Top 5 LLM Evaluation Tools in 2026: Future AGI, Galileo, Arize, MLflow, and Patronus AI Compared
The 5 LLM evaluation tools worth shortlisting in 2026: Future AGI, Galileo, Arize AI, MLflow, Patronus. Features, pricing, and which workload each wins.

Table of Contents
2026 refresh: This guide was first published April 2025 and refreshed in May 2026 with current pricing, 2026 model coverage, and the latest licensing of each tool. For the broader 7-platform comparison, see Best LLM Evaluation Tools in 2026.
TL;DR: How to pick an LLM evaluation tool in 2026
| Tool | Best for | License | Free tier |
|---|---|---|---|
| Future AGI | All-rounders: 50 plus metrics, multimodal, traceAI, gateway, simulation | Apache 2.0 (libs) + commercial dashboard | Yes, 50 GB tracing + 2,000 credits |
| Galileo | Hallucination at extreme volume, flat per-token pricing via Luna-2 | Closed source | Sales call |
| Arize AX + Phoenix | Self-host observability; Phoenix is the source-available layer | Elastic 2.0 (Phoenix) + commercial (AX) | Phoenix free self-host |
| MLflow | Teams already running MLflow for classical ML | Apache 2.0 | Free, self-host |
| Patronus AI | Safety, compliance, hallucination detection via Lynx | Closed source | Sales call |
If you are starting fresh in May 2026 and want one tool that covers evaluation, observability, simulation, gateway, and prompt management, the default pick is Future AGI. If your workload is one specific thing (hallucination at 1B+ tokens/month, deep MLflow shop, fully OSS observability), the niche pick may win.
Why structured LLM evaluation matters in 2026
LLMs power production workflows in legal, finance, healthcare, and customer support. Without a scoring layer, teams ship regressions every week without knowing it. Three regulatory and engineering shifts in the last year make eval non-negotiable:
- EU AI Act enforcement began February 2025 for prohibited practices, with the general-purpose AI obligations active from August 2025. Production LLM deployments now need documented eval evidence.
- Reasoning-capable models are now common at the frontier, with extended-thinking modes available on the latest GPT, Claude, and Gemini releases. Token bills are higher and latencies longer. Catching regressions before deploy saves real money.
- Multimodal eval became table stakes. Text-only eval misses the actual user-facing failure modes for image, audio, and video workflows.
Cost of failing to evaluate LLMs: 2026 examples
The 2023-2025 horror stories (CNET’s hallucinated finance stories, Apple Intelligence’s bad summaries, Air Canada’s liable chatbot) are still cited because nothing prettier happened since.
Recent examples that anchored the trust gap:
- Hallucinations in legal AI tools have repeatedly drawn court sanctions. The widely cited Mata v. Avianca case from June 2023 (lawyer sanctioned for submitting fake ChatGPT-generated citations) established the pattern, and the Stanford RegLab study on AI legal research errors showed legal AI tools still hallucinate on 1 in 6 queries or more in 2024-2025.
- Air Canada’s chatbot ruling in February 2024 set legal precedent that companies are responsible for their bots’ outputs (Forbes coverage).
- Apple suspended AI news summaries in January 2025 after the BBC reported false alerts.
The pattern is the same: ship without eval, lose money, get sued, or both.
How to choose the right LLM evaluation tool in 2026: the criteria
- Metric coverage: 50 plus built-in metrics for accuracy, groundedness, format, safety, and custom judges.
- Modality coverage: text plus image plus audio, with video support where production-ready or explicitly beta.
- Tracing layer: OpenTelemetry-native, ideally Apache 2.0.
- Online + offline: same platform for batch eval and live observability.
- Pricing predictability: BYOK or flat per-token, not surprise overages.
- Customisation: ability to write custom LLM judges, deterministic rules, and agent-as-judge.
- Self-host option: required for HIPAA, regulated data, or air-gapped deployments.
Five tools compared against those seven criteria below.
Tool 1: Future AGI
Future AGI offers Apache 2.0 evaluation and observability libraries alongside a commercial platform with a managed dashboard. The library surface includes 50 plus built-in eval metrics, multimodal scoring across text, image, and audio, and a BYOK LLM gateway. The Apache 2.0 evaluation library lives at github.com/future-agi/ai-evaluation. The Apache 2.0 OpenTelemetry tracing layer lives at github.com/future-agi/traceAI.

Core evaluation capabilities
- Conversational quality: coherence and resolution metrics for multi-turn dialogue.
- Content accuracy: groundedness and faithfulness on RAG outputs.
- RAG metrics: chunk utilization, chunk attribution, context relevance, context sufficiency.
- Generative quality: translation accuracy, summary quality, style adherence.
- Format and structure: JSON validation, regex match, email/URL validation.
- Safety and compliance: toxicity, bias, PII detection, GDPR/HIPAA-style data privacy checks.
import os
from fi.evals import evaluate, Evaluator
os.environ["FI_API_KEY"] = "..."
os.environ["FI_SECRET_KEY"] = "..."
# Score one (input, output) pair against the chosen evaluator.
score = evaluate(
evaluator=Evaluator.GROUNDEDNESS,
input="What EU AI Act obligations were active for general-purpose AI models in 2025?",
output="The model's RAG answer goes here.",
context=["Retrieved chunk 1...", "Retrieved chunk 2..."],
)
print(score)Custom eval frameworks
- Agent as a Judge: multi-step AI agent (chain-of-thought plus tool use) evaluates each step in a trajectory.
- Deterministic eval: rule-based scoring with regex, JSON schema, or grammar. Same result every time on the same input.
- CustomLLMJudge: ship your own LLM-as-judge prompt with the metric registered in code.
from fi.evals.metrics import CustomLLMJudge
from fi.evals.llm import LiteLLMProvider
judge = CustomLLMJudge(
name="brand_tone",
rubric="Score 1-5 on whether the output matches our brand voice (warm, technical, never preachy).",
provider=LiteLLMProvider(model="gpt-5"),
)Advanced capabilities
- Multimodal evals: text, image, audio. Video evaluation in beta as of May 2026.
- Safety evals: built-in toxicity, bias, prompt-injection screens.
- No ground truth needed: reference-free metrics for live production traffic.
- Real-time guardrailing: 18 plus built-in guardrail scanners (PII, prompt injection, toxicity, brand-tone, custom regex) at the gateway layer via Future AGI’s Protect guardrails surface.
- Observability: spans from traceAI flow to the dashboard with per-span eval scores.
- Error localizer: pinpoints the exact failing span in a multi-step trace.
- Reason generation: structured rationale per eval verdict.
Deployment and pricing
- Install:
pip install futureagiplus the Apache 2.0ai-evaluationandtraceAIlibraries on GitHub; the managed Future AGI dashboard is a commercial product running on top of those libraries. - Integrations: Vertex AI, LangChain, LlamaIndex, Mistral, OpenAI, Anthropic, plus 100 plus providers via Agent Command Center BYOK gateway.
- Pricing: Free tier (50 GB tracing, 2,000 AI credits, 100K gateway requests, 100K cache hits, 1M simulation tokens). Boost $250/mo. Scale $750/mo (HIPAA). Enterprise from $2,000/mo (SOC 2). Pricing at futureagi.com/pricing.
Customer impact
Customer case studies show concrete improvements on specific workloads, including SQL accuracy gains on a retail analytics pipeline and faster eval iteration on an EdTech product (see the retail analytics case study and the EdTech case study for the measured baselines and final numbers).
Tool 2: Galileo AI
Galileo’s GenAI Studio is built around hallucination detection. The standout 2025-2026 launch is the Luna-2 family of small evaluator models which deliver flat per-token pricing (roughly $0.02 per 1M tokens) on hallucination scoring. That cost structure makes Galileo hard to beat at extreme volume.
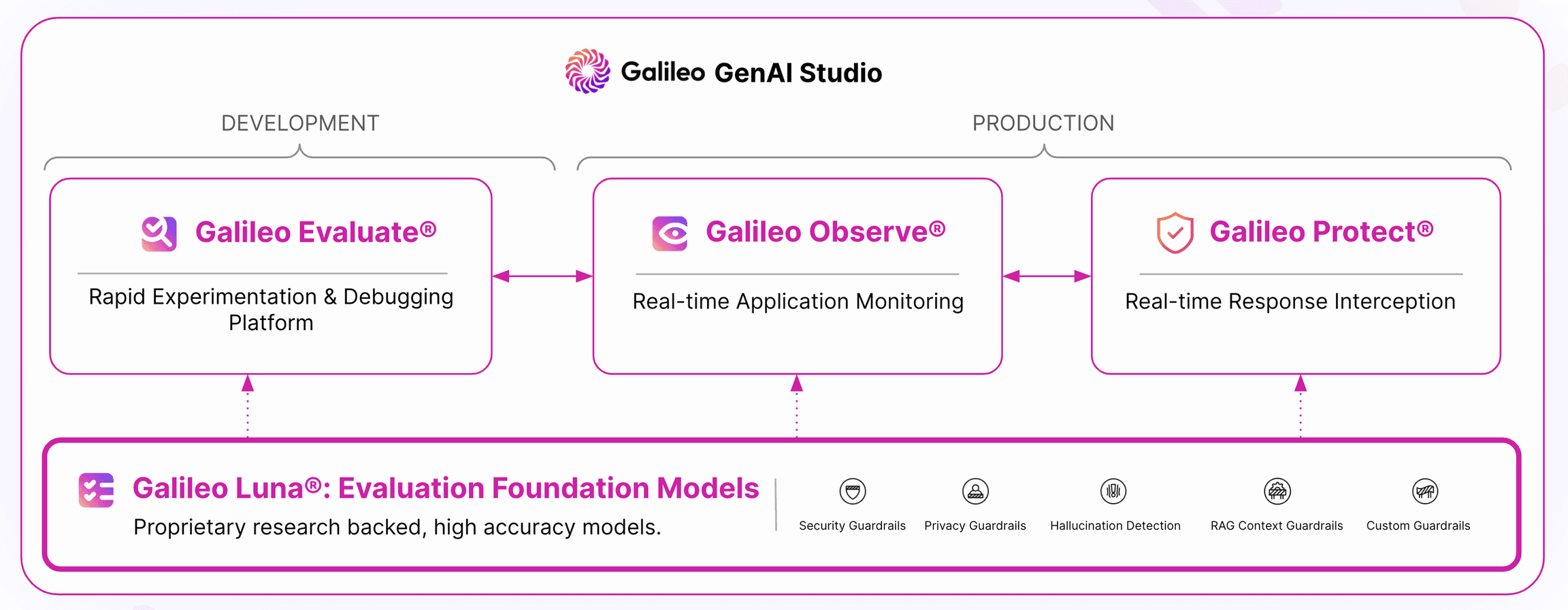
What Galileo does well
- Hallucination at scale: Luna-2 is a small evaluator model trained for groundedness. Flat per-token cost makes it the price leader at 1B plus tokens/month.
- Custom metrics: registered Python functions for deterministic checks, plus LLM-judge support via Galileo’s custom metrics framework.
- Guardrails: toxicity, bias, PII filtering.
- Agentic evals: newer surface (2025), credible.
Where Future AGI has the edge
- Breadth: 50 plus built-in metrics vs Galileo’s narrower catalog; multimodal vs Galileo’s text/image only.
- Stack: gateway plus simulation plus prompt versioning in one platform.
- License: Apache 2.0 OSS plus commercial dashboard, vs Galileo’s closed source.
- Free tier: 50 GB tracing free vs Galileo’s sales-call gate.
Galileo’s flat per-token Luna-2 pricing is genuinely sharp at extreme volume. Future AGI’s built-in groundedness and hallucination evaluators cover the same workload via credit pricing and add simulation and gateway in the same stack, so the cost trade only matters for teams whose eval bill dominates everything else.
Tool 3: Arize AI
Arize splits into two products in 2026: Phoenix (source-available observability under Elastic 2.0 dual licensing) and Arize AX (commercial enterprise platform).

What Arize does well
- Phoenix: solid source-available tracing UI, popular as a self-host observability layer.
- Specialised evaluators: HallucinationEvaluator, QAEvaluator, RelevanceEvaluator.
- LLM-as-a-Judge: well-documented patterns for human-in-the-loop workflows.
- Multimodal: text, image, audio.
- Integrations: LangChain, LlamaIndex, Azure OpenAI, Vertex AI.
Where Future AGI has the edge
- Eval depth: Future AGI ships more built-in eval templates than Phoenix or AX.
- Gateway: Arize does not have an LLM gateway product. Future AGI’s Agent Command Center handles BYOK routing across 100 plus providers.
- Simulation: Future AGI runs persona-driven load tests against any agent runtime. Arize has no equivalent.
If you want self-hostable observability without any commercial dependency, Phoenix is a respectable choice (source-available under Elastic 2.0, not OSI open source). Future AGI’s traceAI is Apache 2.0 OSI open source and ships with a deeper eval catalog plus the commercial dashboard you can opt into.
Tool 4: MLflow
MLflow is the Linux Foundation’s Apache 2.0 ML lifecycle platform. LLM and GenAI eval shipped in 2024 and matured through 2025-2026.

What MLflow does well
- End-to-end lifecycle: experiment tracking, model registry, deployment, plus evaluation in one open platform.
- Apache 2.0 end to end: no commercial gates.
- Cross-domain: works for classical ML and GenAI in the same UI.
- Managed offerings: Databricks, SageMaker, and Azure ML host MLflow.
- Multi-language SDKs: Python, REST, R, Java.
Where Future AGI has the edge
- GenAI eval breadth: MLflow’s eval surface is lighter than Future AGI’s (fewer built-in metrics, less multimodal coverage).
- Production observability: MLflow tracks experiments; Future AGI traces live production with span-level eval scores.
- Guardrails and gateway: MLflow has neither. Future AGI has both.
If you already run MLflow for classical ML, the unification story is real and MLflow is the right pick. If you are starting fresh and your stack is GenAI-first, Future AGI gives a faster path to a complete eval+observability+gateway loop.
Tool 5: Patronus AI
Patronus AI ships hallucination detection (Lynx evaluator), rubric-based scoring, and safety evals. Focused on regulated industries.

What Patronus does well
- Hallucination detection: Lynx is a fine-tuned evaluator trained for groundedness.
- Rubric-based scoring: Likert-style scoring on custom rubrics for tone, clarity, task completeness.
- Safety evals: no-gender-bias, no-age-bias, no-racial-bias evaluators.
- Format validation: is-json, is-code, is-csv.
- Custom evaluators: function-based, class-based, and LLM-judge patterns.
- MongoDB partnership: pre-built RAG evaluation flows on Atlas.
Where Future AGI has the edge
- Catalog size: Future AGI ships 50 plus built-in eval templates; Patronus is in the 12-20 range.
- Multimodal: Future AGI supports audio; Patronus is text plus image.
- Free tier: Future AGI’s free tier is generous; Patronus is sales-call gated.
- Gateway and simulation: only Future AGI bundles these.
Patronus is sharp on hallucination and compliance. For teams whose entire eval problem is “did the LLM lie,” Patronus and Galileo both compete strongly on that axis. Future AGI also covers hallucination, while offering a broader metric catalog plus tracing, simulation, and gateway in one platform.
Side-by-side comparison: May 2026
| Capability | Future AGI | Galileo | Arize (Phoenix + AX) | MLflow | Patronus AI |
|---|---|---|---|---|---|
| Multimodal | Text, image, audio (video beta) | Text, image | Text, image, audio | Text | Text, image |
| Built-in eval templates | 50 plus (broad) | Narrower | Narrower | Limited | Narrower |
| OSS license | Apache 2.0 (libs) | Closed | Elastic 2.0 (Phoenix) | Apache 2.0 | Closed |
| LLM gateway (BYOK) | Yes (Agent Command Center) | No | No | No | No |
| Simulation | Yes (persona-driven) | No | No | No | No |
| Real-time guardrails | 18 plus scanners (Protect) | Yes | Yes | No | Yes |
| Custom LLM judge | Yes | Yes | Yes | Yes | Yes |
| Agent-as-judge | Yes | Yes | Yes | No | Yes |
| Deterministic eval | Yes | Yes | Yes | Limited | Yes |
| Self-host | Yes | No (cloud) | Yes (Phoenix only) | Yes | No |
| Free tier | Generous (50 GB tracing + 2,000 credits) | Sales call | Phoenix OSS free | Free self-host | Sales call |
| Best at | Breadth + integration | Hallucination at extreme volume | OSS observability | ML+LLM unification | Safety, compliance |
Key takeaways: what each tool does best
- Future AGI delivers the most comprehensive bundle (50 plus metrics, multimodal, traceAI tracing, Agent Command Center gateway, simulation, guardrails) with Apache 2.0 eval and tracing libraries plus a commercial dashboard that has a generous free tier.
- Galileo owns the flat per-token cost ceiling for hallucination at extreme volume via Luna-2.
- Arize Phoenix is the cleanest self-hostable observability layer (source-available under Elastic 2.0) if you need to host without any commercial coupling.
- MLflow is the right pick if you already run MLflow for classical ML and want one platform across ML and GenAI.
- Patronus AI wins on safety-first, compliance-heavy workflows where Lynx hallucination detection plus rubric scoring matches the regulatory shape.
Why Future AGI stands out for end-to-end LLM evaluation in 2026
Each tool brings real strengths. MLflow gives unified lifecycle management. Arize gives clean OSS tracing. Galileo gives sharp flat-rate hallucination scoring. Patronus gives compliance-tuned evaluators.
Future AGI unifies the same capabilities (and more) in a single low-code platform with Apache 2.0 libraries and a commercial dashboard: 50 plus eval metrics across text, image, and audio; Apache 2.0 OpenTelemetry tracing via traceAI; an LLM gateway with BYOK on 100 plus providers (Agent Command Center); agent-as-judge; simulation; real-time guardrails. Customer case studies (retail analytics SQL accuracy, EdTech KPI workflows) document the measured gains on specific workloads. Future AGI is the natural default for teams who want one platform instead of stitching three together.
Start free at futureagi.com or read the eval architecture deep-dive for the engineering view.
Sources
[1] The Verge: CNET AI-written stories with errors
[2] BBC: Apple suspends AI news feature
[3] Forbes: Air Canada chatbot ruling
[4] Future AGI EdTech case study
[5] Future AGI retail SQL case study
[6] Future AGI ai-evaluation library, Apache 2.0
[7] traceAI, Apache 2.0 OpenTelemetry instrumentation
[8] Galileo Luna-2 announcement
[10] MLflow on GitHub
Frequently asked questions
What is the best LLM evaluation tool in 2026?
What is the difference between Future AGI and Galileo for LLM evaluation in 2026?
Are any of these LLM evaluation tools open source?
Do I need separate tools for LLM evaluation and observability in 2026?
What is the cheapest LLM evaluation tool for startups in 2026?
What evaluation metrics matter most in 2026?
How do I evaluate an LLM agent (not just a single prompt) in 2026?
Can I run LLM evaluation offline before deployment?

Build a generative AI chatbot in 2026: model selection, RAG, prompt-opt, evaluation, observability, guardrails, gateway. Step-by-step with current tooling.


LangChain callbacks in 2026: every lifecycle event, sync vs async handlers, runnable config patterns, and how to wire callbacks into OpenTelemetry traces.

How to build production AI chatbots in 2026. Compare GPT-5, Claude Opus 4.7, Gemini 3, Llama 4. RAG, agentic memory, eval, and handoff patterns that ship.
