RAG Prompting to Reduce Hallucination
Discover how Retrieval-Augmented Generation (RAG) and strategic prompting reduce AI hallucinations, improving the accuracy and reliability of model responses.

Table of Contents
Introduction
Building on our previous blog on advanced chunking strategies to enhance RAG performance, this edition delves into RAG Prompting to Reduce Hallucination, highlighting techniques that enhance factual accuracy and ensure well-grounded responses. To further explore strategies for mitigating hallucinations in LLMs, check out our detailed guide on Taming the Hallucination Beast: Strategies for Reliable LLMs.
We know that RAG combines generative pre-trained models with real-time retrieval mechanism, ensuring the outputs are grounded and up-to-date with current knowledge. Unlike traditional models, which rely solely on the data they were trained on, RAG fetch relevant information from external sources at inference time. For instance, in a traditional language model, like OpenAI’s GPT-4, without RAG, a query like “Why does the Meeseeks Box require maintenance?” might result in a generic or speculative answer. Here’s how it might look:
from langchain.chat_models import ChatOpenAI
from langchain.schema import HumanMessage
llm = ChatOpenAI(model="gpt-4")
query = "Why does the Meeseeks Box require maintenance?"
query_message = [HumanMessage(content=f"Answer the following question: {query}")]
no_rag_response = llm(query_message)
print("Without RAG:")
print("Answer:", no_rag_response.content)Without RAG:
Answer: The show "Rick and Morty" does not provide detailed information on why the Meeseeks Box would require maintenance. This could be due to it being a complex piece of technology, which may need occasional repairs, updates, or checks to ensure it functions correctly. It could also be due to the fact that each use of the box creates a sentient being, which could cause wear and tear. However, this is mostly speculative as the show does not explicitly state why the Meeseeks Box requires maintenance.However, when using RAG, the model can retrieve relevant documents from an external knowledge base in real-time to provide a more accurate and grounded response. The choice of chain type plays a pivotal role in how the retrieved information is processed. For example, the stuff chain type combines all retrieved documents into a single input, making it effective for scenarios with concise or limited data. On the other hand, the map_reduce chain type processes each document individually to summarise and then aggregates the results, suitable for larger and complex dataset.
Here’s how RAG works with different chain types:
from langchain.schema import Document
from langchain.chains import RetrievalQA
from langchain.chat_models import ChatOpenAI
from langchain.vectorstores.faiss import FAISS
from langchain.embeddings.openai import OpenAIEmbeddings
embedding_model = OpenAIEmbeddings()
llm = ChatOpenAI(model="gpt-4")
documents = [
Document(page_content="The Meeseeks Box begins its creation process by harvesting proto-Meeseeks from a quantum foam field, a process that stabilizes subatomic particles for practical tasks."),
Document(page_content="Quantum foam fields require careful maintenance, as disruptions can lead to unstable proto-Meeseeks that fail to complete tasks."),
Document(page_content="The harvested proto-Meeseeks are condensed into small energy packets, which must remain in temporal stasis until activated."),
Document(page_content="Maintenance ensures the anti-decay field that stabilizes the Meeseeks remains functional, preventing disintegration during tasks."),
Document(page_content="Each Meeseeks is programmed with a neural imprinting laser that assigns it a single task, ensuring focus and efficiency."),
Document(page_content="The Meeseeks Box requires periodic calibration of its logic circuits, which randomly assign objectives like opening jars or solving math problems."),
Document(page_content="Overusing the Meeseeks Box can deplete its quantum foam reservoir, necessitating regular recharges to maintain functionality."),
Document(page_content="Without proper maintenance, the Meeseeks Box may fail to stabilize Meeseeks, leading to chaotic behavior or premature disintegration."),
Document(page_content="Periodic maintenance involves recharging energy packets, recalibrating circuits, and inspecting neural laser systems for precision."),
]
vectorstore = FAISS.from_documents(documents, embedding_model)
retriever = vectorstore.as_retriever()
chain_types = ["stuff", "map_reduce"]
for chain_type in chain_types:
rag_chain = RetrievalQA.from_chain_type(
llm=llm,
retriever=retriever,
chain_type=chain_type,
return_source_documents=True,
)
rag_response = rag_chain({"query": query})
print(f"\\nWith RAG (chain type: {chain_type}):")
print("Answer:", rag_response["result"])
print("--" * 20)
print("\\nSource Documents:")
for doc in rag_response["source_documents"]:
print("- ", doc.page_content)With RAG (chain type: stuff):
Answer: The Meeseeks Box requires maintenance for several reasons. First, without proper maintenance, the box may fail to stabilize Meeseeks, leading to chaotic behavior or premature disintegration. Second, overuse of the box can deplete its quantum foam reservoir, which requires regular recharges to maintain functionality. Lastly, the box requires periodic calibration of its logic circuits, which are used to randomly assign objectives to the Meeseeks. Maintenance also ensures the anti-decay field that stabilizes the Meeseeks remains functional, preventing them from disintegrating during tasks.
----------------------------------------
With RAG (chain type: map_reduce):
Answer: The Meeseeks Box requires maintenance to stabilize the Meeseeks and prevent chaotic behavior or premature disintegration. Maintenance is also needed to recharge the quantum foam reservoir if the box is overused. Additionally, periodic calibration of its logic circuits is required for the random assignment of objectives. This maintenance ensures the functionality of the anti-decay field that prevents the Meeseeks from disintegrating during tasks.
----------------------------------------
Source Documents:
- The Meeseeks Box requires periodic maintenance to recharge its quantum foam reservoir, which can run dry if overused.
- The Meeseeks Box has an internal logic circuit that randomly assigns objectives, such as opening jars, solving math problems, or organizing sock drawers.
- When the button on the Meeseeks Box is pressed, it releases a fully-formed Meeseeks, temporarily stabilized in our dimension by an anti-decay field.
- The Meeseeks Box begins its creation process by harvesting proto-Meeseeks from a quantum foam field.RAG’s ability to provide accurate and relevant responses depends significantly on the quality of the prompts used. Effective prompt engineering helps guide the model to better utilise the retrieved information and reduces the likelihood of irrelevant or speculative answers. Additionally, the choice of further impacts the quality.
For example, consider the following two prompts for the same query:
- Generic Prompt: “Why does the Meeseeks Box require maintenance?”
- Specific Prompt: “Based on retrieved documents, explain the maintenance requirements of the Meeseeks Box.”
The second prompt is more precise, explicitly directing the model to ground its response in the retrieved content. This improves factual accuracy and coherence. However, when combined with the map_reduce chain, the process becomes even more robust. The map_reduce chain processes each document individually, summarises its key points, and then combines these summaries to produce a cohesive and comprehensive answer. This approach minimises the risk of information overload and ensures that the model can handle larger datasets more effectively than the stuff chain.
Let’s now explore different types of prompts to improve RAG’s performance, using different chain types to evaluate how effectively each prompt guides the model’s responses
Types of Prompting Techniques
To demonstrate how different prompting techniques enhances RAG’s performance and reducing hallucinations, we will explore them with an example query and document:
documents = [
Document(page_content="The Meeseeks Box begins its creation process by harvesting proto-Meeseeks from a quantum foam field."),
Document(page_content="The harvested proto-Meeseeks are condensed into small energy packets and stored in temporal stasis inside the Meeseeks Box."),
Document(page_content="A neural imprinting laser programs each Meeseeks with a single objective, ensuring they are perfectly task-oriented."),
Document(page_content="The Meeseeks Box has an internal logic circuit that randomly assigns objectives, such as opening jars, solving math problems, or organizing sock drawers."),
Document(page_content="When the button on the Meeseeks Box is pressed, it releases a fully-formed Meeseeks, temporarily stabilized in our dimension by an anti-decay field."),
Document(page_content="After completing their task, the Meeseeks are designed to disintegrate into harmless particles of joy-energy, which dissipate harmlessly into the atmosphere."),
Document(page_content="The Meeseeks Box requires periodic maintenance to recharge its quantum foam reservoir, which can run dry if overused."),
]
query = "Why does the Meeseeks Box require maintenance?"Retrieved documents using above query:
Source Documents:
- The Meeseeks Box requires periodic maintenance to recharge its quantum foam reservoir, which can run dry if overused.
- The Meeseeks Box has an internal logic circuit that randomly assigns objectives, such as opening jars, solving math problems, or organizing sock drawers.
- When the button on the Meeseeks Box is pressed, it releases a fully-formed Meeseeks, temporarily stabilized in our dimension by an anti-decay field.
- The Meeseeks Box begins its creation process by harvesting proto-Meeseeks from a quantum foam field.a. Baseline prompt
- This is the simplest type of prompt where the model is directly asked to answer a question without any additional guidance or examples.
"Answer the following question: {query}"Answer: The Meeseeks Box requires periodic maintenance to recharge its quantum foam reservoir. This reservoir can run dry if the box is overused.- Without explicit context or guidance, the model may produce irrelevant or inaccurate answers, increasing the risk of hallucinations.
b. Context Highlighting
- This prompt explicitly instructs the model to rely only on the provided context to respond.
'''
Use only the following retrieved context to answer the question:
{context}
Question: {query}
'''Answer: The Meeseeks Box requires maintenance to recharge its quantum foam reservoir, which can run dry if overused.- It can sometimes restrict the model’s flexibility, making it less capable of exploring ideas beyond the provided context.
c. Step-by-Step Reasoning
- This method encourages the model to break down its thought process into logical steps before answering.
'''
Given the retrieved context, think step by step and provide a detailed explanation for the following question:
{context}
Question: {query}"
'''Answer: The Meeseeks Box requires periodic maintenance to recharge its quantum foam reservoir. This reservoir can run dry if the box is overused.- Effective for complex questions but might feel redundant or overly verbose for simple queries.
d. Fact Verification
- This prompt ensure the model validates its response against the provided context for accuracy.
- This reduces errors and helps build confidence in the reliability of the output.
'''
Verify the answer to the following question using the provided context. Ensure factual accuracy:
{context}
Question: {query}
'''Answer: The Meeseeks Box requires periodic maintenance to recharge its quantum foam reservoir, which can run dry if overused.- Its effectiveness depends on the quality and completeness of the provided context
e. Role-Based Prompting
- This approach frames the model as a specific persona, allowing it to respond with specialized knowledge and insights.
- Ideal for domain-specific queries or tailored responses.
'''
You are an expert in the show called Rick and Morty. Use the retrieved context to answer the following question as an expert would:
{context}
Question: {query}
'''Answer: The Meeseeks Box requires periodic maintenance to recharge its quantum foam reservoir. This reservoir can run dry if the Box is overused.- Can sometimes overly narrow the focus, limiting consideration of broader or alternative perspectives.
Evaluating Prompts
To determine the most effective prompting technique for reducing hallucination in a RAG system, we evaluate outputs using a consistent query and analyze their alignment with retrieved context to ensure accuracy and coherence.
a. BLEU
- Measures n-gram overlap between the response and the source documents to evaluate how closely the response matches the original text.
- Combines all retrieved documents into a single text and then calculates n-gram overlap.
from nltk.translate.bleu_score import sentence_bleu, SmoothingFunction
def compute_bleu(response, source_documents):
source_content = " ".join(doc.page_content for doc in source_documents)
smoothing = SmoothingFunction().method1
return sentence_bleu([source_content.split()], response.split(), smoothing_function=smoothing)b. ROUGE-L
- Evaluates the lexical overlap between the response and the source documents by measuring the longest common subsequence (LCS).
- Combines all retrieved documents into a single text and then compares this aggregated text with the response to compute the LCS-based ROUGE-L score.
from rouge import Rouge
rouge = Rouge()
def compute_rouge(response, source_documents):
source_content = " ".join(doc.page_content for doc in source_documents)
scores = rouge.get_scores(response, source_content)
return scores[0]["rouge-l"]["f"]c. BERT Score
- Measures token-level semantic similarity using contextual embeddings.
- Aggregates the source content and computes contextual embeddings for both the response and source. Then compute precision, recall, and F1 scores between the response and source content.
from bert_score import score as bert_score
def compute_bertscore(response, source_documents):
source_content = " ".join(doc.page_content for doc in source_documents)
precision, recall, f1 = bert_score([response], [source_content], model_type="bert-base-uncased", lang="en")
return f1.mean().item()d. Embedding Similarity
- Measures the semantic alignment between the generated response and the retrieved documents.
- Converts the response and source documents into vector representations. Then, it computes cosine similarity for each pair and selects the maximum similarity score.
from sentence_transformers import SentenceTransformer, util
model = SentenceTransformer('distilbert-base-nli-stsb-mean-tokens')
def embedding_similarity(response, source_documents):
response_embedding = model.encode(response, convert_to_tensor=True)
source_embeddings = [model.encode(doc.page_content, convert_to_tensor=True) for doc in source_documents]
similarities = [util.cos_sim(response_embedding, source_emb).item() for source_emb in source_embeddings]
return max(similarities)Result
The following Python code generates responses for each prompt, calculates the metrics, and prepares the results for easy comparison:
results = []
for prompt_name, prompt_template in prompts.items():
rag_response = rag_chain({"query": query})
source_docs = rag_response["source_documents"]
retrieved_context = " ".join([doc.page_content for doc in source_docs])
formatted_query = (
prompt_template.format(query=query, context=retrieved_context)
if "{context}" in prompt_template
else prompt_template.format(query=query)
)
answer = rag_response.get("result", "No result found")
bleu = compute_bleu(answer, source_docs)
rouge_l = compute_rouge(answer, source_docs)
similarity_score = embedding_similarity(answer, source_docs)
bertscore = compute_bertscore(answer, source_docs)
results.append({
"Prompt": prompt_name,
"BLEU": bleu,
"ROUGE-L": rouge_l,
"BERT Score": bertscore,
"Embedding Similarity": similarity_score
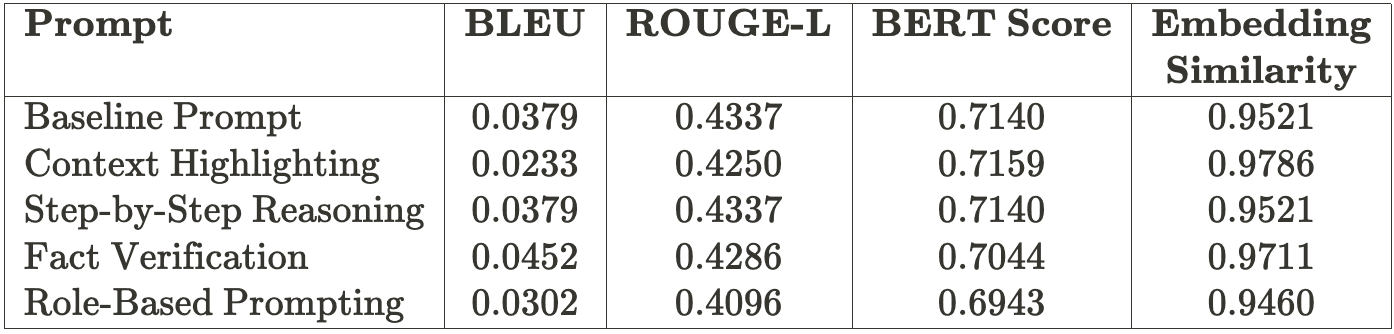
})Below is the evaluation of different prompts using the stuff chain type:
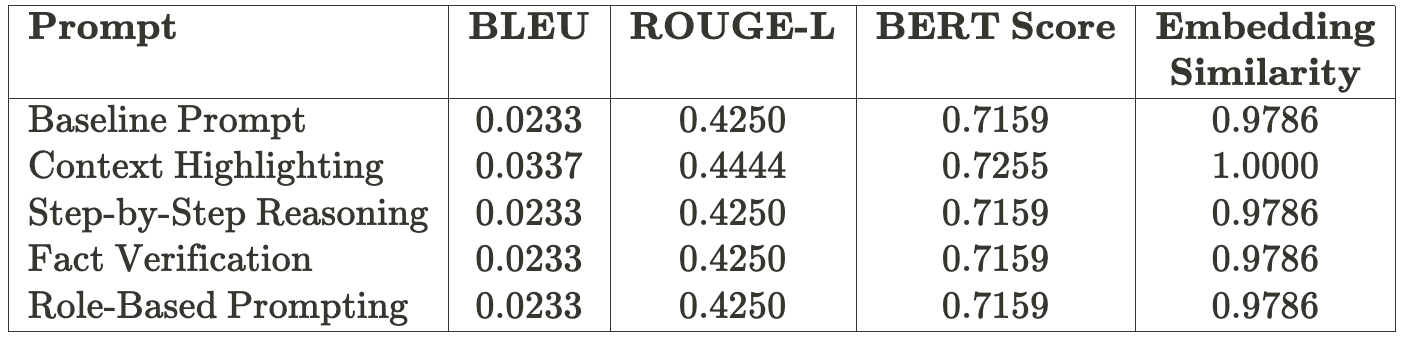
Below is the evaluation of different prompts using the map_reduce chain type:
Conclusion
- The stuff chain shows variability across prompts because it processes all retrieved documents as a single input, making it more susceptible to token limits and the relative quality of individual prompts.
- The map_reduce chain processes documents individually, ensuring each contributes equally to the final response, thus resulting in more consistent performance across the prompts.
- Context Highlighting excels in both chains, showcasing its adaptability and effectiveness in grounding responses to retrieved content.
- Baseline Prompt delivers steady but average performance due to its lack of specificity.
- Step-by-step reasoning ensures logical flow but shows minimal improvement due to its broad approach.
- Fact verification performs well in the stuff chain due to its focus on specific details, boosting BLEU scores, but struggles with semantic alignment due to weaker contextual grounding.
- Role-based prompting underperforms across chains as it lacks a clear focus on retrieved content, leading to weaker grounding and coherence.
Related Articles
View all
How to Build LLM Agents for Real-World Applications
Learn how to build LLM agents for AI automation. Explore key concepts, tools, and best practices to create intelligent, efficient AI-powered workflows.


Best Free AI Search Engines to Try Today
Discover the best free AI search engines like You.com and Perplexity AI. Experience smarter and personalized searches for accurate, efficient information

LLM Fine-Tuning Techniques I & II
Explore LLM fine-tuning techniques to optimize AI models for specific tasks. Learn key strategies, examples, and best practices for enhanced performance.