What is Reflection Tuning? Reflexion, Self-Refine, and 2026 Patterns
Reflection tuning is when an LLM critiques its own output and rewrites under that critique. The Reflexion / Self-Refine origins, 2026 production patterns.

Table of Contents
A coding agent generates a Python function for a leetcode problem. It runs the function against the unit tests. Three tests fail. The agent reads the test output, writes a verbal note (“the off-by-one is on the inner loop bound”), and tries again. The next attempt passes. The score on HumanEval moves from the GPT-4 baseline of around 80 percent to 91 percent in the Reflexion paper. The technique is older than this loop, simpler than it sounds, and has been iterated on continuously since the original 2023 papers.
The umbrella term is reflection tuning. It covers Self-Refine, Reflexion, the post-hoc critic loops that ship inside agent frameworks, and the more recent distillation work that bakes the loop into model weights. This guide covers the concept, the canonical papers, the cost trade-offs, and the production patterns that work in 2026.
TL;DR: What reflection tuning is
Reflection tuning is the family of techniques where an LLM critiques its own output and rewrites under that critique. Three forms appear in production:
- Inference-time reflection. Generate, critique, refine, all using the same or different LLM calls. Self-Refine (Madaan et al. 2023) and the in-loop variants used by agent frameworks fit here.
- Cross-episode reflection. When an attempt fails, persist a verbal lesson in episodic memory so the next attempt has it as context. Reflexion (Shinn et al. 2023) is the canonical reference.
- Distilled reflection. Train the base model on (draft, critique, refined) triples so the deployed model produces the corrected output in one pass. Removes the inference-time loop overhead.
The lift comes from one fact: for many tasks, verifying an output is easier than generating it correctly the first time. Reflection turns that asymmetry into accuracy gains by giving the model a verification step.
Why reflection tuning exists
Two observations from the 2022 to 2023 prompting literature pushed the field toward reflection.
First, LLM outputs improve when given a critique. If you show GPT-4 its own answer and ask “find what is wrong with this,” it often finds real errors. The model has the capability to detect mistakes; what it lacks during a one-shot generation is the trigger to apply that capability. An explicit critique prompt is the trigger.
Second, in-context learning was hitting limits on tasks that required stateful trial and error. RL-style fine-tuning works but is expensive: a coding agent learning from environmental rewards needs millions of samples and a fine-tuning loop. Reflexion’s contribution was reformulating this as verbal feedback in an in-context memory buffer, no weight updates needed. The agent reflects on what went wrong, writes that reflection into memory, and the next attempt has it as context.
The Reflexion paper reported 91 percent pass@1 on HumanEval surpassing the GPT-4 baseline of 80 percent in their experimental setup. Self-Refine reported approximately 20 percent absolute improvement averaged across seven tasks (dialog, math, code, sentiment). The numbers were strong enough that reflection-style loops became standard in agent frameworks within a year.
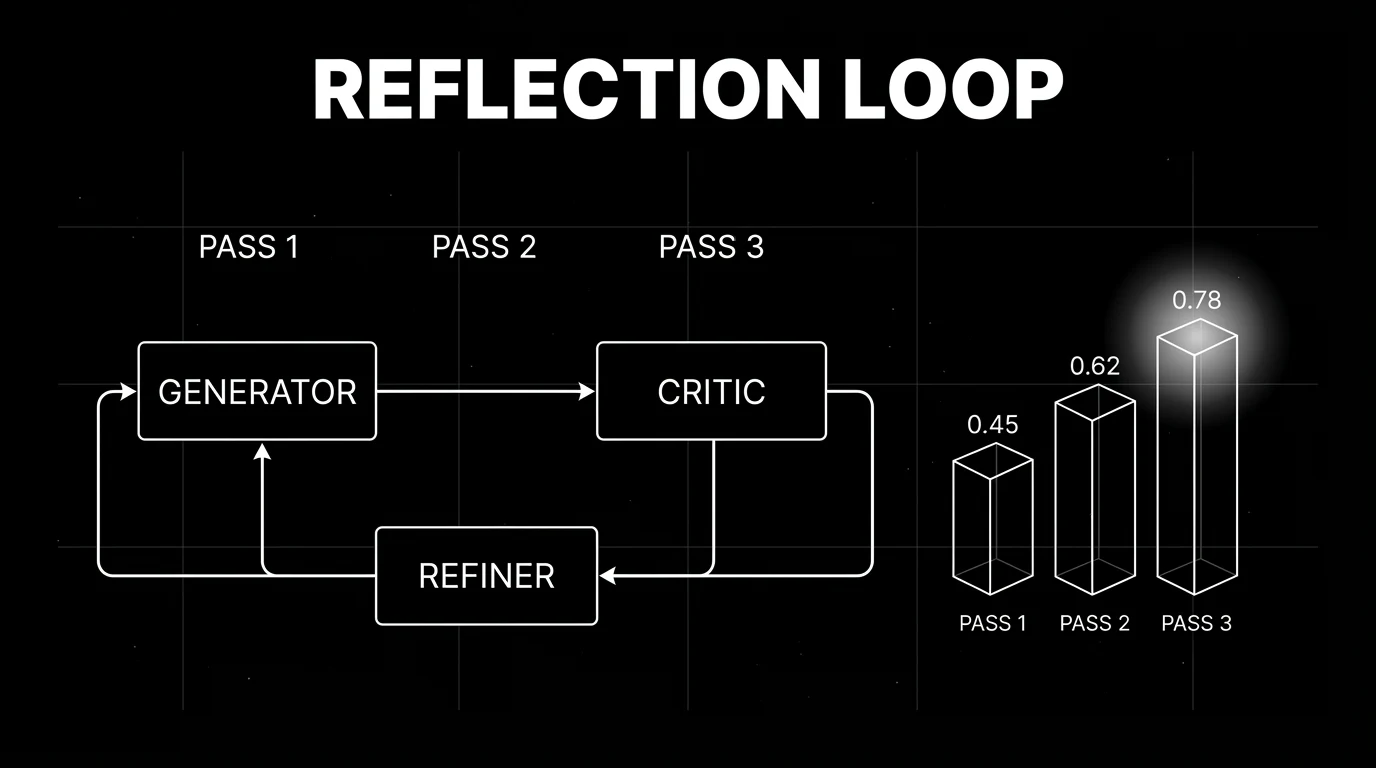
How reflection tuning works
Three roles, run sequentially or in a loop:
Generator
The same LLM you would have called normally, given the task prompt. Produces a draft answer.
Critic
A second call (often the same LLM with a different prompt, sometimes a smaller specialist model or a deterministic checker) that scores the draft. The critique can be free-form (“identify any errors in the above answer”) or rubric-bound (“score the answer on factuality, completeness, and tone, 1 to 5 each”). The critic output drives the next step.
Refiner
A third call that takes the original task, the draft, and the critique, and produces a revised answer. In Self-Refine, the same LLM is used for all three roles with different prompts. In production stacks, teams often split: a stronger generator, a cheaper rubric-bound critic, a refiner equal to or stronger than the generator.
Optional: episodic memory (Reflexion)
After each attempt, the verbal critique is appended to a memory buffer that primes future attempts at the same task type. This is what makes Reflexion’s gains compound across tries on the same problem.
Self-Refine vs Reflexion: where they differ
Both papers shipped within months of each other in 2023. They are often conflated. They are not the same thing.
| dimension | Self-Refine (Madaan et al.) | Reflexion (Shinn et al.) |
|---|---|---|
| loop scope | within one task attempt | across multiple task attempts |
| memory | none persisted | episodic memory buffer of past reflections |
| feedback type | natural-language critique | natural-language verbal RL feedback (scalar or text) |
| weight updates | none | none |
| reported lift | ~20% absolute avg across 7 tasks | 91% pass@1 on HumanEval (vs 80% GPT-4 baseline) |
| canonical use | one-shot tasks where rewriting helps | multi-attempt tasks where the agent gets multiple tries |
| best for | summarization, dialog, math, code | coding, decision-making, sequential reasoning |
For a customer-support reply that gets one shot at the user, Self-Refine fits. For a coding agent that runs against a unit-test suite and gets multiple tries, Reflexion fits.
Reflection tuning in 2026: distillation, frozen models, and hybrids
The 2023 papers framed reflection as inference-time prompting. The 2024 to 2026 literature pushed it into three new directions.
Distilled reflection (single-pass deployment)
If reflection works on (draft, critique, refined) triples at inference, those triples are training data. Multiple academic and industry research lines since 2024 have explored reflection-distilled models: train on a corpus of reflection traces, deploy a model that produces the refined answer in one pass. The win is at inference: 1x cost back, no critic call. The cost is moved into a fine-tuning pipeline. The broader self-improvement literature, including DPO-style preference fine-tuning on (chosen, rejected) reflection pairs, fits this pattern.
Frozen model reflection (no weights touched)
The original Self-Refine and Reflexion patterns. Still the right answer when you cannot fine-tune (closed model APIs), when the task is too narrow to justify a fine-tune, or when reflection is one of several scaffolds you need to swap fast. Costs 2 to 5x at inference relative to the base model, but the implementation is one prompt and one loop.
Hybrid: reflection plus tools plus search
Modern agent frameworks (LangGraph, OpenAI Agents SDK, CrewAI) bundle reflection inside larger graphs that also include tool calls and tree-style search. A planning node generates candidate actions, a critic node prunes obviously bad ones, the agent executes the best, and a reflection node updates an episodic memory if the action failed. This is where ReAct, Reflexion, Tree of Thoughts, and tool-using agents converge.
Production patterns that work
Several patterns recur in production stacks that ship reflection well.
Cascade reflection (do not reflect on most calls)
Run the generator. Run a fast checker (deterministic when possible, cheap LLM-judge otherwise). If the checker flags the draft, run critic-then-refiner. If not, ship the draft. Cuts the average cost by 50 to 80 percent on production workloads where most outputs pass first draft. The latency tax only applies on the failing tail.
Deterministic critic where possible
If the task has a deterministic verifier (unit tests, JSON schema, regex, type-check, math checker), use it as the critic. The signal is sharper, the cost is order-of-magnitude lower than an LLM-judge call, and the critic does not have correlated bias with the generator.
Bounded loop with stop rule
Cap the reflection loop at 1 to 3 rounds. Score the draft pre and post each round. If the post-refinement score is worse, roll back to the pre-refinement output. Without the stop rule, sycophantic critics can degrade outputs across rounds.
Different model for generator and critic
Same model for both is the cheapest setup but the critic shares the generator’s blind spots. A different family or size for the critic (Anthropic critic on a GPT generator, or vice versa, or a specialist judge model) catches errors the generator’s distribution missed.
Span-attached refinement scores
Instrument the (draft, critique, refined) triple as three spans under one parent. Attach pre and post refinement scores to those spans. Production drift detection then catches the case where reflection used to lift scores and quietly stopped doing so after a model update or prompt change. The guide on evaluating LLM self-reflection loops covers the three metrics that matter here.
Common mistakes when implementing reflection tuning
- Sycophantic critic. A weakly-prompted LLM critic returns “looks good, very thorough.” The refiner rewrites under noise. Mitigation: rubric-bound critique with explicit failure categories, plus calibration against a labeled set.
- No stop rule. Reflection over-corrects on rounds 2 and 3 of a loop that should have terminated at round 1.
- Same model on both ends. Generator and critic share blind spots; the loop bounces between two equally wrong answers.
- Reflecting on tasks where the model is at ceiling. Adding 2 to 3x cost for zero lift.
- No deterministic checker when one is available. Spending LLM-judge tokens to verify what a unit-test or schema-check could verify for free.
- Treating Self-Refine and Reflexion as interchangeable. They solve different problems.
- No span instrumentation. When the loop quietly stops helping, no signal surfaces until quality drops at the user level.
How to use this with FAGI
FutureAGI is the production-grade evaluation and observability stack for teams running reflection tuning in production. With traceAI (Apache 2.0) for OpenTelemetry-native LLM tracing, reflection loops surface as nested spans with the (draft, critique, refined) triple under one parent. Each span carries the rubric scores as attributes, and the parent span carries the pre and post refinement deltas. For cascade reflection at the policy layer, the Agent Command Center routes draft outputs through a fast online check (turing_flash runs guardrail screening at 50 to 70 ms p95) and only triggers the heavier critic-and-refiner pass when the check fails.
For evaluating reflection-tuned outputs offline, FAGI eval templates score draft and refined answers side-by-side at roughly 1 to 2 second latency per pair, suitable for offline regression suites that compare reflection variants. The same plane carries 50+ eval metrics, persona-driven simulation that exercises the reflection loop on hard task distributions, the BYOK gateway across 20+ providers via six native adapters (OpenAI, Anthropic, Gemini, Bedrock, Cohere, Azure) plus OpenAI-compatible presets and self-hosted backends, and 18+ guardrails on one self-hostable surface; pricing starts free with a 50 GB tracing tier.
Sources
- Madaan et al. (2023). Self-Refine: Iterative Refinement with Self-Feedback
- Shinn et al. (2023). Reflexion: Language Agents with Verbal Reinforcement Learning
- Self-Refine project page
- Reflexion GitHub repo
- Yao et al. (2022). ReAct: Synergizing Reasoning and Acting in Language Models
- Bai et al. (2022). Constitutional AI: Harmlessness from AI Feedback
Series cross-link
Related: Self-Improving AI Agent Pipeline, Chain of Thought Prompting in 2025, AI Prompting in 2025
Frequently asked questions
What is reflection tuning in plain terms?
How is reflection tuning different from chain of thought?
What is the difference between Self-Refine and Reflexion?
Is reflection tuning the same as fine-tuning a reflection model?
When does reflection tuning help in production?
What is the cost overhead of reflection tuning at inference?
Can reflection tuning fail or hurt the output?
How does reflection tuning relate to RLHF and DPO?

Tree of Thoughts prompts an LLM to explore reasoning branches under an evaluator and search policy. When it pays off vs CoT, 2026 production patterns.


Best LLMs May 2026: compare GPT-5.5, Claude Opus 4.7, Gemini 3.1 Pro, and DeepSeek V4 across coding, agents, multimodal, cost, and open weights.

Best Voice AI May 2026: compare Deepgram, Cartesia, ElevenLabs, Retell, and Vapi for STT, TTS, latency budgets, and production voice agents.