Controllable TalkNet on Hugging Face in 2026: TTS Architecture, Setup, and Evaluation
Controllable TalkNet on Hugging Face in 2026: how the TTS model works, pitch and duration controls, install steps, ethics, evaluating voice output.

Table of Contents
Controllable TalkNet on Hugging Face in 2026: the right framing first
Controllable TalkNet is a text-to-speech model, not a text generation model. It takes a written sentence and produces audio. The “controllable” part is what made it popular in the singing-voice and character-cover community: the user can supply an explicit pitch contour and explicit per-phoneme durations, and the model will follow them. The base architecture comes from NVIDIA’s TalkNet 2 (arXiv:2104.08189); the fork most people interact with on Hugging Face Spaces and Colab is by community author SortAnon, who maintains the ControllableTalkNet repo and the matching demo.
This article is the 2026 walkthrough: what TalkNet actually does, how the controllable fork extends it, how to run it from Hugging Face or locally, how to evaluate the output, and where TalkNet fits in the broader open-weight and publicly available TTS landscape that now includes Coqui XTTS-v2, Bark, MetaVoice, Parler-TTS, and OpenVoice.
TL;DR
| Question | Short answer |
|---|---|
| What is TalkNet? | A non-autoregressive neural TTS model from NVIDIA that predicts duration, pitch, and a mel-spectrogram, then hands the mel to a vocoder. |
| What is “Controllable” TalkNet? | A community fork (SortAnon) that exposes pitch and duration so the user can re-pitch and re-time a target voice without retraining. |
| Where do I try it? | The SortAnon Hugging Face Space and the matching Colab notebook, or a local install of ControllableTalkNet. |
| Is it a text generation model? | No. It is text-to-speech. |
| What is more common for general TTS in 2026? | Open-weight and publicly available models (Coqui XTTS-v2, Bark, MetaVoice, Parler-TTS, OpenVoice) and hosted APIs (ElevenLabs, Cartesia) for production voice agents. TalkNet still leads in the singing-voice and character-cover niche. |
| How do I evaluate output quality? | WER through an ASR like Whisper, speaker similarity (ECAPA-TDNN), pitch RMSE, duration error, plus end-to-end conversation evaluation through traceAI + fi.evals. |
What is TalkNet?
TalkNet is a non-autoregressive convolutional TTS model. It splits speech synthesis into four predictable steps:
- A grapheme-to-phoneme (G2P) front end converts text into a phoneme sequence (CMUdict / ARPABET in the canonical NVIDIA implementation).
- A duration predictor decides how long each phoneme should last.
- A pitch predictor decides the fundamental frequency at each frame.
- A mel-spectrogram generator produces the spectrogram, which a separate vocoder (HiFi-GAN is the common pairing) converts to a waveform.
Because the duration and pitch are predicted up front and the rest of the network is non-autoregressive, TalkNet is fast at inference and stays stable across long utterances. NVIDIA’s original TalkNet 2 is described in Beliaev and Ginsburg, 2021 (arXiv:2104.08189).
The image below shows the canonical TalkNet pipeline: text passes through G2P, duration prediction, pitch prediction, and a mel generator before the vocoder.

What “Controllable” adds on top
The community fork that is most commonly called “Controllable TalkNet” lives at github.com/SortAnon/ControllableTalkNet. Its key additions:
- Explicit phoneme-level duration control. The user can lengthen or shorten any phoneme.
- Explicit pitch contour control. A reference audio can drive the pitch curve for the target voice.
- Reference audio matching. Provide an audio clip and the model will try to match its prosody when speaking new text in the target voice.
- A library of community-trained voices. Many of the voices used in the wider Pony Preservation Project and similar communities are TalkNet checkpoints, which is why the fork is associated with character covers and singing voice synthesis.
The Hugging Face Spaces demo by the same author exposes these controls in a browser UI, which is the lowest-friction way to try TalkNet.
Running Controllable TalkNet
Option 1: Hugging Face Space or Colab
The fastest path is the community Colab and the Hugging Face Space by SortAnon. Pick a voice, paste text (or upload reference audio), tweak pitch and duration in the UI, generate. This is good for prototyping a voice match and for non-engineers who only need a clip.
Option 2: Local install
git clone https://github.com/SortAnon/ControllableTalkNet.git
cd ControllableTalkNet
pip install -r requirements.txtYou will need PyTorch with a CUDA-capable GPU for reasonable speed on inference. The repo’s README documents the model checkpoints and the expected directory layout. For new projects, prefer a more recent TTS stack (XTTS-v2, Parler-TTS, OpenVoice) and treat TalkNet as a specialist tool when you need explicit pitch and duration control.
Option 3: Programmatic use in a voice agent
Most production voice agents do not call TalkNet directly. They call a managed TTS API for the TTS step and use TalkNet only for offline tooling (voice match, dataset creation, dubbing). If you do wire TalkNet into a serving path, the usual shape is: ASR (Whisper) → LLM → TalkNet → vocoder → audio out, with traceAI instrumenting each step so you can see WER, LLM latency, and TTS latency in one trace.
Evaluating TalkNet output
Voice quality has four core measurable dimensions. Track each one.
1. Intelligibility (WER)
Run an ASR model (Whisper, Distil-Whisper, or Faster-Whisper) over the synthesized audio and compute word error rate against the source text. WER above a few percent on clean text usually means the voice or the vocoder is failing — though WER alone is not enough for voice agents.
2. Speaker similarity
If you are trying to match a target voice, compute speaker embeddings with ECAPA-TDNN (SpeechBrain) for the synthesized audio and a reference clip, then take cosine similarity. Higher is better; below 0.6 usually means the voice does not match.
3. Prosody fidelity
Compare pitch contour and per-phoneme duration of the synthesized audio against the reference. Standard metrics are pitch RMSE (Hz) and average phoneme duration error (ms). These are the metrics that matter for singing-voice work and dubbing. The full rubric set is in how to evaluate TTS quality for voice AI.
4. End-to-end conversation quality (for voice agents)
For agents that use TalkNet (or any TTS) inside a real conversation, the right level of evaluation is the conversation turn, not the audio clip. Capture traces of the full agent, score each turn for task completion, helpfulness, and safety, and route findings back into the prompt or the TTS configuration.
This is where evaluation tooling earns its keep. Future AGI’s ai-evaluation library (Apache 2.0) ships evaluators that work on trace data:
from fi.evals import evaluate
score = evaluate(
"answer_relevance",
output="Your appointment is confirmed for Thursday at 10am.",
context="User asked to book Thursday morning.",
)
print(score)For traces, traceAI (Apache 2.0) is the OpenTelemetry-native instrumentation library. It exports spans from any LLM or agent framework via fi_instrumentation.register and FITracer and bundles auto-instrumentors such as traceai-langchain (LangChainInstrumentor), traceai-openai-agents, traceai-llama-index, and traceai-mcp. A voice agent emits one trace per turn with spans for ASR, LLM, and TTS, which is what makes per-step quality and per-step latency visible. Future AGI cloud judges available through fi.evals.evaluate include turing_flash (about 1 to 2 seconds), turing_small (about 2 to 3 seconds), and turing_large (about 3 to 5 seconds) per the cloud-evals reference.
Ethics, consent, and guardrails
Voice cloning systems amplify all the existing risks of synthetic media. The deeper treatment is in voice cloning safety and brand voice management. The 2026 minimum bar:
- Consent. Use only voices you have a rights agreement for. Public figures are not opt-in by default.
- Disclosure. Synthetic audio should be labeled, especially in customer-facing and journalistic contexts.
- Watermarking. Where feasible, embed inaudible watermarks so synthesized audio can be detected downstream.
- Policy guardrails on production agents. Restrict the prompts that can reach the TTS step (no impersonating real people, no harassment, no political fundraising in regulated contexts). Future AGI’s
fi.evals.guardrails.Guardrailsand the Agent Command Center BYOK gateway at/platform/monitor/command-centercan evaluate every voice-agent turn against these rules and, when wired into a blocking workflow, gate the call before TTS runs.
Real-world applications
Where Controllable TalkNet specifically shines:
- Character voice covers and singing voice synthesis. The pitch control is what made the model popular in the fan-music community.
- Dataset prototyping. Quickly produce a sketch of how a target voice would sound saying new text before recording a real performance.
- Offline dubbing experiments. Provide a reference performance and ask TalkNet to speak new lines that match its prosody.
For general voice agents, customer support, and scaled content production, modern TTS stacks (XTTS-v2, Parler-TTS, OpenVoice, or managed APIs like ElevenLabs and Cartesia) are usually a better fit.
How Controllable TalkNet compares to other open-weight TTS options in 2026
This is a no-rank list of open-weight and publicly available options; the right choice depends on your use case and the model’s license.
- Controllable TalkNet (SortAnon fork): explicit pitch and duration control; strong for singing voice and character covers; smaller installed footprint of pretrained character voices.
- Coqui XTTS-v2: voice cloning from a few seconds of reference audio; multilingual; widely deployed for general TTS.
- Bark (Suno): expressive non-verbal sounds and music; slower; harder to control prosody precisely.
- Parler-TTS: text-prompt controllable TTS; good for descriptive style control (“a slow, calm female voice”).
- MetaVoice-1B: 1B-parameter open-weight TTS with voice cloning.
- OpenVoice (MyShell): style and voice transfer from a short reference.
For production voice agents you also have hosted APIs (ElevenLabs, Cartesia, OpenAI voice, Google TTS), which trade open weights for lower latency and SLA-backed availability.
Limitations and what to watch in 2026
- TalkNet is not a generative LLM. If you want to change what the voice says, change the upstream LLM. TalkNet only changes how it sounds.
- Modern open-weight TTS has caught up on quality and added cloning. XTTS-v2, OpenVoice, and Parler-TTS cover use cases TalkNet does not.
- The community fork’s release cadence is slow. Treat it as a specialist tool rather than a maintained production dependency.
- Voice cloning regulation is tightening. Expect more jurisdictions to require disclosure of synthetic audio; build the disclosure into the agent surface, not as an afterthought.
How Future AGI helps voice teams evaluate and monitor TTS pipelines
TTS itself is not Future AGI’s product. The platform’s role around a TalkNet (or XTTS-v2, or ElevenLabs) deployment is the evaluation, observability, and guardrail layer:
- traceAI (Apache 2.0) instruments the full ASR → LLM → TTS stack with OpenTelemetry spans through
fi_instrumentation.register+FITracer, plus auto-instrumentors for LangChain, LlamaIndex, OpenAI Agents, and MCP. - fi.evals.evaluate and fi.evals.Evaluator score the spoken conversation per turn for helpfulness, answer relevance, faithfulness, and tool correctness.
- fi.evals.metrics.CustomLLMJudge + fi.evals.llm.LiteLLMProvider let you bring your own LLM judge for voice-specific criteria (clarity, persona match).
- fi.simulate.TestRunner generates synthetic voice agent scenarios so you can A/B prosody and prompts before they hit production.
- fi.evals.guardrails.Guardrails plus the Agent Command Center BYOK gateway at
/platform/monitor/command-centerevaluate every call against safety, brand voice, and synthetic-audio disclosure policies, and can be wired into approval or blocking workflows where the team chooses to enforce them inline.
Authentication uses FI_API_KEY and FI_SECRET_KEY (two variables, not one).
Summary
Controllable TalkNet on Hugging Face is a text-to-speech model with explicit pitch and duration control, derived from NVIDIA’s TalkNet 2 and packaged as the community SortAnon fork. It is not a text generator; it does not invent prose. In 2026, TalkNet remains the right tool for singing voice and character cover work, while general voice agents have moved to XTTS-v2, Parler-TTS, OpenVoice, and managed APIs. Whatever TTS stack you ship, instrument it with traceAI, evaluate every turn with fi.evals.evaluate, and put guardrails around what the voice is allowed to say.
Frequently asked questions
What is Controllable TalkNet?
Is Controllable TalkNet a text generation model?
Where can I run Controllable TalkNet?
What does 'controllable' actually mean here?
How do I evaluate the quality of a TalkNet voice in 2026?
Are there ethical concerns with TalkNet-style voice cloning?
Which Hugging Face Space is the canonical Controllable TalkNet demo?
What replaces TalkNet for new TTS projects in 2026?
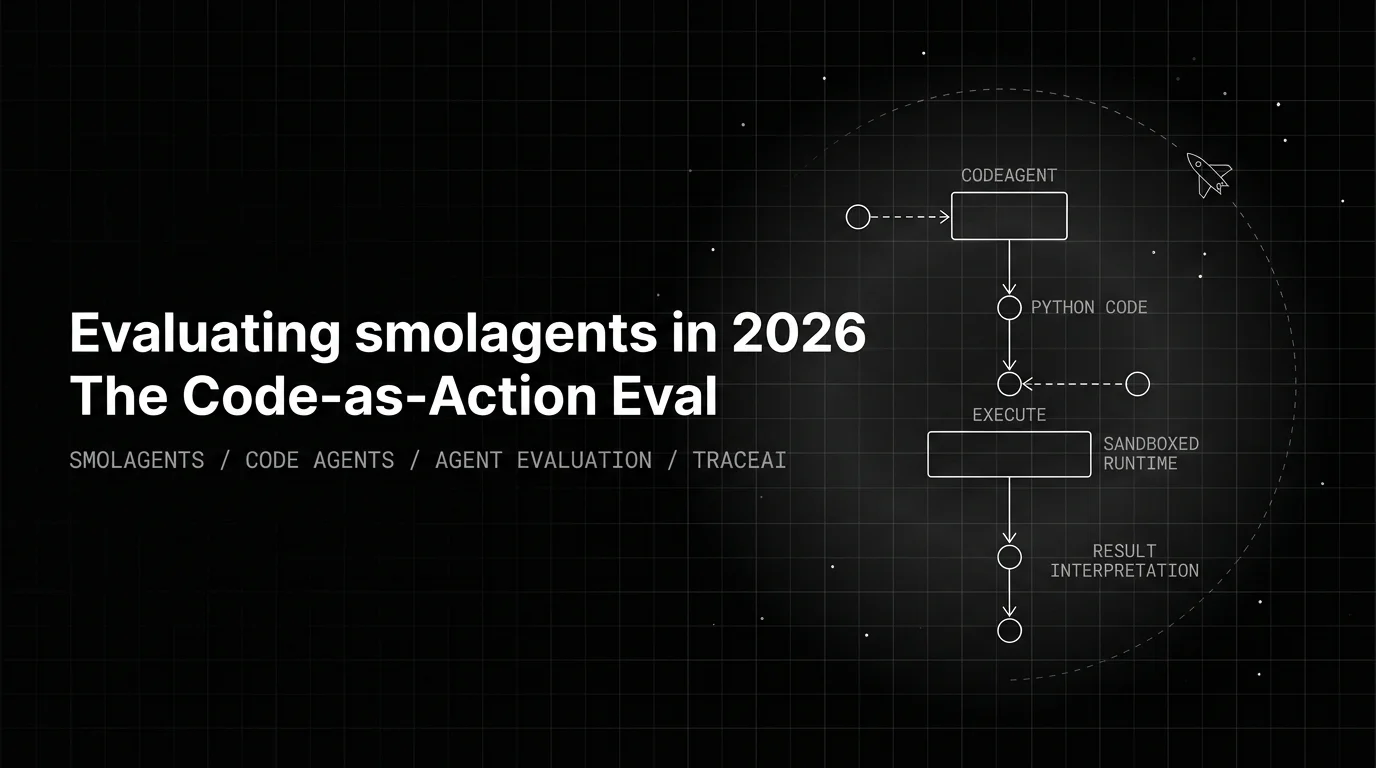
smolagents' CodeAgent makes the plan AS code, so the eval changes shape: code synthesis correctness, sandbox safety, and result-interpretation fidelity.


ElevenLabs vs Cartesia in 2026: streaming TTFA latency, voice realism, cloning, multilingual coverage, SSML, pricing, same-rubric evaluation guide.


Tested and ranked: 7 best TTS providers for voice AI agents 2026, with real per-character pricing, streaming TTFA latency, voice cloning, SSML support.
