What is Tree of Thoughts Prompting? Branching Reasoning in 2026
Tree of Thoughts prompts an LLM to explore many reasoning branches under an evaluator and search policy. What it is, when it pays off vs CoT, and 2026 production patterns.

Table of Contents
A Game of 24 puzzle gives the digits 4, 9, 10, 13 and asks you to combine them with arithmetic to reach 24. GPT-4 with a single Chain of Thought prompt solves this 4 percent of the time. The same GPT-4 wrapped in Tree of Thoughts, branching at each numeric step and pruning under a value prompt, solves it 74 percent of the time. The numbers come from Yao et al.’s NeurIPS 2023 paper that named the technique. The lift is real. The token cost is also real, and that is the framing every engineer asks for: when is the search worth the spend.
This guide unpacks Tree of Thoughts as a concept, situates it against Chain of Thought and reasoning models, walks the search policies and evaluator choices, and lays out the 2026 production patterns where ToT pays off and where it just burns tokens.
TL;DR: What Tree of Thoughts is
Tree of Thoughts is a prompting framework where the model produces several candidate reasoning steps at each decision point, an evaluator scores those candidates, and a search policy decides which branches to expand and which to prune. The output is a search tree of partial reasoning rather than a single linear chain. Three knobs control it: branching factor (how many candidates per node), beam width or depth (how many survive and how far to expand), and the evaluator (the LLM-judge or deterministic checker that scores each thought). The original paper specifies BFS, DFS with backtracking, and best-first as search policies. Production deployments most often use a bounded beam.
Why Tree of Thoughts exists
Chain of Thought made one big bet: write the reasoning out, the model gets better. It does, on tasks where the right answer is reachable from the first plausible step. CoT fails when the first step locks the model into a wrong basin. Combinatorial puzzles, multi-step planning, creative writing with hard constraints, and crosswords all share this shape. The Yao et al. team measured it cleanly. On Game of 24, CoT with GPT-4 solves 4 percent. The model sometimes picks “13 minus 9 equals 4, then 10 plus 4 equals 14” and never recovers. ToT lets the model float three or four candidate first steps, score them, and keep going only on the ones the evaluator believes can reach 24.
The deeper claim is that LLMs have always been doing search implicitly inside the forward pass; ToT externalizes the search so it becomes observable, steerable, and capped by a budget. Once the search is external, you can plug in a different evaluator, set a beam width, or terminate early on a confidence threshold. None of that is possible inside a single CoT completion.
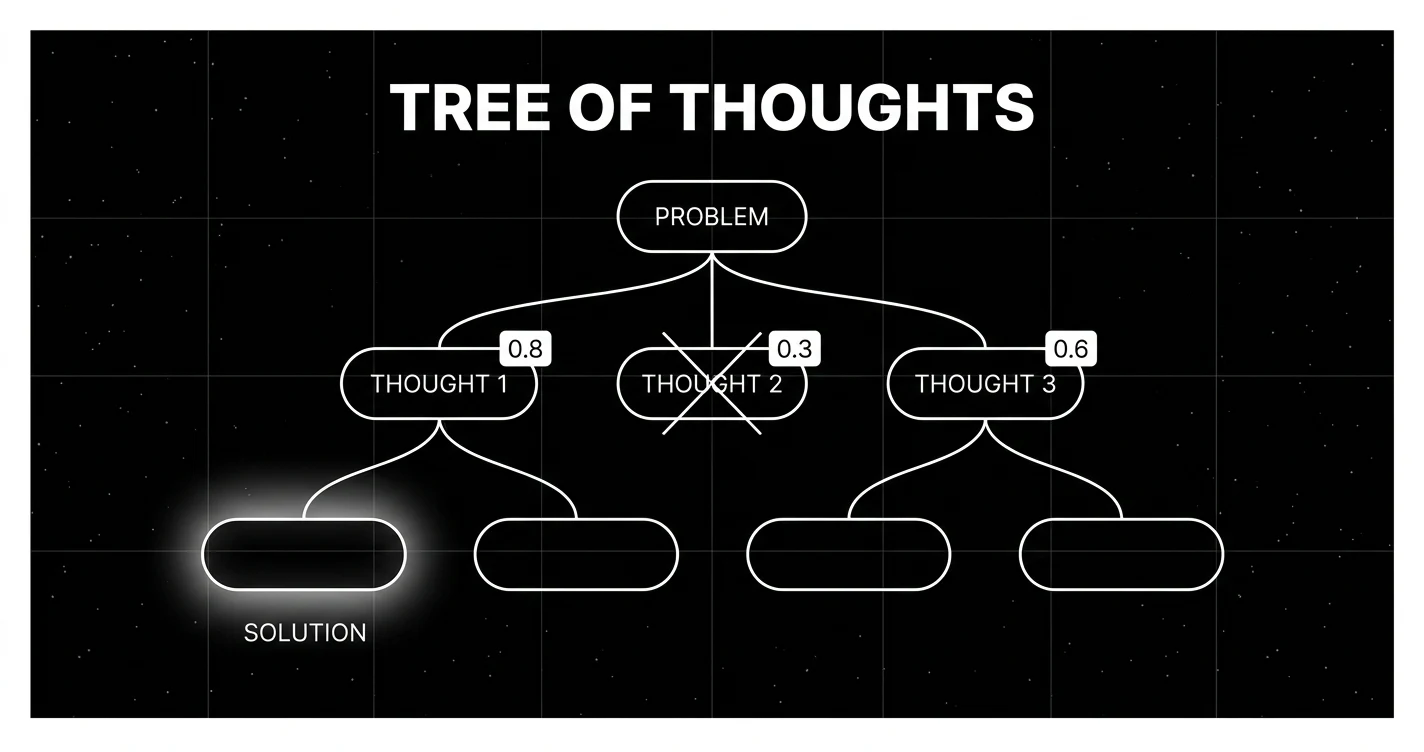
How Tree of Thoughts works
Four moving parts make a ToT run. Get any one wrong and the result is worse than a vanilla CoT for more cost.
1. Thought decomposition
Decide what one “thought” is for your task. The original paper proposes coherent text chunks that represent intermediate reasoning steps, sized so the LLM can rate them faithfully and so a single forward pass can produce one. For Game of 24, a thought is one arithmetic operation: “(13 - 9) = 4”. For creative writing, a thought is a paragraph plan. For crosswords, a thought is a candidate word fill at a position. Too small a thought (one token) wastes calls; too large (the entire solution) collapses ToT to CoT.
2. Thought generation
At each node, prompt the model to produce b candidate thoughts. Two patterns:
- Sample independently. Send b independent calls, each asking for one continuation. Captures diversity, costs b tokens.
- Propose in one call. Ask the model in a single call to produce b distinct candidates. Cheaper but candidates correlate. The original paper used both depending on whether the thought space was rich.
3. Evaluation
Score each candidate. Three choices:
- Value prompt. Send the partial reasoning back to the LLM and ask “is this on track to reach the answer? Reply with a number 1 to 10 or sure / maybe / impossible.” Cheap and always available; biased by the model’s own preferences.
- Voting prompt. Show all b candidates to the LLM and ask it to vote for the most promising. Useful when scoring is relative.
- Deterministic checker. If the task supports it (arithmetic validity, schema check, regex match), evaluate without an LLM. Most reliable when applicable.
4. Search policy
Decide what to expand. The Yao et al. paper proposes:
- BFS. Expand all surviving nodes at depth d before going to d+1. Used in their Game of 24 results.
- DFS with backtracking. Drill into the highest-scoring branch; backtrack on dead ends. Used in their crossword task.
Common production generalizations:
- Best-first. Pop the highest-scoring frontier node, expand, push children. A priority-queue version of search.
In production, beam-style search with width k is the most common. At each depth, keep the top-k thoughts by evaluator score and prune the rest. The total node budget is bounded by k × b × d, which is what budget-conscious teams need.
Tree of Thoughts vs Chain of Thought: cost-benefit
The cost question is the one that decides whether ToT goes into production.
| dimension | CoT | ToT (b=4, k=2, d=3) |
|---|---|---|
| forward passes | 1 | around 20 generations + 20 evaluator scores |
| latency | one round-trip | up to 6 dependent LLM round-trips; fewer provider calls when candidates are batched per depth |
| input tokens | one prompt | b × d prompts at growing context |
| output tokens | one completion | k × b × d short generations + scores |
| eval cost | none | half the total when LLM-judge |
| accuracy on Game of 24 (GPT-4, Yao et al.) | 4% | 74% |
| accuracy on customer support reply | already high | no measurable lift |
The Game-of-24 lift looks like a slam dunk. It is the wrong reference task for most production code. Many real-world LLM products spend most calls on tasks where CoT already scores high. The arithmetic of ToT is worst on those tasks: high marginal cost for low marginal lift.
A useful screen before adopting ToT:
- Does CoT score under 50 percent on your eval set?
- Is the failure mode a wrong commitment in the first one or two reasoning steps?
- Can you write or generate an evaluator that scores partial reasoning faithfully?
- Can you tolerate 3 to 30x the token cost of CoT?
Three yes answers tilts toward ToT. Two or fewer, stay with CoT and invest the budget in better prompts, retrieval, or eval-driven prompt iteration.
Tree of Thoughts and reasoning models
The 2024 to 2026 wave of reasoning models (OpenAI o-series, DeepSeek-R1, Anthropic extended thinking, Google reasoning Gemini) changes the calculus. These models do extensive internal search inside their forward pass, often producing thousands of reasoning tokens before the visible answer. On math and code benchmarks, the native search is hard to beat with externally-scaffolded ToT.
Where external ToT still earns its keep with reasoning models:
- Observable branches. When the system needs to enumerate alternatives the user can compare or pick between (legal arguments, design options, plan candidates), ToT externalizes the branching.
- Steerable search. When you want a separate evaluator with different bias from the generator (a smaller specialist judge, a deterministic checker, a domain-specific rubric).
- Search-as-API. When the agent system already has a tool-calling loop and adding ToT means adding nodes to a graph the agent runtime is already managing.
- Cost cap. When the reasoning model’s internal search is unbounded and you need an explicit budget.
For pure accuracy on a single math or code task, a reasoning model usually beats a non-reasoning model wrapped in ToT for the same total spend. For task families where the search must be transparent or have a budget, ToT remains the right scaffolding.
Production patterns that work
Several patterns recur in production stacks that use ToT well.
Cascade: CoT first, ToT on low confidence
Run CoT. If the answer fails a sanity check (schema invalid, judge score below threshold, deterministic verifier disagrees), escalate to a bounded ToT pass. Most queries pay only the CoT cost; only the hard ones pay the ToT premium. Common implementations cap the ToT branch at b=3, k=2, d=2 to bound the worst-case spend.
Beam at the plan level, single chain inside each branch
Use ToT only for high-level planning (3 to 5 candidate plans, evaluator picks the best 2), then execute each surviving plan with a single CoT call. Avoids the combinatorial blowup at the leaf level while keeping the diversity at the decision point that matters.
Self-consistency as a poor-man’s ToT
Sample N parallel CoT completions and majority-vote the answer. Cheaper than full ToT (no per-step evaluator) and often closes most of the gap on math problems. Wang et al. (2022) Self-Consistency is the canonical reference. The 2026 take: when self-consistency works for your task, full ToT is overkill.
Deterministic evaluator wherever possible
Replace LLM-judge with a deterministic checker when the task allows: schema validation, arithmetic verification, regex match, type-check, unit-test pass. The search quality jumps and the per-node cost drops by an order of magnitude.
Bounded budget with fallback
Set a hard spend cap on the ToT call. If the budget is exhausted before a solution is found, return the best partial result and log it. Production systems that do not enforce this will eventually see a runaway tree blowing past 10x the expected cost on adversarial inputs.
Common mistakes when implementing Tree of Thoughts
- Skipping evaluator calibration. A weak LLM-judge picks the worst branches as often as the best. Calibrate against a labeled set of 100 to 200 partial-reasoning samples before trusting the search.
- Branching too wide. b=8 or b=10 rarely beats b=3 to 5 and burns 2 to 3x the tokens.
- Going too deep. Past d=4, most tasks plateau; the model’s ability to reason coherently across 5+ explicit thought levels degrades.
- No termination rule. Without a max-node or score-threshold cutoff, ToT can run unbounded.
- Treating it as a free upgrade. ToT is not strictly better than CoT. On tasks where CoT is already strong, ToT is a regression in cost-per-correct-answer.
- No span-attached eval. If the search is not instrumented at the span level, you cannot tell whether a regression came from the search policy, the evaluator, or the generator.
How to use this with FAGI
FutureAGI is the production-grade evaluation and observability stack for teams running Tree of Thoughts in production. With traceAI (Apache 2.0) for OpenTelemetry-native LLM tracing, ToT runs are first-class trees in the Agent Command Center: each thought becomes a span, the evaluator scores attach as span attributes, and the search policy is observable in the span hierarchy. A failing ToT call shows the exact branch that scored highest, the candidates that were pruned, and the per-node token cost. For production cascades that fall through to ToT only on low confidence, the Agent Command Center routes the escalation based on online eval scores, with turing_flash running guardrail screening at 50 to 70 ms p95 as the confidence checker before triggering the heavier ToT call.
For evaluation work itself, FAGI eval templates score partial reasoning at roughly 1 to 2 second latency, suitable for offline ToT runs on hard task suites where the evaluator quality matters more than per-call speed. The same plane carries 50+ eval metrics, persona-driven simulation, the BYOK gateway across 100+ providers, and 18+ guardrails on one self-hostable surface; pricing starts free with a 50 GB tracing tier.
Sources
- Yao et al. (2023). Tree of Thoughts: Deliberate Problem Solving with Large Language Models
- Wei et al. (2022). Chain of Thought Prompting Elicits Reasoning in Large Language Models
- Wang et al. (2022). Self-Consistency Improves Chain of Thought Reasoning
- Hao et al. (2023). Reasoning with Language Model is Planning with World Model (RAP)
- Zhou et al. (2023). Language Agent Tree Search (LATS)
- OpenAI o1 system card
Series cross-link
Related: Chain of Thought Prompting in 2025, AI Prompting in 2025, Context Engineering for GenAI
Frequently asked questions
What is Tree of Thoughts prompting in plain terms?
How is Tree of Thoughts different from Chain of Thought?
When does Tree of Thoughts pay off in production?
What are the search policies in ToT?
What is the role of the evaluator in ToT?
What is the cost overhead of Tree of Thoughts?
Does Tree of Thoughts work with reasoning models like o-series and DeepSeek-R1?
How does Tree of Thoughts relate to MCTS and AlphaGo-style search?

Reflection tuning is when an LLM critiques its own output and rewrites it under that critique. What it is, the Reflexion / Self-Refine origins, and 2026 production patterns.


Best LLMs May 2026: compare GPT-5.5, Claude Opus 4.7, Gemini 3.1 Pro, and DeepSeek V4 across coding, agents, multimodal, cost, and open weights.

Best Voice AI May 2026: compare Deepgram, Cartesia, ElevenLabs, Retell, and Vapi for STT, TTS, latency budgets, and production voice agents.