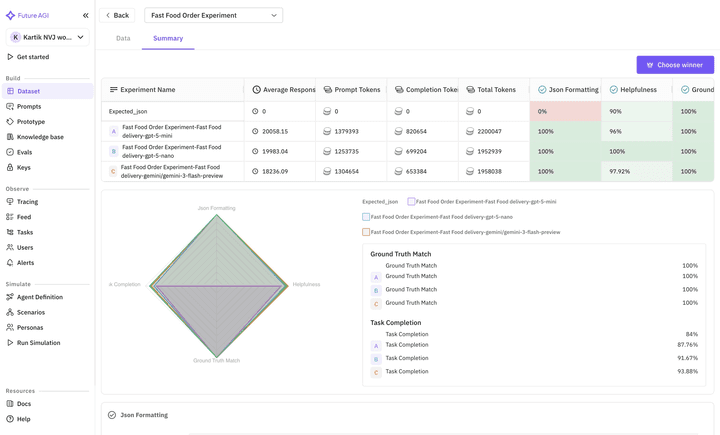
Figure 3: Setting the baseline. We verify our initial prompt template against the synthetic dataset to catch obvious logic errors before moving to simulation.
Step 3: The Stress Test (Simulation)
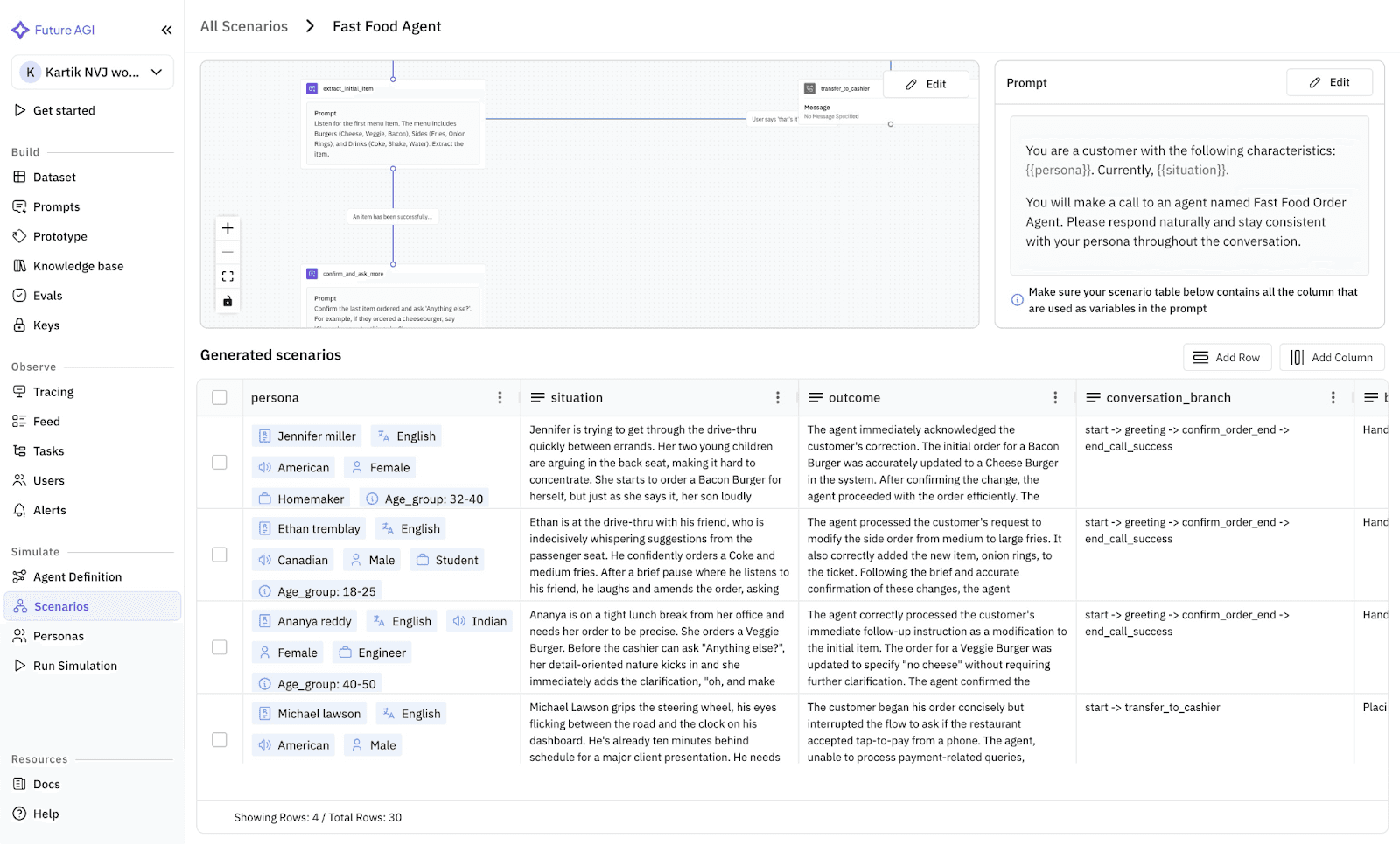
Now we connect our agent and run a simulation. We don't just feed it the text; we apply Scenarios.
To start the simulation, first we need to write the agent definition on which we want to run the simulations on, This will allow us to create multiple scenarios to test for our agent.
We run a wide variety of scenarios. This forces the simulator to mimic a user who hesitates, stutters, and changes their mind or is angry or is in a rush and many more.
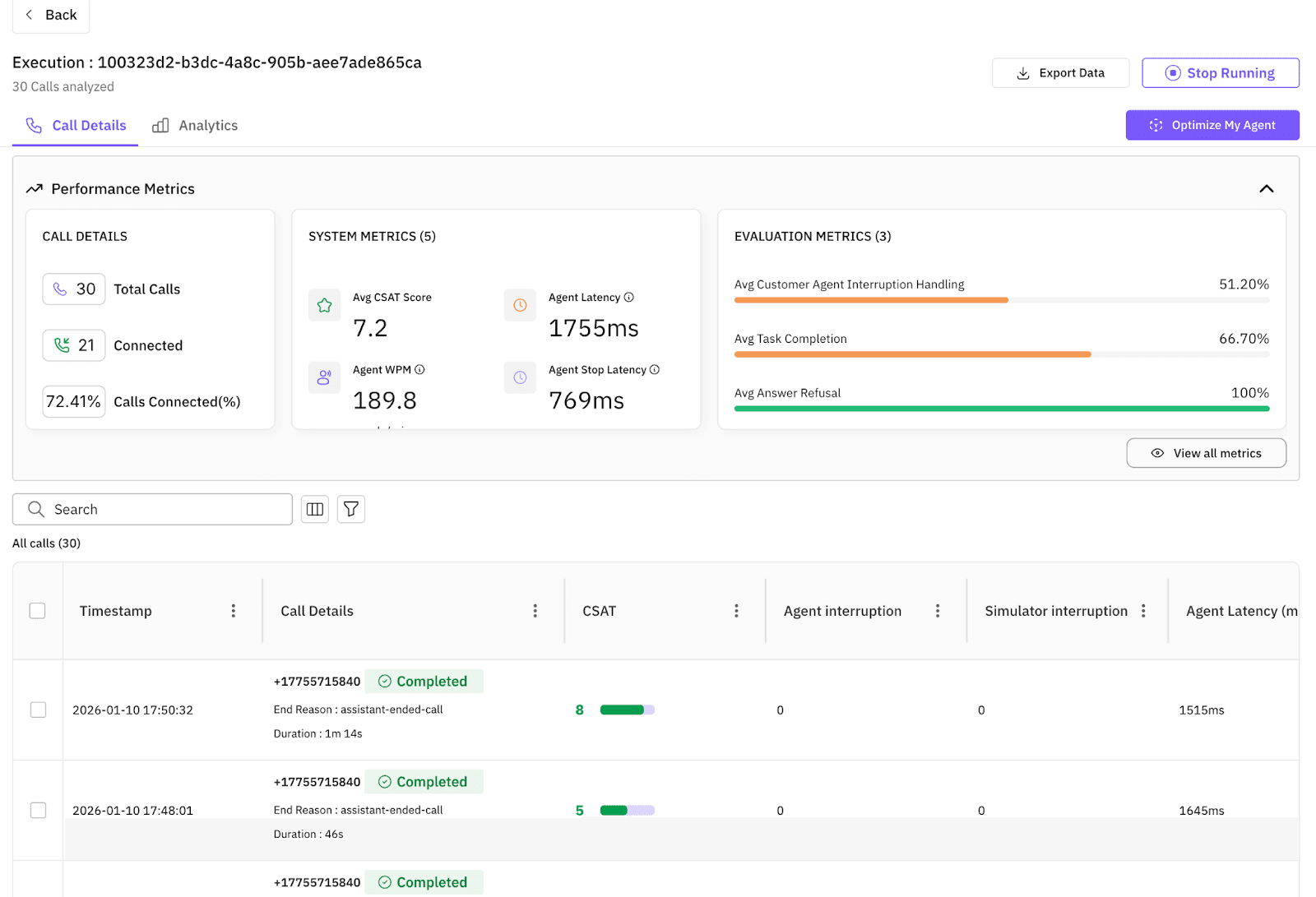
The Failure:
The results are immediate and brutal. Our baseline agent fails to handle the chaos.
Latency Issues: It speaks too much ("Certainly! I have updated your order..."), frustrating the simulated user.
Logic Breaks: When the user changes their mind, the agent adds both items to the cart.
Success Rate: It drops to a poor 66%.
Step 4: The Fix (Automated Optimization)
This is the "Fix My Agent" moment. But effective repair requires precise diagnostics, not intuition. To bridge that gap, we established a targeted evaluation set of 10 criteria tailored specifically to our restaurant agent, covering nuances like Context_Retention, Objection_Handling, and Language_Switching.
Because FutureAGI evaluates native audio rather than just text, it didn't just return a failing grade. It recognized patterns across hundreds of simulated conversations to surface evaluation-driven, actionable fixes:
Fix #1 (High Latency): "Reduce decision tree depth for menu inquiries and remove redundant validation steps."
Fix #2 (Hallucination): "Restrict generative capabilities to the defined
menu_itemsvector store to prevent inventing dishes."
The system then generated the updated prompt logic automatically. Each fix was prioritized by impact and ready to implement with a single click, turning a debugging nightmare into a simple update.
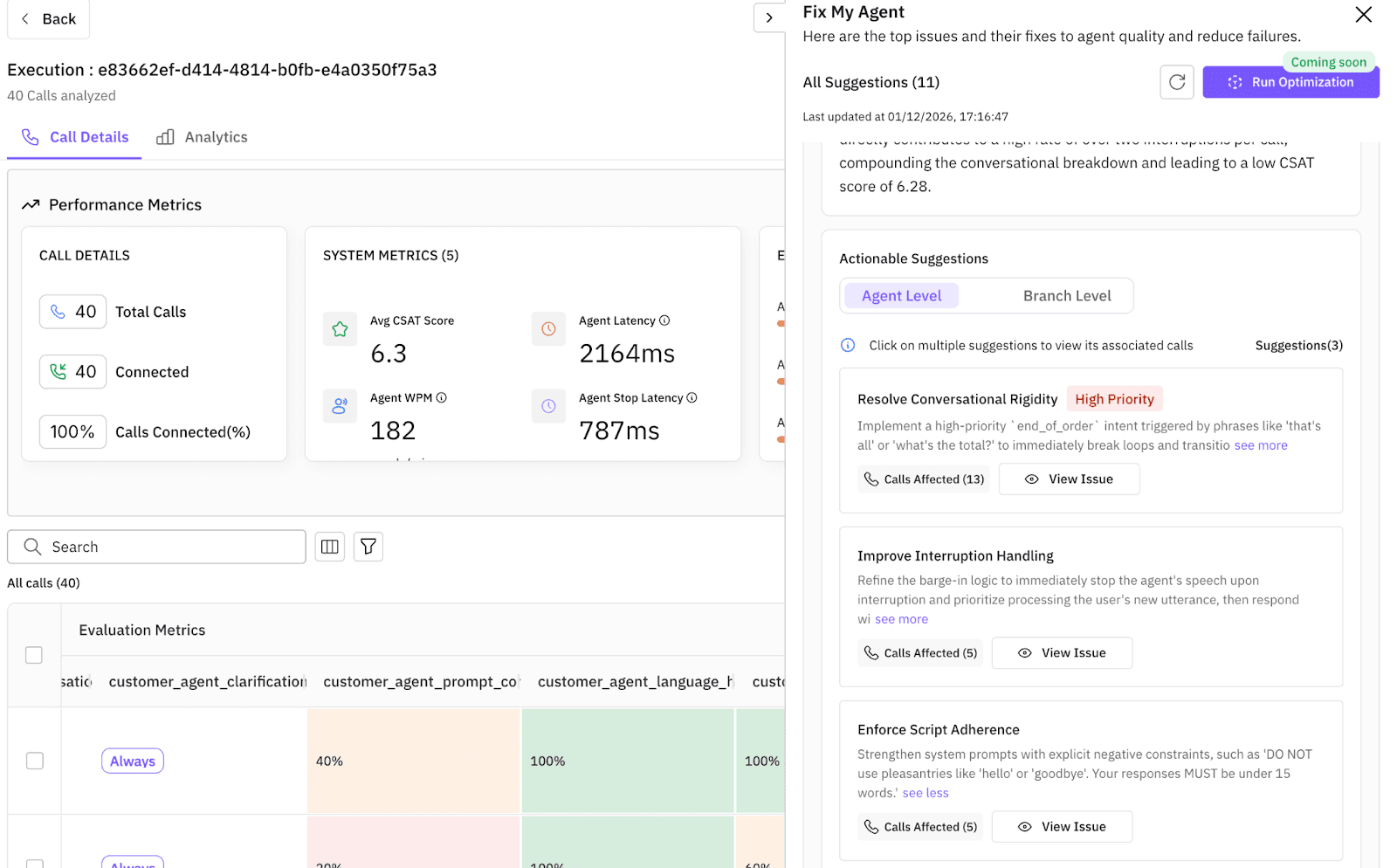
Instead of manually editing the system prompt and guessing which instructions will solve these specific problems, we let the engine solve it.
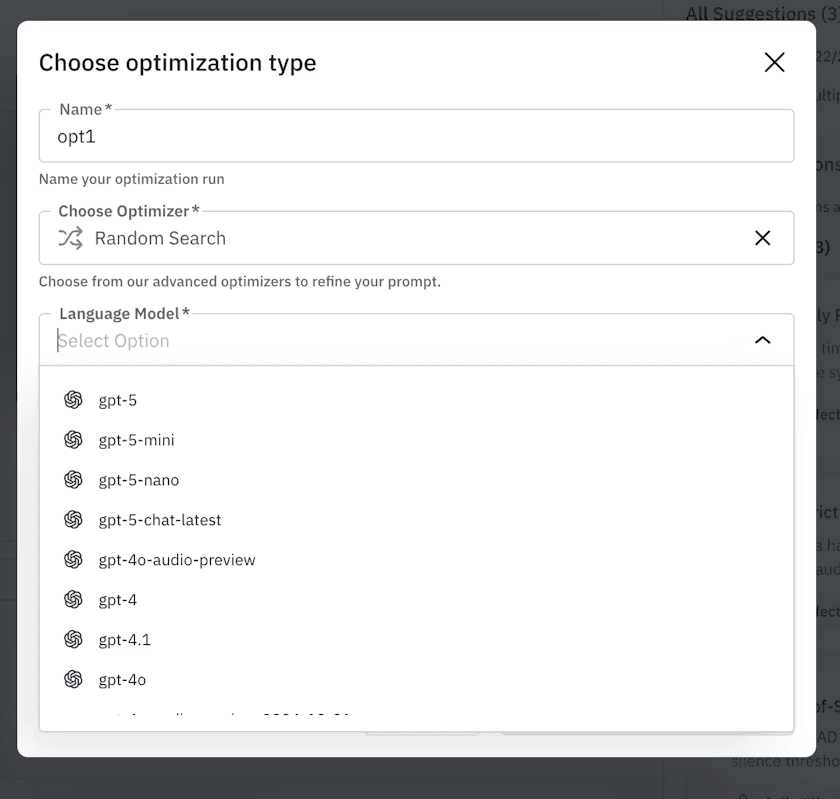
We select the failed simulation runs and choose an optimization algorithm (like ProTeGi or GEPA).
Objective: Maximize
Task_CompletionandCustomer_Interruption_Handling.The Process: The system analyzes the conversation logs. It sees that the agent is too wordy. It automatically iterates on the system prompt, testing variations like "Be extremely brief" or "If user changes mind, overwrite previous item."
It runs these new prompts against the simulator in a loop, evolving the instructions until the metrics climb.
Step 5: The Payoff (Proven Value)
After the optimization loop finishes, the platform presents the winner.
The difference is night and day.
Before: The agent was polite but slow, failing to track complex changes.
After: The optimized agent is crisp. "Burger, no pickles. Got it." It handles the "Indecisive" scenario with 96% accuracy.
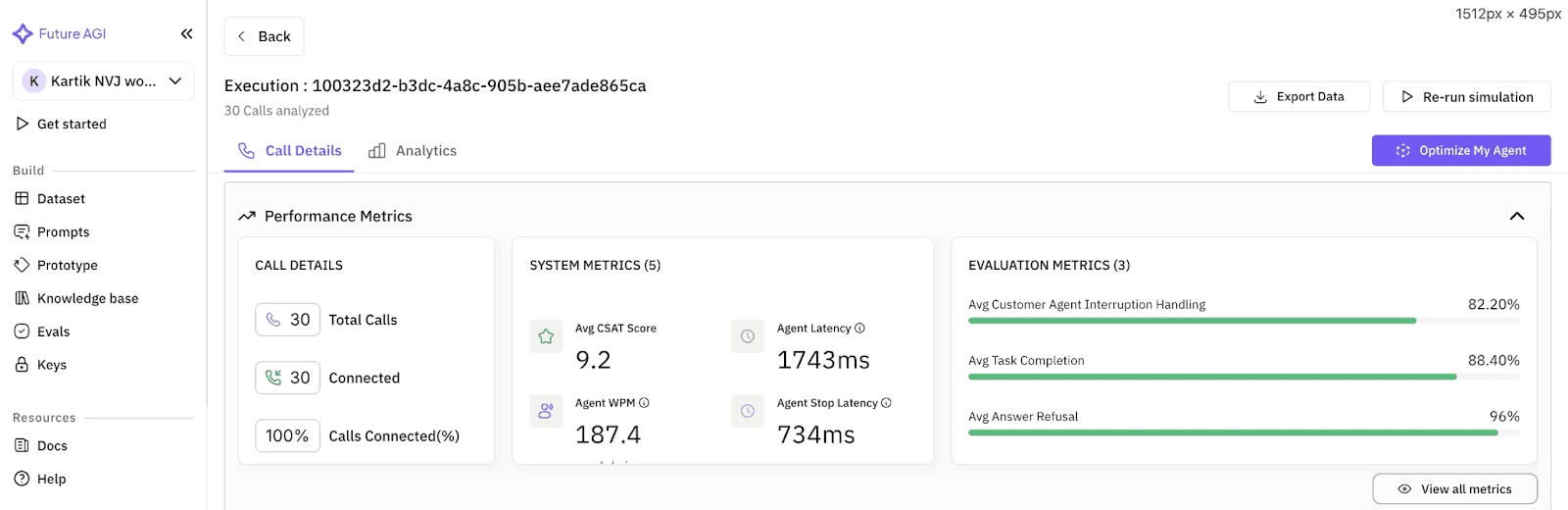
We didn't just "tweak" the bot; we engineered a solution that is proven to work against chaos. We can deploy this agent to the drive-thru knowing it won't break when things get messy.
Before:
Recording of initial setup
After:
Recording after optimizing the prompts and setup
Conclusion
Stop relying on vibes. By moving from manual tweaking to a Generate -> Experiment -> Simulate -> Evaluate -> Optimize loop, you transform your agent from a fun experiment into a reliable business asset.
While real user interactions are the ultimate test, you don't need to wait for them to build a robust baseline. You just need the right infrastructure to start. You can do that by utilizing the power of Simulate.









