Advanced RAG Chunking Techniques: A Complete Guide with Code and Evaluation (2026)
Learn fixed, recursive, semantic, and agentic RAG chunking in 2026. Covers five types, Python code examples, retrieval accuracy tradeoffs, and when to use each.

Table of Contents
Why RAG Needs Chunking: Limitations of Full-Document Embeddings
Retrieval-augmented generation (RAG) is a framework that addresses the limitations of any pre-trained models, such as hallucination and outdated information, by allowing the models access to domain-specific and up-to-date data [1]. RAG uses a vector database to store and retrieve semantically relevant information created by indexing vector embeddings of documents. However, creating embeddings of entire documents or even at paragraph level can lead to dilution of contextual accuracy, leading to lesser retrieval precision [2]. Thus, we need a better strategy to create embeddings of documents to preserve contextual meaning and improve retrieval.
What Is Chunking in RAG and Why Does It Matter for Retrieval Accuracy?
Chunking is the process of creating “chunks” of documents. It means splitting documents. Splitting should be done in such a way that each chunk contains semantically coherent information.

Fig 1. Document chunking process
This process becomes essential for long documents, as it helps preserve the flow of information and ensures that the chunks remain useful for tasks like retrieval, summarization, or analysis. Creating semantically coherent chunks retains the integrity of the document’s content.
Types of RAG Chunking: Fixed-Size, Delimiter-Based, and Semantic Approaches Explained
Splitting documents can be done in majorly three ways:
- Fixed-size chunking: Splitting documents into chunks of equal sizes as per the globally defined chunk size. This is the most straightforward approach but is less semantically guided.
- Delimiter-based chunking: splitting documents in such a way that the natural structure of the documents is preserved. This means splitting the document into sentences. Though better than the first one, it avoids cutting sentences in half as a sentence can be considered semantically self-contained, but this method can lead to a lack of broader context.
- Semantic chunking: splitting a document according to the contextual meaning. Each chunk is a semantically cohesive unit with broader contextual awareness, which is required for tasks like text summarization.
Below are detailed explanations of different chunking strategies. To better understand each strategy, we will use the same text example to see how different methods generate chunks.
#Input Text
Mr. and Mrs. Dursley, of number four, Privet Drive, were proud to say that they were perfectly normal, thank you very much. They were the last people you’d expect to be involved in anything strange or mysterious, because they just didn’t hold with such nonsense.
Mr. Dursley was the director of a firm called Grunnings, which made drills. He was a big, beefy man with hardly any neck, although he did have a very large mustache. Mrs. Dursley was thin and blonde and had nearly twice the usual amount of neck, which came in very useful as she spent so much of her time craning over garden fences, spying on the neighbors. The Dursleys had a small son called Dudley and in their opinion there was no finer boy anywhere.
The Dursleys had everything they wanted, but they also had a secret, and their greatest fear was that somebody would discover it. They didn’t think they could bear it if anyone found out about the Potters. Mrs. Potter was Mrs. Dursley’s sister, but they hadn’t met for several years; in fact, Mrs. Dursley pretended she didn’t have a sister, because her sister and her good-for-nothing husband were as unDursleyish as it was possible to be. The Dursleys shuddered to think what the neighbors would say if the Potters arrived in the street. The Dursleys knew that the Potters had a small son, too, but they had never even seen him. This boy was another good reason for keeping the Potters away; they didn’t want Dudley mixing with a child like that.
When Mr. and Mrs. Dursley woke up on the dull, gray Tuesday our story starts, there was nothing about the cloudy sky outside to suggest that strange and mysterious things would soon be happening all over the country. Mr. Dursley hummed as he picked out his most boring tie for work, and Mrs. Dursley gossiped away happily as she wrestled a screaming Dudley into his high chair.RAG Chunking Techniques Explained with Python Code Examples
Fixed Character Splitting for RAG: Separator-Based Chunking with LangChain
-
Splits input text into chunks of fixed size.
-
Does not care about any underlying semantic meaning.
-
This can sometimes lead to words being split arbitrarily.
-
Simple and fast to implement.
-
It takes a separator as an input to create chunks that split text at different points.
- ‘ ’ - Splits text into exact chunk sizes
- ‘ ‘ - Ensures splitting at word boundaries
from langchain.text_splitter import CharacterTextSplitter
char_text_splitter = CharacterTextSplitter(chunk_size= 100, chunk_overlap=0, separator=' ')
char_splitted = char_text_splitter.create_documents([text])[['Mr. and Mrs. Dursley, of number four, Privet Drive, were proud to say that they were perfectly'],
['normal, thank you very much. They were the last people you’d expect to be involved in anything'],
['strange or mysterious, because they just didn’t hold with such nonsense.\\n\\nMr. Dursley was the'],
['director of a firm called Grunnings, which made drills. He was a big, beefy man with hardly any neck,'],
['although he did have a very large mustache. Mrs. Dursley was thin and blonde and had nearly twice'],
['the usual amount of neck, which came in very useful as she spent so much of her time craning over'],
['garden fences, spying on the neighbors. The Dursleys had a small son called Dudley and in their'],
['opinion there was no finer boy anywhere.\\n\\nThe Dursleys had everything they wanted, but they also had'],
['a secret, and their greatest fear was that somebody would discover it. They didn’t think they could'],
['bear it if anyone found out about the Potters. Mrs. Potter was Mrs. Dursley’s sister, but they'],
['hadn’t met for several years; in fact, Mrs. Dursley pretended she didn’t have a sister, because her'],
['sister and her good-for-nothing husband were as unDursleyish as it was possible to be. The Dursleys'],
['shuddered to think what the neighbors would say if the Potters arrived in the street. The Dursleys'],
['knew that the Potters had a small son, too, but they had never even seen him. This boy was another'],
['good reason for keeping the Potters away; they didn’t want Dudley mixing with a child like'],
['that.\\n\\nWhen Mr. and Mrs. Dursley woke up on the dull, gray Tuesday our story starts, there was'],
['nothing about the cloudy sky outside to suggest that strange and mysterious things would soon be'],
['happening all over the country. Mr. Dursley hummed as he picked out his most boring tie for work,'],
['and Mrs. Dursley gossiped away happily as she wrestled a screaming Dudley into his high chair.']]Recursive Character Splitting for RAG: Hierarchical Text Segmentation with LangChain
-
It uses a series of separators hierarchically
"\\n\\n"- Double new line, paragraph breaks"\\n"- New lines" "- Spaces" "- Characters
-
Assumes larger natural boundaries are more likely to contain related and cohesive information.
-
It is not semantically guided and relies too much on structured text for the separators to work.
from langchain.text_splitter import RecursiveCharacterTextSplitter
rec_char_text_splitter = RecursiveCharacterTextSplitter(chunk_size= 100, chunk_overlap=0)
rec_char_splitted = rec_char_text_splitter.create_documents([text])[['Mr. and Mrs. Dursley, of number four, Privet Drive, were proud to say that they were perfectly'],
['normal, thank you very much. They were the last people you’d expect to be involved in anything'],
['strange or mysterious, because they just didn’t hold with such nonsense.'],
['Mr. Dursley was the director of a firm called Grunnings, which made drills. He was a big, beefy man'],
['with hardly any neck, although he did have a very large mustache. Mrs. Dursley was thin and blonde'],
['and had nearly twice the usual amount of neck, which came in very useful as she spent so much of'],
['her time craning over garden fences, spying on the neighbors. The Dursleys had a small son called'],
['Dudley and in their opinion there was no finer boy anywhere.'],
['The Dursleys had everything they wanted, but they also had a secret, and their greatest fear was'],
['that somebody would discover it. They didn’t think they could bear it if anyone found out about the'],
['Potters. Mrs. Potter was Mrs. Dursley’s sister, but they hadn’t met for several years; in fact,'],
['Mrs. Dursley pretended she didn’t have a sister, because her sister and her good-for-nothing'],
['husband were as unDursleyish as it was possible to be. The Dursleys shuddered to think what the'],
['neighbors would say if the Potters arrived in the street. The Dursleys knew that the Potters had a'],
['small son, too, but they had never even seen him. This boy was another good reason for keeping the'],
['Potters away; they didn’t want Dudley mixing with a child like that.'],
['When Mr. and Mrs. Dursley woke up on the dull, gray Tuesday our story starts, there was nothing'],
['about the cloudy sky outside to suggest that strange and mysterious things would soon be happening'],
['all over the country. Mr. Dursley hummed as he picked out his most boring tie for work, and Mrs.'],
['Dursley gossiped away happily as she wrestled a screaming Dudley into his high chair.']]Sentence-Level Splitting for RAG: Linguistically Guided Chunking with spaCy
- Splits text into chunks of sentences.
- It uses a linguistic model to identify the semantic sentence level boundary.
- Assumes that each sentence is semantically self-contained and coherent.
- It might not work when the semantic meaning spans multiple sentences.
import spacy
nlp = spacy.load('en_core_web_sm')
doc = nlp(text)
sentences = [sent.text for sent in doc.sents][['Mr. and Mrs. Dursley, of number four, Privet Drive, were proud to say that they were perfectly normal, thank you very much.'],
['They were the last people you’d expect to be involved in anything strange or mysterious, because they just didn’t hold with such nonsense.\\n\\n'],
['Mr. Dursley was the director of a firm called Grunnings, which made drills.'],
['He was a big, beefy man with hardly any neck, although he did have a very large mustache.'],
['Mrs. Dursley was thin and blonde and had nearly twice the usual amount of neck, which came in very useful as she spent so much of her time craning over garden fences, spying on the neighbors.'],
['The Dursleys had a small son called Dudley and in their opinion there was no finer boy anywhere.\\n\\n'],
['The Dursleys had everything they wanted, but they also had a secret, and their greatest fear was that somebody would discover it.'],
['They didn’t think they could bear it if anyone found out about the Potters.'],
['Mrs. Potter was Mrs. Dursley’s sister, but they hadn’t met for several years; in fact, Mrs. Dursley pretended she didn’t have a sister, because her sister and her good-for-nothing husband were as unDursleyish as it was possible to be.'],
['The Dursleys shuddered to think what the neighbors would say if the Potters arrived in the street.'],
['The Dursleys knew that the Potters had a small son, too, but they had never even seen him.'],
['This boy was another good reason for keeping the Potters away; they didn’t want Dudley mixing with a child like that.\\n\\n'],
['When Mr. and Mrs. Dursley woke up on the dull, gray Tuesday our story starts, there was nothing about the cloudy sky outside to suggest that strange and mysterious things would soon be happening all over the country.'],
['Mr. Dursley hummed as he picked out his most boring tie for work, and Mrs. Dursley gossiped away happily as she wrestled a screaming Dudley into his high chair.']]Semantic Chunking for RAG: Embedding-Based Text Segmentation with Cosine Similarity
This chunking method involves creating vector embeddings of sentences and then grouping local cohesive vector embeddings. Thus creating a semantically coherent chunk [3]. This method addressed the limitation of sentence-level chunking, where a coherent semantic meaning spans multiple sentences. We can create embedding vectors for each sentence by using OpenAI’s Embeddings.
from langchain.embeddings import OpenAIEmbeddings
oaie = OpenAIEmbeddings()
embeddings = oaie.embed_documents(sentences)We will create pairwise-cosine similarity to visualize the semantic relationship between these newly created sentence-level embeddings. Even though the chunks will be created by grouping neighboring similar vectors, creating pairwise similarity allows us to explore relationships between non-consecutive sentences.
Cosine similarity is used to capture the semantic relationship between these high-dimensional vectors. Consider two non-zero vectors, u and v. The cosine similarity of u and v is the normalized dot product of both vectors.
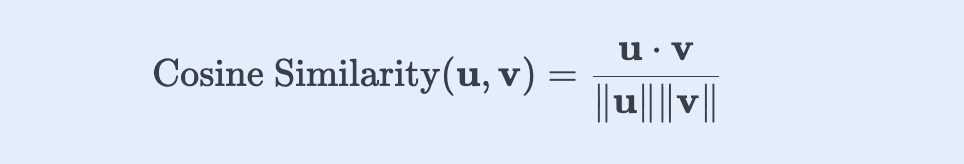
Its value ranges between -1 and 1, where a value closer to 1 means the vectors are highly similar and pointing in the same direction. A value closer to -1 means the vectors are in opposite directions, representing contrasting meanings.
import numpy as np
from sklearn.metrics.pairwise import cosine_similarity
cos_sim_matrix = cosine_similarity(embeddings)import seaborn as sns
import matplotlib.pyplot as plt
plt.figure(figsize=(12, 8))
sns.heatmap(cos_sim_matrix, annot=True, cmap="YlGnBu", fmt=".2f")
plt.title("Cosine Similarity Matrix")
plt.show()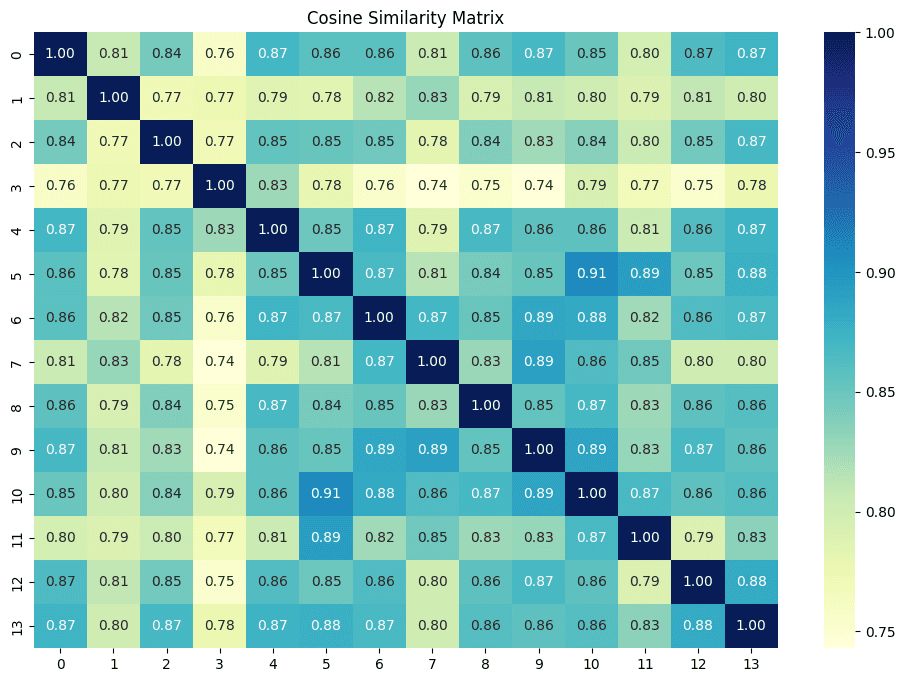
Fig 2. Cosine similarity matrix
From this pairwise-cosine similarity, we will create semantically coherent chunks using the greedy approach, in which we will group consecutive sentences with a cosine similarity score above a threshold. This threshold value is a hyper parameter; adjusting it will change the number of chunks created. We can select an appropriate threshold value by observing a heat map plot of pairwise cosine similarity scores.
We will traverse the 2D matrix of this pairwise cosine similarity to create chunks of contiguous embeddings. If Matrix[i][i+1]>threshold, then we will include them in a chunk. Below is the detailed code for creating desired chunks:
def create_chunks(sentences, cos_sim_matrix, threshold):
chunks = []
current_chunk = [sentences[0]]
for i in range(1, len(sentences)):
if cos_sim_matrix[i-1][i] > threshold:
current_chunk.append(sentences[i])
else:
chunks.append(current_chunk)
current_chunk = [sentences[i]]
chunks.append(current_chunk)
return chunks
chunks = create_chunks(sentences, cos_sim_matrix, threshold=0.8)[['Mr. and Mrs. Dursley, of number four, Privet Drive, were proud to say that they were perfectly normal, thank you very much.',
'They were the last people you’d expect to be involved in anything strange or mysterious, because they just didn’t hold with such nonsense.\\n\\n'],
['Mr. Dursley was the director of a firm called Grunnings, which made drills.'],
['He was a big, beefy man with hardly any neck, although he did have a very large mustache.',
'Mrs. Dursley was thin and blonde and had nearly twice the usual amount of neck, which came in very useful as she spent so much of her time craning over garden fences, spying on the neighbors.',
'The Dursleys had a small son called Dudley and in their opinion there was no finer boy anywhere.\\n\\n',
'The Dursleys had everything they wanted, but they also had a secret, and their greatest fear was that somebody would discover it.',
'They didn’t think they could bear it if anyone found out about the Potters.',
'Mrs. Potter was Mrs. Dursley’s sister, but they hadn’t met for several years; in fact, Mrs. Dursley pretended she didn’t have a sister, because her sister and her good-for-nothing husband were as unDursleyish as it was possible to be.',
'The Dursleys shuddered to think what the neighbors would say if the Potters arrived in the street.',
'The Dursleys knew that the Potters had a small son, too, but they had never even seen him.',
'This boy was another good reason for keeping the Potters away; they didn’t want Dudley mixing with a child like that.\\n\\n'],
['When Mr. and Mrs. Dursley woke up on the dull, gray Tuesday our story starts, there was nothing about the cloudy sky outside to suggest that strange and mysterious things would soon be happening all over the country.',
'Mr. Dursley hummed as he picked out his most boring tie for work, and Mrs. Dursley gossiped away happily as she wrestled a screaming Dudley into his high chair.']]Agentic Chunking for RAG: GPT-4 Powered Adaptive Text Splitting with ReAct
Until now, we have been explicitly deciding on the strategy for creating chunks. Strategies include fixing the number of characters in a chunk, the order of separators to follow, and how to combine embeddings. But in agentic chunking, the agent generates the plan for splitting the text.
It’s adaptability and global semantic awareness set agentic chunking apart from the rest of the traditional methods. It takes advantage of tools such as chunk creator and chunk analyzer that create and analyze the chunks.
Below is the code for agentic chunking that uses GPT -4’s reasoning and acting (ReAct) capabilities in a zero-shot setting:
def agentic_chunking(text: str, base_chunk_size: int = 500, chunk_overlap: int = 50):
tools = [
Tool(
name="Chunk Creator",
func=lambda chunk: f"Created chunk: {chunk}",
description="Creates chunks from the input text."
),
Tool(
name="Chunk Analyzer",
func=lambda chunk: f"Analyzed chunk: {chunk}",
description="Analyzes the chunk and decides on its purpose."
),
]
chat_model = ChatOpenAI(model="gpt-4", temperature=0.8)
agent = initialize_agent(
tools=tools,
llm=chat_model,
agent="zero-shot-react-description",
verbose=True,
)
strategy_prompt = f"""
You are an intelligent agent tasked with creating coherent chunks from the following text:
{text}
Provide your chunking strategy by determining how to divide the text into meaningful segments
with an approximate size of {base_chunk_size} characters. Include any overlap if necessary.
"""
chunking_strategy = agent.run(strategy_prompt).strip()
chunking_prompt = f"""
Based on the following strategy, create meaningful chunks from the input text.
Return each chunk as a separate list of sentences:
Strategy: {chunking_strategy}
Text: {text}
"""
chunks_response = agent.run(chunking_prompt).strip()
chunks = []
for chunk in chunks_response.split("\\n\\n"):
sentences = [sentence.strip() for sentence in chunk.split("\\n") if sentence.strip()]
if sentences:
chunks.append(" ".join(sentences))
return chunks
chunks = agentic_chunking(text)[["Mr. and Mrs. Dursley, of number four, Privet Drive, were proud to say that they were perfectly normal, thank you very much. They were the last people you’d expect to be involved in anything strange or mysterious, because they just didn’t hold with such nonsense."],
["Mr. Dursley was the director of a firm called Grunnings, which made drills. He was a big, beefy man with hardly any neck, although he did have a very large mustache. Mrs. Dursley was thin and blonde and had nearly twice the usual amount of neck, which came in very useful as she spent so much of her time craning over garden fences, spying on the neighbors. The Dursleys had a small son called Dudley and in their opinion there was no finer boy anywhere."],
["The Dursleys had everything they wanted, but they also had a secret, and their greatest fear was that somebody would discover it."],
["They didn’t think they could bear it if anyone found out about the Potters. Mrs. Potter was Mrs. Dursley’s sister, but they hadn’t met for several years; in fact, Mrs. Dursley pretended she didn’t have a sister, because her sister and her good-for-nothing husband were as unDursleyish as it was possible to be. The Dursleys shuddered to think what the neighbors would say if the Potters arrived in the street. The Dursleys knew that the Potters had a small son, too, but they had never even seen him. This boy was another good reason for keeping the Potters away; they didn’t want Dudley mixing with a child like that."],
["When Mr. and Mrs. Dursley woke up on the dull, gray Tuesday our story starts, there was nothing about the cloudy sky outside to suggest that strange and mysterious things would soon be happening all over the country. Mr. Dursley hummed as he picked out his most boring tie for work, and Mrs. Dursley gossiped away happily as she wrestled a screaming Dudley into his high chair."]]How to Evaluate RAG Chunking Methods: Metrics and Benchmarks
Evaluating RAG Chunks Using LDA Coherence Score
A good chunk should capture a semantically coherent segment of a text. The coherence score quantifies the semantic relation between the words in a chunk. A high coherence score indicates that the chunks are meaningful and grouped semantically, whereas a low coherence score indicates arbitrary grouping or poor structure of chunks. Latent Dirichlet Allocation (LDA) is a topic modeling technique that generates topics based on word usage patterns and co-occurrence within a document. It assumes that each document is a mix of topics and each topic is a mix of frequently appearing words. LDA maximizes the separation between the categories by creating an axis that maximizes the distance between the means and minimizes the distance between the variation of categories [4]. LDA assumes that documents with similar topics will use similar words. Documents are a probability distribution over latent topics, and topics are a probability distribution over words. To better understand how LDA operates, it can be visualized as a generative process often referred to as the LDA machine, as shown below:
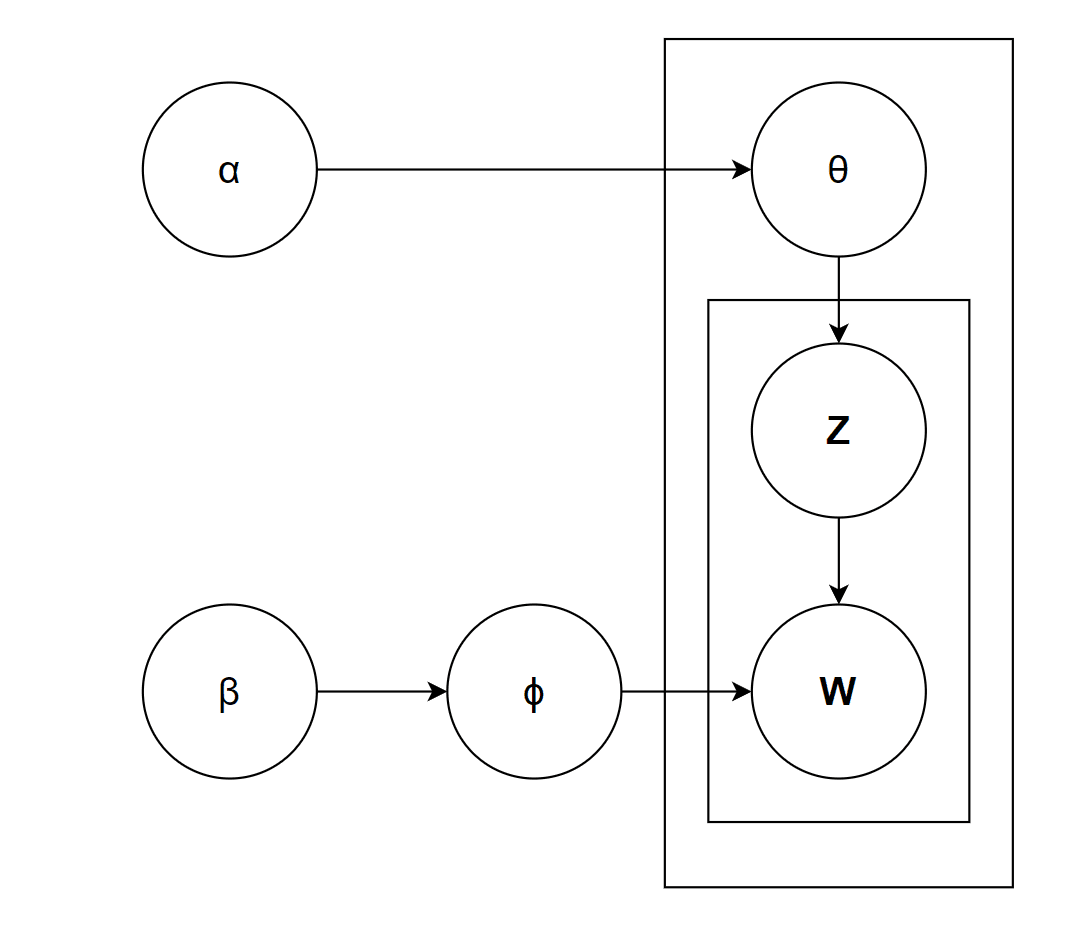
Fig 3. LDA machine
To formalize this process mathematically, it is expressed below as a joint probability distribution, which gives the probability of generating a document from a corpus.


When evaluating chunking methods, the probability distribution P(W, Z, θ, ϕ; α, β) helps in quantifying how well the latent topics align with the chunks by analyzing how well the topics and word distribution fit the chunks. Well-chunked text produces clear document-topic distributions ( θj ), meaningful topic-word distributions ( Φj ), consistent topic assignments ( Z j,t} ), and high word probabilities P(W j,t | ΦZj,t).
Below is the code for evaluating different chunks created by different chunking methods using LDA coherence score:
import spacy
from nltk.corpus import stopwords
from gensim import corpora
from gensim.models import LdaModel
from gensim.models.coherencemodel import CoherenceModel
import nltk
nltk.download('stopwords')
nlp = spacy.load("en_core_web_sm")
def preprocess_text(chunk):
if isinstance(chunk, str):
chunk = [chunk]
doc = nlp(" ".join(chunk))
return [
token.text.lower()
for token in doc
if token.text.lower() not in stopwords.words("english") and token.is_alpha
]
def compute_lda_coherence(chunks, num_topics=2, passes=50, random_state=42):
if any(isinstance(chunk, str) for chunk in chunks):
chunks = [[chunk] if isinstance(chunk, str) else chunk for chunk in chunks]
processed_chunks = [preprocess_text(chunk) for chunk in chunks]
dictionary = corpora.Dictionary(processed_chunks)
corpus = [dictionary.doc2bow(chunk) for chunk in processed_chunks]
lda_model = LdaModel(
corpus, num_topics=num_topics, id2word=dictionary, passes=passes, random_state=random_state
)
coherence_model = CoherenceModel(
model=lda_model, texts=processed_chunks, dictionary=dictionary, coherence='c_v'
)
coherence_score = coherence_model.get_coherence()
return coherence_scoreThe table below compares LDA coherence scores for different chunking methods. The higher the LDA score, the better the semantically coherent chunks.
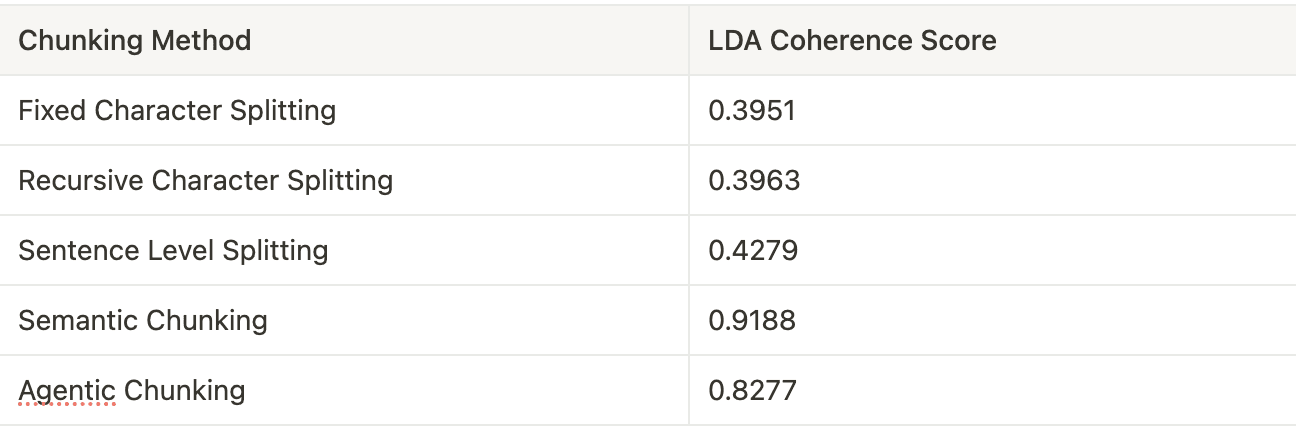
Evaluating RAG Chunks Using Intersection over Union (IoU)
The goal of any RAG system is to retrieve relevant tokens. To quantify this, we can calculate the intersection of the set of retrieved tokens with a set of ground truth (relevant) tokens. Ground truth tokens are tokens of chunks created by humans. Below is the ground truth chunking created by humans:
#Ground Truth Chunks
[["Mr. and Mrs. Dursley, of number four, Privet Drive, were proud to say that they were perfectly normal, thank you very much. They were the last people you’d expect to be involved in anything strange or mysterious, because they just didn’t hold with such nonsense."],
["Mr. Dursley was the director of a firm called Grunnings, which made drills. He was a big, beefy man with hardly any neck, although he did have a very large mustache. Mrs. Dursley was thin and blonde and had nearly twice the usual amount of neck, which came in very useful as she spent so much of her time craning over garden fences, spying on the neighbors. The Dursleys had a small son called Dudley and in their opinion there was no finer boy anywhere."],
["The Dursleys had everything they wanted, but they also had a secret, and their greatest fear was that somebody would discover it. They didn’t think they could bear it if anyone found out about the Potters. Mrs. Potter was Mrs. Dursley’s sister, but they hadn’t met for several years; in fact, Mrs. Dursley pretended she didn’t have a sister, because her sister and her good-for-nothing husband were as unDursleyish as it was possible to be. The Dursleys shuddered to think what the neighbors would say if the Potters arrived in the street."],
["The Dursleys knew that the Potters had a small son, too, but they had never even seen him. This boy was another good reason for keeping the Potters away; they didn’t want Dudley mixing with a child like that."],
["When Mr. and Mrs. Dursley woke up on the dull, gray Tuesday our story starts, there was nothing about the cloudy sky outside to suggest that strange and mysterious things would soon be happening all over the country. Mr. Dursley hummed as he picked out his most boring tie for work, and Mrs. Dursley gossiped away happily as she wrestled a screaming Dudley into his high chair."]]This human-annotated chunking will give you the number of relevant tokens that were correctly retrieved. But just using intersection as a standalone metric is not enough, as it can be misleading. Thus, it is required to be normalized. This is done by dividing the union of the set of retrieved and relevant tokens. This IoU metric is widely used in computer vision to compare the similarity between two shapes [5].

Using a normalized intersection score helps eliminate false positives and negatives in the retrieval process. False positive tokens are irrelevant tokens retrieved by the system but not part of relevant tokens. False negative tokens are those relevant tokens not retrieved by the system. Below is the code for the IoU metric. It evaluates how closely the generated chunks match with the relevant chunks.
def tokenize_chunk(chunk):
return set(chunk.lower().split())
def calculate_iou(relevant_tokens, retrieved_tokens):
intersection = relevant_tokens.intersection(retrieved_tokens)
union = relevant_tokens.union(retrieved_tokens)
iou = len(intersection) / len(union) if len(union) > 0 else 0
return iou
def iou_chunks(relevant_chunks, generated_chunks):
flat_relevant = [tokenize_chunk(" ".join(chunk)) for chunk in relevant_chunks]
flat_generated = [tokenize_chunk(" ".join(chunk)) for chunk in generated_chunks]
iou_scores = []
for gen_chunk in flat_generated:
iou_max = 0
for relevant_chunk in flat_relevant:
iou_score = calculate_iou(relevant_chunk, gen_chunk)
iou_max = max(iou_max, iou_score)
iou_scores.append(iou_max)
average_iou = sum(iou_scores) / len(iou_scores) if iou_scores else 0
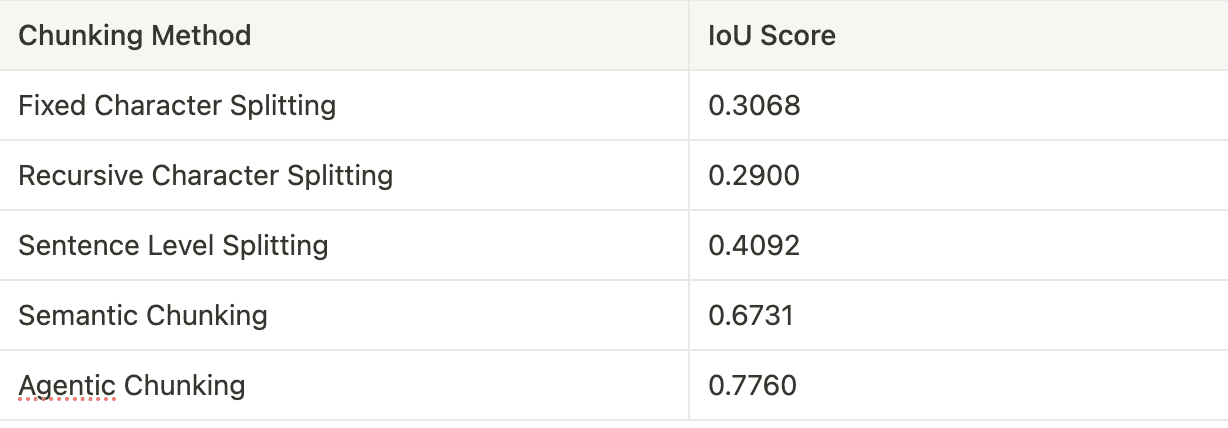
return iou_scores, average_iouThe table below compares IoU scores for different chunking methods. The higher the IoU score, the better the alignment of generated chunks with the reference chunks.
Which RAG Chunking Method Should You Use? A Decision Guide

- Recursive character or sentence-level chunking can be used as a first choice.
- Semantic chunking can be used if you want to create semantic-aware chunks and can come up with a strategy.
- If your dataset lacks proper structuring or you don’t know what strategy to follow to create chunks, then agentic chunking can be preferred.
References
[1] P. Lewis et al., “Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks,” Apr. 2021. Available:https://arxiv.org/pdf/2005.11401
[2] A. J. Yepes, Y. You, J. Milczek, S. Laverde, and R. Li, “Financial Report Chunking for Effective Retrieval Augmented Generation,” arXiv.org, Mar. 16, 2024.https://arxiv.org/abs/2402.05131
[3] Azzedine Aftiss and Said, “Combining Semantic Clustering and Sentence Embedding Representation for Abstractive Biomedical Summarization,” Lecture notes in networks and systems, pp. 425–435, Jan. 2024, doi:https://doi.org/10.1007/978-3-031-52385-4_40.
[4] D. Blei, B. Edu, A. Ng, M. Jordan, and J. Edu, “Latent Dirichlet Allocation,” Journal of Machine Learning Research, vol. 3, pp. 993–1022, 2003, Available:https://jmlr.org/papers/volume3/blei03a/blei03a.pdf
[5] H. Rezatofighi, N. Tsoi, J. Gwak, A. Sadeghian, I. Reid, and S. Savarese, “Generalized Intersection over Union: A Metric and A Loss for Bounding Box Regression.” Available:https://arxiv.org/pdf/1902.09630

Learn how to integrate user feedback into automated data layers in 2026. Covers feedback collection, data augmentation, and continuous model improvement.


Discover the best free AI search engines in 2026. Covers You.com, Perplexity AI, ChatGPT Search, how AI search works, and how to choose the right tool

Explore how continued LLM pretraining boosts adaptability in healthcare, finance, legal, and education. Covers strategies and benefits over fine-tuning.